基于YOLO V3的施工电梯人数检测系统研究
2021-06-01徐奕森张建强关加浚徐成烨
徐奕森 张建强 王 蕊 关加浚 徐成烨
(华南理工大学广州学院,广州 510800)
根据国家安监法规的安全人数限制要求,目前的施工电梯没有很好的解决方法。施工电梯承载能力强,进入电梯人数超载的情况下,一般不易触发质量超限报警,导致施工电梯依旧启动,降低了其安全性。目前,国内外的电梯人数统计方法取得了一些进展,但其采用传统视觉识别方法,且并未实现与电梯主控系统的连接。通过图像分割对其进行Hough变换的方法,实现了对安全帽的识别[1]。通过图像分割对其进行二值变换,实现了对安全帽的识别[2]。研究多采用基于图像分割对人头进行数量识别,但并未对未佩戴安全帽的情况进行统计。应用软硬件相结合的方式,采用远红外识别的方法,对电梯内人数进行识别。但是,该方法平均计算效率较低。上述研究大都是针对简单环境的识别定位,且研究方法的识别效率较低,无法时时与电梯内主控系统连接,实现在人数超载情况时的禁止启动,对在实际复杂环境中的识别效率鲜有研究[3-5]。
目前,深度卷积神经网络主要有两大类:一种是RCNN[6]基于候选区域的方法;另一种是SSD[7]、RetinaNet[8]、YOLO等无候选区域的方法。基于单步检测的YOLO算法,不同于RCNN为代表的双步检测算法,网络结构更加简单。相同条件下,基于单步检测的YOLO算法的检测速率相比于Faster-RCNN快约10倍[9-10]。由深度卷积神经网络的YOLO检测,在复杂条件下具有检测速度感高、稳定性好的优点。针对现在人数检测存在的问题,由卷积神经网络简化的YOLO V3算法检测人员静态图片和动态视频,摸索在实际复杂条件下机器视觉的工作效率,可为施工电梯人数检测方案提供视觉检测系统理论基础。
机器视觉具备识别精度高、检测流畅等优点。将机械视觉融入工程机械,有助于提高工作安全性。稳定快速的目标检测系统通过串行通信总线实现与施工电梯的实时信息交互,当超过设定人数后,禁止电梯启动,确保安全。
1 YOLO V3目标检测算法
YOLO V3目标检测算法将检测问题转化为回归问题,通过使用卷积神经网络实现回归,使得整个网络结构简明。它具有特有的网络结构,且端对端的网络结构使其速度远高于其他网络模型。
YOLO V3算法对目标检测的原理,如图1所示。先将输入的图片按照一定尺度划分为m×m个网格,当目标位于某个网格中时,便由该网络进行目标检测。其中,每个网络又可以划分成s个预测边界区域。预测边框时,Cx、Cy为相对于左上角的位置。通过归一化,将每个格子缩放到单位长度为1。此时,Cx=1,Cy=1。Tx和Ty分别经过Sigmoid输出0-1之间的偏移量,与Cx、Cy相加后得到Bounding boxes中心点的位置。Pw、Ph是设置的Anchor宽和高,Tw、Th分别与Pw、Ph作用后获得的边界框的宽和高,如图1所示。
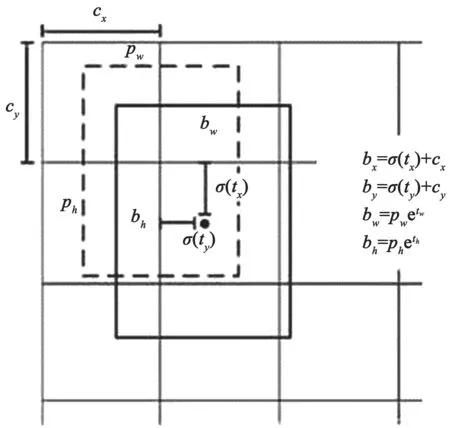
图1 YOLO V3边界框原理图
置信度一般分为两个部分:一是预测边界框内物体类别的概率;二是预测边界与真实边界的重合度。它的置信度计算公式为:

