土壤重金属数据异常识别方法
2021-05-26沈惠雅李晓岚潘瑜春冯登超刘振民杜鹏飞
沈惠雅 李晓岚 潘瑜春 冯登超 刘振民 杜鹏飞

摘要:土壤重金属调查数据中的异常往往会导致评价分析结果与真实分布情况产生偏差和错误,直接影响后续的决策管理。针对传统异常值检测中邻域范围的确定偏于主观,且异常值检测后无法识别其类型的问题,提出了一套土壤重金属异常识别方法。该方法基于K临近法确定重金属合理稳定的最佳邻域区间,结合局部空间自相关法识别空间异常值,基于相关性分析识别土壤重金属异常类型。以北京市2006年铅(Pb)和铜(Cu)重金属含量为例,将该方法与其他方法结合进行变异特征和插值预测精度评价分析。结果显示,Pb和Cu含量存在稳定的邻域区间,其中6号点位的Pb、Cu含量,39号点位的Cu含量存在异常;前者异常类型疑似真实异常,后者异常类型疑似数据错误;将原始样点进行全局、局部和疑似数据错误异常样点剔除后,样本总体的离散程度降低,样本空间自相关性程度及区域结构性变异趋势增强;剔除全局和局部异常点后,数据空间插值误差明显减小,去除疑似数据错误异常点后插值误差较去除局部异常点时的插值误差基本一致。说明原始样点中对判断为疑似数据错误的样点进行剔除后对整体插值估计影响甚微,证明该土壤重金属异常识别方法的有效性和准确性。
关键词:异常值识别方法;异常值类型;北京;重金属
中图分类号: X53文献标志码: A
文章编号:1002-1302(2021)08-0219-07
收稿日期:2020-07-23
基金项目:国家重点研发计划(编号:2017YFD0801205);研究生创新资助项目(编号:YKY-2019-20)。
作者简介:沈惠雅(1995—),女,河北保定人,硕士研究生,主要从事空间数据分析研究。E-mail:shenhuiya_net@163.com。
通信作者:潘瑜春,博士,研究员,主要从事土壤信息技术研究。E-mail:panyc @nercita.org.cn。
土壤重金属污染调查检测中,土壤重金属的检测值反映了污染程度,其数据质量会影响区域污染状况的评价结果[1]。通常由于人为或自然因素等,调查结果存在某些异常情况,这些异常数据往往会造成土壤重金属空间分布情况的分析结果产生偏差和错误。其中,由于自然因素或人为生产活动导致土壤重金属含量异常,客观反映了土壤重金属进入土壤导致局部土壤含量明显高于或低于周围土壤的情况,对于这类异常数据应当予以保留。而由于人为测量失误、仪器系统误差等原因,导致土壤重金属实际含量与正常值产生偏差,对于这种异常数据应当予以剔除。因此,在对土壤重金属调查数据的处理和分析过程中,有必要对调查数据进行异常值检测和识别。
