基于深层语言模型的古汉语知识表示及自动断句研究
2021-05-27胡韧奋诸雨辰
胡韧奋,李 绅,诸雨辰
(1.北京师范大学 中文信息处理研究所,北京 100875;2.北京师范大学 汉语文化学院,北京 100875;3.北京师范大学 文学院,北京 100875)
0 引言
汉语典籍记载和文献编纂有着悠久的历史,涵盖政治、历史、哲学、文学等各领域。中国人也尤其注重古籍的整理与利用,《永乐大典》《四库全书》都是历史上重要的文献整理工程。然而,古典文献的一个重要特点是不使用标点符号,这与古人因声求气、涵咏情性的文化有关,却给现代读者带来了困难。因而古文句读便成为当代古籍整理中一项非常重要的工作。
然而,古文句读却对专家知识有极高要求,因为句读不仅需要考虑当前文本的意义和语境信息,还需要综合历史文化常识。宋代大儒朱熹读韩愈文章,便有“然不知此句当如何读”[1]之惑。近代经学大师黄侃在致陆宗达的信中也表示“侃所点书,句读颇有误处,望随时改正。”[2]
在现有的古籍数据中,大部分尚未实现句读。据本文统计,殆知阁古代文献藏书2.0版语料库规模约33亿字,其中仅25%左右数据包含标点,可见古籍整理是一项浩大的工程,自动句读技术有强烈的现实需求。
自然语言处理技术的发展使得自动断句成为可能。张开旭等人[3]提出一种基于条件随机场的古文自动断句方法,对《论语》和《史记》的文本进行实验,其《论语》断句的F值达到76%左右,而《史记》断句的F值则在68%左右。王博立等人[4]提出一种基于循环神经网络的古文断句方法,采用基于GRU的双向循环神经网络进行古文断句,该模型对古文断句的F值达到74%~75%。由于现有模型对文本意义和语境信息理解并不充分,断句效果距离实用尚有距离,还需要进一步提升。
近年来,ELMO、BERT等预训练语言模型极大地提升了语言信息表示的效果,并在文本分类、语言推断、文本生成、阅读理解等一系列自然语言处理任务中取得了突出的成绩提升[5-6]。然而,现有的语言模型多基于大规模百科或新闻语料训练,缺乏古汉语语言知识编码。为了改进现有古文断句模型,促进古汉语信息处理技术的发展,本文在33亿字古汉语语料库上训练深层语言模型,实现了古汉语知识的高效表示,并在此基础上利用条件随机场和卷积神经网络学习句读模型。系统在诗、词和古文三种文体上开展了测试,其F1值分别达到99%、95%和92%以上,在断句难度较高的词和古文文体上,本文方法较之王博立等人的双向GRU模型界值提升幅度达到12%以上。
