基于LLVM 的Android 应用程序加固方法
2021-05-28江秋语殷芙萍
江秋语,殷芙萍
(1.四川大学计算机学院,成都610065;2.上海理工大学管理学院,上海200082)
0 引言
Android 平台的开源特性使它在全球智能手机市场占据主导地位[1]。然而,近90%的Android 应用程序中存在重打包的现象,严重侵犯了开发者的知识产权。由于Java 类文件和DEX 文件保留了大部分的语义信息,攻击者使用逆向工具可以轻而易举地进行破解以获取程序的源代码。
为解决此问题,常用混淆技术对Android 应用程序进行加固。代码混淆技术是一种代码转换机制,通过将易读的代码或数据进行保留语义的转换、重组和整理来加大代码分析难度,达到保护软件安全的目的。但是对Java 代码进行混淆会大大降低程序的性能,为了解决这个问题,本文提出了一种基于LLVM 的Android应用程序的混淆方法,利用LLVM 将DEX 文件中的Java 函数转化为本地代码,相比于Java 代码,本地代码具有更少的语义信息和更快的加载速度,能有效增加攻击者分析的难度,减少混淆带来的性能损失。
1 相关工作
近年来,由于本地代码具有更少的语义信息和更快的加载速度的特点,Android 应用保护的研究方向也逐渐转向本地代码的保护,研究人员开始结合代码混淆技术和虚拟化保护方法来保护Android 应用中的本地代码。
Vivek Balachandran 等人[2]提出一种针对Java 层代码的混淆保护方法,利用切片技术将函数划分为多个代码片段,通过pack 和switch 指令将代码片段的控制流平展,同时插入垃圾代码扩展分支语句来增强其控制流复杂程度,为了防止符号执行方法恢复混淆后的控制流,使用try 和catch 指令来隐藏控制流的跳转。但仅仅增加控制流的复杂程度不能很好地增加攻击者分析的难度,而且对APK 内所有基本块进行切片并进行混淆会导致很大的性能开销,因此只能选择部分关键函数进行保护。
Kyeonghwan Lim 等人[3]进一步提出针对Android 本地代码的保护方法,通过将Android 字节码以更安全和高效的形式保存在本地代码中并使用OLLVM 来对其进行混淆,以增强代码最终的安全性,但是近年来有很多针对OLLVM 的反混淆研究,仅仅使用OLLVM 进行混淆保护不能很好的增加攻击者分析的难度,因此需要增加混淆方式的多样性和复杂性以便更好的保护Android 应用程序。
赵贝贝等人[4]提出了针对DEX 文件和SO 文件的多重虚拟化保护方法,通过将DEX 文件中的部分函数转化为本地层函数,然后分别对其和SO 文件进行指令的虚拟化,大大增加的逆向分析的难度。由于虚拟化保护技术需要将被保护代码全部转化为自定义的虚拟指令,然后在运行的时候根据自定义的解释器逐条翻译虚拟指令,这样会大大降低Android 应用程序的执行效率。
综上所述,现有的Android 应用程序保护方法能够在一定程度上提高程序的安全性,但是仍然存在性能开销过大和无法有效抵御动态攻击的问题。
2 具体实现
