基于部分标签数据和经验分布的命名实体识别
2021-05-27宋晔璇
宋晔璇,陈 钊,2,武 刚,2
(1.北京林业大学 信息学院,北京 100083;2.国家林业草原林业智能信息处理工程技术研究中心,北京 100083)
0 引言
命名实体识别(named entity recognition)指抽取文本中的人名、地名、机构名、领域术语等专有名词,是自然语言处理领域的基础任务。
近年来,基于深度神经网络的命名实体识别模型,在新闻[1]、医学等领域[2-3]已经展示出了较高的准确性和鲁棒性,很大原因是这些领域有着大规模的完整标注的语料。然而,在许多领域,数据的标注难度大,标注成本高,高质量的标注数据难以获得。
针对特定领域缺少标注数据的问题,研究人员探索使用更加容易获得的部分标签数据。通过现有资源如目标领域的词典、网页超链接等,自动标记出数据中的一部分实体,得到数据中的部分标签。最早对部分标签数据的研究主要基于条件随机场(conditional random field,CRF)[4],结构化感知器和结构化支持向量机[5]。Tsuboi等[6]提出了一种基于部分标签数据训练的CRF模型,能够应用于命名实体消歧[7]、依存分析[8]、词性标注[9]和命名实体识别[10]等任务。但是,其仍存在的问题是部分标签数据中有一些字符的标签未知,这些未知的标签会在训练模型时引入噪声[11]。一种典型的方法是将未标注的位置直接视为非实体标签,还有一些方法[12]假设未标注位置的标签是均匀分布的。但是这两种方法取得的效果并不好,第一种导致大多数实体无法被识别,降低了召回率;第二种虽然能够召回大量实体,但同时也降低了查准率。
迁移学习的方法是从现有资源的角度出发来解决目标领域中没有标注数据或标注数据少的问题[13]。在自然语言处理领域,迁移学习主要分为基于资源的迁移和基于模型的迁移。基于资源的迁移对额外资源的规模和质量比较敏感,在跨语言迁移任务中[14-15]比较常见。基于模型的迁移不需要额外资源,通过对模型结构、损失函数或特征表示等进行调整,利用神经网络的自适应性,在两个不同但有关联的任务间传递知识。一些跨领域的序列标注方法[16-18]通过把一个在成熟源领域数据上训练的命名实体识别模型的参数迁移到另一个有少量标准的目标领域数据集上,从而提高了目标领域的识别效果,验证了不同领域在处理相同任务时具有底层知识相似性,而且这种底层知识具有可迁移性。
本文提出了一种基于部分标签数据和迁移学习的命名实体识别方法。首先扩展了Tsuboi等[6]的方法,使得模型能够联合部分标签数据和标签的经验分布进行训练。然后将新闻领域的知识迁移到本文的测试领域,在测试领域的部分标签数据上训练得到标签的经验分布。最后,将部分标签数据和标签的经验分布输入模型进行训练。
我们分别在植物病虫害和优酷视频数据集上进行了实验,实验结果表明,本文方法能够有效降低部分标签数据的噪声,且取得较好的识别效果。
1 基础模型
中文命名实体识别是一种序列标注问题。由于中文词边界不容易确定,为了避免分词错误影响模型的识别效果,本文选择对序列中的字符进行标注。在含有全部标签的训练数据中,每个字有且仅有一个与之对应的标签。本文使用三标记(BIO),B表示该字符是实体词的起始位置,I表示该字符是实体词的中间位置或结束位置,O表示该字符为非实体词。如图1所示,在句子“北京是中国的首都”中,“北京”和“中国”为实体词,其他字符为非实体词,该句子的标注序列为:

图1 “北京是中国的首都”的标注序列
L={B,I,O,B,I,O,O,O}
目前,在中文数据集上,识别效果较好的是Bi-LSTM-CRF模型[1],本文使用Bi-LSTM-CRF模型作为基础模型,使用以字作为语义单元,字词信息相结合的方式[19],具体结构如图2所示。

图2 BiLSTM-CRF网络结构

其中,Wi和bi是全连接层的权重和偏置。给定完全标注的训练数据{xj,yj}N,其中N为样本个数,n为句子长度。每条样本xj在所有可能的识别结果中只有一条正确的路径yj。根据Lafferty等[4]提出的条件随机场,模型的损失函数计算如式(7)、式(8)所示。

(7)

(8)

