基于Spark Streaming的高校网站敏感信息监测设计与实现
2021-05-27王丹邓谦刘姣
王丹 邓谦 刘姣

摘 要 高校在实现智慧化的同时也面临着网站发布信息或网页内容被黑客篡改成不符合国家或学校规定的信息及内容。通过对已有学术研究发现,现有技术的研究普遍存在着效率低、实时性差的问题,本文提出了一种基于Spark Streaming的高校网站敏感信息监测系统。该系统利用Kafka作为中间存储,系统架构在Spark Streaming框架上可实时消费Kafka中数据进行链接解析处理,将获取到的网页内容存储到Elastic Search中进行倒排索引敏感信息匹配,从而达到数据采集和数据处理同步,提高了网站监测效率。
关键词 Spark Streaming Kafka Elastic Search 敏感信息监测 倒排索引
中图分类号:TP311 文献标识码:A DOI:10.16400/j.cnki.kjdkz.2021.02.017
Design and Implementation of University Website Sensitive
Information Monitoring Based on Spark Streaming
WANG Dan, DENG Qian, LIU Jiao
(Information Construction and Management Office of Jiangsu University of Science and Technology, Zhenjiang, Jiangsu 212000)
Abstract While realizing intelligence, colleges and universities are also facing the fact that the information published on the website or the content of the webpage is tampered with by hackers into information and content that does not comply with the national or school regulations. Through the existing academic research, it is found that the existing technology research generally has the problems of low efficiency and poor real-time performance. This paper proposes a sensitive information monitoring system for college websites based on Spark Streaming. The system uses Kafka as an intermediate storage. The system architecture can consume data in Kafka in real time on the Spark Streaming framework for link resolution processing, and store the obtained web page content in Elastic Search for inverted index sensitive information matching, so as to achieve data collection and data processing synchronization improves the efficiency of website monitoring.
Keywords Spark Streaming; Kafka; Elastic Search; sensitive information monitoring; inverted index
0 引言
随着信息技术不断的飞速发展,高校的信息化需求也在不断增加,传统高校逐渐向智慧信息化校园演进。高校作为一个重要的信息化载体,内部网站很容易遭到黑客攻击以植入非法信息,校内各部门发布的文件信息中也可能包含不符合国家或者学校规定的相关信息。[1]
随着智慧校园的不断完善,网络信息安全性的重要性越来越凸显,但因高校网站架构与管理方法不统一,网站信息繁杂,导致很难做到网站信息全量监管。本文主要研究建立一种高校网站敏感信息监测系统,通过从海量数据中侦测敏感信息并及时通知相关网站管理人员,从而有效避免非法信息的传播,维护高校网络安全。
1 敏感信息监测系统设计
高校网站众多,传统数据采集对网络带宽要求较高,[2]为保证网站链接爬取及敏感信息匹配不影响师生网站的正常使用,本文采用分布式批量处理方式。在Hadoop[3]分布式框架上定时抓取网站链接,将抓取到的链接存储到Kafka[4]消息队列中,网页解析和敏感信息匹配架构在Spark Streaming[5][6]框架上,实时从Kafka消息队列中讀取消息,批量处理解析数据和匹配敏感信息。
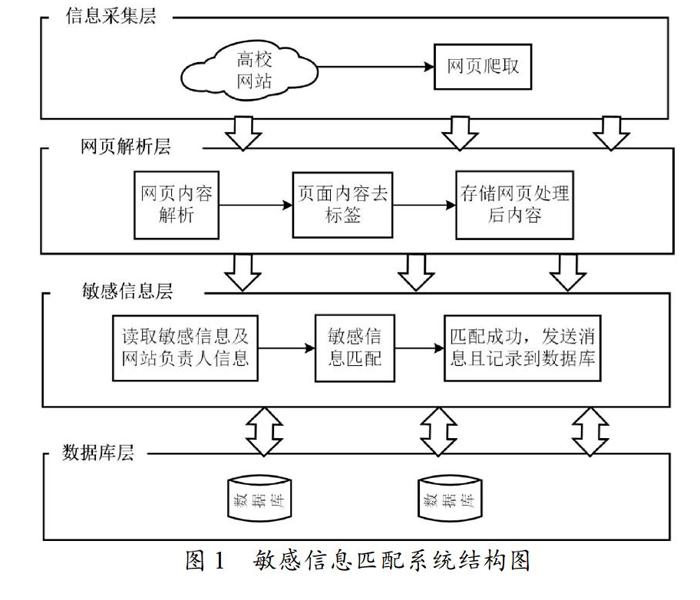
敏感信息匹配系统如图1所示,主要包括高校网页信息采集模块、基于Spark Streaming 网页解析模块、基于Spark Streaming和Elastic Search[7]的敏感信息匹配模块。
