一种基于前馈序列记忆神经网络的改进方法
2021-05-28梁翀刘迪浦正国张彬彬
梁翀,刘迪,浦正国,张彬彬
一种基于前馈序列记忆神经网络的改进方法
梁翀1,刘迪2,浦正国1*,张彬彬1
1. 安徽继远软件有限公司, 安徽 合肥 230088 2. 国网信息通信产业集团有限公司, 北京 102211
针对具有时序性的信号的分析和建模,主流的RNN、LSTM由于反馈连接的影响,在学习效率和稳定上有所不足。本文基于标准的前馈神经网络,借鉴滤波器中的抽头延迟线结构,提出一种改进的前馈序列记忆神经网络FSMN(cFSMN)和深层cFSMN(Deep-cFSMN),实现时序的音视频信号快速建模,减少了反馈连接,具有更高的学习速率和更好的稳定性。
前馈序列记忆神经网络; 改进方法
深度学习的发展推动人工智能的兴起,而深度学习的发展离不开神经网络[1,2],其中应用最广泛的是前馈型神经网络[3,4]和卷积神经网络[5,6]。对非结构化数据(文本、语音和视频)这些时序性信号,如何有效地对这些时序信号的长时相关性进行建模就显得尤为重要。因此,先后出现循环神经网络RNN、前馈全连接神经网络FNN和LSTM等不同的神经网络。循环神经网络RNN[7]通过循环反馈机制,将学习到的历史表达存储在网络的权重中,从而实现对时序信号进行建模,而RNN由于其记忆存储机制理论上可以实现任意长度的序列到另一个序列的映射[8],由于其内部的反馈连接,训练需要采用所谓的BPTT(Back-propagation through time)[9],BPTT会导致RNN的计算复杂度很高,而且会导致梯度消失和梯度膨胀。长短时记忆单元(Long Short Term Memory, LSTM)[10,11]是一种增强型的RNN结构,选择学习的门来替代循环连接,从而可以确保训练过程中梯度的传递更加有效,并在序列建模[12]、机器翻译[13]、语音识别[14]等任务上取得一定突破。虽然在时序信号的建模问题上,LSTM、RNN等神经网络取得一定的效果,但受制于反馈连接的影响,在学习效率和稳定上有所不足,本文针对上述问题,基于标准的前馈神经网络,并模仿滤波器中的抽头延迟线结构,提出一种比LSTM、RNN学习效率高和稳定的神经网络,快速对时序的音视频信号建模,减去了反馈连接,并命名为前馈序列记忆神经网络(FSMN, Feed-forward Sequential Memory Network)。
1 改进的FSMN网络结构
1.1 简洁的前馈序列记忆神经网络
在低维度的线性投影层上添加记忆模块,减少额外参数数目,改进标准的FSMN结构,形成第层为cFSMN-layer的cFSMN(如图1)。
进一步简化模型的结构,减少参数复杂度和计算量,如1图所示,以cFSMN-layer中Memory Block的输出当做下一层的输入,具体公式如下:
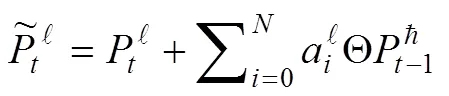
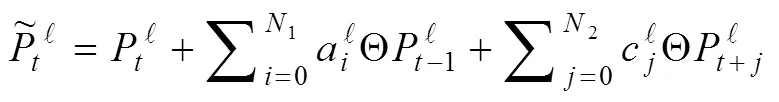
1.2 深层的前馈序列记忆神经网络
传统的矩阵低秩分解多层的cFSMN,导致层数过多(4个cFSMN层以及2全连接层,最后的层数将达到12层),带来梯度消失的问题,训练存在很大的不确定因素。引入跳转链接(如图2)的深层cFSMN结构,实现低层记忆模块的输出向高层记忆模块叠加,解决深层的cFSMN梯度消失的问题的同时不引入多余参数。

图 1 cFSMN的网络结构示意图
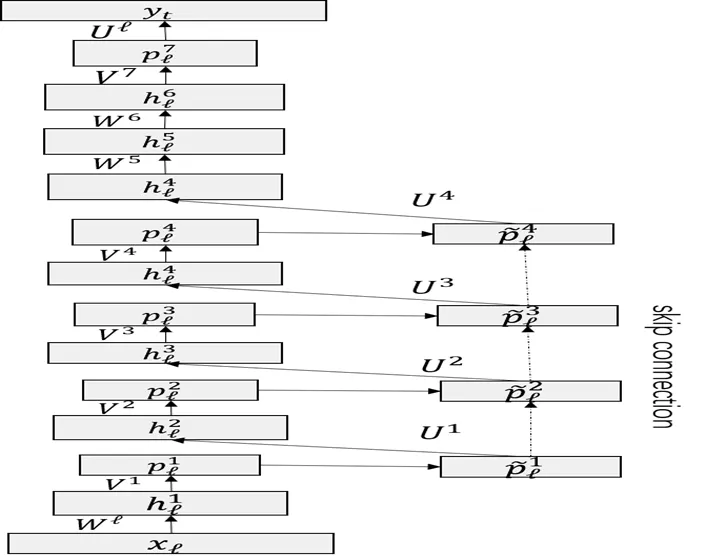
图 2 基于快捷连接的深层cFSMN结构框图
从时序信号的特性(相连时刻信息相似),基于扩张卷积的思路,引入步幅因子到记忆模块。计算如下:

2 结果分析
本文改进的神经网络是为了解决时序信号的建模效率低与不稳定的问题,为了验证本文改进算法在建模的训练效率与稳定性方面优势。本文设计相同实验条件和相同评价标准要求下,针对语音识别声学建模Switchboard (SWB)和Hsher (FSH)任务以及语言模型建模PTB和Wiki9任务等常见任务,给出常见算法与本文改进算法在词错误率(Word Error Rate,WER)评价指标上的对比。