式中,Pr(classi|object)表示边界内物体的类别的概率,Pr(object)表示网络中是否有待检测目标的中心点。若有,则为1;反之,则为0。IOU表示其交并比。
使用NMS算法对生成的预测框进行筛选,通过设置置信度的值消去冗余的预测边界框,通过剩下的边界框检测其目标。
2 YOLO V3模型设计
YOLO V3网络整体共用106层网络层。考虑到本文识别对象为人,过多的卷积层会增加大量计算,使参数量过多导致检测时间过久无法及时报警,因此简化设计YOLO V3神经网络结构。参考VGG-19搭建如图2所示的16层网络结构,其中两类输出张量分别为52×52×21与26×26×21,并尝试减少不同数量的残差层(res),从而减小网络模型。简化后,网络结构如图2所示。它的残差层可简化为不同的层数,通过设定不同的层数来控制其检测精度与计算速度,故其与条件相同时改变残差层数量,以便确定最优残差层。
3 实验模型训练与调试
3.1 数据收集与标注
3.1.1 数据收集
数据采集均在某工程装备公司内。它采集的数据多处于施工电梯工作状态下,有佩戴红色安全帽、白色安全帽、蓝色安全帽、黄色安全帽、不佩戴安全帽与其他等情况。图像的分辨率为1 280像素×720像素。多种样本总数为4 000张,包含佩戴不同颜色安全帽的4种情况共2 000张,不佩戴安全帽的1 000张,佩戴其他帽的1 000张。数据集中,训练集、验证集和测试样本的比例约为8:1:1。
3.1.2 数据标注
为了满足样本的多样性及其质量,消除外界环境对其检测的影响,采集白天1 000张、高矮1 000张、覆盖1 000张、密集环境1 000张下的人头图片,并将其分类筛选后加入样本集。图片采用Labellmg进行人工手动标注,并保存为xml文件,具体格式包括x、y(目标中心点x、y坐标)与w、h(标注框高度与框长度)。

图2 YOLO V3网络训练结构
3.2 模型训练与评价标准
本次训练与测试均在PC端完成,配置为Intel i5 7300与GeForce GTX 1060显卡。程序运行在Windows10系统下,调用英伟达并行开源计算库CUDA、CUDNN与开源视觉库OPENCV运行,每个模型均训练20 000次。
在交并比IOU为0.5时,YOLO V3算法有3种像素可供训练选择,人数识别方案采用416像素模式。为了对不同模型的性能进行评价,本文采用准精度均值(mean Average Precision,mAP)和其每秒平均帧率共同作为模型评价标准,计算公式为:

式中,K为阈值数,N为引用阈值的数量,P(k)为准确度,R(k)为召回率,mAP为人头顶部和安全帽的平均精度。
3.3 网络最优残差层
从表1可看出,随残差层数量减少,其速率上升检测精度下降。残差层为3层时,网络模型的检测平均速率为4.24 f·s-1,速率较慢;减少1层网络后,监测速率上升至平均55.59 f·s-1,比拟完整残差模型提升1.79倍,监测流畅程度明显上升。当残差模型减少2层后,检测速率上升至平均65.87 f·s-1,相比3层残差模型上升约1.83倍,相比减少1层残差网络模型上升约1.18倍。

表1 残差层性能影响
从表1可看出,当减少网络模型层数到2层时,人头顶部和安全帽的平均精度为84.37%;而减少至只有1层残差层时,由于反馈过于薄弱,几乎无法检测到,故其无法选用。3层完整的残差层,效果与2层残差层时基本相同,且相对于2层残差层更加消耗资源,不利于日后移植到开发板中。综合来看,2层残差层在测试精度速率均衡下效果最好,故采用2层残差层作为测试模型。
3.4 实验同人数情况下的静态图片试验分析对比
本次试验以数量作为变量,测试集包括400张照片,其中含1~3图片共100张,包含4~6图片共200张,包含7个及以上图片共100张。每一种抽取20张作为检测样本,检测出样本总量、正确识别的数量、未检测人员的数、误检测的人员数,采用精度均值与每秒帧率作为综合评价值。图片边缘残缺人头部分忽略不计。从图3可以看出,在数量较少的情况下,两种方法都能正确识别到未带安全帽的人和佩戴安全帽的人,但SSD算法存在对已检测到手持安全帽误检测的现象。这是因为网络深度不够无法有效区分佩戴情况所导致。但是,人数增加到7个及以上时,改进后YOLO算法识别依旧准确,而SSD算法出现了识别对已检测到手持安全帽误检测与识别精度降低的情况。这是由于人头部的尺寸减小、人头重叠与粘连等情况增加了模型识别的难度。表2为两种算法对不同人数下的检测结果。