目前基于空间数据异常识别的研究主要分为2种:基于属性邻域识别空间数据的属性值异常和基于数据空间邻域识别空间异常。基于数据属性邻域识别空间数据的异常主要采用统计学方法检测空间数据的异常值,常见的为基于分布方法、统计判别法[2-3]和统计聚类检验法[4-5]等。这些方法均是只基于数据属性邻域的统计学方法,可以识别空间数据的全局异常情况,但由于没有考虑空间数据的空间自相关性,无法检测出局部数据是否存在异常。而基于数据空间邻域识别空间异常主要通过建立空间数据的邻域关系,基于空间自相关性来检测数据异常[6-8]。这类方法能够检测一定邻域范围内的局部异常,但是在确定邻域范围时一般是基于经验值,具有一定的主觀性,并没有考虑确定邻域范围对异常识别的影响。目前已有一些研究基于邻域范围展开数据相关性程度及异常检测等相关研究[9-11]。如杨冕等通过K临近方法探讨了长江经济带PM2.5在稳定邻域范围内的空间自相关程度[12]。邓敏等通过聚类分析获取空间相关性较强的簇,并考虑空间数据的局部相似特性,挖掘同一数据集中不同分布中的局部空间异常[13]。这些方法根据研究区的特点通过设定不同空间邻近关系,确定区域存在的异常情况,但是缺少对异常类型的进一步分析。
对土壤重金属调查数据的异常识别,须要充分考虑在合理的邻域范围内结合土壤重金属调查数据的空间分布情况,进行异常值检测和异常类型识别。因此,本研究提出一套土壤重金属异常识别方法,该方法通过基于K临近法确定合理稳定的最佳邻域范围,结合局部空间自相关法对空间异常值进行识别,并基于相关性分析对异常值类型进行判别,同时以2006年北京市土壤重金属污染调查数据为例,对异常识别效果进行分析,以期丰富土壤重金属数据异常识别方法,为土壤重金属数据分析和评价工作提供辅助支撑。
1 材料与方法
1.1 研究区概况
北京市地处华北平原西北部,地形西北高、东南低,属大陆性季风气候,平均日照时数在2 000~2 800 h,农作物生成期225 d左右,土壤类型以褐土和潮土为主,另外包含少量水稻土、沼泽土和风沙土;西部、北部多分布褐土,东南部多分布潮土、湿潮土等。土壤成土母质为各类岩石风化物和第四纪疏松沉积物。受成土母质和地形的影响,北京市近郊区的种植物以果树、蔬菜为主,远郊区种植物以小麦、水稻和玉米为主[14]。
1.2 样品的采集与处理
本研究采用2006年北京市72个农田土壤重金属样点数据,点位分布情况如图1所示。采样时利用GPS获得样点地理坐标并详细记录采样点周围环境情况。测定方法按农业化学常规分析方法,每个样点单元均是边长为10 m的正方形,每个采样点采集土壤耕层(0~25 cm)3~5个点,按四分法将1.0 kg待分析样品混合。所有土样在室内自然风干,碾压磨碎后,过100目尼龙网筛。分析过程中加入国家标准样品进行分析,质量控制按照 GB 15618—2018《土壤环境质量 农用地土壤污染风险管控标准》执行完成。
1.3 异常识别研究方法
本研究提出的土壤重金属异常识别方法主要包括3个方面。
首先,基于K临近距离,确定空间中合理稳定的研究区间。空间样点的距离关系将邻近结构限制为K个最近的近邻点,使得每个区域单元都有相同数量的近邻点[15]。通过设定K值,形成基于K个点的空间邻近关系,邻近点的空间邻接矩阵中对应项为1,否则为0。为下一步进行空间自相关分析提供权重基础。
