基于TMRF 算法的电信客户流失预测方案研究*
2021-06-01李兵陈俊才
李兵 陈俊才
(1.广东邮电职业技术学院,广东广州 510630;2.中国电信广东公司,广东广州 510000)
0 引言
自我国电信业重组之后,各大电信运营商在生产经营活动中,对客户的竞争加剧,增量客户争夺与存量客户维系是两个最重要的业务指标。据调查数据表明,争取1名增量用户成本为保持1名存量用户的4-5倍[1]。而目前存量客户的维系基本上依靠市场人员的经验锁定潜在流失客户进行营销,存在准确性低、维系效果不理想的问题。近年来,随着计算机设备算力增加与分布式计算等大数据存储、计算技术的快速发展,为拥有海量用户数据的电信运营商进行客户流失预测研究提供了便捷。以电信行业大数据为“矿藏”,使用以回归算法、分类聚类、决策树及人工神经网络等机器学习算法,可以从大量历史流失客户的特征规律着手,客观地研究出客户的属性,实现潜在流失客户的精准识别,以便市场人员开展客户流失挽留。
目前国内外各大电信运营商对客户流失的研究主要集中在三个方面:(1)电信客户离网影响要素研究;(2)电信客户挽留策略与营销方法研究;(3)预测算法建模分析客户流失。本文所述研究为第三方面,旨在从现网客户中找出潜在流失客户。
1 客户流失与机器学习
客户流失是指客户终止当前的电信套餐服务并不再续约,也称之为用户离网。根据现有研究可知,客户流失主要因素可以归纳为价格、网络质量、服务质量、故障响应速度、增值服务等,当然也包括一些自身原因,如工作原因致使号码变化、居住城市、他网(同类型服务商)竞争等。这些潜在因素成为我们进行流失预测建模的重要输入,以期实现流失预警与维系双管齐下的目标。
机器学习[2]是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科,它使用计算机模拟人类行为,以获得新知识与规律。大数据技术为机器学习提供更广阔的应用舞台。
国外基于机器学习算法的电信客户流失的研究相对较早,Louis使用决策树TreeNet不仅实现了对Verizon客户流失的高准确度预测,同时找到影响客户流失的重要因素[3];Nath等[4]人使用Bayes分类器较为准确地计算出未来3个月客户离网概率;Khan等[5]人使用少量变量通过递归神经网络RNN算法对英国电信British Telecom客户数据进行流失预测分析。
国内学者关于这一领域的研究虽起步晚,但相关研究发展迅速。赵宇等人针改进了传统SVM 算法在数据不平衡下使客户流失的预测准确率大幅提升[6];徐新乔通过分布式架构大数据平台整合异构数据,提出基于XGBoost的Bagging方法构建二分类模型对电信用户进行离网预测,较好地提升了模型的精确率与召回率[7];沈江明等提出了基于不均衡数据处理与组合模型相结合的组合模型,用于客户流失隔月预测,实现了命中率的提升[8];蔡男将聚类算法融入随机森林构造新的随机森林改进了传统随机森林模型的预测性能指标[9]。近年来,多算法融合的机器学习方法成为预测客户流失的一个重要分支,并引起越来越多学者的关注。
目前国内外关于电信客户流失的研究,大多基于Clementine、SPSS等数据挖掘软件,存在单数据挖掘算法或组合挖掘算法调参不便、使用数据维度有限等问题,难以全面分析客户流失。
2 客户流失预测实现方案
2.1 流失预测方案过程
国内各电信运营商由于行业规定、业务发展与网络分析需要早已建有各类历史信息管理系统,包含客户关系管理系统CRM、业务支撑系统BSS、运营支撑系统OSS、宽带日志、故障申告等,这些系统底层数据库基本上采用传统的关系型数据库系统如MySQL、Oracle、SQL Server等,存储格式往往按时间、站点等属性进行存储。我们在进行客户流失预测建模之前,需整合各个数据源到统一的大数据平台。预测方案的建立过程如图1 所示。
从图1可知,流失预测方案过程包括“数据源→大数据平台→预处理→特征选择→标准化处理→预测算法构建→预测训练→预测方案生成→方案评估→最终预测优化方案”。在训练过程中预测指标达不到预期,需采用各种机器学习方法进行反复训练并加以验证。

