基于BERT的临床术语标准化
2021-05-27孙曰君刘智强杨志豪林鸿飞
孙曰君,刘智强,杨志豪,林鸿飞
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
0 引言
随着医疗信息化的快速发展,各医院累积了海量电子病历数据,如何有效利用这些数据来提高医疗健康服务水平是当前研究热点之一[1]。电子病历作为病人入院就诊信息的基本载体,记录了大量有意义的信息,这些病例信息大多以自由文本形式存在,并且由于医生个人书写习惯以及术语表达多样性等因素,导致电子病历中同一医疗概念会对应多种不用的表述形式,阻碍了医疗数据的检索、分析和利用。把形式多样的医疗概念映射到标准的医疗术语编码,即临床术语标准化(clinical term normalization),对于疾病辅助诊疗、科研检索、疾病分组(diagnosis related groups,DRGS)以及智能医保控费等研究具有重要的现实意义[2]。
当前国内的手术操作编码主要采用的是《手术操作分类与代码应用指导手册》(简称,ICD9—2017协和临床版)。它是根据国际疾病分类临床修订本(第三卷)进行的本土化修订,收纳了近9 000条的手术、操作名称,按照编码规则,统一扩展为6位数,编码样例如表1所示。

表1 ICD9—2017协和临床版编码样例
尽管临床术语的标准化编码对于医疗行业的发展非常重要,但在实际情况中患者就诊时为其分配正确的编码,不但耗时、易出错且成本高昂。医疗机构的专业编码人员会对临床医生的诊断进行二次编码,编码人员需要查阅医生对某次临床事件写的诊断描述以及电子病历中的其他信息,然后再按照编码指导以人工的方式分配合适的标准编码。这种方式总体学习成本较高,并且效率低下。因此,研究一种自动的临床术语标准化方法对于推进医疗信息化建设以及减少编码人员的工作量、提高工作效率具有重要的现实意义。
本文将临床术语标准化问题抽象为分类问题,提出一种基于BERT的临床术语标准化方法。首先计算待标准化的手术原词与标准词之间的Jaccard相似度系数,生成候选标准词集合;然后将手术原词与候选标准词使用BERT模型进行匹配分类,得到最终的预测结果。该方法在2019年CHIP临床术语标准化评测数据集上准确率为90.04%,表明该方法对于临床术语标准化任务是有效的。
1 相关方法
针对临床术语标准化问题,已有大量医生和技术人员进行了研究和探索,目前主要分为三类方法,即基于人工手动结合规则的方法、基于机器学习的方法和基于深度学习的方法。
宁温馨等[3]提出一种为中文临床诊断进行术语标准化的算法,利用分布式语义相似度计算方法计算文本语义相似度,并且基于词语和汉字构建词向量来提高性能。黄嘉俊[2]提出了一种基于组合语义相似度技术进行疾病术语标准化的方法,其主要基于领域知识库结合分词、实体识别和词向量表示技术进行临床术语相似度计算。Larkey等[4]通过组合三种分类器:K-近邻(K-nearest-neighbor)、相关性反馈(relevance feedback)以及贝叶斯独立分类器(Bayesian independence classifier),对住院患者的出院记录实现临床术语自动标准化。Shi等[5]提出了一种分层神经网络模型,可以捕获到原始词与标准词之间的潜在语义信息,并且设计了注意力机制来解决原始词对应标准词数量和预测的标准词数量之间的不平衡问题。赵等[1]提出了一种基于深度学习的电子病历医学实体标准化算法,使用Siamese网络架构和LSTM网络搭建模型,采用Pairwise方法训练模型。张等[6]构建了一种基于融合条目词嵌入和注意力机制的深度学习模型,该模型首先对含有病案条目的文本进行融合条目的词嵌入,并通过关键词注意力来丰富词级别的类别表示,然后利用词语注意力来突出重点词语的作用,增强文本表示,最后通过全连接神经网络分类器进行分类,输出标准化的结果。杜等[7]提出了一种基于多尺度残差图卷积网络的临床术语标准化方法,该方法采用多尺度残差网络来捕获临床文本的不同长度的文本模式,并基于图卷积神经网络抽取标签之间的层次关系,以加强标准化的能力。Xu等[8]充分利用电子病历中的各种数据资源,结合机器学习和深度学习的优势,对不同类型的数据(非结构化、半结构化和结构化的数据)学习不同的分类器,然后集成起来,实现基于多模态的临床术语标准化系统。
从当前结果来看,三类方法各有所长和不足。人工加规则的方法匹配精度较高,但效率低下;机器学习的方法无法捕获到文本中隐藏的深层语义信息;深度学习在文本建模上具有强大的表征能力,不仅可以更好地表示词语和文本,还可以学习到词语的上下文关系和重要词语的信息,在文本分类领域展现出强大的优势。因此,深度学习成为目前研究临床术语标准化的主流方法。
2 基于BERT的临床术语标准化方法
本文方法首先对文本进行规范化处理,并根据规则对原始词对应的标准词数量进行判断,将对应多个标准词的原始词进行拆分。然后使用相似度算法生成原始词对应的候选标准词集合,得到初步的预测结果,然后使用BERT模型对原始词进行分类,得到最终的预测结果。其系统架构如图1所示,任务流程如图2所示。