与前人工作相比,本文的贡献体现在以下几个方面:首先,通过深层语言模型实现了高质量的古汉语知识表示,使模型在“理解”的基础上句读;第二,根据断句任务中语言特征和标签信息之间的关系,设计了深层语言模型+条件随机场(BERT+CRF)、深层语言模型+卷积神经网络(BERT+CNN)两种序列标注方法,较之传统神经网络方法取得了显著的性能提升。从评测效果看,本文提出的断句方法在多种类型语料中均取得了实用级效果,并能有效检测出已出版古籍中的断句错误。此外,为了更好地服务古籍整理和文献研究,我们构建了在线古诗文断句工具(1)https://seg.shenshen.wiki/。
1 基于深层语言模型的古汉语知识表示
1.1 神经词向量表示方法
语言知识表示是自然语言处理技术的重要基础,在现有的模型中,通常以词语为单位进行语言特征表示。为了将词义信息编码到词语表示中,Mikolov等人[7]提出了一种神经词向量(neural word embeddings)表示方法,并发布了训练词向量的工具包Word2Vec。其模型基于语言学家Harris[8]提出的词义分布假说:上下文相似的词,其意义也相近。具体来说,词向量的训练基于大规模语料库,依次取中心词和它左右两边的上下文词,通过神经网络模型构建两种预测方式:利用上下文词语预测中心词(CBOW模型),利用中心词预测上下文词语(Skip-gram模型)。通过训练,可以得到定长的稠密实数词向量,其维度通常为50~300,每一维均由一个实数表示。与Word2Vec类似,利用词语和上下文的共现信息,Pennington 等人提出了GloVe 模型[9],Levy和Goldberg提出了正值逐点互信息模型 (PPMI)和奇异值分解模型(SVD)[10]。
神经词向量表示能够较好地捕捉词语的语法和语义性质,例如,“麦克风”和“话筒”向量的cosine相似度极高,甚至还可以实现“国王”-“男人”+“女人”≈“王后”、“天”-“天天”+“人人”≈“人”这样的词法、词义推理[11]。这种词向量表示方法被广泛运用到文本分类、机器翻译、语义搜索、自动问答等各种自然语言处理任务中,大大提升了自然语言理解和生成的效果。
在古汉语特征表示领域,Li等人[11]基于《四库全书》训练了古汉语字义表示,图1给出了其向量空间经PCA降维后一个局部区域的汉字分布情况。由图可见,该区域语义表示与数字、时间等概念密切相关,形成了较为明显的数字词簇和时间词簇,如单位“千、百、万”,数词“一”到“九”,序数词“甲乙丙丁戊己庚辛”,时间词“日夜月夕”“年岁”等。
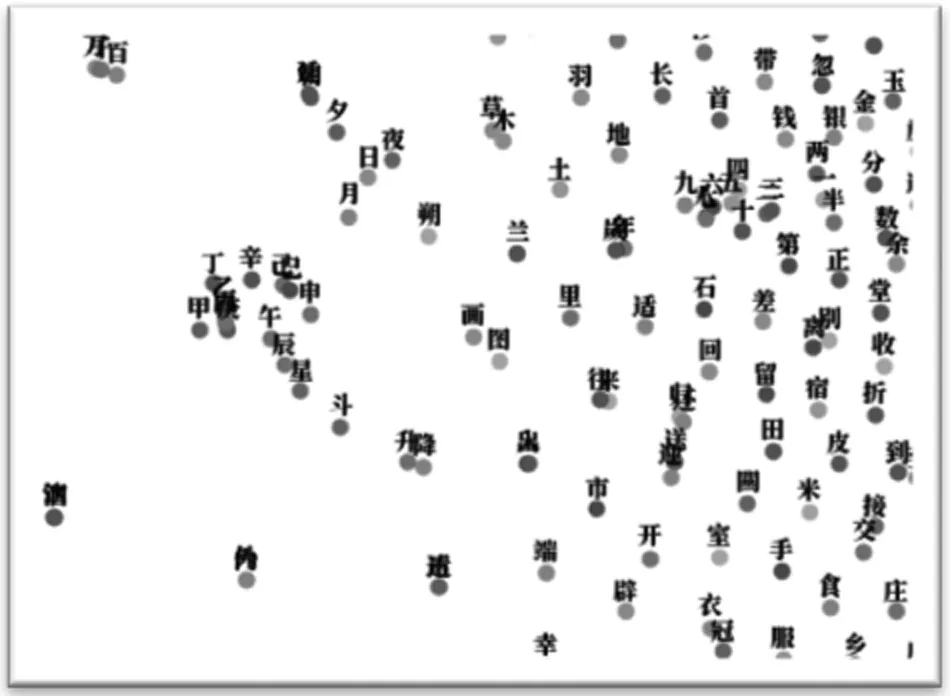
图1 古汉语神经词向量示例
然而,传统的词向量表示方法仍然面临一个突出的问题:即仅能为每个词获取一个词向量,无法区分同形词和多义词的不同义项。在古代文言文表达中,往往单字成词,每个单字词可承载的意义极为丰富,其同形词和一词多义现象比现代汉语更为突出,这不仅为现代人理解文言文含义造成困难,也为计算机表示古汉语带来了挑战。为了有效解决这个问题,本文引入了基于深层语言模型的古汉语知识表示方法。