图1 客户流失预测方案的建立过程Fig.1 The establishment process of customer churn prediction scheme
2.2 流失预测方案
2.2.1 数据源整合与大数据平台
目前我国电信运营商数据平台众多且分散,OSS、BSS、SEQ、上网等全网多种数据源的整合工作量大、难度较高,且存在数据口径不一致的情况。本部分工作是决定大数据挖掘效果至关重要的一个环节。数据整合的质量决定预测模型的上限,后续算法的优化为预测模型能否接近上限,因此数据源的整合往往占据着电信行业大数据挖掘的绝大部分时间。现有系统往往利用数据集成套件BDI和日志收集系统Flume将离线数据抽取到Hadoop平台的分布式文件系统HDFS中;对于实时性要求高的数据源往往采用FLume整合Kafka的方式实现实时数据采集,如图2 所示。在大数据前提下而言,数据源越多进行预测建模的预测准确性等评价指标会越好,但实际操作过程中应根据运营商数据源现状合理整合,尽量避免大量“脏数据”的出现。
本方案采集的源数据包括客户基本信息、故障报备与投诉记录、DTS线路检测、移动通话记录、宽带网络访问日志等。
2.2.2 大数据预处理
目前大多数挖掘建模过程,都会将预处理后的二次数据放在关系型数据库,但本方案对于数据量大、数据类型多、数据价值密度相对较低的电信行业大数据,如上图2所示使用MapReduce进行分布式计算,能极大地提升计算效率。预处理的主要内容包括去除奇异点数据、补充缺失数据、数据重组、无效数据清洗以及数据抽取等内容。本步骤最重要的在于无效数据的清洗与对已离网客户数据的完整性、准确性进行检查,这是决定后续预测算法效果最重要的两个因素。数据抽取环节完成将源数据记录转变为以客户为粒度的网络行为特征,数据抽取工作往往根据建模经验与专家判断而定。本方案将上述源数据抽取为326个客户网络行为特征。

图2 电信大数据整合与应用框架图Fig.2 Telecom big data integration and application framework

表1 客户流失预测方案特征表Tab.1 Characteristic table of customer churn prediction scheme

图3 TMRF 算法流程图Fig.3 Flow chart of TMRF algorithm

表2 混淆矩阵Tab.2 Confusion matrix
2.2.3 特征选择
不是所有的数据属性都与客户流失相关,为了减少建模算法的运算量,往往需要使用数据探索性分析[10](Exploratory Data Analysis,简称EDA)以去除不相关的数据,并选取重要的关键特征子集。目前采用主成分分析[11](如PCA)等降维方法或分析工具的方式实现特征选择比较常见。本方案采取datawrangler工具实现特征的选择,最终得到相关性较大的行为特征共57个,如表1所示。表1数据统计周期为月,其中客户行为的变化趋势为同比上月的数据。
2.2.4 标准化处理
在多特征建模过程中,由于各特征的性质、量纲及数量级不同,通常需要在应用预测算法建模前,对数据进行标准化处理使数据指标化。常用的方法有min-max标准化、log函数转换以及z-score标准化等。本方案根据输入特征的实际情况采用最大最小规范法,如公式1 所示,进行标准化处理,以使得各非数值类特征统一落在一个较小的区间[0,1]。