其次,基于空间自相关的异常值测度指标,以空间自相关理论中的局部莫兰指数方法进行异常值测度,确定每类重金属异常点个数和高低、低高的异常类型。
最终,基于相关性分析识别土壤重金属异常类型。针对不同重金属元素之间存在紧密的相关性,各重金属既作为检测指标,也作为其他数据的辅助指标。本研究以较强相关性的检测指标和辅助指标展开分析,针对两者的异常值分布判断点位存在的异常类型。
1.3.1 K邻近距离的空间邻域确定方法
在异常值检测中,邻域范围标志着空间范围内样点数据的参与检测程度,这直接影响土壤重金属异常检测的结果,因此有必要确定一个合理稳定的邻域范围,从而保证异常值检测结果稳定有效。因此,本研究采用基于K临近距离的方法来确定稳定的空间邻域分布。该方法的基本原理如下:首先,K临近法设定每个点周围指定的K个临近点,根据K值的不同,生成不同大小的邻域值。通常由小到大选取K值,每个要素至少具有1个相邻要素,随着K值逐渐增大,临近要素过多会导致小尺度的空间信息减弱或丢失,此时探测稳定的邻域区间非常关键。其次,在每个重金属临近K值的探测过程中会利用局部莫兰指数产生异常值,这一过程一直持续,到产生稳定的空间邻域区间探测。最终,在生成的空间权重矩阵中,临近的K个点在矩阵中的结果为1/K。局部莫兰指数依次利用各个1/K值生成的权重矩阵对空间点分布重新定义,生成不同权重矩阵对应下的异常值分布情况。
1.3.2 空间自相关-局部莫兰指数
地理学第一定律为:任何事物都是与其他事物相关的,越相近的事物关联越紧密[16]。几乎所有空间数据都具有空间依赖性或空间自相关特征。空间自相关是空间数据中,空间单元与邻近单元之间针对同一属性值存在潜在的相互依赖的特性。空间自相关分析分为全局自相关和局部自相关分析。全局自相关度量了空间邻近的区域单元中单元属性值之间的相似程度。局部自相关进一步分析了观测值的高值或低值聚集、高低或低高异常值分布。局部莫兰指数表达式如下:
I=(Xi-X)S2∑nj=1Wij(Xi-X);(1)
S2=1n∑ni=1(Xi-X)2;(2)
X=1n∑ni=1Xi。(3)
式中:I为局部空间自相关指数值;Xi是某一变量在空间单位i上的实测值;X是变量的均值;S2为空间单元i属性观测值的标准化值;n是变量观测值总数,个;Wij是空间单元i与j 之间的空间权重。
1.3.3 土壤重金属异常类型识别方法
不同元素含量之间的相关性分析可以反映各个元素的来源是否相同。因此,相关性分析可以识别土壤重金属来源[17-25]。在土壤重金属相关性分析中,各个重金属作为检测指标,根据土壤形成特点和土壤中重金属的来源情况,可以将植被类型、土壤类型、地貌类型等作为相关性分析中的辅助指标进行分析。若一组指标具有强相关性,说明检测数据受该辅助数据影响较大。当辅助数据的值较高时,检测数据极可能偏高;若辅助数据的值较低时,检测数据含量极可能偏低。若某一强相关性的辅助数据值较高,则其对该地块的重金属含量影响也较大,该重金属含量极可能偏高。
