结合问题类型及惩罚机制的问题生成
2021-05-27武恺莉朱朦朦朱鸿雨张熠天洪宇
武恺莉,朱朦朦,朱鸿雨,张熠天,洪宇
(1.苏州大学 计算机科学与技术学院,江苏 苏州 215006;2.国家工业信息安全发展研究中心,北京 100043)
0 引言
问题生成(question generation,QG)是智能问答领域一个重要的任务。问题生成任务有多种输入形式,比如自由文本、表格数据等。本文研究答案可知的句子级问题生成任务,即输入为陈述句和目标答案,自动生成对应的问句。如例1所示(选自SQuAD测试集),通过理解陈述句和目标答案的语义,自动生成疑问句。问题生成任务可以应用于医疗、教育、对话等领域。此外,该任务还可以生成大量问答对,用于扩充问答系统的语料资源,协助自动问答系统构建[1-2]。
本文对答案可知的问题生成(answer-aware question generation)任务展开研究,对现有基于神经网络的问题生成模型进行改进,以优化该任务的性能。特别地,本文主要关注以下两个问题:其一是提高疑问句对应问题类型的准确率;其二是减轻生成问题与目标答案重复词的现象。如例1、例2所示,例1中疑问句的问题类型为“what”,例2为“when”。问题类型标识该疑问句提问的目标,对一个疑问句来说这是很重要的。所以,提高问题类型的准确率有助于生成正确的疑问句,保证与目标答案匹配。另一方面,从语言学角度,疑问句中包含要回答的答案的现象很少见。据观测,在现有研究生成的问句中不存在上述现象。因此,本文提出一种融合问题类型和惩罚机制的问题生成模型来改进上述问题。
例1
源端陈述句:Antibiotics revolutionized medicine in the 20th century,and have together with vaccination led to the near eradication of diseases such as tuberculosis in the developed world.<译文:抗生素在20世纪使医学发生了革命性的变化,并与疫苗一起使发达国家的结核病等疾病几乎根除。>
目标答案:20th <译文:20世纪>
疑问句:In what century did antibiotics revolutionized medicine?<译文:抗生素在哪个世纪彻底改变了医学?>
例2
源端陈述句:By 1139,Portugal had established itself as a kingdom independent from León.<译文:到1139年,葡萄牙已经建立了一个独立于里昂的王国。>
目标答案:1139
疑问句:By what year had Portugal established itself as an independent kingdom?<译文:葡萄牙在哪一年建立了自己的独立王国?>
本文在斯坦福阅读理解数据集(Stanford question answering dataset,SQuAD)[3]上进行实验,使用Du等[4]的数据划分方式。实验结果显示,本文所提方法能取得较好的性能。
本文的主要贡献包括:
(1) 通过BERT[5]模型训练问题类型分类器,得到每个输入的问题类型表示。利用门控机制在编码端融入问题类型,得到具有问题类型信息的源端陈述句表示。
(2) 提出一种惩罚机制,即在损失函数中加入对生成目标答案中词的惩罚,用于减轻从目标答案生成词的情况。
本文组织形式如下,第1节简要介绍问题生成任务的相关工作;第2节给出本文所研究的答案可知的问题生成任务的定义;第3节详细描述本文所提方法的细节;第4节介绍本文所用的数据集、实验配置以及评价指标;第5节展示和分析实验结果;第6节总结全文并展望未来工作。
1 相关工作
目前,问题生成的研究思路主要分为两种,其一是基于人工编写的问题模板转换得到疑问句,其二是基于端到端的神经网络将陈述句编码后解码生成疑问句。
基于规则的问题生成依赖于深层的语言知识,以及精心设计的陈述句到疑问句的转换规则。Lindberg等[6]结合语义标记信息提出一种复杂的基于模板的方法。将基于语义的方法的好处与基于模板的方法的表面形式灵活性相结合,最重要的一点是不受语法的严格约束。Heilman等[7]重复使用人工编写的规则将陈述句转换为疑问句,然后使用逻辑斯蒂回归模型将重复生成的疑问句进行排序,按比例保留排序靠前的疑问句。
随着神经网络以及大规模数据集的出现,基于神经网络的问题生成研究逐渐被关注。Du等[4]首次将神经网络模型应用在问题生成任务中,使用基于注意力机制的端到端模型,实验表明生成的疑问句在自动评价方法上可取得不错的性能,人工评价也优于基于规则的问题生成方法。由于Du等[4]未使用答案信息,这类研究也称为答案不可知的问题生成(answer-agnostic question generation)。Scialom等[8]将Transformer[9]框架应用于答案不可知的问题生成任务,并提出三种解决未登录词的策略。为了使生成的疑问句用于提问某个答案的,出现了答案可知的问题生成(answer-aware question generation)任务。Zhou等[10]加入词汇特征以及目标答案的信息,帮助模型生成更为具体的疑问句,并且使用拷贝机制[11]拷贝一些词表中没有的源端单词。Dong等[12]利用问题类型的语义特征,通过使用问题分类模型对目标答案的类型进行预测,加入到问题生成过程,生成具体的问句。Zhou等[13]将语言模型作为辅助任务,通过多任务学习提升性能。
基于规则的方法领域性较强,普适性较低。而且问题模板更注重于句子的结构信息,忽略句子的语义信息。与此相比,基于端到端神经网络的方法可以使模型自适应学习,省去人工构造规则。此外,大规模阅读理解数据集的开放,也为问题生成任务提供了更多的语料资源,推动了基于端到端神经网络方法的发展。
2 任务定义