2.2.5 预测算法的构建与方案训练
目前通常采用回归算法、分类聚类、决策树及人工神经网络等算法进行流失预测建模。有很多非常方便的工具和算法库支撑数据处理,如Tensorflow、scikitlearn、NumPy等。利用这些已有的工具和算法库能有效地减少算法开发与验证难度。本方案拟采用scikit-learn改进随机森林以实现预测建模。对于电信运营商而言,客户流失可以按业务类型进行划分,如宽带、4/5G移动、IPTV等,本方案以4/5G移动客户的流失预测为目标。其它业务类型客户流失预测机制相似,本文可作为参考。
2.3 流失预测方案评估
使用训练数据完成预测方案训练后,再利用验证数据进行对比来判断方案的预测效果。常用的评估方法有5个:混淆矩阵、洛伦兹图、GINI系数、KS曲线及ROC曲线。本方案根据应用需要,选用混淆矩阵与ROC 曲线对预测算法进行评估。其中混淆矩阵指标如表2 所示,通过以下三个指标来评估模型的有效性:
精确率Precision=TP/(TP+FP)
召回率Recall=TP/(TP+FN)
F1-值(F1-score)=2*P*R/(P+R)
F1-score是精确率和召回率的调和平均数,在机器学习中,往往将其作为模型重要评测指标,此外,ROC 曲线(AUC的值)能更为稳定地反映模型好坏,一般预测算法的AUC(如下公式2,M与N分别代表正负样本数量)介乎0.5至1之间才能证明算法有效,AUC越接近1,算法模型性能越好。

3 预测算法构建
在整个客户流失预测方案中,预测算法是核心。现有的电信客户流失分类预测模型最早采用基于决策树的ID3算法对离散型数据进行分类,其后C4.5算法使用连续属性离散化的方法对ID3算法做了改进,增加了对连续属性的分类,之后大量学者使用随机森林算法进行流失潜在客户预测[12]。
本文预测方案拟改进传统的随机森林算法,提出多决策树合并的随机森林算法(Trees Merge Random Forest,以下简称TMRF),以保持预测整体性能的前提下,减少算法模型的存储与计算时间开销。TMRF 算法分为两个阶段:(1)由传统随机森林中对分类精度较高的决策树进行约简、合并,得到高精度子森林;(2)使用K-Means++聚类算法对高精度子森林进行聚类[13],从中过滤出高精度且低相似的决策树组成新随机森林。TMRF 算法流程如图3所示。
3.1 选择高精度子森林
首先利用验证集计算原始森林的所有决策树AUC值作为各决策树的分类精度,并进行降序排序。按现有研究经验选择前67%(约总决策树的2/3),本算法拟选取精度高于随机森林平均值的所有决策树作为子森林SubT,如公式3所示,其中Auci为第i棵决策树ti的AUC 值。
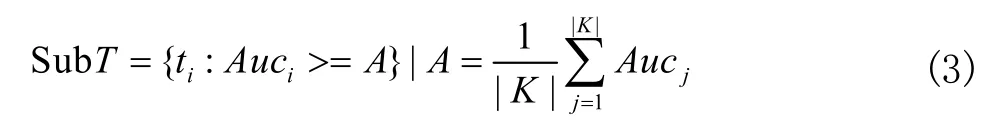
如图3所示,高精度子森林约简过程为:(1)使用自举(Bootstrap)抽样有放回地从训练集D中抽取K个子集;(2)对K个训练子集进行决策树算法训练基分类器模型;(3)使用验证数据集V 的样本对K 个决策树进行分类,并计算其AUC值;(4)对各树AUC值进行降序列排列,取得高于AUC平均值的高精度子森林集SubT。
3.2 K-Means++过滤出低相似随机森林
通过上一阶段,去除了分类能力差的决策树,但留在子森林集合SubT中的高相似决策树仍然未得到优化,会影响造成预测算法计算时间过长。为此,使用聚类算法完成高相似随机森林的合并:(1)将上阶段的SubT随机森林对验证样本的分类结果作为数据集D={x1,x2,…,xm},从D中随机选取k个样本作为初始质心向量{u1,u2,…,uk};(2)遍历数据集D,根据公式4计算各xi到质心向量μj(j=1,2,...k)的距离,将数据划分到最近的中心组成类簇;(3)根据公式5更新各类簇的中心值uj;(4)重复2)与3)步骤,直至各类簇中心稳定;(5)计算不同K值 下各类对应的轮廓系数s(见公式6,disMeanin为该样子与本类其它样本的平均距离,disMeanout为该样本与非本类样本的平均距离),确定合适的K值与聚类结果;(6)从各类簇中选择代表性的决策树组成随机子森林。