本研究将各重金属含量既作为检测指标,又作为其他重金属含量的辅助指标进行分析。選择具有强相关性的一组检测指标和辅助指标,如果检测指标数据的异常值检测结果与辅助指标数据的异常值检测结果相同,即均表现为高低型或者低高型,则表明该异常点位疑似真实异常类型;如果检测指标数据的异常值检测结果与辅助指标数据的异常值检测结果不同,即检测指标存在异常而辅助指标不存在异常,或者两者都存在异常但是异常点位或类型不一致,则说明该异常点位疑似数据错误异常。
2 结果与分析
2.1 数据特征分析
对各重金属指标之间进行初步的相关性分析,提取相关性较强的一组重金属指标来展开后续的异常识别和识别效果分析。如表1所示,铅(Pb)含量和铜(Cu)含量的相关性最强,因此本研究以Pb含量和Cu含量为例展开相关研究。
如表2所示,Pb含量与Cu含量的变异系数均为25%~75%,属于中等强度变异;且Pb和Cu含量经过对数转换后符合正态分布。
2.2 异常识别结果分析
2.2.1 最佳邻域确定
本研究基于上述“K临近距离”的空间领域确定方法,计算和统计重金属Pb和Cu含量在不同K值时的高低(HL)和低高(LH)异常值对应的数量。根据图2-a可知,Pb含量在K值为2~5邻域范围内能识别出稳定的1个异常值,因此确定Pb含量的最佳邻域K值范围为2~5。根据2-b图可知,Cu含量在K值为2~8邻域范围内能比较稳定地识别出2个异常值,其中在2~6范围内能基本涵盖6~8区间识别出的异常点,因此确定Pb含量的最佳邻域K值范围为2~6。
2.2.2 异常值检测结果
基于上述确定的最佳邻域范围分别对Pb和Cu含量指标进行异常值检测。如表3所示,Pb含量检测到1个高低异常点,其位于顺义区杨镇汉石桥的6号点位,说明在6号点位Pb含量相较于周围的点位偏高。Cu含量检测到2个高低异常点,分别为顺义区杨镇汉石桥的6号点位和怀柔区雁栖镇下庄村的39号点位,说明Cu含量在6号与39号点位相较于周围的点位而言偏高。具体的异常点位的空间分布图如图3所示。
2.2.3 异常类型识别结果
基于土壤重金属异常类型识别方法,对上述检测出的Pb和Cu含量的异常值进行进一步的类型识别。如表4所示,在6号点位Pb与Cu含量的异常值类型均为HL类型,说明6号点位重金属指标极有可能比周围点位高,从而判别该点位异常类型疑似真实异常。39号点位Cu含量为HL类型异常,但Pb含量不存在异常情况,2种相关性强的重金属含量异常情况不一致,表明该点位中Pb或者Cu含量可能存在疑似数据错误的情况,从而判别该点位异常类型疑似数据错误。具体的点位异常类型分布图如图4所示。
2.3 异常识别方法效果分析
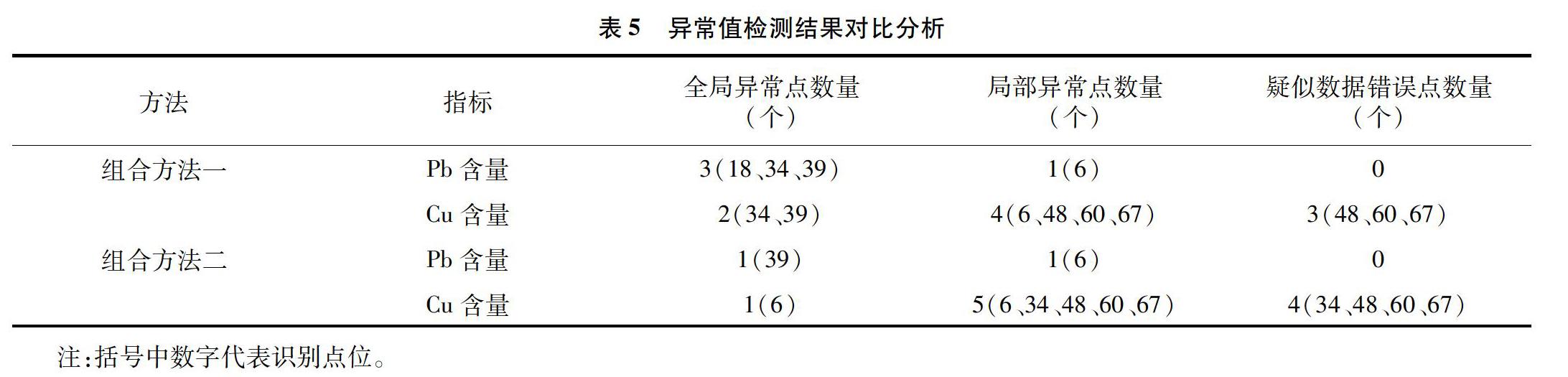
