基于最短依存路径和集成学习的化学物蛋白质关系抽取
2021-05-27邵一帆钱龙华周国栋
程 威,邵一帆,钱龙华,周国栋
(苏州大学 计算机科学与技术学院 自然语言处理实验室,江苏 苏州 215006)
0 引言
化学物蛋白质关系抽取(chemical protein relation extraction,CPRE)是指从生物医学文献中自动抽取出化学物和蛋白质之间的相互作用关系,如上调、下调、激动、拮抗和催化作用等。例如,在句子“Troglitazone,a second ACS4 inhibitor,inhibited ACS activity <10% in microsomes and mitochondria and 45% in MAM.”中的化学物“Troglitazone(曲格列酮)”抑制了蛋白质“ACS4”和“ACS”的活性。了解化学物(药物)和蛋白质的相互作用关系对新药研制、精准医学和基础生物医学研究具有重要意义。生物医学研究人员研究了大量化学物和蛋白质之间的关联作用,并将研究成果发表在生物医学文献中,最后由编目员将它们补充到化学物蛋白质相互作用数据库中,如Proteindata数据库和PDSP Ki数据库等。从文献中人工提取化学物蛋白质关系需要编目员具备深厚的生物医学领域背景知识,然而,随着生物医学文献数量的急剧增长,人工挖掘化学物蛋白质关系不仅费用高昂,而且非常耗时。因此,利用自然语言处理(natural language processing,NLP)中的关系抽取技术从生物医学文献中自动抽取化学物蛋白质关系的研究工作便吸引了越来越多研究者的关注。
为了促进化学物蛋白质关系自动抽取技术的研究,BioCreative VI[1]任务提供了化学物和蛋白质关系的标注语料库。该语料库来源于PubMed摘要集合,标注了五种化学物蛋白质关系,包括激活(activator)、抑制(downregulator)、激动剂(agonist)、拮抗剂(antagonist)和反应底物/反应产物关系(substrate)。
具体而言,激活关系是指化学物通过与蛋白质的结合间接上调或激活蛋白质的活性。抑制关系是指化学物通过与蛋白质的结合来抑制蛋白质活性。拮抗关系是指化学物可以降低另一种化学物对蛋白质的激活作用。激动作用是指化学物可以与蛋白质受体相结合从而改变蛋白质受体的状态。反应底物或反应产物关系是指化学物作为酶促反应的反应底物或者反应产物。
传统的生物医学实体关系抽取(如蛋白质相互作用关系)往往采用基于特征的方法或基于核函数的方法[2]。基于特征的方法专注于为关系实例设计有效的特征,包括词汇、句法和语义信息等[3-4]。基于核函数的方法通过核函数来计算关系实例的结构相似性,因而可以更有效地捕获它们的结构信息[5]。
随着神经网络(DNN)模型(如卷积神经网络[6]和递归神经网络)和注意力机制在自然语言处理中的广泛应用,如机器翻译[7]、问答[8]和文档分类[9]等,基于注意力的神经网络模型已被用于多个关系提取任务[10]。在CPRE任务上,相继提出了基于CNN[11-13]、GRU[13]、LSTM[14-15]、Bi-LSTM[11,16]、Transformer[15]、TreeLSTM[17]等模型的关系抽取方法,这些研究的共性是,关系实例的表示方式或是基于完整句子,或是将依存信息集成到其他信息中,没有单独考虑最短依存路径的作用。
本文考察了最短依存路径在化学物蛋白质相互作用关系抽取中的作用。在BioCreative VI CHEMPROT任务的CPRE实验表明,与完整句子序列相比,在LSTM模型上的F1指数可以提升5.2个百分点。特别是采用集成方法之后,最终F1指数提高到68.1,达到了该任务上的较好水平。
1 相关工作
在CPRE任务上,有些研究工作采用传统的机器学习方法,Mehryary 等[14]采用基于词、词法和依存类型等特征的SVM方法进行关系抽取;Warikoo等[5]采用基于卷积依存树核的SVM方法来进行关系抽取;Lung等[3]结合关键词和依存关系类型特征,使用随机森林、Logistic回归、朴素贝叶斯等方法进行关系抽取;Tripodi等[4]在实体类型和依存类型等特征的基础上,结合知识库中的实体类别信息,使用朴素贝叶斯和随机森林的方法进行关系抽取。
在基于深度学习的关系抽取方面,Sergio[16]采用CNN模型;Liu等[13]对比了CNN和ATT-GRU模型;Sergio[16]采用了LSTM模型;Peng等[11]采用了基于句子和依存路径的CNN和LSTM模型;Lim等[17]采用TreeLSTM 模型;Corbett等[15]使用基于迁移学习的LSTM模型,将词向量的预训练任务迁移到CPRE任务上进行关系抽取。
在深度学习模型的特征方面,Lim等[17]在词的基础上加入了位置特征,Liu等[13]加入了词性特征。依存信息也作为特征广泛应用。Peng等[11]将依存关系类型作为句子序列的特征加入到CNN模型中;Sergio[16]将依存关系类型作为特征加入到CNN和LSTM模型中;Lung等[3]将最短依存路径(SDP)上单词和依存关系类型的特征作为SVM、随机森林、Logistic回归、朴素贝叶斯、LSTM等分类器的输入。
与上述采用整个句子作为关系实例的表示方法不同,本文采用最短依存路径(SDP)作为实例表示方法,结合词语、词性、位置和依存关系等特征,考察最短依存路径对化学物蛋白质关系抽取的作用。
2 最短依存路径
依存句法[18]最早由法国语言学家Lucien Tensniere于1959年提出,旨在描述句子结构,明确句子中单词之间的相互依存关系。在句子的依存结构(图1)中,两个单词之间存在多条依存路径。最短依存路径SDP是指两个单词在依存句法结构上的最短路径。由于最短依存路径简洁地表达了两个实体之间的句法关系,保留了表达实体关系的主干模式,因此被广泛地应用于关系抽取中[2-3,10,13,15]。为了得到最短依存路径,首先要从句子的依存结构得到依存树,然后,给定句子s中的单词序列s={w1,w2,w3,….,wn-1,wn} 和两个标记出的化学物和蛋白质实体e1和e2(e1和e2也在单词序列中),两个实体间的最短依存路径是指实体e1和e2所在单词在依存树上的路径。
如图1所示,表示了句子(PMID:12244038)的依存结构中化学物实体(Gemfibrozil)和蛋白质实体(nitric-oxide_synthase)之间存在着下调关系(downregulate)。两个实体之间的最短依存路径就是从“gemfibrozil”出发到达“nitric-oxide_synthase”的加粗带箭头方向线构成,可表达为:

图1 句子的依存结构
“CHEM→nsubj→inhibits←dobj←induction←prep←of ←pobj←GENE”。
3 基于注意力机制的双向LSTM模型
由于基于注意力机制的双向LSTM模型(Att-BiLSTM)被广泛地用于关系抽取,本文也把它作为CPRE的基本模型。其结构如图2所示,包括嵌入层、BiLSTM层、注意力机制层和输出层。

图2 基于注意力机制的双向LSTM模型
模型的输入SDP层是经过依存关系解析得到的两个实体e1和e2之间的最短依存路径上的单词序列。在嵌入层中,输入路径上单词的各个特征分别转换为各个向量,这些向量再拼接在一起构成了BiLSTM层的输入向量。然后,BiLSTM层对输入序列进行循环处理和转换得到该层的输出序列。之后,应用注意力机制将它们与相关权重相乘后再合并为句子级向量。最后,在输出层中使用Softmax函数将句子表示转换为关系类型的预测概率。
3.1 嵌入层
嵌入层的输入是两个实体在句子中的最短依存路径,特征包括依存路径上单词的词性、依存关系以及该词到两个实体的相对位置等特征,这些特征通过字典查找获得相应的向量表示:词向量、位置向量、词性向量和依存向量。
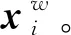


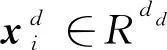
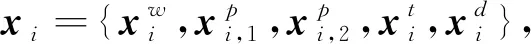
3.2 BiLSTM层
BiLSTM层接受输入序列S,并将其隐藏单元序列输出到注意力层。LSTM模型由一组循环连接的单元组成,称为存储单元。每个单元根据前一个隐藏向量ht-1和当前输入向量xt计算得到当前隐藏向量ht,其操作可以定义如式(1)~式(6)所示。
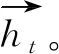
3.3 Attention层
在依存路径中,不同的单词对关系预测有不同贡献。如图1中,对于“DOW”的关系类型,单词“inhibitor”的重要性就高于其他词。因此,本文同样引入了注意力机制[19]来衡量不同的单词对关系分类的重要程度。序列中第i个单词的重要性得分εi由式(7)给出:
其中,hi是BiLSTM层的第i个输出向量,而ωi是在训练过程中要学习的权重向量,hi和ωi的维数均是dw。然后,可以通过Softmax函数获得每个单词的归一化重要性权重αi,如式(8)所示。
最后依存路径的表示r由所有输出向量的加权和形成,即:
3.4 输出层
在输出层中,注意力层的表示r首先通过非线性操作转换为向量h*,如式(10)所示。
然后使用Softmax分类器来预测句子S中实体对(e1,e2)在关系类型y上的概率分布,如式(11)所示。
其中,W2∈l×k为参数矩阵,b(s)∈r为偏置量。根据上述概率分布,得到实体对(e1,e2)的预测关系类型,如式(12)所示。
3.5 模型训练
模型的损失函数定义为交叉熵损失函数,即:

(13)
其中,p(yi|si,θ)代表预测关系类型的置信度,θ表示模型的所有参数,λ是正则化系数。
3.6 集成学习
在机器学习中,与单一模型相比,集成学习方法往往可以显著提高学习性能。为了提高关系抽取模型的性能,本文尝试了不同的模型集成方法,包括投票法和平均法。投票法是指在多个模型对样本的预测结果中,选择数量最多的关系类型作为最终结果。如果有多个并列关系类型,则随机选择一个作为最终结果。平均法是指对多个模型输出的关系类型置信度计算平均值,取置信度平均值最高的关系类型作为最终结果。
4 实验
4.1 语料库
本文实验语料采用BC-VI Task5上的CHEMPROT[1]语料,它包含训练集、开发集和测试集等,分别由1020 612和800篇摘要构成,其中的化学物和蛋白质实体及其关系均由人工标注。表1统计了该语料中训练集、验证集和测试集的化学物蛋白质关系数量。从表中可以看出,超过一半的关系类型都是DOW,而AGO和ANT类型的数量最少。

表1 语料库关系数量统计
4.2 预处理
文献摘要首先经过分句变成句子,接着句子中的实体被替换成符号,即所有的蛋白质使用“GENE_i”表示,化学物用“CHEM_i”表示,其中i表示它在句子中的实体序号,这样做的目的是为了防止一个实体中的多个单词出现在句法树中的不同成分中。然后,使用Bllip Parser[2]获得句子的成分句法树,再使用Stanford转换器[18]将句法树转换为依存树。最后,将所有出现在同一句子的任意两个实体构成一个潜在的关系实例,如果标注了这两个实体之间的关系类型,则该关系实例作为一个正例,如果没有标注实体间的关系类型,则该关系实例作为一个负例。
4.3 评估
实验中将CHEMPROT任务的训练集、开发集合并为新的训练集,测试集保持不变。在训练过程中,训练集中的20%作为验证集,每次实验取5次运行的平均值作为最终性能。
评估标准采用标准的P/R/F1指数(precision/recall/F1-score),其定义如式(14)~式(16)所示。
其中,TP(true positive)表示预测正例中正确的数量,FP(false positive)表示预测正例中错误的数量,而FN(false negative)表示预测负例中错误的数量。
4.4 参数设置
神经网络模型的主要参数取验证集上效果较好的值,如表2所示。

表2 神经网络模型参数设置
4.5 实验结果及分析
4.5.1 不同特征对抽取性能的影响
表3比较了在基于最短依存路径的Att-BiLSTM模型上不同特征对抽取性能的影响。特征如3.1节所示,其中,Word表示包含基本词特征时的性能,各个特征按照累加的方式逐一添加到特征集中,每一列性能中的最高值用粗体表示。

表3 不同特征对抽取性能的影响
从表3中可以看出:
(1)Word词特征已经可以取得比较好的结果,说明在最短依存路径上的词序列中,词向量是关系抽取的重要特征。例如,句子“[CHEM],alipid-loweringdrug,inhibitstheinductionof[GENE]inhumanastrocytes.”的最短依存路径上的词序列为“[CHEM]inhibitsinductionof[GENE]”,简化了句子表达,且保留了“inhibits”这个关键词,从而帮助系统识别出关系类型。
(2)Part-of-speech特征通过提升准确率(~4.7%)来提升F1指数,说明词性特征能够排除部分假正例。而Position特征略微提升了F1指数(~0.3%),说明Position特征的作用不大。
(3)Dependency特征对精确率和召回率都有相当程度的提高,这说明依存关系类型特征能够帮助识别词序列无法识别出来的句子。例如,在句子“antifolatesCHEM_2(CHEM_3,CHEM_4)andCHEM_5([CHEM])aremorespecificandpotent[GENE]inhibitors”(PMID:15353299)中,最短依存路径的词序列“[CHEM]CHEM_5CHEM_2antifolatesinhibitors[GENE]”不足以说明化学物和蛋白质之间的抑制关系,但根据依存关系,[CHEM]是CHEM_5的同位语,后者和CHEM_2是并列关系,CHEM_2又是antifolates的同位语,而antifolates能抑制[GENE],进而可以说明[CHEM]是[GENE]的抑制剂。
4.5.2 不同实例表示方法对抽取性能的影响
表4比较了在Att-BiLSTM模型上不同实例表达形式(SENT/SDP)对抽取性能的影响,其中SENT表示采用整个句子序列作为关系实例的表示方法,而SDP表示基于最短依存路径的关系实例表示方法。两种实例表示方法都使用了句子或路径上的Word、POS、Position、Dependency等特征(表4)。