(1)
其中,P(y|X,A)表示给定X和A的条件下,预测问句的对数条件概率。
3 方法
本文基于编码器-解码器框架,结合问题类型以及惩罚机制,对现有答案可知的问题生成架构进行优化。使用预训练模型BERT[5]微调问题类型分类器,得到问题类型的表示。在原有编码端产生的语义表示上,通过门控机制与问题类型表示进行融合,用于提高生成的问句对应类型的准确率。此外,在解码生成疑问句时,加入对复制目标答案词的惩罚项,减轻从目标答案生成问句的现象。本文的模型总体架构如图1所示。
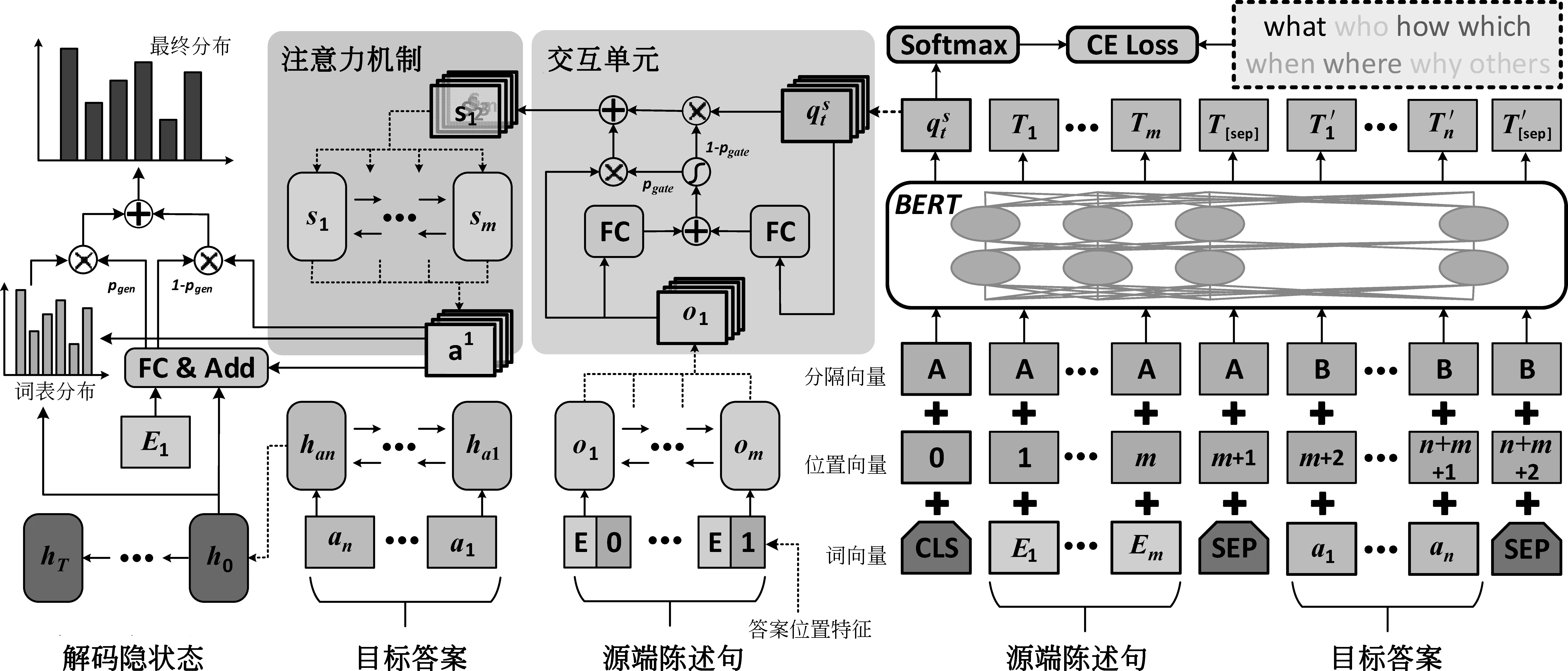
图1 模型总体架构图
3.1 编码层