为了验证本研究提出的土壤重金属异常识别方法的有效性,引入格拉布斯准则(Grubbs)及四分法与本研究方法进行对比分析。其中,Grubbs和四分法检测全局异常值,在去除全局异常的基础上,通过本研究方法来检测局部异常值,最后针对原始样点、去除全局异常、去除局部异常点和去除识别为疑似数据错误的异常点位,这4种情况下的土壤重金属含量的变异特征和插值预测精度进行对比分析。
其中组合方法一为四分法与本研究方法结合,组合方法二为Grubbbs法与本研究方法结合。由表5可知,四分法识别出的全局异常值比Grubbs法多,组合方法一在去除了全局异常点的基础上利用本研究方法检测到Pb含量在6号点位存在局部异常,没有识别出疑似数据错误的异常点。检测到Cu含量有4个局部异常点,其中3个点位识别为疑似数据错误。组合方法二在去除了全局异常点的基础上利用本研究方法检测到Pb在6号点位存在局部异常,没有识别出疑似数据错误的异常点。检测到Cu含量有4个局部异常点,其中3个点位识别为疑似数据错误。
2.3.1 变异特征分析
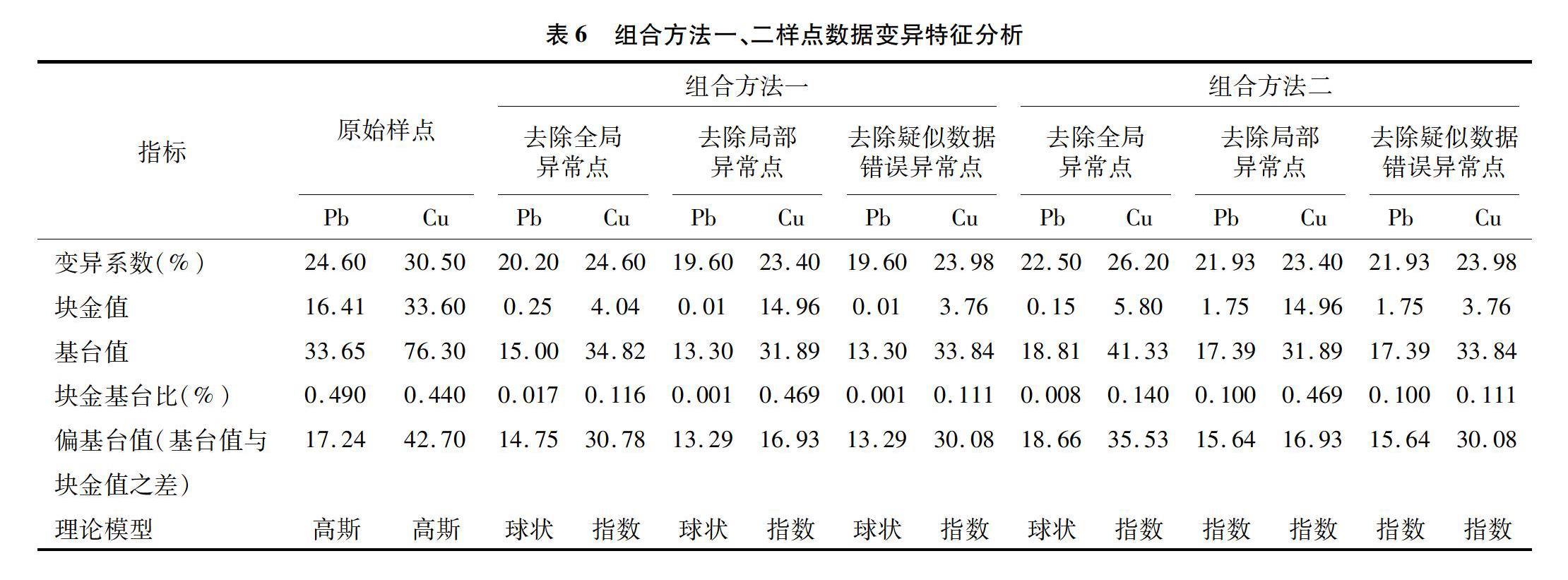
基于上述异常点位识别结果,分别统计组合方法一、二在原始样点、去除全局异常点、去除局部异常点、去除疑似数据错误异常点这4种情况下剩余的土壤重金属样点数据的变异特征信息,统计结果如表6所示。
经过组合方法一、二的系列处理后。与原始样点相比,Pb含量的变异系数有所下降,说明Pb样点数据整体的离散程度有所降低。Pb含量的块金基台比经过土壤重金属去除局部异常后空间自相关性变强。Pb含量的偏基台值经过方法一呈下降趋势,方法二在去除全局异常点后的偏基台值略有上升,但是在去除局部异常点和疑似数据错误异常点后的偏激台值较原始样点呈下降趋势。说明本研究提出的异常识别方法降低了Pb含量的偏激台值,证明区域结构性变异降低。
与原始样点相比,Cu含量的变异系数有所下降,在去除全局、局部异常样点后样本总体的离散程度降低,但在去除疑似数据错误异常样点后,样本总体的离散程度进一步增大,说明疑似数据错误样点识别效率较好,没有引起明显的数据离散程度的变化。Cu含量的块金基台比在去除局部异常点后样本的空间自相关性降低,而去除疑似数据错误异常样点后样本的块金基台比降低,表明样本的空间自相关性增强。说明去除了局部异常点中空间相关性较强的异常点,去除疑似数据错误异常点的同时保留了空间相关性较强的点。与原始样点相比,Cu含量的偏基台值在2种方法下均下降,在去除局部异常点后偏基台值下降,表明区域结构性变异降低,而在去除疑似数据错误样点保留疑似自然异常样点的情况下,区域结构性变异增强,说明了土壤重金属异常识别结果的有效性。
2.3.2 预测精度分析
针对组合方法一、二在原始样点、去除全局样点、去除局部样点、去除疑似数据错误异常点这4种情况下,对剩余的土壤重金属样点数据采用普通克里金插值分析,分别统计对应情况下的平均相对误差(MRE)和均方根误差(RMSE)。
