大数据环境下基于决策树算法的人才招聘系统优化研究
2021-06-01
(深圳职业技术学院,广东深圳 518055)
统计显示,最近五年,我国高校毕业生人数连年猛增,2021届高校毕业生将突破900万人,人数再创新高。规模增长必然使就业形势更加严峻,传统招聘方式渠道众多,需投入大量的人力审核简历,且审核结果容易受影响。招聘结束后,简历大量沉淀,人才库利用率低。因此,提高招聘系统处理海量数据的能力,亟待解决。
另一方面,招聘过程中面临的最大挑战之一,是将招聘目标锁定在合适的候选人身上。寻找一个合适的候选人并邀约面试,需要花费3~5天时间,面试时间一般在30分钟到1 小时,而后续的跟进周期更长。利用大数据的分析和人工智能技术[1],高效的找到合适的候选人,也是招聘系统必须解决的问题。
本文将采用大数据平台Hadoop及决策树算法,实现招聘系统自动快速、精准地筛选出候选人信息。利用Hive工具,建立人才数据仓库,对应聘者的数据做深层次分析,从而提高科学识人的水平。
1 相关模型
1.1 Hadoop
Hadoop是一个开源的分布式系统基础架构,它在分布式环境下提供了海量数据的处理能力。Hadoop主要有以下几个重要组成部分,分别为HDFS(分布式文件系统)、MapReduce(计算框架)、HBase、Hive等组件[2-3]。
Hive设计了SQL语句查询功能,能透明地将select、insert等SQL语句翻译为MapReduce任务来执行。Hive可以实现快速MapReduce统计,简化了MapReduce程序设计,可以处理大数据的统计分析,降低了处理数据仓库的使用门槛[4]。
1.2 决策树
常用的分类算法包括决策树、贝叶斯、神经网络、K近邻、支持向量机等。决策树是非常广泛的分类算法,其中C4.5算法是比较成熟的算法[5]。C4.5算法使用信息增益率来判断最佳分支属性,能较好地处理非离散数据属性。
2 招聘系统设计
传统的招聘系统主要包含了职位发布管理、应聘者投递简历、简历筛选等模块。对管理者而言,筛选简历是最繁重的工作,尤其是竞争激励的职位,达到上千人应聘。通过大数据、数据挖掘等技术手段,可以明显地提高简历筛选的效率。
2.1 数据源
通过分析处理简历库中的历史数据[6],以决策树为手段,可以准确、高效地筛选简历,本文采集了2017年至2020年每年的招聘系统数据。主要数据如表1 所示。

表1 招聘系统简历库数据表Tab.1 Resume database data table of recruitment system
2.2 建立基于Hive的数据仓库
(1)首先,分别启动Hadoop、Hive。
(2)在Hive中创建分区表[7]。使用Hive查询,一般会遍历整个表内容,当数据量过大时,查询效率明显降低。在建表时引入了分区(partition)概念。Hive分区表对应一个分布式文件(HDFS)系统上的单独的文件夹,该文件夹下存储的是对应分区所有的数据文件。当查询时,通过查询某些子目录中的数据,能加快数据的检索速度和对数据按照一定的规格和条件进行管理。创建分区表时,要调用可选参数partitioned by实现。
例如:创建基本信息分区表如下,其他表如同。
create table BasicInformation (
id string comment 'ID',
name string comment '名字',
sex string coment ‘性别’,
……
)
partitioned by (InforDate string comment '按日前分区')