表4 不同实例表达形式对抽取性能的影响
(1)使用基于最短依存路径的关系实例表示方法比使用句子序列取得了超过5个点的性能提升,这说明最短依存路径是表达关系实例的有效方式;
(2)最短依存路径对性能的提升不仅体现在准确率上,也体现在召回率上。这说明最短依存路径序列在保留关系表达中的关键部分时,也消除了句子中对关系无关部分的影响。
4.5.3 不同关系类型的性能比较
表5列出了在所有特征的情况下各关系类型上的抽取性能,每一列性能中的最高值用粗体表示。

表5 不同关系类型抽取性能的比较
从表5中可以看出:
(1) ANT拮抗关系取得了最高的精确率,这是由于表达拮抗关系的模式比较独特,岐义性小。如大量出现的模式“[CHEM] antagonists [GENE]”总是表达化学物和蛋白质之间的拮抗关系。
(2) DOW抑制关系取得了最高的召回率和F1值。这是由于抑制关系的训练实例数量最多,一些具有岐义性的模式也都被预测为抑制关系。
4.5.4 不同模型集成方法和模型数量对性能的比较
图3比较了不同集成方法(投票法和置信度平均法)和基模型数量对抽取性能的影响,其中横坐标表示集成的基模型数量,纵坐标表示P/R/F1值。

图3 不同集成方法和模型数量的抽取性能比较
从图中可以看出:
(1) 置信度平均法的性能比投票法普遍要高,且主要是体现在准确率的提高上。
(2) 无论哪一种集成方法,随着基模型数量的增加,性能一开始呈上升趋势,但波动较大,特别是对于投票法。但是当模型数到达到10之后,性能趋于平坦,波动也较小。
考虑上述因素,本文集成方法的最终性能取基模型数量为10时的平均法性能值,即P/R/F1值分别为71.8/65.2/68.1。
4.5.5 与其他系统的性能比较
表6列出了本文实验系统与当前同类型系统的性能比较(表6)。

表6 与其他系统的性能比较
(1) 在LSTM模型上,本文取得了最好的性能,高于基于句子的LSTM模型[16]和Bi-LSTM模型[11],这说明最短依存路径和注意力机制能够有效提升CPRE抽取性能。
(2) 和其他单分类器相比,本文取得了仅次于Björne[20]分类器的性能。本文采用实体间最短依存路径上的词、距离、词性、依存关系类型等特征,而Björne[20]在句子的词、距离、词性特征的基础上加入实体间最短依存路径、单词到实体依存路径和事件信息等特征。
(3) 在集成模型方面,Peng等[11]使用随机森林的方法集成SVM,LSTM和CNN模型,Björne等[20]集成了5个F1值最高的CNN模型,使用置信度平均值法,取模型的平均预测结果。本文分别采用投票法、置信度平均值法进行实验,可以看出,集成模型的性能要优于单分类器的性能,而且本文获得了最高的召回率和仅次于Björne的F1值。
5 结束语
本文提出了一种基于最短依存路径和注意力机制的双向LSTM模型来进行化学物蛋白质相互作用关系抽取,其特征包括词性、位置和依存类型等。在此基础上再采用集成方法来提高关系抽取的性能。在BioCreative VI CHEMPROT任务上的实验表明,在基于依存信息的单一模型上取得了仅次于最好的性能,说明基于注意力的双向LSTM模型能有效捕获化学物和蛋白质实体间最短依存路径上的信息。另外,基于平均置信度的集成方法能进一步提高关系抽取的性能,最终性能与目前该任务上的最佳系统的性能相当。