图1 模型的系统架构
2.1 数据预处理
2.1.1 数据规范化
由于文本中存在不规范的非汉字字符,需要将其中的无关字符去除,例如,“(右侧)颅内硬膜下冲洗术((01.0903))”转化为“(右侧)颅内硬膜下冲洗术”。
2.1.2 基于规则的标准词数量预测
由于手术原词存在一个原词对应多个标准词的情况,本文的处理方式是对手术原词进行数量判断,将包含多个标准词的手术原词以“+”或“、”为界进行切分,切分成多个细粒度的手术原词,对多个细粒度原词进行预测,将预测得到的多个标准词通过“##”连接,作为包含多个标准词的手术原词的预测结果,图2是任务流程图。

图2 临床术语标准化任务流程
2.2 相似度算法
候选标准词的生成方式是通过对给定的手术操作原词与标准词表中的每一个标准词进行相似度计算,通过相似度值对标准词进行打分排序得到n个候选标准词。
中文短文本相似度计算的主流方法有:余弦相似度(cosine)、BM25相关性评分、Jaccard系数、编辑距离(minimum edit distance,MED)、Dice距离等。
余弦相似度是通过计算两个向量之间夹角的余弦值来衡量相似度大小,夹角越小,相似度越高。假设V1和V2是两个n维向量,它们之间的余弦相似度计算如式(1)所示。

(1)
BM25相关性评分的主要原理是:对于句子s1先进行分词,生成词列表[wi],对于要与句子s1进行比较的句子s2,计算每个词wi与s2的相关性得分,最后将wi相对于s2的相关性得分进行加权求和,计算方法如式(2)所示。
式(2)中的idf(wi)为词wi的idf值,fi为词wi在句子s2中出现的频率,k1与b为调节因子,通常分别为2和0.75,len(s2)为句子s2的长度,avgsl是所有句子的平均长度。
Jaccard系数是一个用于衡量两个集合相似程度的度量标准,对于给定的两个集合A,B,它们之间的Jaccard系数计算如式(3)所示。

(3)
基于编辑距离(MED)的相似度算法计算方法,如式(4)所示。

(4)
其中,s1和s2为待计算的两个字符串,len(s1)和len(s2)分别是字符串s1和s2的字符个数,d(s1,s2)是s1和的s2编辑距离,即将s1变成s2的最小操作次数,允许的编辑操作为替换一个字符、插入一个字符、删除一个字符3种。
Dice距离用于度量两个集合的相似性,因为可以把字符串理解为一种集合,因此Dice距离也会用于度量字符串的相似性。对于给定集合C和D,它们之间的Dice距离计算如式(5)所示。
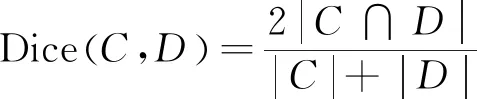
(5)
2.3 候选标准词匹配
BERT[9]是Google在2018年推出的预训练模型,在多项自然语言处理任务上取得了不凡的表现,其模型结构如图3所示。