4 方案验证与应用
4.1 数据说明
本预测方案的验证源数据来自广东省某市级电信运营商公司的自建Hadoop大数据平台,该数据平台共计170多个分布式计算节点,存储容量达到4.9PB、2700核CPU、12T内存计算资源,已经完成OSS、BSS、宽带访问记录、通话记录等多个数据源整合,并以全网唯一标识号以索引建立220 余万以客户为维度的326 维网络行为特征的抽取。目前能支撑全市在网客户的流失预警、智能交通、精准投放、场景营销等场景应用。
为了有效地验证我们的预测方案,我们从中选取2019年网络行为特征值相对较完整的客户,共计476485人(全网唯一标识号)。由于客户流失行业具有一定的延时性,因此我们以对算法的训练规则为:以第N 月数据为输入,观察其后三个月是否流失为输出建模,如图4 所示。这是一个经典的二分类决策建模问题。
实验选取2019年1-6月数据作为训练数据集,7-12月数据作为验证数据集。1-3月的特征数据进行TMRF算法训练,对其后3个月2-6月是否流失进行建模预测,如图4所示。最后将2020年7-9月的客户特征数据输入到模型,以8-12月的在网客户数据进行验证。这样保证了建模数据与验证不存在干扰的可能。
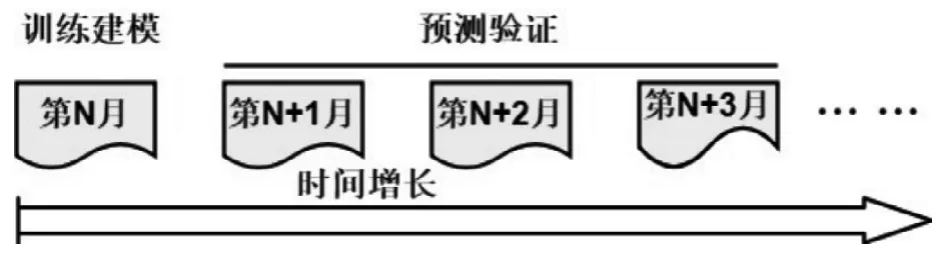
图4 预测模型示意图Fig.4 Schematic diagram of prediction model
4.2 训练和评估
我们针对训练数据集进行多次训练,通过对训练结果反复验证和评价经验,选择将初始随机森林规模设置为300颗树,采样方法为Bootstrap,初始树的最大深度为19层,叶子最小样本数242个;经过高精度子森林的约简后与K-Means++聚类后,得到SubT随机森林为84颗,最大深度为16,叶子最小样本数756个。
为了验证基于TMRF 算法的有效性,我们同样在将C4.5与传统随机森林对训练数据进行训练建模,并在7-12月验证数据集验证后进行整体性能比较。如图5所示,三种预测算法在随时间推进(7-9月预测),精确率、召回率及F1-score值相对平稳,说明TMRF算法经过训练生成模型后固化性高,各项评估指标相对稳定,短期内应用无需反复训练。
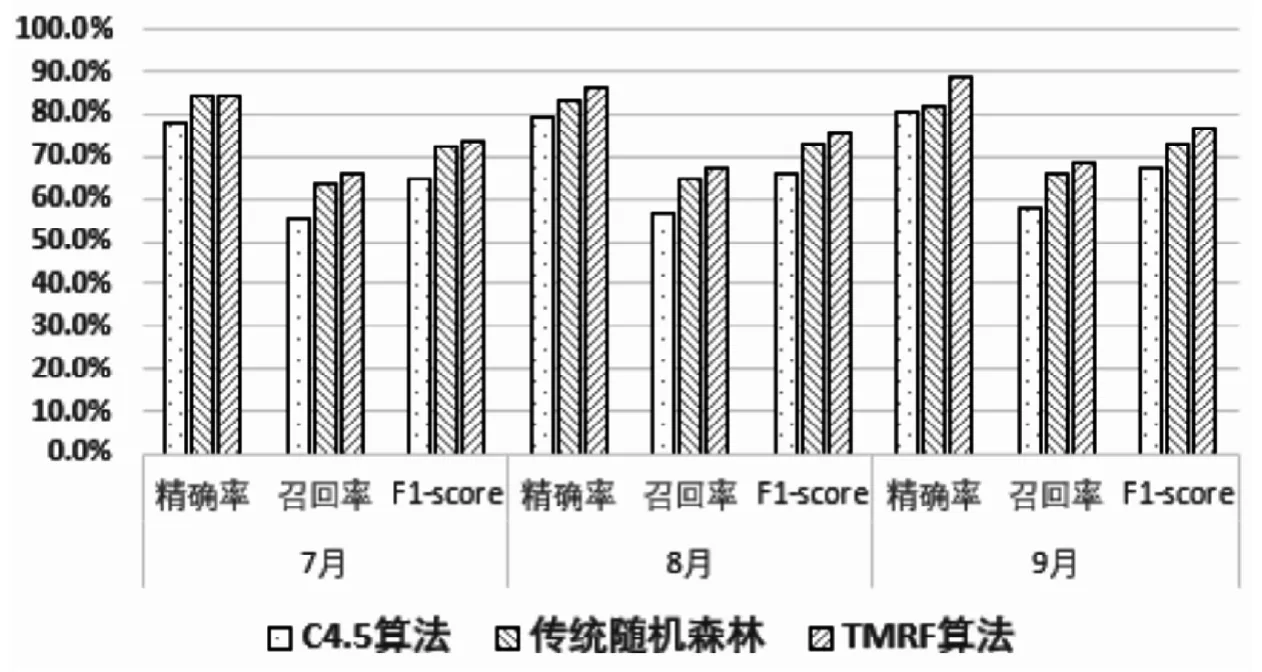
图5 三种预测算法性能指标图Fig.5 Performance index chart of three prediction algorithms
我们将三个月的预测结果的整体数据进行汇总统计,如表3 所示可知,TMRF 算法在精确在各项性能指标方面比两种传统预测算法上有了较大提升。