其中,yi-1和yi表示第i-1个和第i个字符的标注结果,T和A分别为转移矩阵和发射矩阵。Tyi-1,yi表示从yi-1到yi的转移得分,Ai,yi表示yi的发射得分。
2 基于部分标签数据和经验分布的命名实体识别方法
2.1 基于部分标签数据和标签经验分布的Partial-CRF
2.1.1 部分标签数据
以图3中的句子“北京是中国的首都”为例。在无法获得完整的标注信息的场景下,只能够确定“中国”是一个地名实体,由此可以将这两个字符准确地标记为B、I,而其他字符的标签是未知的,可能为B、I、O中的任意一个,这样的数据就是部分标签数据。
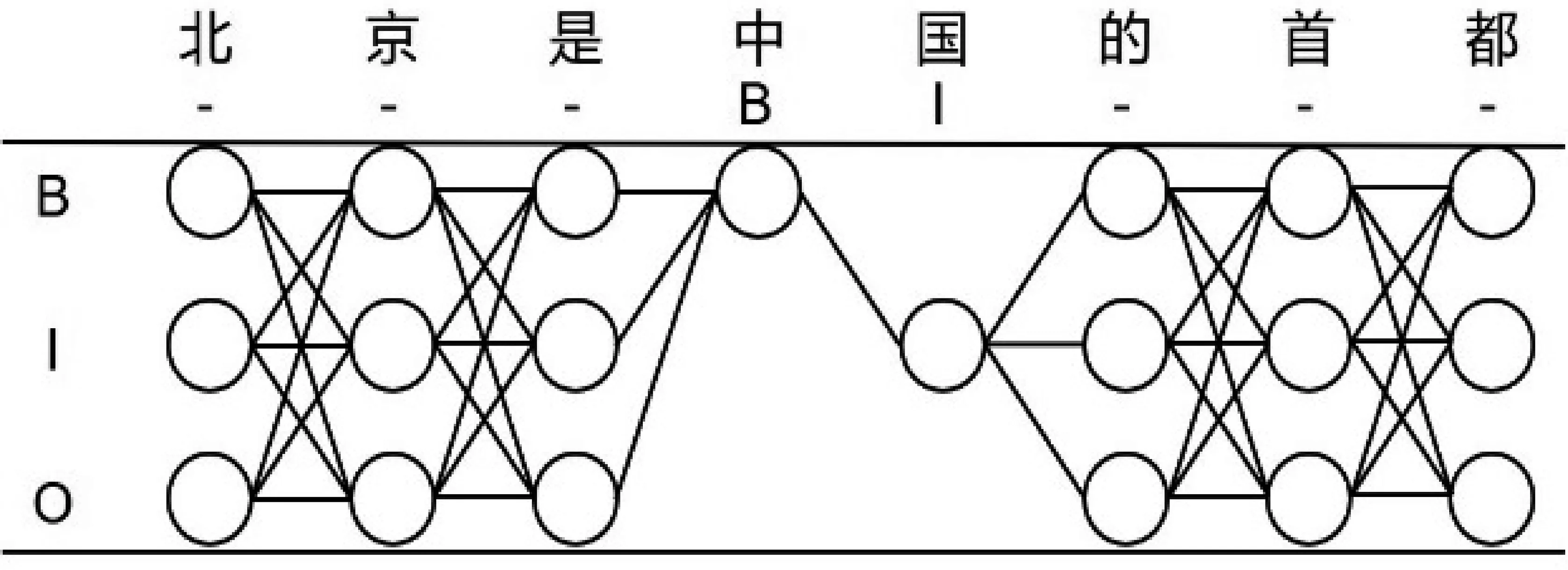
图3 “北京是中国的首都”部分标签数据
在部分标签数据中,对于每个被观测的句子xj,得到的标注序列不是唯一的,而是一个由所有满足约束条件的可行序列组成的集合。如句子“北京是中国的首都”在满足“中国”被标记的条件下,每个字对应的可能标注集合为:
P={(B,I,O),(B,I,O),(B,I,O),(B),(I),
(B,I,O),(B,I,O),(B,I,O)}
设YP是可行序列的集合,那么相应的部分标签数据的损失函数就可以粗略计算为:
2.1.2 标签的经验分布


图4 标签的经验分布

2.2 基于迁移学习的经验分布的计算方法
本文没有使用统计方法计算概率分布。因为在特定领域缺少标注语料,很难准确地统计出每个实体出现的频率。此外,实体类型繁多,训练数据也无法覆盖所有实体。
本文使用模型迁移的方法计算标签的经验分布。模型迁移的本质是通过迁移模型参数将知识从源领域传输到目标领域。源领域数据一般是来自于公共领域的完整标注数据,如本文使用了人民日报语料作为源领域的数据。源领域数据包含了丰富的语义和语法信息,这种底层知识迁移到其他领域同样适用。如连词、助词等在文本中频繁出现的词一定不是实体,而频繁出现的语义近似的词很有可能是实体。