1.2 深层语言模型表示方法
1.2.1 BERT模型
本文参考Devlin等人提出的BERT模型学习古汉语知识表示,并将自动断句作为下游任务对整个网络进行微调(fine-tuning)。BERT模型可以基于大规模语言数据学习上下文敏感的词语和句子表示(contextual embeddings)。与Word2Vec同一词形仅能生成一个词向量不同,预训练的BERT模型可以联系上下文“理解”词义,为词语“订制”独一无二的语境向量表示,从而很好地解决同形词和一词多义问题。BERT模型的学习主要涉及两个核心模块:编码器和目标任务,本节将分别对两者进行介绍。
在编码器的选择上,BERT采用12层或24层Transformer模型进行特征学习。如图2所示,Transformer模型的输入为字符向量、片段向量和位置向量之和。模型内每一层由两部分组成:多头自注意力(multi-head self attention)和全连接神经网络(fully connected neural networks),每个网络的输出均经过层归一化操作(layer normalization)。其中,多头自注意力网络中每个隐单元的输入均由上一层隐单元输出加权平均得到,使得每个隐单元均能和上一层所有隐单元直接关联,这样一来,每个隐单元都可以较好地编码全局语义信息。

图2 古汉语知识表示模型的输入和输出示例
在目标任务上,BERT模型采用了完形填空和句子预测这两项任务。在完型填空任务中,15%的单词会被选中,其中,80%被替换为[MASK],10%被替换为一个随机词,10%保持不变,模型需要据此预测被选中的词。在句子预测任务中,模型需要判断句子A和B是否相邻。通过两个目标任务,语言模型能够同时捕捉词语和句子级别的语言知识。
1.2.2 古汉语知识表示
在训练BERT模型时,Devlin等人采用字级别中文维基百科语料库训练了中文语言模型,其编码以句子为单位。本文在此基础上引入海量古汉语语料库进行增量训练,考虑到古汉语句子长度较短,且大量训练数据不含断句和标点信息,本文将段落作为输入单位。
如图2所示,训练模型时,输入字符串S,Transformer模型首先将其转换成字符序列,在开始和结束位置处添加[CLS]和[SEP]标签,并给出其位置和片段信息,将三者向量求和作为模型输入。输入向量经过预训练模型编码,在每个位置都可以得到对应的输出Ctoken,每个输出均为一个768维的语境向量。其中,[CLS]对应位置的语境向量可视为编码了整个片段的语义信息,常作为下游文本分类任务的输入。