如图5所示,基于Pb含量进行的插值分析中,在分别去除全局样点、局部样点这2种情况后,MRE和RMSE均较原始样点插值误差明显减小,在此基础上去除疑似数据错误,MRE和RMSE差别不大,说明疑似数据错误的插值结果对整体插值精度影响不大。基于Cu含量进行的插值分析中,在分别去除全局异常样点、局部异常样点这2种情况下,MRE和RMSE均较原始样点插值误差明显减小,但是去除疑似数据错误异常点的情况下插值误差较去除局部异常样点情况下插值误差略有增大,但基本保持一致。说明去除疑似错误数据异常点对整体插值精度影响不大,这表明土壤重金属异常识别中对判断为疑似数据错误的样点进行剔除后对整体插值估计影响甚微,一定程度上佐证了土壤重金属异常识别方法的准确性。
3 讨论与结论
本研究所用土壤重金属异常识别方法,基于稳定的K邻域确定稳定的异常检测范围,能够检测到稳定的局部异常点,降低了传统邻域空间范围确定的主观性,提高了土壤重金属异常识别的有效性。
本研究所用土壤重金属异常识别方法,基于辅助指标与检测指标的相关性程度进行异常类型识别。判别异常点类型是属于疑似数据错误还是属于疑似自然异常,相较于传统的异常点检测模式,该方法能进一步对异常点类型进行识别,根据异常类型识别结果能够有效指导后续土壤重金属数据处理,辅助提高数据评价分析精度。
基于2006年北京市農田区土壤重金属数据,分别将本研究方法与四分法和Grubbs法结合,对原始
样点,去除全局、局部及疑似错误数据异常点这4方面的变异特征和预测精度进行分析。通过以上3个方面对原始样点的处理,样本总体的离散程度降低,样本空间自相关性程度变化及区域结构性变异趋势增强,数据空间插值的预测精度提高,验证了本研究提出的土壤重金属异常识别方法的有效性和准确性。
参考文献:
[1]陈秀端. 西安市表层土壤重金属污染的环境地球化学研究[D]. 西安:陕西师范大学,2013:1-14.
[2]Zhang C S,Selinus O.Statistics and GIS in environmental geochemistry-some problems and solutions[J]. Journal of Geochemical Exploration,1998,64(1/2/3):339-354.
[3]王景云,杨 军,杨俊兴,等. 基于空间自相关和概率论的土壤重金属异常值的识别方法[J]. 地球信息科学学报,2017,19(5):605-612.
[4]贺 玲,吴玲达,蔡益朝. 数据挖掘中的聚类算法综述[J]. 计算机应用研究,2007(1):10-13.
[5]Yin C Y,Zhang S. Parallel implementing improved k-means applied for image retrieval and anomaly detection[J]. Multimedia Tools and Applications,2017,76:16911-16927.