在相同的SWB数据库上,对比不同声学模型的迭代训练时间。以交叉熵(CE)准则为判断依据,在相同的硬件配置条件下训练,本文选择单Nvidia Tesla K20 GPU。实验结果见表1,LSTM和FSMN等有效对长时相关进行建模的模型训练效果更优化,显著提升DNN性能。前者耗时9.4 h,而BLSTM耗时长达23.7 h。这是由于两种算法的并行代价资源不同,受限计算资源的配置,BLSTM只能16句话,而LSTM则可以达到64句。改进的vFSMN的效果稍微优于BLSTM。这是由于其结构简单,耗时仅需要6.7 h,速度提升3倍较与BLSTM。然而vFSMN的参数复杂度比BLSTM小了一个量级,这一方面,cFSMN更优,参数减少到74 MB,仅有BLSTM参数量40%。其耗时低到3.1 h,训练加速达到BLSTM的7倍多,且12.5%的词错误率,比BLSTM的0.9%有10倍多的提升。

表 1 不同声学模型的训练模型参数量、训练时间和效果的对比
对比不同配置下的深层cFSMN的性能,引入表达式:216-×[2048-(_1,_2)]-×2048--8991表示模型,其中和的不同,表示cFSMN-layer和标准全连接层的数目的不同,而代表线性投影层节点数目。_1,_2分别代表向前和向后的滤波器阶数。对于相同的值的模型可以用(,_1,_2)来区分模型。在表2中前两次实验对比应用式(3)的Memory Block编码计算,设置较大步幅,实现更长远的上下文信息的检测,得到更优的性能。在后续实现增加cFSMN-layer层的数目,发现性能逐渐提高,添加跳转连接,训练深层cFSMN(含有12个cFSMN-layer和2个全连接层),即Deep-cFSMN,基于Hub5e00数据集达到9.0%的词错误率。

表 2 不同配置跳转连接训练深层cFSMN声学模型的性能(基于FSH任务)
3 结 语
本文基于标准的FSMN,改进出简洁结构的FSMN(cFSMN)和深层cFSMN(Deep-cFSMN).对于声学模型训练(SWB)任务的实验,发现cFSMN的性能优于BLSTM。且在FSH任务深层的cFSMN随着隐层数目的递増,模型性能提升越好,但复杂干扰情况(噪音、远场)下的识别性能还不稳定的问题还有待解决。
[1] Lecun Y, Bengio Y, Hinton G. Deep learning [J]. Nature, 2015,521(7553):436-444
[2] Schmidhuber J. Deep learning in neural networks: an overview [J]. Neural Network, 2015,61:85-117
[3] Dahl GE, Yu D, Deng L,. Context-Dependent Pre-Trained Deep Neural Networks for Large-Vocabulary Speech Recognition [J]. IEEE Transactions on Audio, Speech and Language Processing, 2012,20(1):30-42
[4] Hinton G, Deng L, Yu D,. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups [J]. IEEE Signal Processing Magazine, 2012,29(6):82-97
[5] Krizhevsky A, Sutskever I, Hinton G. ImageNet Classification with Deep Convolutional Neural Networks [C]. NIPS. Curran Associates Inc. 2012
[6] 张晴晴,刘勇,王智超,等.卷积神经网络在语音识别中的应用[J].网络新媒体技术,2014,3(6):39-42
[7] 王龙,杨俊安,陈雷,等.基于循环神经网络的汉语语言模型建模方法[J].声学技术,2015,34(5):431-436