与Word2Vec训练产生的词向量相比,BERT模型输出的语境向量能够编码细粒度的词义信息,表1以“安”为例,给出了两种模型的最近邻信息。计算BERT模型最近邻时,我们从《论语》中选取了四条“安”含义不同的语料,经预训练模型编码,获取了“安”在不同上下文中的语境向量,随后以《史记》语料为查找对象,找到与其最相近的语境向量表示。由表中内容可见,基于Word2Vec模型的最近邻词语聚焦在表示“安宁”“平安”“使安定”意义的古汉语词汇上,而BERT模型可以针对句中词语根据当前上下文给出语境向量表示,因而能够捕捉细粒度的词义信息。

表1 “安”的最近邻示例
2 古汉语自动断句模型
预训练语言模型不仅可以实现高效的古汉语词义表示,还可通过微调(fine-tuning)机制接入下游任务,如文本分类、序列标注、语义推理等。在微调过程中,伴随下游任务的训练,整个语言模型的参数也随之迭代更新。
自动断句模型可以被视为一个典型的序列标注任务,即输入字符串,针对每个字符预测在该位置是否断句,例如,输入“君子食无求饱居无求安”,模型应预测“OOOOOSOOOO”,其中,“O”表示该位置后不应断句,“S”表示“饱”后应断句。Devlin等人在BERT模型的基础上提出了基于全连接神经网络分类器的序列标注方法,并在CoNLL-2003命名实体识别任务上取得了最优效果,其模型结构如图3(a)所示。这种序列标注方法虽然能够利用BERT模型输出的高效语义表示做标签预测,但存在收敛速度慢、未考虑标签之间的依赖关系等问题。为了改进序列标注方法,本文基于深层预训练语言模型引入条件随机场(CRF)和卷积神经网络(CNN)模型,实现了更为高效、准确的中文断句方法。
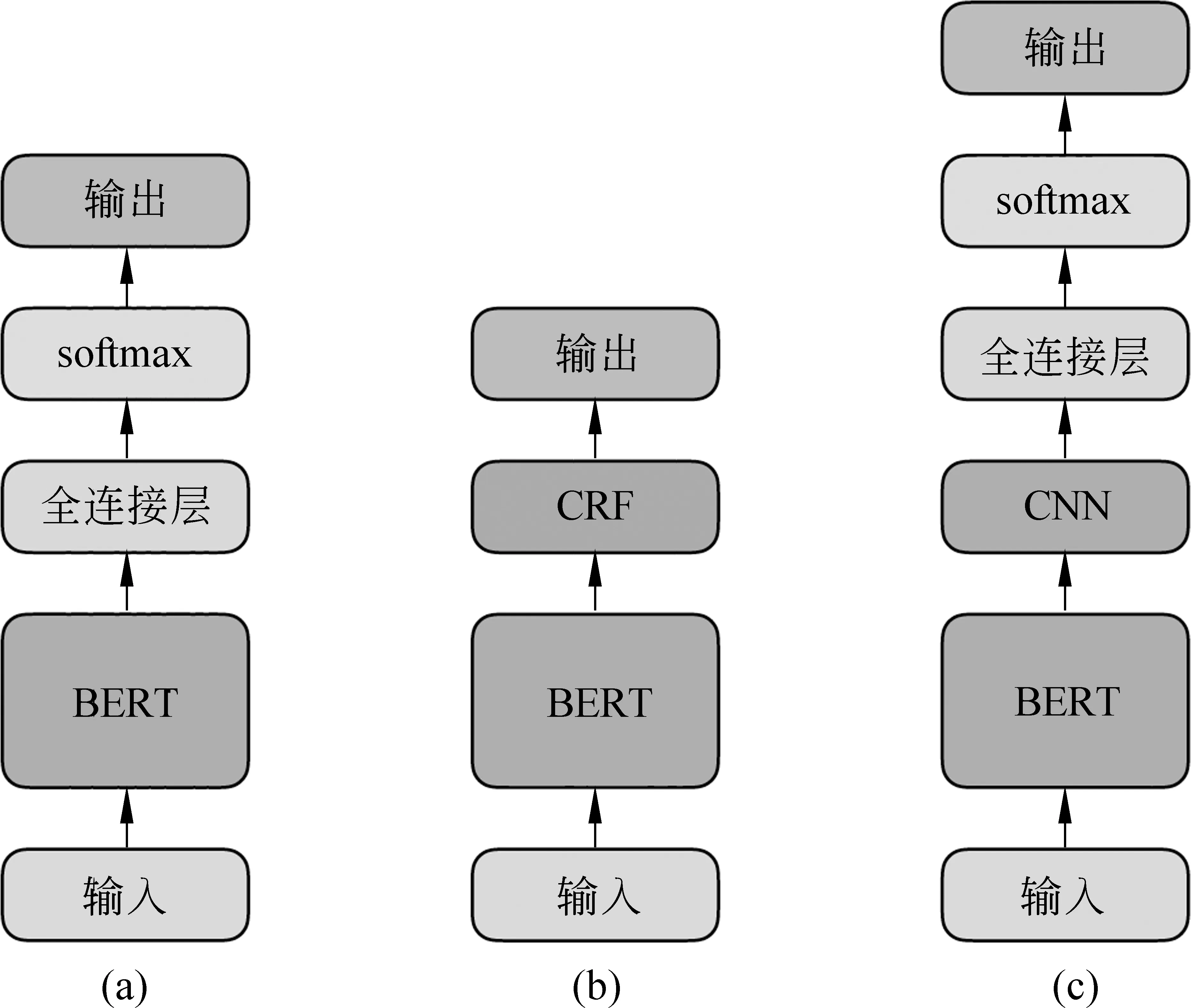
图3 古汉语自动断句模型结构图
条件随机场是一种经典的序列标注模型,在中文分词、词性标注、命名实体识别等自然语言处理任务中均有着广泛应用[12]。伴随神经网络模型的兴起,Huang等人[13]在双向长短期记忆网络(Bi-LSTM)上添加了CRF层,用于求解概率最优的标签路径,在一系列序列标注任务上取得了明显的效果提升。
受前人工作启发,本文将条件随机场模型接入深层语言模型,其结构如图3(b)所示。通过观察BERT+CRF模型的预测结果,我们发现由于CRF模型预测时仅能考虑当前位置及之前位置的特征,未能充分地利用上下文信息进行断句,造成了一些断句错误,例如:
BERT+CRF:行未三四十里 ○ 忽乌剌赤者急下马拜跪 ● 伏其言 ● 侏离莫能晓 ○ 而其意则甚哀窘
该例中的句读重点有二:一是“拜”“跪”“伏”为连续的动作,二是“其言”与后文的“其意”呼应,均应作主语。
为了进一步提升模型对上下文语言特征的编码能力,本文在BERT模型基础上引入卷积神经网络做特征抽取,并基于其编码结果利用一层全连接神经网络实现断句标记分类,其结构如图3(c)所示。由于CNN模型能够通过卷积对两侧上下文信息进行编码,综合决策后作出了正确的断句决策,结果如下所示:
船型组合③:A、B泊位停靠2000DWT杂货船:15 + 86 + 50 +125 + 22.5 = 298.5m < 300m
BERT+CNN:行未三四十里 ○ 忽乌剌赤者急下马拜跪伏 ○ 其言侏离莫能晓 ○ 而其意则甚哀窘
3 实验及评估
3.1 数据集
古汉语深层语言模型训练基于殆知阁古代文献藏书2.0版语料库(2)http://www.daizhige.org/,共计33亿字,由于数据中繁简体字混合出现,考虑到繁转简准确率更高,在预处理阶段采用zhconv工具(3)https://pypi.org/project/zhconv/将文本统一转成简体。
在自动断句任务中,我们从Github中华古诗词数据库(4)https://github.com/chinese-poetry/chinese-poetry中获取了带标点的古诗词数据,其中诗311 691首,词20 643首,从殆知阁古典文献藏书2.0语料库中获取带标点的文言文语料8 163 988条(以段落为单位)。由于诗词具有较为明显的格律特征,如大部分古诗为四、五、七言,而词牌名可以提示断句规则,为了帮助模型更好地学习语义和韵律信息,在预处理数据时保留了古诗题目,并去除词牌名。针对数量较少的词数据,取10%作为测试集,针对数量较多的古诗和文言文数据,各取5 000条作为测试集,其余诗、词、文言文数据合为训练集,并从训练集中随机抽取10 000句作为验证集。
3.2 模型及参数设置
古汉语BERT模型训练采用12层Transformer模型,hidden size为768,自注意力机制的head数量为12,总参数量为1.1亿,采用4块1 080Ti型号的GPU并行训练100万步得到语言模型。
在断句模型上,本文将王博立等人[4]提出的双向GRU模型(Bi-GRU)作为基线(baseline)模型,实验中将GRU模型的hidden size设为256,考虑到本文训练数据规模远大于文献[4]中的数据集,我们另增加了一组hidden size为2 048的实验。此外,将Devlin等人提出的BERT+全连接层(fully connected layer)序列标注模型应用到断句任务中(简称为BERT+FCL),并构建了 BERT+CRF与BERT+CNN模型。其中,CRF层采用Tensorflow默认设置,CNN层使用了100个宽度为3的卷积核,用于抽取特征。所有模型均训练到验证集收敛为止。
3.3 实验结果
五组模型的断句实验结果如表2所示。从测试数据类型的角度看,无论是双向GRU模型,还是融入深层预训练语言模型的方法,均呈现出古诗断句效果最优、词次之、古文再次之的特点,这与文体表达的规律性和韵律性密切相关,也折射了不同文体断句难度的差异。

表2 断句模型实验结果