图3 BERT模型结构图
BERT模型使用了双向Transformer的Encoder作为基本组成单元,BERT的这种结构能够联合所有层中的左右两个方向的上下文信息进行训练。此外,BERT模型使用的Transformer基于多头注意力机制(muli-head attention)。多头注意力机制可以帮助模型捕获更多的语义特征,将各个注意力头单独进行计算,然后将其结果进行拼接,得到最终的结果。BERT是通过大量未标注的百科文本语料进行训练得到的预训练语言模型,可针对特定目标任务对BERT模型进行微调。
候选标准词匹配的过程是将手术原词与候选标准词用[SEP]分隔符隔开作为BERT的输入,如图1中候选标准词匹配部分所示,然后取BERT输出中CLS位置对应的向量作为下一个全连接层的输入,使用softmax函数进行激活,把手术原词与候选标准词语义相似度计算问题抽象为二分类问题。
3 实验
3.1 实验数据
本文使用CHIP2019临床术语标准化评测任务的数据集进行实验,该评测是针对中文电子病历挖掘出的真实手术原词进行语义标准化,所有手术原词均来自于真实医疗数据,以《ICD9-2017版协和临床版》手术词表进行了标注。实验数据统计如表2所示。

表2 实验数据统计
实验数据样例如表3所示,对于一个手术原词包含多个标准词的情况,标准词之间用“##”连接。
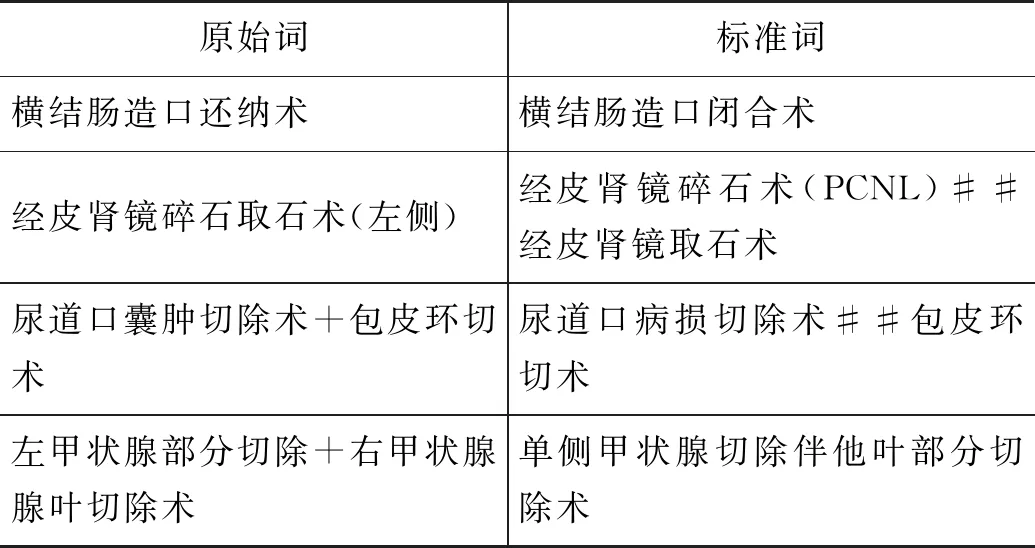
表3 实验数据样例
3.2 评价指标
候选标准词生成实验采用的是召回率(Recall)作为评价指标,其计算如式(6)所示。
其中,A和B分别是待预测原词集合和候选标准词集合。
分类实验在数据集上的预测结果有以下四种情况:模型把正例预测为正例的情况(true positive,TP);模型把负例预测为正例的情况(false positive,FP);模型把负例预测为负例的情况(true negative,TN);模型把正例预测为负例的情况(false negative,FN)。
对于原词分类实验采用的评价指标是准确率(accuracy,A)、精确率(precision,P)、召回率(recall,R)和F1值。其计算如式(7)~式(10)所示。
其中,pre_T为预测正确的手术原词加手术标准词的组合数量,N为待预测手术原词的总数。准确率是CHIP2019临床术语标准化评测任务使用的评价指标。
3.3 实验结果及分析
3.3.1 候选标准词生成实验
针对图1中的候选标准词生成部分,为了对比分析2.2节中不同相似度算法对候选标准词生成效果的影响,本文设计实现了五种方法进行候选标准词的生成,实验结果如表4所示。