图1 描述了本文所提Android 应用程序加固方法的五个步骤:首先是关键函数的提取,通过一个决策模型选择被保护函数,将其反汇编为Smali 代码;再对Smali 代码进行解析,将其转化为同语义的C++代码;接着由LLVM[5]前端Clang 解析、验证和诊断输入的C++代码;然后通过编写LLVM 中端的优化模块完成对LLVMIR 的优化、转换、混淆[6]等一系列自定义操作,将优化后的指令转化为本地代码;最后将修改后的DEX文件和LLVM 后端生成的本地代码重新打包为一个新的APK 文件。下面介绍一些关键技术的具体实现,如选择关键函数、关键函数的转化、控制流混淆、不透明谓词混淆、整型数和字符串混淆。
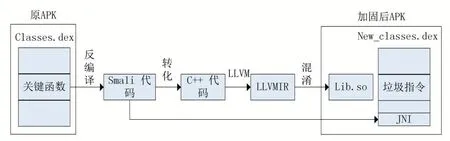
图1 本文所提加固方法的主要流程
2.1 选择关键函数
对所有Java 层函数进行加固会造成巨大开销[7],部分函数的程序框架,如窗口操作和界面渲染,已经被业内人士所熟知。相比于核心加密和通信逻辑的函数,这些函数本身调用了许多其他函数,无需浪费额外的资源对其进行加固,因此本文构建一个决策模型识别DEX 文件中的关键函数:
首先深度优先遍历反汇编后的Smali 文件,生成每个函数的函数调用树;其次选择树中的叶子节点,也就是不存在函数调用的函数,将函数名添加到被保护函数列表中,修改函数属性为Native 类型;最后删除原函数体并添加无用的垃圾指令来影响攻击者逆向分析。
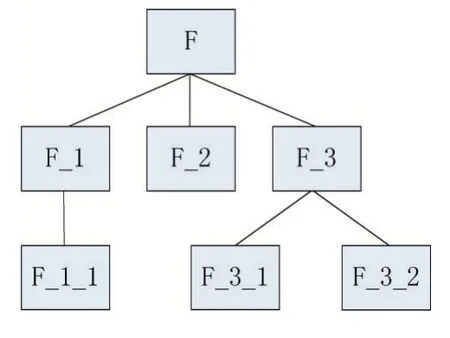
图2 函数F调用树
2.2 关键函数的转化
将关键函数转化为C++代码通过指令逐条翻译和程序语义恢复实现。
指令逐条翻译:图3 是一个函数反汇编生成的Smali 代码,Smali 是基于寄存器的指令,由于同一个寄存器一般储存多个不同类型的变量,因此在翻译每一条指令时要对寄存器里的值进行区分。将Smali 指令逐条翻译后如图4 所示:为每一个寄存器操作分配一个新的临时变量来翻译指令,当该寄存器进行赋值操作后,用一个新的临时变量替代之前的临时变量。

图3 Smali 指令
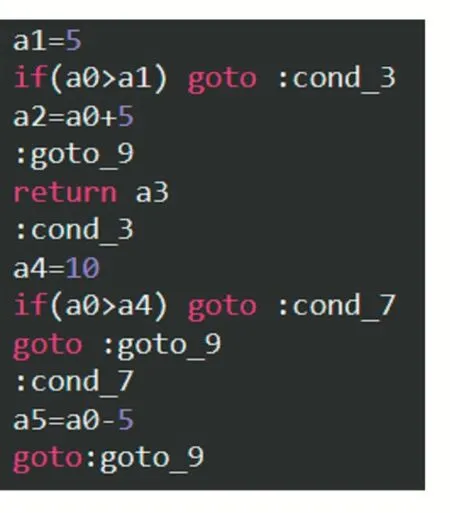
图4 C++代码
程序语义恢复:构建一个以每一条指令作为一个节点的指令图,深度优先搜索图中的每一个节点,根据每个节点的前驱节点和后继节点以及节点的出度和入度,删除不必要的变量并增加新的变量关联,恢复程序正常的逻辑关系和上下文。
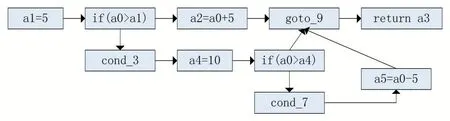
图5 C++代码的指令图

图6 优化后的C++代码
2.3 控制流平坦化
控制流图[8]是程序的抽象表现,图中每一个节点代表一个基本块。控制流平坦化将程序的控制流图转化为一个有很多分支的switch 结构,通过替换程序中的循环判断条件和计数器,将程序的跳转过程集中在switch 的判断语句。一个函数的原始控制流图,包含一些变量的赋值和一个循环,如图7 所示。图8 是对其进行控制流平坦化后的控制流图,通过变量V 来控制程序的执行,每执行完一个基本块后,对V 进行赋值操作来决定下一个要执行的基本块。