[6]張 颖,黄俊宇. 金融创新、新型城镇化与区域经济增长——基于空间杜宾模型的实证分析[J]. 工业技术经济,2019,38(12):93-101.
[7]杨 岩,姚长青,张均胜,等. 长江中游城市群科研人才空间集聚分析[J]. 地理空间信息,2018,16(9):5-10.
[8]刘彦文,刘成武,何宗宜,等. 基于像元尺度耕地质量局部空间自相关的基本农田划定[J]. 农业机械学报,2019,50(5):260-268,319.
[9]黄熠锋,张梦迪,倪佳峰,等. 基于空间自相关分析的温瑞塘河底泥Ni、Zn空间聚类和异常值分析[J]. 浙江农业科学,2019,60(12):2286-2290.
[10]Yang J,Wang J Y,Zheng Y M,et al. Method for identifying outliers of soil heavy metal data[J]. Environmental Science and Pollution Research,2018,25(13):12868-12875.
[11]Meklit T,van Meirvenne M,Verstraete S,et al. Combining marginal and spatial outliers identification to optimize the mapping of the regional geochemical baseline concentration of soil heavy metals[J]. Geoderma,2009,148(3/4):413-420.
[12]杨 冕,王 银. 长江经济带PM2.5时空特征及影响因素研究[J]. 中国人口·资源与环境,2017,27(1):91-100.
[13]邓 敏,刘启亮,李光强. 采用聚类技术探测空间异常[J]. 遥感学报,2010,14(5):944-958.
[14]李晓岚,高秉博,周艳兵,等. 基于时空不确定性分析的北京市农田土壤重金属镉含量等级划分[J]. 农业环境科学学报,2019,38(2):307-316.
[15]曼弗雷德·M·费希尔,王劲峰.空间数据分析 模型方法与技术[M]. 张 璐,肖光恩,吕博才,译. 北京:中国人民大学出版社,2018:20-28.
[16]Anselin L.Local indicators of spatial association-LISA[J].Geogr
Anal 1995,27(2):93-115.
[17]Zhou J,Ma D S,Pan J Y,et al.Application of multivariate statistical approach to identify heavy metal sources in sediment and waters:a case study in Yangzhong,China[J]. Environmental Geology,2008,54:373-380.
[18]刘 英,李旭东,郑 超,等. 玉溪市农田土壤3种重金属监测结果分析[J]. 环境卫生学杂志,2018,8(4):299-301.
[19]潘瑜春,刘巧芹,陆 洲,等. 离群样点对土壤养分空间变异分析的影响研究[J]. 土壤学报,2010,47(4):767-771.
[20]Fu W J,Zhao K L,Zhang C S, et al. Outlier identification of soil phosphorus and its implication for spatial structure modeling[J]. Precision Agriculture,2016,17:121-135.
[21]王加恩,康占军,许新苗,等. 矿区土壤中重金属元素含量异常的调查[J]. 环境污染与防治,2009,31(7):105-108.
[22]刘 伟,郜允兵,潘瑜春. 农田土壤重金属空间变异多尺度研究[J]. 江苏农业科学,2018,46(23):357-361.
[23]Gao Y F,Liu H L,Liu G X. The spatial distribution and accumulation characteristics of heavy metals in steppe soils around three mining areas in Xilinhot in Inner Mongolia,China[J]. Environmental Science and Pollution Research,2017,24(32):25416-25430.
[24]Hu B F,Wang J Y,Jin B,et al. Assessment of the potential health risks of heavy metals in soils in a coastal industrial region of the Yangtze River Delta[J]. Environmental Science and Pollution Research,2017,24:19816-19826.
[25]Gao Y F,Liu H L,Liu G X. The spatial distribution and accumulation characteristics of heavy metals in steppe soils around three mining areas in Xilinhot in Inner Mongolia,China[J]. Environmental Science and Pollution Research,2017,24(32):25416-25430.