图3 两种算法下不同人数下的检测效果
从表2可看出,随着数量的增多,佩戴安全帽的和未佩戴安全帽的精度均值均减小,但SSD算法无法区分佩戴与手持安全帽。当人数大于7时,精度均值下降3%~5%。由于人数量的增多,SSD算法易产生一人多框及错漏识别的现象。改进后YOLO采用改进后的多层次神经元网络,能够检测细小的栅格,在小目标的检测识别上取得了较好的效果。试验中,改进的YOLO算法精度均值最高,使用的阈值为0.5。SSD的检测速度比改进后YOLO慢约2.14倍。
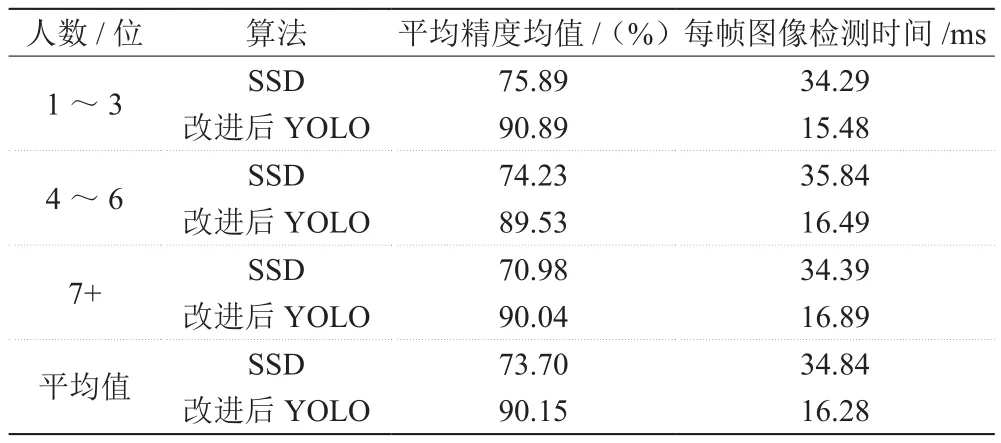
表2 两种算法在各人数检测试验
3.5 动态视频中的识别效果对比
实际工地中可能存在多种复杂情况。图4为两种算法在内部佩戴安全帽的不同状态的检测效果。当未佩戴安全帽时,头部目标较小,存在相互重叠、粘连的情况。而进入电梯后,部分脱去安全帽后存在双检测目标。当检测精度不足时易误检,且检测重叠、粘连现象出现频率高。当进入佩戴遮阳帽时,识别难度大幅增加,易出现漏识别、一人多框以及对手持安全帽误识别等现象。相对SSD识别算法,改进后的YOLO算法在视频识别的精度上具有明显优势。可见,改进后YOLO算法不仅在识别精度上保持着较好的准确性,而且在复杂环境下具有良好的鲁棒性。
对于不同的佩戴状况,佩戴遮阳帽时的平均精度均值最高,如表3所示,识别速率最佳。对于进入后脱帽与佩戴遮阳帽的情况,增加了模型识别的时长和运算量。改进后YOLO算法平均检测速率约比SSD算法快2.45倍。在识别效果上,改进后YOLO算法平均精度均值最高,SSD算法相对较差,且其检测精度在外界环境变换时会发生较大变化。例如,在佩戴遮阳帽的识别的情况下,识别准确度较差,且存在识别粘连等情况。综上,改进后YOLO模型可以胜任人数识别方案的要求,平均识别速度达到了54.4 f·s-1。

图4 两种算法在不同佩戴状态下的效果检测

表3 两种算法在不同佩戴状态下的效果检测
4 结语
为解决施工电梯人数超载的问题,本文提出了基于YOLO V3算法的人数检测方法。通过对YOLO V3模型进行设计改进,在保证检测精度的同时降低了硬件资源需求。研究表明,改进后的YOLO算法检测速率达到了54.4 f·s-1,平均精度约为89.88%,视频检测速率符合实时检测的要求。在视频中,包括遮挡、密集等复杂情况下,它有良好的鲁棒性。简化后的模型可满足施工电梯人数检测方案的基本要求,检测速度比SSD算法快2.4倍,基本满足施工电梯对人数检测需求,并为进行嵌入式移植奠定了基础。