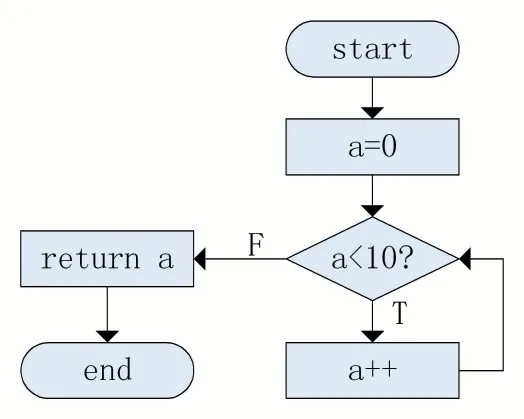
图7 函数的原始控制流图
实现流程如下面的伪代码所示:遍历函数中所有的基本块,选择第一个基本块作为函数的入口,若是有条件的基本块,则将其转为一个无条件的基本块和一个有条件的基本块,并将无条件的基本块作为程序的入口;为每一个基本块分配一个唯一的编号,并修改其结尾的跳转指令,若当前基本块为非条件跳转,将变量V 的值赋值为要跳转的基本块的编号;若当前基本块为条件跳转,则需要修改为两个条件赋值指令。最后,将基本块插入到switch 结构中。
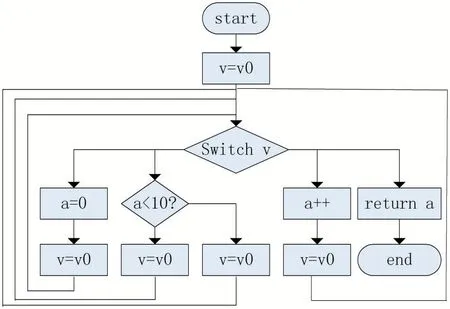
图8 控制流平坦化后的控制流图

图9 伪代码
2.4 不透明谓词混淆
不透明谓词[9]是一种布尔表达式,其结果为真或者为假。攻击者只有在程序执行到一定阶段才能利用逆向工具对它进行分析,因此不透明谓词混淆可以抵御大部分静态攻击,本文选择数论的结论来生成不透明谓词。
实现过程如下:对基本块进行拆分,直到每个基本块都无法再被拆分,向前驱基本块插入一个无条件跳转指令指向其后继基本块,以保证程序的正确运行;生成一组不透明谓词(pi,i=1,2,…,n,其中任意一个pi 的值为真时,其他所有不透明谓词的值都为真)将其插入到拆分后的基本块中,如图10 所示。
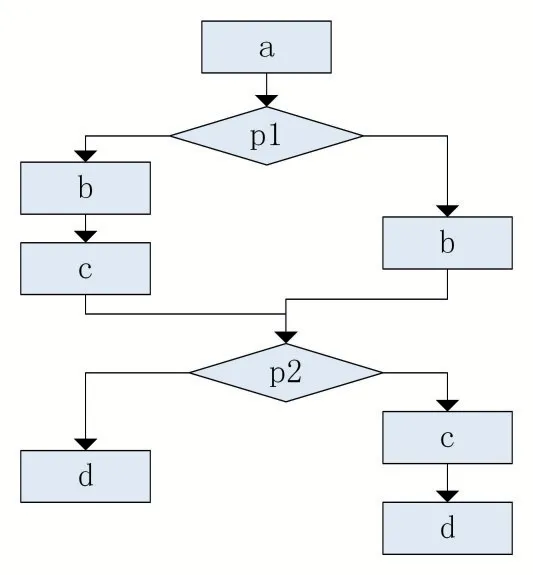
图10 不透明谓词混淆
2.5 整型数替换
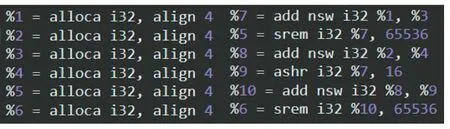
整型数替换相比于加密优势在于,加密后的数据在内存中运行时解密,很容易被攻击者发现并利用,而混淆后的数据在内存中保持原有的形式,攻击者难以理解。整型数替换的原理是将一个整型数拆分为高位和低位长度相同的两部分,分别储存在寄存器中并对整型数的基本运算进行替换。例如,可以将一个长为2N 的整型数A 拆分为长度均为N 的Ah(高位)和Al(低位)。
对于加法运算A=B+C,
Al=(Bl+Cl)mod(1< 对于减法运算A=B-C, Al=(Bl-Cl)mod(1< 对于比较运算,只需要先比较高位,若不相等则不需要再比较低位。 对于位运算,只需要同时对高位或低位进行相同的位运算操作即可。 对于移位运算A=B>>x, 其中0 对于除法和乘法运算,LLVM 在编译器优化过程会对乘除法指令进行替换,转化为由移位和加法等指令等价表示的形式,由于乘法和除法的拆分会造成很大的开销,因此不对存在乘法和除法的代码进行整型数的拆分。 LLVMIR[10]使用了一个由%字符命名的无限寄存器集合,而不是一个固定的命名寄存器集合。整型变量的表示一般以i 为起始标志,i32 表示32 位整型数,all⁃oca i32 指令用于分配32 位长度的整型数变量。例如加法运算A=B+C,%1、%2、%3 分别用于储存A、B、C的值,然后将B 和C 的值读取出来,相加后储存到A中;其进行整型数拆分的结果如图11 所示,分别使用两个寄存器储存A、B、C 的值,首先是低位相加,再对65536 取模,完成低位相加,然后是高位相加的结果和低位和右移16 位的结果相加,最后对65536 取模完成高位相加。 