因此,经过编码层得到X对应的隐状态表示为o={o1,o2,…,om}。
3.2 问题类型分类器
本文定义了常见的7种问题类型(“what”“who”“how”“which”“when”“where”“why”)以及其他类“others”。根据疑问句中是否出现上述问题类型词,给出对应的问题类型标记;若都未出现,则标记为“others”。
本文使用BERT模型[5]在问题类型分类任务上进行微调。考虑到同一个源端陈述句可能包含多个目标答案,从而生成不同问题类型的疑问句。所以,本文输入为源端陈述句X和目标答案A,输出为对应问题类型。

(5)
3.3 交互层

其中,wo、wq、bgate为模型参数,σ表示sigmoid激活函数。
3.4 解码层

3.4.1 初始化解码状态
本文使用单层Bi-LSTM对目标答案A单独编码,得到隐状态表示,并用最后一个时刻的隐状态han初始化解码状态h0,如式(8)所示。
h0=han
(8)
3.4.2 注意力机制
注意力机制的作用是在当前解码时刻生成问句中词的时候,注意到源端陈述句中有关的部分,从而生成更好的问句。本文用Bahdanau等[15]提出的注意力计算方式。在解码的每个时刻t,计算当前时刻对源端表示s的注意力分布at,加权求和得到语义向量ct。计算过程如式(9)~式(11)所示。
其中,v,Ws,Wh,battn为可训练的模型参数,ht指当前时刻的隐状态。
3.4.3 拷贝机制
拷贝机制的作用是让模型能从源端陈述句中生成词。本文使用的拷贝机制继承自See等[16]的工作,通过计算从词表中生成词的概率pgen来实现,则从源端拷贝单词的概率为1-pgen。计算过程如式(12)所示。
(12)
其中,wc、wh、wx、bp为可训练的参数。
3.4.4 生成器
解码生成词的概率分布由两部分组成,其一,从词表生成词对应的概率分布Pvocab;其二,使用注意力分布at直接从源端陈述句拷贝生成词。利用公式(12)中的生成概率pgen计算最终的概率分布P(W),计算如式(13)~(14)所示。
Pvocab(wt)=softmax(V(V′[ht,ct]+b)+b′)
(13)
(14)
其中,V、V′、b、b′为可训练的模型参数。利用最终的概率分布即可得到当前时刻生成的单词。当解码生成的单词为“
3.5 损失函数与惩罚机制
本文使用交叉熵作为损失函数,计算模型生成的疑问句与目标疑问句的损失,如式(15)所示。
(15)
其中,T为目标疑问句的长度,P(wt)为当前时刻目标疑问句中的单词对应的生成概率。
本文在损失函数中加入惩罚机制,用于抑制模型从目标答案中生成词,本文在损失函数中加入罚项Lans,计算如式(16)所示。
(16)
其中,n为目标疑问句的长度,P(wt)为目标答案中的词对应的生成概率。即,当前目标答案中词对应的概率P(wt)越大,则对应的损失值越大。
最终的损失函数为两部分损失加权求和,如式(17)所示。
Lall=λL+(1-λ)Lans
(17)
其中,λ为权重因子。
4 实验配置
4.1 数据集
本文在SQuAD问题生成数据集上进行实验,来验证所提方法的有效性。该数据集来源于阅读理解数据集SQuAD,数据划分方法和Du等[4]相同。
原始SQuAD数据集是从维基百科的536篇文档的段落中构建的问答对,这些问答对由众包工作者提供,并且要求答案是段落的一部分,共有超过100k的问答对。Du等人将包含答案的句子抽取出来作为问题生成语料的源端陈述句,问题则为要生成的疑问句。因为原始SQuAD数据集的测试集不公开,所以Du等重新划分训练集、开发集和测试集,数量分别为70 484、10 570和11 877条。由于Du等人没有使用目标答案,本文根据原始SQuAD 数据集从陈述句中抽取目标答案。表1列出了该数据集源端陈述句、目标答案以及目标疑问句对应的平均长度。