表3 客户流失预测结果汇总统计表Tab.3 Summary statistics of customer churn forecast results
最后,我们绘制ROC曲线图直观地对比三种预测算法的结果,如图6所示。从图可知C4.5、传统随机森林算法、TMRF算法的AUC值分别为79.5%、83.6%、88.7%。TMRF算法较之C4.5算法与传统随机森林算法的AUC值分别提高了9.2%与5.1%,在AUC值上,使用改进后的随机森林是最优的模型。

图6 三种预测算法ROC 曲线图Fig.6 ROC curves of three prediction algorithms
4.3 方案应用
我们对流失客户进行根因分析,发现流失客户具有故障申诉不及时、异网社交圈比例小、流量使用趋势下降、通话时长趋势下降、套餐即将到期、周末移动网上网时长低等标签。将这些流失客户的标签属性与本模型预测结果相结合,有利于电信运营商更有针对性地制定客户挽留策略,并精准锁定潜在流失客户并开展挽留工作,既能节约人才物力,又能减少对无离网意向客户的打扰。
5 结语
本文系统地分析了大数据挖掘技术在电信客户流失预测中应用现状与客户流失预测方案的建立过程,并在方案中使用决策树约简与K-Means++聚类的方法改进了传统随机森林算法,获得到高精度、低相似的TMRF 随机森林预测算法。最后,通过某市电信运营商大数据平台的真实数据进行预测方案的验证,我们发现:TMRF 算法用于客户流失预测较C4.5与传统随机森林在精确率、召回率、F-score值及ROC曲线等指标上表现更为优异。基于TMRF 算法的预测方案得到的预测结果对电信运营商开展客户服务质量提升与潜在流失客户挽留工作具有较好的指导意义。
后续我们的预测建模工作将集中在两个方面[14]:(1)由于采集数据的限制,本文的基础数据源未包含移动网络信令数据、定位数据等,针对移动用户流失的预测能力尚有提升空间;(2)使用优化的人工神经网络等深度学习技术进行流失预测建模对比。