图11 混淆前的LLVMIR 图12 混淆后的LLVMIR 代码中hashcode 的字符串可以在生成的binary 中查找到,因此增加破解的难度对字符串进行混淆很重要。常用方法是在编译过程中使用密钥对原字符串异或加密,然后在函数头部插入解密代码在运行时进行字符串解密[11],文件加载后,字符串在内存中仍是解密后的形式,因此,需要对字符串的解密进行隐藏。 实现过程如下:首先生成随机密钥对字符串异或加密,在函数要使用加密的字符串时调用解密函数。解密函数会首先申请一个与原字符串等长的栈空间,用于保存解密后的字符串,并修改原字符串的引用地址到当前栈的地址;字符串使用后会释放栈的空间,解密后的字符串不会一直存在内存中,能一定程度上抵抗动态攻击。 从手动分析、通用脱壳工具攻击和运行性能三个 方面进行测试。编译时系统使用Ubuntu 16.04 和LLVM 5.0 版本;测试端使用Android 5.0。 本部分主要以攻击者的角度,使用一些逆向工具来分析加固后的代码。首先,使用JEB[12]的工具反编译Android 应用程序。如图13 所示,可以看到未加固代码的逻辑是清晰可见,而加固后的代码在Java 层中只有方法的声明。攻击者再进一步的分析,结合Java 文件中的函数声明和从IDA[13]输出的伪代码,可以快速找到函数的实现,但是经过字符串和整型变量混淆以后,它们都没有完整的语义,导致攻击者很难理解。所以,攻击者想要获取应用程序的原始逻辑需要大量的时间和精力。 图13 原始代码反编译结果 图14 加固后代码反编译结果 本部分主要选择了六个常见的Android 脱壳工具,并使用它们来分析加固后的应用程序。DEXExtractor[14]原理是修改系统DVM 虚拟机模块代码DEXFile.cpp文件的DEXFileParse 函数,在系统调用DEXFileParse函数之前将原始DEX 文件从内存dump 出来。但是本文的方法已经将DEX 文件中的关键函数本地化,即使在内存中dump 出DEX 文件依然得不到函数的实现方式。Drizzledumper[15]原理是在root 环境下,通过ptrace附加需要脱壳的APK 进程,然后在脱壳的APK 进程的内存中进行DEX 文件头的特征搜索,当搜索到DEX文件时进行DEX 文件的内存dump。由于函数经过本地化保护后在内存中找不到DEX 头文件,因此这个工具对于本方法是无效的。ZjDroid[16]基于Xposed 框架,通过hook 每个应用进程在Java 级别获取DEX 文件并利用获得的mcookie dump 出DEX 文件,因此它无法在本地层还原代码。DEXHunter[17]原理是在Android 系统代码调用函数dvmDefineClass 进行类加载之前,主动地一次性加载并初始化DEX 文件所有的类。但它不能处理带有代码混淆和垃圾指令的加壳程序。Packer⁃Grind[18]从运行时跟踪、系统跟踪和指令跟踪对加壳的App 进行监控和分析,最后进行还原。本文对代码的控制流和数据都进行了混淆,不透明谓词产生的虚假控制流使它无法决定哪个代码是正确的。