[8] Meng FD, Lu ZD, Tu ZP,. Neural Transformation Machine: A New Architecture for Sequence-to-Sequence Learning [J]. Computer Science, 2015:1-13
[9] Werbos PJ. Backpropagation through time: what it does and how to do it [J]. Proc IEEE, 1990,78(10):1550-1560
[10] 金宸,李维华,姬晨,等.基于双向LSTM神经网络模型的中文分词[J].中文信息学报,2018,32(2):29-37
[11] 张晓.基于LSTM神经网络的中文语义解析技术研究[D].南京:东南大学,2017
[12] Graves A. Generating Sequences with Recurrent Neural Networks [J/OL]. arXiv:1308.0850 [cs.NE], 2013
[13] Cho K, Van Merrienboer B, Gulcehre C,Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation [J/OL]. arXiv:1308.0850 [cs.NE], 2014
[14]Sak H, Senior A, Beaufays F. Long Short-Term Memory Based Recurrent Neural Network Architectures for Large Vocabulary Speech Recognition [J/OL]. arXiv:1308.0850 [cs.NE], 2014:338-342
An Improved Method Based on Feedforward Sequence Memory Neural Network
LIANG Chong1, LIU Di2, PU Zheng-guo1*, ZHANG Bin-bin1
1.230088,2.102211,
For the analysis and modeling of sequential signals, the mainstream RNN and LSTM have some shortcomings in learning efficiency and stability due to the influence of feedback connection. Based on the standard feedforward neural network and the takeout delay line structure in the filter, this paper proposes an improved feedforward sequential memory neural network fsmn (cfsmn) and deep cfsmn (deep cfsmn) to achieve sequential sound. Video signal fast modeling reduces feedback connection, has higher learning speed and better stability.
Feedforward sequential memory network; improved method
TP183
A
1000-2324(2021)02-0313-03
10.3969/j.issn.1000-2324.2021.02.028
2019-01-05
2019-03-06
国家电网有限公司总部科技项目:基于机器学习的智能文档自动编制关键技术研究与应用(No.52110418002X)
梁翀(1992-),男,硕士,工程师,主要从事电力行业信息化系统体系架构设计、研发以及智能语音和图像识别研究等工作. E-mail:liangchong@sgitg.sgcc.com.cn
Author for correspondence. E-mail:1144187870@qq.com
网络首发:http//www.cnki.net