其中,Ai为全连接层的输出得分,L为标签集。
2.3 模型训练
本文训练的三个模型都是相同的Bi-LSTM结构,分别是用于迁移学习的源模型(source model)、用于计算经验分布的目标模型(target model)和输出最终结果的任务模型(task model)。源模型用softmax输出结果,使用交叉熵计算损失。目标模型用softmax输出经验分布,然后加入任务模型,共同使用Partial-CRF计算模型的损失。源模型和任务模型都使用预训练的词向量和随机初始化的字向量。整个模型框架如图5所示。

图5 模型训练框架图
训练顺序如下:
(1) 使用人民日报语料训练源模型,将性能调至最优。然后将参数迁移到目标模型。目标模型的word embedding层、char LSTM层和token LSTM层使用源模型的参数,其余层使用随机初始化的参数。
(2) 将我们的领域数据输入目标模型,输出经验分布;将我们的领域数据输入任务模型,输出BI-LSTM的隐层特征。目标模型和任务模型是同时进行训练的。
(3) 将隐层特征和经验分布共同输入Partial-CRF层计算损失,然后进行梯度下降的过程,同时更新目标模型和任务模型的参数,也可以选择固定目标模型的参数。
3 实验与分析
3.1 实验数据
本文使用的含有部分标签的语料来自于植物病虫害领域和视频领域。提到的源领域模型在1998年人民日报的标注语料上训练。语料的统计信息如表1所示。

表1 语料统计信息
其中,视频领域的语料来自Jie等[10]发布的公开数据集,他们收集了优酷网页上的标题文本,通过移除语料中的实体标记来获得含有部分标签的语料。我们使用该语料作为训练集,并保留了原本语料中的部分实体标记。考虑到很多领域存在一些专有名词本身就属于实体词或实体词的一部分,有效地利用这些专有名词,同样能够得到标注数据中的部分标签。因此我们还构建了植物病虫害领域的部分标注语料,具体实现方法如下:
语料收集和预处理我们在《植物保护》《杂草学报》《农药学学报》《昆虫学报》中搜集了主题为植物保护和病虫害防治的摘要5 062篇,并筛选其中长度为10到100的句子用于本文语料的构建。然后进行了预处理,包括英文大小写转换和中文简繁体转换等。另外,我们考虑到病虫害领域的名称表示方法不统一,可能使用英文缩写、罗马字符和中文。因此,我们将罗马字符和英文缩写统一转换为中文,例如:
(1) 对农药的单位和剂型进行转换,如将“g a.i./hm2”转换为“克有效成分用量每公顷”,将“SC”转换为“分散剂”;
(2) 对病虫害的品种进行转换,如将“Ⅱ代”转换为“二代”;
(3) 对时间单位进行转换,如将“y”转换为“年”,将“M”转换为“月”,将“d”转换为天。
测试集人工标注测试集,标注完成后由专业人员进行校验。另外,由于林业领域的特点,有些病虫害实体中包含植物名称,根据命名实体的标注规则应该对更长的实体进行标记,如将“水稻卷叶螟”标注为病虫害实体,就不再对“水稻”单独标注。
训练集首先收集领域内的词汇构建领域词典,然后基于词典匹配的方法自动地标记出语料中的部分实体,从而得到用于训练模型的部分标签数据,节省了大量的人工成本。本文使用的植物病虫害领域词典包括三类专有名词,分别来自于中国植物信息网和《农药通用名称 GB 4839-1998》,词典规模如表2所示。

表2 植物病虫害词典
然后使用双向最大匹配算法进行匹配得到部分标签数据,该算法综合考虑了正向和逆向的匹配结果。
3.2 实验设置
实验中使用随机初始化的字向量和基于Gigaword语料库[19]训练的100维的词向量。实验的源模型、目标模型和任务模型采用同样的超参数设置,训练模型时均使用Adam算法更新参数。具体的超参数信息如表3所示。

表3 超参数设置
3.3 实验结果及分析
本文采用查准率(Precision,P),召回率(Recall,R)及F值来评估实验结果,相应的计算如式(14)~式(16)所示。
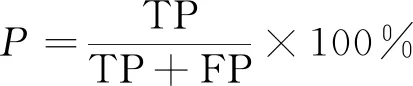
(14)

(15)

(16)
TP(true positives)为所有正样本中被正确识别为正样本的数量,FP(false positives)是指负样本被识别成正样本的数量,FN(False Negatives)是指正样本被错误识别为负样本的数量。
为了验证本文提出方法的有效性,我们设计了五组实验,具体实验结果如表4和表5所示。