DROIDUN⁃PACK 可以对JNI 接口进行检查,进而知道哪些函数已经本地化,本文的方法对数据进行了混淆,使得它很难将其还原为正确的指令执行。 结果如表1 所示,DROIDUNPACK 是目前最强大的脱壳工具,但是对本文提出的方法无效。这是因为本文的方法将DEX 字节码编译时混淆成本机代码,在运行代码时动态还原并在使用后再次加密。实验结果表明,本文提出的加固方法克服了传统加固方法容易被还原的缺点,对通用逆向工具有良好的抵抗能力。 表1 脱壳工具以及对应的脱壳结果 本部分从CPU 占用率、大小和运行时内存使用率三个方面来评估加固前后程序的运行性能。选择了六个常见的Android 应用,每一个应用程序都要运行10次,取其结果的平均值作为最后的实验结果。在测试过程中,通过Monkey[19]触发随机点击、幻灯片、文本或字符输入模拟用户的行为,随机事件设置间隔为1s,每次数据收集的时间为10 分钟。最后使用腾讯的开源性能测试工具GT[20]获得了相应的实验数据,如表2所示。 CPU 使用率:可以看出,加固后程序的CPU 使用率与原应用程序几乎相同。 大小:从表中可以看出,所有加固后的应用程序比原应用程序约增加20%,原因是加固后的应用程序包含一个修改过的DEX 文件和一个新生成的SO 文件。虽然DEX 文件中的一些函数是在本机层中实现的,但它在原函数的指令中添加了JNI 注册信息以及一些垃圾指令,因此它比原函数要占用更大的内存空间,并且在一定程度上增加了攻击者逆向分析的难度。 内存使用:加固后,程序总内存使用量呈上升趋势,但增幅不大,增加的内存消耗主要来自本机代码的消耗。 综上所述,由于本机层代码直接执行效率更高、更直观的CPU 指令,使得函数的本地化提高了程序的运行效率、抵消了部分混淆带来的性能开销,因此加固前后程序的性能未受到很大影响。 表2 加固前后程序运行性能对比 本文提出了一种基于LLVM 的Android 应用加固方法,该方法将被保护程序中的Java 函数转化为本地代码并对其进行混淆保护,能够有效抵抗逆向软件的静态分析和攻击者的动态调试。将关键函数反汇编为Smali 指令后转化为C++代码,利用LLVM 框架的特点对C++代码进行分析得到LLVM 中间表示,然后对LL⁃VMIR 指令进行优化和混淆,最后输出机器码。实验结果表明,本文提出的方法具有较高的隐蔽性,相比其他混淆保护方法使用更少的性能消耗和代码体积,且能够抵御大部分通用脱壳工具的攻击,因此本文的方法具有更优越的性能。 本文仅选择不存在函数调用的函数作为保护的对象,在具有函数调用的函数中可能存在比较重要、需要被保护的函数。在以后的工作中,将考虑保护更多函数时应用程序性能的变化,以及如何在保证高安全性的前提下克服代码混淆带来的性能开销。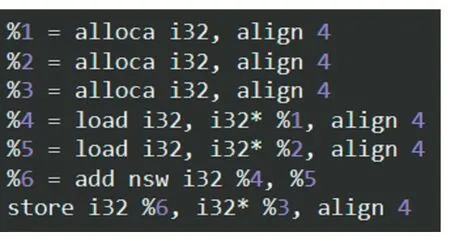
2.6 字符串混淆
3 实验
3.1 手动攻击


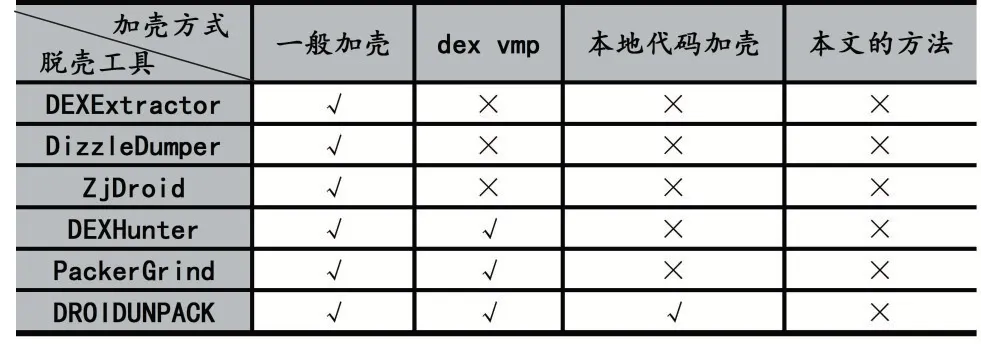
3.2 通用脱壳工具攻击
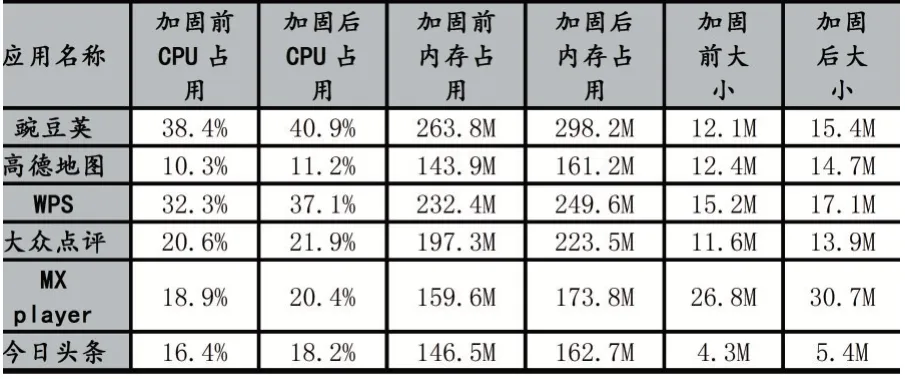
3.3 运行性能
4 结语