表1 平均长度统计表
本文所使用的问题类型分类器数据集输入为陈述句和目标答案。输出为问题类型标签,通过构造规则从目标疑问句中抽取,规则如下:
(1) 定义问题类型标记列表[“what” “who”“how”“which”“when”“where”“why”]。
(2) 查找疑问句中是否包含上述某个标记,若有,则对应问题类型为此标记;若无,则对应问题类型标记为“others”。
(3) 对训练集、开发集以及测试集进行问题类型标记,得到问题类型分类数据集。
经统计,每个类别对应的数量如表2所示。

表2 问题类型统计表

续表
4.2 超参数设置
4.2.1问题类型分类器超参数设置
本文使用BERT-Base模型(12-layer,768-hidden,12-heads)进行微调,最大长度设置为150,训练阶段batch_size为16,学习率(learning_rate)为5e-5。
本文使用验证集上性能最好的模型作为分类器,对所有数据抽取问题类型进行表示。
4.2.2 问题生成模型超参数设置
本文在源端和目标端使用相同的词表,词表大小为47 385。预训练词向量来源于GloVe[17],其维度为300。位置向量是随机初始化的向量,其维度为16。编码层和解码层的LSTM隐含层单元(hidden size)为256维。模型优化器为Adam[18],其学习率(learning rate)为0.000 5。批量数据大小(batch size)为16。测试阶段,使用集束搜索(beam search),其大小(beam width)为4。源端陈述句最大长度为100,目标答案最大长度为5,解码生成疑问句的长度为30。损失函数的权重因子λ取0.5。
4.3 评价指标
4.3.1问题类型分类器评价指标
本文使用准确率(accuracy,A)评价问题类型分类器,即正确预测的数量/样本总数。
4.3.2 问题生成模型评价指标
本文使用和Du等[4]相同的评价指标评价生成的疑问句,包括BLEU[19]、METEOR[20]以及ROUGEL[21],使用现有开源的评价方法包[22]计算上述值。BLEU用来评价候选文档在一组参考文档上的平均n-gram精度,并对过短的句子进行惩罚。BLEU-n表示计算BLEU值使用n-grams统计共同出现的次数,常用计算值有BLEU-1、BLEU-2、BLEU-3以及BLEU-4。METEOR是一种基于召回率的评价指标,通过考虑同义词、词干和释义来计算生成的句子和参考答案的相似度。ROUGE(recall-oriented understudy for gisting evaluation)是一种面向n元词召回率的评价方法。本文使用ROUGEL进行评价,该值基于最长公共子序列统计共现词的次数。
5 实验结果与分析
5.1 性能对比
为了验证所提方法的有效性,本文与现有问题生成模型进行比较。以下简要介绍本文的对比系统设置。
Du[4]首次将神经网络模型应用于问题生成任务,并从SQuAD数据集中抽取陈述句-问题对作为语料。使用基于注意力机制的端到端模型解决答案不可知的问题生成任务,未使用目标答案。
M2S+cp[23]通过多视角上下文匹配算法增强与目标答案相关的部分,匹配策略包括完全匹配、注意力匹配以及最大注意力匹配。此外,在解码端使用拷贝机制从源端生成词。
S2S-a-ct-mp-gsa[24]编码端通过门控自注意力机制实现,解码端是最大化指针网络,用于提升输入为较长的陈述句的性能。
Ass2s[25]答案分离的端到端神经网络,将源端陈述句中的目标答案用“”代替,用于学习缺失目标答案的语义。此外,通过Keyword-Net融合目标答案中的关键信息。
Wu[26]基于pointer-generator网络,融合目标答案及其位置信息,用于生成特定目标答案对应的问句。本文以此作为基线系统。
Qiu[27]为了解决生成过多一般性及与源端陈述句、目标答案相关性不大的问题,提出两种方式。其一,通过部分拷贝机制为词法上相近的词设置较高的优先级,从而可以生成语法上正确的形式;其二,通过基于阅读理解的重排序策略在候选问题列表中选择好的问题。
QPP+QAP+RL[28]通过两个下游任务增强语义的奖赏,通过强化学习来生成语义有效的问句。两个下游任务分别为复述识别和阅读理解任务。
表3列出上述对比系统与本文所提方法的性能。从表中可以看出,本文所提模型在SQuAD数据集上BLEU-4值达到最高。