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
(3)将招聘系统人才库数据按照时间为分区导入到Hive数据仓库。导入数据采用Sqoop工具,该工具是Apache旗下的数据传送工具,它能方便地让数据在Hadoop和关系数据库之间传输。它主要的功能是导入和导出,如图1所示[8]。
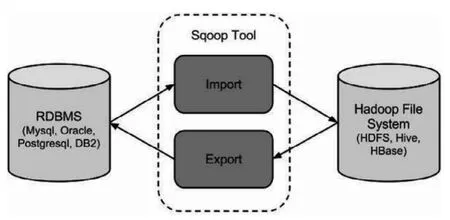
图1 Sqoop 处理数据过程图Fig.1 Sqoop processing data process diagram
Sqoop导入过程如下:
第一步:将Mysql的表数据导入到HDFS;
第二步:根据Mysql的表自动模拟创建Hive表,默认情况下存放到default库中;
第三步:将临时文件中的数据导入到Hive表中。
2.3 基于Hive的C4.5算法
每次的招聘信息定期存入数据仓库,随着数据的不断增加,传统的C4.5算法难以处理[9],可以通过Hive数据仓库的Select操作,查询训练集集合中各属性的信息增益情况。基于Hive的C4.5算法如下:
输入:从数据仓库中获取训练数据集D,特征集记做A,阈值计为ε;
输出:决策树T
步骤1:如果训练集D 中所有实例属于同一类属性Ck,则T 为单结点树,并将属性Ck作为该结点的类标记,返回T;
步骤2:若A=Φ,则T为单结点树,并将D中实例数最大的类Ck作为该结点的类标记,返回T;
步骤3:否则读取Hive数据仓库,统计属性信息,计算特征集A 中各特征对数据集合D 的信息增益率,选择信息增益率最大的特征Ag;
步骤4:如果Ag的信息增益率小于阈值ε,则置T为单结点树,并将D 中实例数最大的类Ck作为该结点的类标记,返回T;
步骤5:否则,分别读取Hive数据仓库中Ag的每一个取值Agi对应的类别Di统计信息,每个类别产生一个子节点,对应特征值是Agi,返回增加了结点的树;
步骤6:对所有的子结点,以Di为训练集,以A-Ag为特征集,递归调用(1)-(5),得到子树Ti,返回Ti。
2.4 招聘系统模型设计
优化后的人才招聘系统主要包括职位发布、应聘者在线投递简历、建立Hive数据仓库、生成基于Hive的C4.5决策树,智能简历筛选几个核心部分,工作流程模型如图2所示。
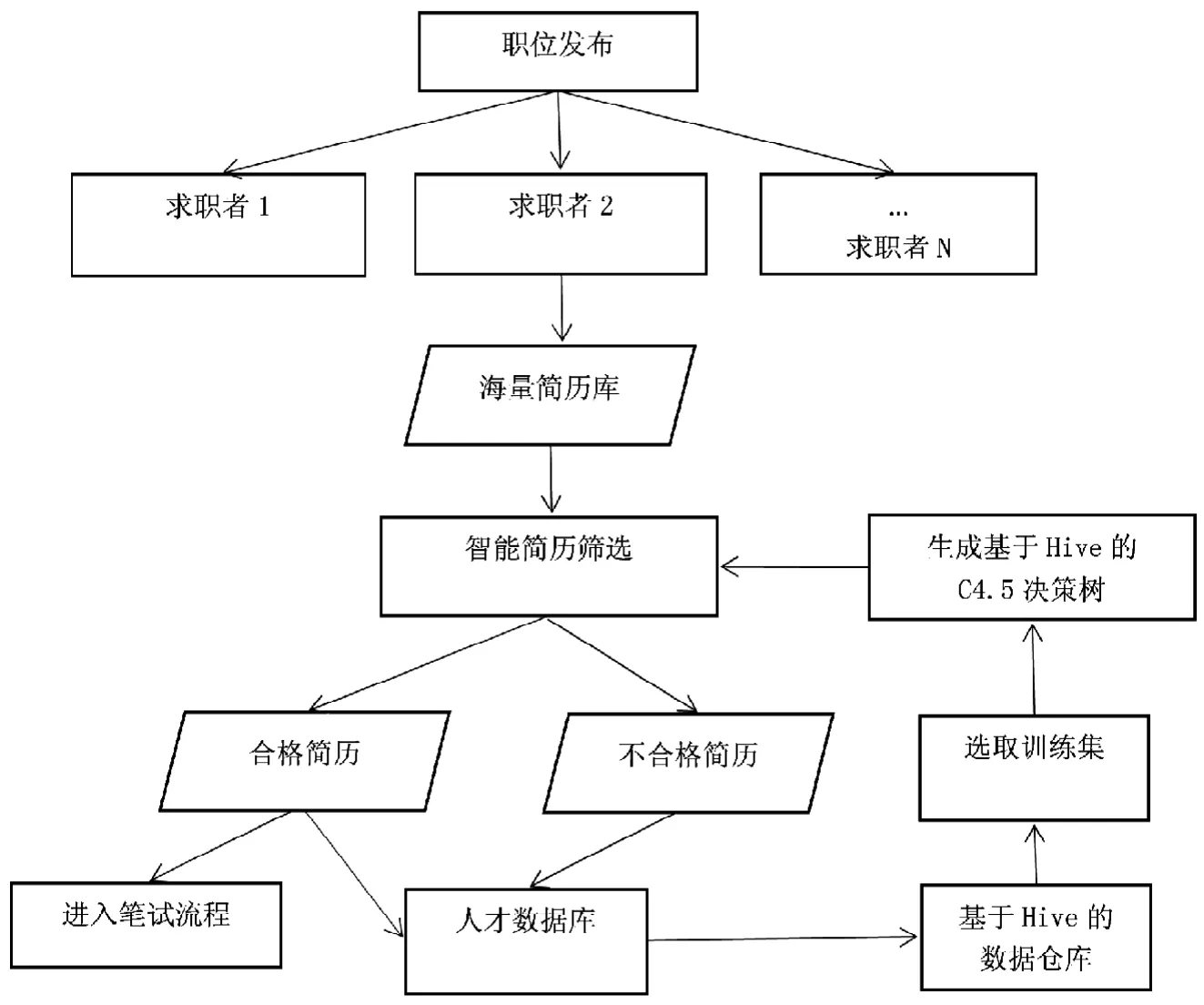
图2 优化后的招聘系统流程图Fig.2 Flow chart of the optimized recruitment system
职位发布:主要包括设置各岗位名称、学历、专业技术资格、工作经历等模块。
应聘者在线投递简历:根据每个招聘岗位的要求,需要应聘者填报不同的信息,具体信息见数据源章节。
智能简历筛选[10]:以原有招聘系统2017年至2020年的简历数据为基础,建立人才数据仓库。首先通过选取性别、出生日期、籍贯、婚姻、参加工作日期、专业技术职务等级信息、论文数等属性从数据仓库抽取训练集数据,其中训练集数据以是否进入笔试为分类结果。从抽取的数据中选取总量的80%为训练集,20%为测试集,从而提高决策树的正确率[11]。
3 结语
原有招聘系统存储了大量的应聘简历,随着数据的不断积累,通过单一的数据库存储方式难以利用。文章以Hadoop 平台的强大数据存储及计算能力为依托,使用Hive建立数据仓库,增强了数据分析能力。通过对数据仓库中的关键信息提取,构建人才属性测试集,用C4.5算法建立的决策树进行简历筛选,协助HR 完成招聘流程,降低时间成本,节省招聘支出,提升工作效率。