从模型表现的角度看,集成BERT深层预训练模型后,与基线模型相比,三种模型在三类文体上的断句效果都得到了巨幅提升。其中,古诗断句F1值接近100%。在语言表达较为灵活、多样的词和古文测试集上,综合表现最优的BERT+CNN模型,比之Bi-GRU2 048模型提升幅度达到10%以上,词断句F1值达到95%以上,古文断句F1值达到92%以上。
此外,通过观察基线模型Bi-GRU的实验结果,不难发现,其断句召回率(R)大大低于精确率(P),即大量断句标记未被识别,这一特点在难度较高的文体(词、古文)上表现尤为突出。融入深层语言模型后,断句召回率与精确率基本持平,均达到了较高的水平。在集成预训练模型的三种方法中,BERT+CRF和BERT+CNN与BERT+FCL相比均有小幅提升。
通过分析测试数据(表3),我们发现,由于深层语言模型可从海量数据中学习语言知识表示,在古汉语领域,其优势具体体现在以下两个方面:
第一,能够较好地捕捉古诗文表达的节奏感和韵律感,例如,表3第1、2句。其中,句1为五言诗,句2为长短句交错的词,该二例断句与节奏、韵律关联紧密,而Bi-GRU模型未能捕捉这种语言表达性质,因而出现了应断未断(“日后”“瑶台月”“心事”处)与不应断而断(“攀”处)错误,三种集成预训练语言模型的方法均能正确识别。
第二,对上下文信息的利用较为充分,如表3例句3、4所示。其中,句3需联系前文理解“行修”为夫君,其所娶妻子“贞懿贤淑”(主谓搭配),“行修”对其十分尊敬(主谓搭配)。句4中,“齐人”“宋人”“邾娄人”为并举,模型需联系上下文在三者之间句读,此外,“伐郑”与“救郑”前后呼应,二者之后均应断句。“书者……”是对“伐郑—救郑”事件的点评,意为《春秋》记载这件事,是在称赞中原国家可以互救。
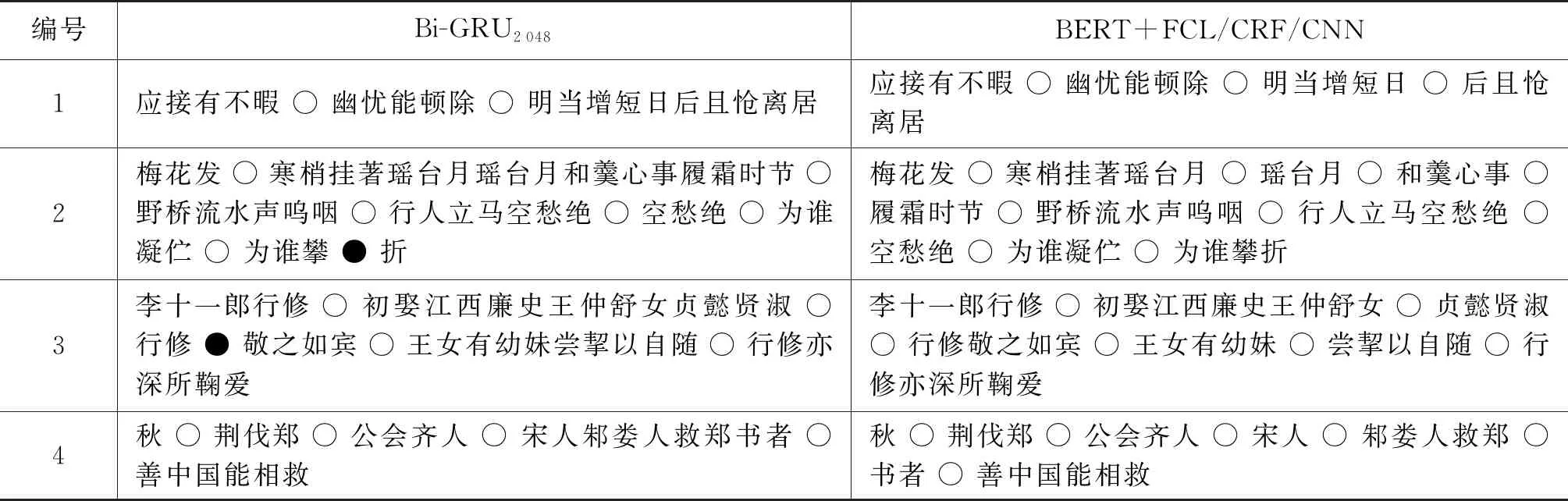
表3 模型断句示例
综上来看,深层语言模型所编码的古汉语知识在一定程度上涵盖了语序、语法、语义、语境等多层次的语言信息,对于后续的自然语言处理任务有重要的贡献。
4 案例应用分析
为了进一步验证BERT模型在处理断句任务中的应用效果,我们根据司马朝军[14]、颜春峰和汪少华[15]等学者的研究,搜集了已出版古籍文本中65则与断句相关的错误案例,并排除了在训练集中出现过的5则语料,得到60则测试数据。其中,11则来自中华书局1997年版《钦定四库全书总目》,49则来自中华书局1987年版《周礼正义》。这两本古籍均由该领域专家完成整理和句读标点,并经多次校对,其中的误例可谓句读任务的难点所在。
《钦定四库全书总目》由李学勤作序,是今人重要的古籍整理成果。我们从司马朝军的研究中找出了11则与断句相关的标点错误,其分别在《春秋后传》《春秋谳义》《数学九章》《姑溪词》等条中,覆盖了经部、子部、集部三类典型文献。我们将这11例去除标点后作为输入,由模型进行断句,其中,8则模型完全断句正确,3则断句不完全正确。试举正误例各一如下:
例1柏何人,斯敢奋笔而进退孔子哉?(《诗疑》第216页)
作者按:“斯”字上属。“何人斯”为上古习语(5)《诗经·小雅·何人斯》:彼何人斯?其心孔艰。。
当作:柏何人斯,敢奋笔而进退孔子哉?
模型:柏何人斯 ○ 敢奋笔而进退孔子哉 (模型断句正确)
例2其中如“大衍”类蓍卦发微,欲以新术改《周易》揲蓍之法,殊乖古义。古历会稽题数既误,且为设问,以明大衍之理。(《数学九章》第1 406页)
作者按:此段标点有破句。
当作:其中如“大衍”类蓍卦发微,欲以新术改《周易》揲蓍之法,殊乖古义、古历。会稽题数既误,且为设问,以明大衍之理
模型:其中如大衍类蓍卦发微 ○ 欲以新术改 ○ 周易 ○ 揲蓍之法 ○ 殊乖古义 ○ 古历会稽题数既误 ○ 且为设问 ○ 以明大衍之理 (模型断句存在错误)
考虑到上古语言与中古语言的差异,为了验证断句模型在处理上古语言时的效果,我们又选择王文锦、陈玉霞点校的《周礼正义》一书,将颜春峰和汪少华整理的49则断句误例送入模型测试。其中,模型能正确断句27则,断句不完全正确的有22则。
《周礼正义》的模型断句误例中,较为集中的是对字义的考证,尤其是引《说文》时的错误,比如 “服,牝服,车之材”误断作“服牝,服车之材”。“服”作为《说文》中的字头,其用法与其他古文表达有较大区别。此外,因盟誓、考课、葬礼等礼仪制度不明而致误亦有数例。
从经典古籍中的断句疑难案例可以看出,本文提出的自动断句方法在处理古籍一般句式表达时有明显优势。而在处理《说文》、古代制度等专业性较强的数据时尚存在问题,这与该类型数据相对较少有关。总的来说,本文方法在已出版古籍的断句疑难误例上取得了很好的效果,测试共计60例(均为专家标点错误,并经多次校对未查出),而模型能完全正确断句35例,达到了较为实用的水平。
5 总结与展望
古汉语信息处理技术在古籍整理和古代文献、文学研究中扮演着重要的角色。为了实现高效的古汉语知识表示,本文基于33亿字古汉语语料库学习深层语言模型,并在此基础上实现了高精度的断句模型,在诗、词和古文三种文体上,模型断句F1值分别达到99%、95%和92%以上。通过分析实验数据,我们发现模型能较好地捕捉诗词表达的节奏感和韵律感,也能充分利用上下文信息,实现语序、语法、语义、语境等信息的编码。在进一步的案例应用中,本文方法在已出版古籍的断句疑难误例上也取得了较好的效果。
从应用角度看,本文提出的断句方法既可以用于大规模古籍整理中预断句工作,大大减轻专家负担,也可用于校对环节,帮助检测人工断句或标点的错误。在后续工作中,我们希望将基于深层语言模型的古汉语知识表示方法应用到古文翻译、古诗文创作等其他古汉语信息处理任务中去。