表4 不同方法的候选词生成Top30结果比较
从表4的结果可以得到以下结论:
(1) 基于Jaccard系数的候选标准词生成效果优于其他四种方法,有助于提高候选标准词生成的质量。
(2) BM25算法依赖于精准的医学分词,Cosine算法依赖于高质量的词向量,本文实验采用的是通用的分词工具和词向量,没有进行人工特征的构建,所以导致二者的效果较差,并且二者的计算复杂度明显高于其他三种方法。
为了充分利用手术原词中隐藏的特征,本文将训练集中的手术原词作为伪标准词,对于待标准化的手术原词,在伪标准词中生成候选数据,将该数据对应的标准词作为候选标准词。针对候选标准词的生成范围(召回范围),本文设计了四个实验,召回范围分别为标准词、伪标准词、标准词&伪标准词和标准词+伪标准词。实验结果如表5所示。

表5 不同召回范围的候选词生成结果比较
表5中,“标准词&伪标准词”代表将两个词表融为一体进行相似度排序生成候选标准词,“标准词+伪标准词”代表在各自词表中进行相似度排序,将生成的候选标准词融合在一起。从表5可以得到以下结论:
伪标准词有助于候选标准词的生成效果,并且“标准词+伪标准词”的召回范围适合于候选标准词的生成。
Top30的召回效果达到了较高的水平,因此本文采用原始词的Top30候选标准词集合作为候选标准词匹配的输入。
Top30内未召回准确标准词的手术原词样例如表6所示。从表6可以看出,对于复杂的手术原词使用单纯的字符相似度算法进行召回,忽略了手术描述的语义信息,导致召回失败。

表6 未召回标准词的手术原词样例
3.3.2 候选标准词匹配训练集构造
候选标准词匹配的过程是基于BERT模型的0-1分类任务,需要构建包含正负例的训练集用于训练模型。
正例:<原词i,标准词i,1>
构建负例:原词i与标准词词表中的每一个标准词计算Jaccard相似度系数,取相似度值的Top20作为候选词表,将标准词i从候选词表中去除,剩下的候选词用作构建负例。
负例:<原词i,标准词j,0>
3.3.3 参数设置
本文采用的是Google 提供的 BERT-Base 模型,详细训练参数如表7所示。
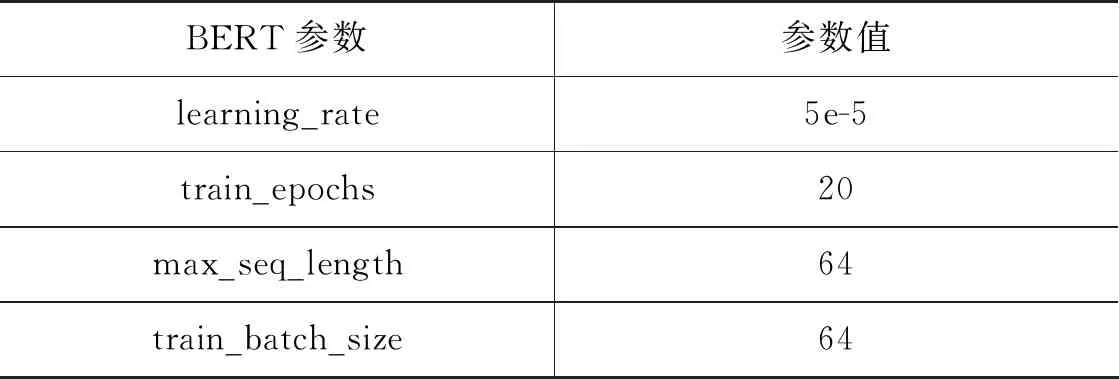
表7 BERT模型参数设置
3.3.4 候选标准词匹配实验
针对训练集中正负例1∶19的不平衡,本文设计了四种正负例比例进行实验,实验结果如表8所示。