表3 性能对比表
针对答案可知的问题生成任务,如何使用目标答案是很重要的。在所列对比系统中,大多关注点都在源端陈述句和目标答案的交互上,用以突出源端中的目标答案片段。与对比系统不同,本文认为不同的目标答案会对应不同的问题类型,标识了疑问句的提问方向。同时,该问题类型的表示又不应局限于特定的几种类别,生硬地映射为固定的表示。所以,本文通过目标答案和源端陈述句预测对应的问题类型,并使用门控机制与原有源端表示进行交互,从而获取具有问题类型信息的表示。通过上述方法,每个输入端对应的问题类型转换为一个隐式表示,通过门控机制融合到原有表示中,从而提升生成的问句对应问题类型的准确率。
现有答案可知的问题生成模型都注重目标答案的信息融合,导致模型可能会生成包含目标答案中词的问句。为了减轻这种情况,本文提出惩罚机制,在损失函数中加入生成与目标答案重复的词的损失。
由表3可见,本文所提模型的BLEU-4和ROUGEL指标都超过对比系统,但是METEOR值略低于QPP+QAP+RL[28]。METEOR是基于准确率和召回率的评价指标,使用WordNet[29]计算特定的序列匹配、同义词、词根和词缀、释义之间的匹配关系。由于METEOR在计算时会考虑同义词匹配关系,本文使用WordNet同义词词典分别统计了源端陈述句(S)、本文所提方法生成的问句(Qsys)包含目标问句(Qgrd)同义词的分布情况,如图2、图3所示。图2中,浅色部分表示S中Qgrd同义词的比例。图3中,浅色表示Qsys中的同义词属于S的比例(即图3中的浅色部分是图2中浅色部分的子集)。Qsys中94.7%的同义词来源于S,但是在S中同义词占比却很小,仅1.3%。由此可见,本文系统善于拷贝原句中的词,但不善于生成同义词。相对比,人工编辑提供的目标问句(即待生成的问句)中具有很多“同义异构”的表述,这类表述中主要以同义词为主。METEOR能够校准同义词,并将“同义异构”的不同表述视作一致的表述,从而使具有复述学习与生成能力的QPP+QAP+RL模型在METEOR上具有较好效果,而未集成复述学习和生成机制且依赖拷贝机制的本文模型,则在METEOR这一评估过程中,难以得到较高的分值。

图2 S中同义词分布图 图3 Qsys中同义词分布图
在表3的下半部分,本文列出了在基线系统中加入本文所提方法的性能。如表3所示,在基线系统中融合问题类型信息,BLEU-4、METEOR和ROUGEL分别提升1.15%、1.26%和3.3%。由此可见,源端与问题类型交互之后包含了类型信息,从而使得性能提高。在基线系统中加入惩罚机制,带来0.99%、1.03%、3.21%的性能提高。在加入两者之后,三个指标较基线系统提升1.47%、1.29%以及3.51%。
为了检验指标提升的显著性,本文选取BLEU_4指标进行显著性测试。表4列出本文所提模型(ours)、融合问题类型(+qtype)、加入惩罚机制(+penalty)分别与基线模型(baseline)计算的p-value[30]值。该值反映了显著水平,值越小则显著水平越高。Johnson[31]建议设置p-value的阈值为0.05,p-value值小于0.05表示显著,否则表示不显著。从表4可以看出,本文所提方法在统计上有显著性提升。