表4 植物病虫害语料的实验结果

表5 优酷语料的实验结果
Dict-Matched:为了测试实体词典的覆盖程度,我们在植物领域的数据集上进行了词典匹配的实验。使用领域词典中的实体词对测试集的数据进行匹配,匹配算法是双向最大匹配;
BiLSTM-CRF:将部分标签数据中的未被标注的字符标记为“O”,然后训练基础模型,最后用该模型在测试集上进行命名实体识别;
Transfer:用人民日报语料训练源模型,并将参数迁移到与源模型结构相同的目标模型。用部分标签数据对目标模型进行微调后,在测试集上进行命名实体识别;
Ours-Frozen:用本文提出的方法同时训练目标模型和任务模型,训练过程中保持目标模型的参数不变,仅优化任务模型的参数,最后在测试集上进行命名实体识别;
Ours-Finetune:用本文提出的方法同时训练目标模型和任务模型,训练过程中使用相同的学习率,更新两个模型的全部参数,最后在测试集上进行命名实体识别。
从表4的结果可知,Dict-Matched方法取得了最低的召回率,这说明尽管领域词典的规模很大,但仍有很多词覆盖不到,主要原因有二:一是由于领域知识更新迭代较快,出现了很多新词;二是由于大多数实体词是两个专有名词的组合或嵌套形式,词典匹配的方法无法识别。在植物病虫害数据集上,BiLSTM-CRF比Dict-Matched方法的召回率提高了19%,说明了字向量和词向量相结合的BiLSTM能够捕获词边界特征和句子的全局信息。Transfer方法在两个数据集上的识别效果都有所提升,说明了不同领域间底层的语义和语法信息是具有共性的,具有相同目标的不同领域可以通过共享模型参数的方式共享知识。本文提出的方法使查全率和查准率都保持在一个稳定的水平,F值在两组数据上分别提高了11%和10.8%。我们的方法比迁移学习的方法效果好,说明经验分布的使用增大了未标记位置被识别的概率,在一定程度上增大了召回率。对比Ours-Frozen方法和Ours-Finetune方法,发现在训练时对目标模型的参数进行微调,能够提升模型的识别效果。
本文在人民日报语料上预训练的模型查准率为90.5%,召回率为91%,F值为90.75%。Ours-Finetune方法在迁移的过程中损失了将近10%的性能,但仍然比Transfer方法的效果要好。说明本文提出的方法也降低了外部语料在部分标签语料上的迁移损失。
我们还在优酷语料和植物病虫害语料上对近几年来的方法进行了比较,实验结果如表6、表7所示。其中,Hedderich等[21]在BiLSTM模型的基础上添加了噪声适应层,可以有效地纠正部分标签数据中的错误信息,但仍需要人工标注少量的数据。Greenberg等[12]基于LSTM模型和边际条件随机场模型(marginal conditional random field),把少量部分标签数据和标准数据集一起训练,取得效果要比单独使用标准数据集更好。Jie等[10]同样使用了边际条件随机场模型(Marginal CRF),他们将部分标签数据分为若干份,通过自训练迭代模型预测剩余一份的标签,经过多次交叉验证得到最终的训练数据。实验证明,经过自训练得到的数据能够有效提高模型的召回率。

表6 不同方法在植物病虫害语料上的对比

表7 不同方法在优酷语料上的对比
由表6和表7可以看出,Greenberg[12]的方法查准率最低,我们认为边际条件随机场是给模型加入了一个均匀分布,将未标记的字等可能视为实体或非实体标签,这样虽然可以最大程度地召回文本中的实体,但也导致大量的非实体被错判成实体。本文提出方法的F值比最好的方法分别提升了2.8%和1.1%,是因为使用外部知识模拟了标签的经验分布,在增大了召回率的同时,也对未标记位置构成约束,使召回率和查准率达到平衡。
4 结论
命名实体识别作为自然语言处理领域的基础任务,有着非常重要的作用。目前,命名实体识别在新闻、生物等领域已经取得了很好的成绩,但在一些缺乏标注数据的领域,效果不够理想,且获得标注数据需要耗费成本。针对这种情况,本文提出了一种基于部分标签数据的命名实体识别方法。考虑到部分标签数据中含有噪声信息,会降低模型的识别效果,本文通过迁移学习计算标签的经验分布,约束样本在模型训练过程中的权重占比,从而使部分标签数据更接近于真实数据的分布。在两个数据集上的实验结果表明本文提出的方法是有效的。我们在计算标签的经验分布时仅使用了模型迁移的方法,所获得的底层知识较少,在未来的研究中可以尝试更有效的迁移方法。