表8 不同正负例比例实验结果比较
从表8的实验结果可以得出结论:10倍正例加负例的组合,有助于提高本文方法的性能。
针对图1中的候选词打分部分,为了对比分析不同神经网络模型的性能,本文选取并实现了以下六种模型进行对比实验。
(1) CDSSM[10]:通过卷积神经网络来捕获上下文信息,根据提取到的特征进行手术原词分类。
(2) MVLSTM[11]:基于双向LSTM网络的多语义模型,该模型能够有效提取句子中的重要特征,根据提取到的特征进行手术原词分类。
(3) Match_pyramid[12]:将文本使用相似度计算构造相似度矩阵,然后使用卷积网络来提取特征,根据提取到的特征进行手术原词分类。
(4) BiMPM[13]:采用了matching-aggregation的结构,把两个句子之间的单元做相似度计算,最后经过全连接层与softamx层得到手术原词分类结果;
(5) DRCN[14]:在特征提取阶段结合了DenseNet的连接策略与注意力机制,在interaction阶段,也采取了多样化的交互策略来提取特征,根据提取到的特征进行手术原词分类。
(6) ESIM[15]:通过使用句子间的注意力机制(intra-sentence attention)来提取特征,根据提取到的特征进行手术原词分类。
本文使用了上述六种模型和BERT模型进行实验,实验结果如表9所示。

表9 不同方法的实验结果比较
从表9的实验结果可以看出本文方法的实验结果均优于其他神经网络的实验结果,表明本文方法可以提高临床术语标准化的效果。
3.3.5 结果分析
对于本文方法的预测结果,选取了3个预测正确和3个预测错误的样例,如表10所示。

表10 预测结果样例

续表
从表10的样例可以看出,手术原词中会包含“全麻下”和“ORIF”这种医生使用的描述,对于标准化的过程会产生干扰。从预测正确的样例来看,本文方法可以捕获到手术原词中的重点词汇,从而对不规范的手术原词预测出准确的标准词。从表10的预测错误样例可以得到以下结论:对于由“部位+术式+入路+疾病性质”组成的手术名称,在使用本文的方法进行标准化时,没有充分考虑到部位、术式、入路和疾病性质的匹配,导致预测结果错误。没有充分融合“部位、术式、入路和疾病性质”这四类语义特征是本文方法的缺陷,这也是本文方法可以继续改进和提升之处。
4 结论
临床术语标准化任务旨在将电子病历中包含的医疗概念映射到标准的编码,对医疗信息化的建设具有重要的意义。
本文提出了一种基于BERT的临床术语标准化方法,将临床术语标准化任务转化为二分类问题。首先计算待标准化的手术原词与标准词之间的 Jaccard 相似度系数,生成候选标准词集合,然后将手术原词与候选标准词使用BERT模型进行匹配分类,得到最终的预测结果。本文方法避免了人工构建特征的繁琐,在CHIP2019临床术语标准化评测数据集上准确率为90.04%,表明本文方法对临床术语标准化任务是有效的。
另一方面,本文方法没有充分利用医疗术语的构成信息,导致对复杂的手术原词预测错误。未来可以从医疗术语的构成特点入手,例如,增加“部位、术式、入路和疾病性质”特征,提高本文方法的预测准确率。