表4 显著性测试表
本文将在5.2节和5.3节分别分析融合问题类型的有效性以及惩罚机制的作用。
5.2 融合问题类型的有效性
为了验证融合问题类型的有效性,本文计算测试集上BERT问题类型分类器(BERT)、基线系统(baseline)、融合问题类型(+qtype)和本文所提模型(ours)的类型准确率,如表5所示。
从表5可以看出,直接使用BERT在问题类型分类器上进行微调,分类的准确率为73.50%。在源端中融合问题类型的信息,问题类型的准确率达到93.06%,比基线系统高26.21%。由此可见,本文所提融合问题类型的方法极大提升了生成的问题类型的准确性。正确的问题类型表示该疑问句的提问方向是对的,保证目标答案是用来回答该问题的。

表5 问题类型准确率对比表
例3列出了基线系统、融合问题类型以及本文所提模型生成的问句。
例3
源端陈述句:By 1139,Portugal had established itself as a kingdom independent from León.<译文:到1139年,葡萄牙已经建立了一个独立于里昂的王国。>
目标答案:1139
标准疑问句:By what year had Portugal established itself as an independent kingdom?<译文:葡萄牙在哪一年建立了自己的独立王国?>
baseline:Who established itself as a kingdom independent from León?<译文:谁建立了一个独立于里昂的王国?>
+qtype:By what year did Portugal become a kingdom independent from León?<译文:葡萄牙哪一年从里昂独立出来的?>
ours:By what year was Portugal established as a kingdom independent?<译文:葡萄牙哪一年建立独立王国的?>
例3中,目标答案“1139”是一个年份,对应的问题应该是“when”,是对时间的提问。而基线系统生成的问句的问题类型为“who”,与目标答案不符。此外,本文所提方法都生成和目标疑问句一样的疑问词“By what year”,比直接将问句中的问题词变成“when”更接近期望的表述。
5.3 惩罚机制分析
本文统计了训练集、验证集以及测试集中疑问句与目标答案重复词数情况,如表6所示。以上统计不包含停用词。
从表6可以看出,减少从目标答案中生成问句中的词是有必要的。从惩罚机制的公式(16)中可以看出,如果当前时刻生成的词是目标答案中的词概率较大,那么1-P(wt)会是一个较小的值,对应的损失会很大,在模型优化时不从目标答案中生成词。

表6 疑问句与目标答案重复词数统计表
为了区别不同长度的目标答案,本文选取目标答案长度从1到5统计了基线模型以及加入惩罚机制的模型生成的疑问句与目标答案的重复词数,如表7所示。由表7可见,惩罚机制对某些长度的目标答案减少了从目标生成词的情况,对于一些长度的目标答案则效果不是很明显。本文分析可能的原因是目标答案长度较短,在源端陈述句中占比较少,所以在损失函数中比较小。

表7 不同长度目标答案重复词数统计表

续表
例4给出加入惩罚机制的模型生成的疑问句的示例对比。
例4
源端陈述句:Antibiotics revolutionized medicine in the 20th century,and have together with vaccination led to the near eradication of diseases such as tuberculosis in the developed world.<译文:抗生素在20世纪使医学发生了革命性的变化,并与疫苗一起使发达国家的结核病等疾病几乎根除。>
目标答案:20th <译文:20世纪>
标准疑问句:In what century did antibiotics revolutionized medicine?<译文:抗生素在哪个世纪彻底改变了医学?>
baseline:In what century did antibiotics develop medicine in the 20th century?<译文:抗生素在20世纪是在哪个世纪发展成医学的?>
+penalty:In what century did antibiotics revolutionized medicine?<译文:抗生素在哪个世纪彻底改变了医学?>
从例4可以看出,基线系统生成的问句包含了目标答案“20th”,而加入惩罚机制的模型生成的问句和目标答案没有重复,和标准疑问句更相似。
6 总结与展望
本文旨在研究句子级答案可知的问题生成任务,主要在两个问题上进行改进。其一,提高问题类型的准确率。其二,根据观测目标答案里的词较少出现在疑问句中,本文提出惩罚机制,使生成的问句更接近人的表述。实验结果表明,本文所提模型提高了性能和问题类型的准确率,并且从一定程度上抑制模型从目标答案中生成词。但是,目前模型还存在一些问题,例如,疑问句和目标答案还存在一些重复词。在未来工作中,将会思考如何更好地解决上述问题。