信息采集模块主要负责从高校各个网站上抓取网页链接并在抓取链接时,使用布隆过滤器进行去重处理,避免重复抓取链接。Kafka消息队列支持实时分批处理数据,将去重后链接对应的域名计算成哈希值作为Key值进行分配存储到Kafka消息队列中,同时将链接存储到Mongodb数据库中。
网页解析模块从Kafka消息中实时读取链接进行批量处理,通过链接获取页面,对页面内容进行解析。获取页面
标签内的内容,使用正则表达式匹配标签内是否含有链接并对获取到的内容去除标签。如果含有链接,对存在链接网页进行相同处理。将去标签后的文本内容、对应链接和链接对应的域名存储到Elastic Search中。敏感信息匹配模块负责匹配处理后的网页是否包含敏感信息和发送敏感信息消息。从数据库中读取敏感信息和网站管理员信息,使用倒排索引算法从Elastic Search中搜索匹配包含敏感信息的网页,如果匹配到敏感信息,将敏感信息处理成可发送信息及相应的链接发送给网站管理员。
2 敏感信息监测系统实现
2.1 高校网页信息采集模块
为避免影响工作时间的网站使用,本文采用定时任务在非工作时间进行分布式爬取。网页爬取采用主题式深度网页爬取,因高校网页分布范围广且数目多,为了快速爬取到更多网页信息,设计了一个分布式网络爬虫,将网络爬虫搭建在Hadoop分布式系统上,该分布式集群上包含有一个控制节点和若干个工作节点,其中控制节点用于分配爬取任务和监控爬取任务进行的情况,工作节点根据任务分配情况启动并执行信息爬取。
爬取到的链接存在大量的冗余,采用布隆过滤器对获取到的链接进行过滤。中间存储使用了Kafka,Kafka是一个生产者和消费者机制,相同Key值会被分配到同一个分区,而且消费者也可以指定读取分区,这样有利于迅速找到对应网站联系人,并且当消息丢失时Kafka可以进行数据回滚。[8]将去重后的链接按照
2.2 网页解析模块
网页解析模块是为了便于敏感信息匹配对网页内容数据预处理获取网页内容。因高校网页较多,网页解析基于Spark Streaming框架实现。当采集网页信息时不断的向Kafka中存储消息,而Spark Streaming框架可以实时处理数据流,对接收的数据进行分批处理。从Kafka中消费消息获得高校网页的链接,使用HtmlParse对网页信息进行解析获取网页内容。网页解析算法如下:
2.3 敏感信息匹配模块
高校页面数据较多,本文通过使用Elastic Search倒排索引方法进行敏感信息匹配。网页解析获取到的网页内容,对网页内容进行个人相关敏感信息匹配,例如身份证、电话号码等。若匹配到敏感信息,则对敏感信息添加不规则字符插入进行脱敏,将脱敏后的敏感信息及对应链接给网站管理人员,否则存储内容及对应链接到Elastic Search中。在存储到Elastic Search时,使用Elastic Search中的中文分词器将存储信息切分成一个个词,多个词组成了单词字典,对每个词创建索引,同时将解析内容对应的链接作为倒排项,倒排项组成倒排列表。从敏感信息库中读取敏感词,使用敏感词进行搜索,如果搜索敏感词成功,从倒排列表中获取敏感信息所在的所有文档信息及敏感信息在该文档出现的位置信息,将敏感信息进行脱敏处理,读取网站对应管理员信息将脱敏后的信息及对应的链接发送到管理员邮箱中,同时将相应的信息存储到数据库中。
3 系統运行与结果分析
本系统运行在CentOS7,64位,服务器需提供高性能计算和大内容存储空间来满足对学校网站网页URL高并发爬虫,因此,服务器CPU采用16核心,内存空间采用32G,硬盘1T,数据库为MongoDB和MySQL。
通过对学校各网站网页采集、预处理、解析网页内容、分词存储搜索获取到带有敏感信息网页,及时将敏感网页地址及内容脱敏处理告知网站管理员,及时解决问题,有效地提高学校舆情监管。本系统将国家、高校及个人相关敏感信息进行分析存储,对学校各网站进行敏感信息监控,监控过程中匹配获取个人信息身份证号码,手机号码相关敏感信息的概率高于其他敏感信息。
4 结论
通过对智慧化校园建设及校园安全性的研究发现,因高校网站过多,普通的网络爬虫和敏感信息匹配无法满足目前高效率需求。通过对分布式爬虫、Kafka消息队列、Spark Streaming实时数据框架和Elastic Search倒排索引搜索的研究发现,利用这些组合技术实现高校网站敏感信息监测系统可以高效、准确的对网站敏感信息进行监测,防止敏感信息大量的扩散。
参考文献
[1] 钱红兵,李艳丽,张蕊.WebCollector和ElasticSearch在高校网站群敏感词检测中的应用研究[J].电子设计工程,2019,27(24):11-14,19.
[2] 陈立章,李斌,陈晓鹏.高校BBS舆情监测系统设计与实现[J].微处理机,2012(01):40-43.
[3] 郑博文.基于Hadoop的分布式网络爬虫技术[D].哈尔滨工业大学.
[4] Nishant Garg.Apache Kafka[M].Packt Publishing,2013.
[5] HoldenKarau.Spark快速大数据分析:lightning-fast big data analytics[M]//Spark快速大数据分析:lightning-fast big data analytics.人民邮电出版社,2015.
[6] 赵秭沐.基于Storm的大数据实时处理架构的设计与实现[D].
[7] Clinton Gormley.Elasticsearch: The Definitive Guide[J].Orlly Media,2015.
[8] 任培花,苏铭.基于Kafka和Storm的车辆套牌实时分析存储系统[J].计算机系统应用,2019,第28卷(10):74-79.
