神经网络模型中灾难性遗忘研究的综述
2021-05-26韩纪东李玉鑑
韩纪东, 李玉鑑,2
(1.北京工业大学信息学部, 北京 100124; 2.桂林电子科技大学人工智能学院, 广西 桂林 541004)
近年来,神经网络模型在很多方面已经远远超过人类大脑,如在围棋领域AlphaGo战胜人类顶尖高手[1-2],在大规模视觉比赛ImageNet中表现出更强的图像识别能力[3-4],在电子游戏中战胜专业顶级游戏玩家[5-6]. 注意,本文中的神经网络泛指所有的神经网络. 这不仅使得神经网络模型受到广泛的关注,还极大地促进了神经网络模型的进一步发展,使得神经网络模型在更多领域取得了更加不凡的成就,如图像分割[7-10]、目标检测[11-13]、自然语言处理[14-17]、姿态估计[18-21]等. 神经网络模型的快速发展,并没有使其克服所有缺陷. 神经网络模型依然有很多不足,如灾难性遗忘、广受争议的黑箱子操作等,但是瑕不掩瑜,神经网络在很多方面的惊艳表现使它依然备受学者们的青睐.
一个显而易见的事实是,人类在学习新知识后不会对旧知识发生灾难性遗忘,而这既是神经网络模型的一个重大缺陷,也是它的一个遗憾. 该问题在很久之前就已经引起了学者们的注意. 20世纪八九十年代,连接网络时期,Carpenter等[22]已经提到了神经网络模型中的灾难性遗忘问题,并且用了一个形象的比喻来说明,一个出生在波士顿的人搬到洛杉矶,他再回到波士顿时,仍然不会忘记他在波士顿的一切;也即他在洛杉矶学会新知识后,仍然会记得之前在波士顿的旧知识,而不会发生灾难性遗忘;McCloskey等[23]描述了神经网络在序列学习中遇到的灾难性遗忘问题,在文中称该问题为灾难性干扰(catastrophic interference). 注意:当时,神经网络常被称为连接网络. 当时,有很多学者提出了相关的方案试图解决该问题,如有学者认为灾难性遗忘是由于存储在神经网络内部表征重叠造成的,因此使用稀疏向量、输入正交编码等方法来避免神经网络模型中的灾难性遗忘[24-25];有学者使用双网络来解决神经网络模型中的灾难性遗忘[26-27];也有学者使用伪训练数据预演的方法来减少神经网络模型中的灾难性遗忘[28].
现在,神经网络模型的参数量已经达到十几亿[16]、几百亿[29],甚至一千多亿[17,30];但是神经网络模型中的灾难性遗忘问题依然广泛存在,如卷积神经网络(convolutional neural networks, CNN)[31-32]、长短期记忆网络(long short-term memory,LSTM)[33]、生成对抗网络(generative adversarial network,GAN)[34-35]等. 这是由于同20世纪相比,神经网络模型的思想变化并不大,变化最大的是训练神经网络模型所使用的硬件设备及所使用的数据量. 目前,神经网络模型依然使用反向传播算法进行反复迭代优化,直到损失函数的值收敛,具体的优化策略可能更丰富了,如自适应梯度法(adaptive gradient,AdaGrad)[36]、AdaDelta[37]、 RMSprop[38]、自适应矩估计(adaptive moment estimation,Adam)[39]等. 为了克服神经网络模型中的灾难性遗忘问题,最近,很多学者提出了他们的解决方案. 如Rebuffi等[40]提出iCaRL方法,该方法选择性地存储之前任务的样本;Sarwar等[41]提出基于部分网络共享的方法,该方法使用“克隆- 分支”技术;Li等[42]提出LwF方法,该方法主要以知识蒸馏的方式保留之前任务的知识;Zeng等[43]提出使用正交权重修改结合情景模块依赖的方法;von Oswald等[44]提出任务条件超网络,该网络表现出了保留之前任务记忆的能力;Li等[45]结合神经结构优化和参数微调提出一种高效简单的架构. 也有学者研究了神经网络中的训练方法、激活函数及序列学习任务之间的关系怎样影响神经网络中的灾难性遗忘的问题,如Goodfellow等[46]就发现dropout方法在适应新任务和记住旧任务中表现最好,激活函数的选择受两任务之间关系的影响比较大.
目前对神经网络模型中灾难性遗忘的研究主要是增量学习(incremental learning),在很多情况下,也被称为持续学习(continous learning)或终身学习(lifelong learning)等. 这里如没有特别说明统一称为增量学习,但是有时为与原论文保持一致也可能使用持续学习或终身学习. 还有一些其他神经网络模型方法对灾难性遗忘问题的研究非常有意义且与增量学习有一定的交叉,如多任务学习(multi-task learning)、迁移学习(transfer learning). 多任务学习是同时学习多个任务,利用不同任务的互补,相互促进对方的学习[47];迁移学习主要是将之前学习的知识迁移到新任务上[48],但是这种学习方式不关心学习到新知识后是否发生灾难性遗忘,也即该方法主要的关注点是怎样将之前任务上的知识迁移到新任务上. 多任务学习、迁移学习和增量学习如图1所示. 图1(a)表示多任务学习的一个实例, modela和modelb分别针对taskA、taskB,涵盖2个模型的蓝色背景代表modela和modelb在同时训练2个任务时的某种联系,如共享神经网络的前几层等;图1(b)表示迁移学习,model1表示已经使用任务taskA的数据训练好的模型,model2表示针对任务taskB的模型且尚未被训练,迁移学习就是将model1的知识迁移到model2;图1(c)表示增量学习,在t时刻,modelI学习任务taskA,在t+1时刻modelI学习任务taskB,增量学习要求modelI在学习过taskB后不能忘记taskA.

图1 多任务学习、迁移学习和增量学习Fig.1 Multi-task learning, transfer learning and incremental learning
显然,神经网络模型中的灾难性遗忘问题已经成为阻碍人工智能发展的绊脚石,该问题的解决无疑将是人工智能发展史上的一个重要里程碑. 为促进该问题的早日解决,本文对神经网络模型中灾难性遗忘问题的相关研究做了一个综述. 该综述的主要目的是为了总结之前在这方面的研究和对该问题提出一些研究建议.
1 相关工作
之前的连接网络模型中,French[49]对连接网络的灾难性遗忘的问题做了一个综述. 该文献不仅详细地分析了造成连接神经网络灾难性遗忘的原因,而且介绍了多种解决连接神经网络灾难性遗忘问题的方案. 该作者最后指出解决神经网络的灾难性遗忘问题需要2个单独的相互作用的单元,一个用于处理新信息,另一个用于存储先前学习的信息. 但是该文献作者分析的是早期的神经网络模型,随着神经网络技术的快速发展,现在的神经网络模型与连接神经网络模型在神经网络的结构、深度以及优化策略,甚至是训练神经网络模型的数据量等方面都有很大不同.
最近,为了总结对神经网络模型中灾难性遗忘的研究,也有部分学者做了一些综述性研究. de Lange等[50]对持续学习中的图像分类任务做了一个对比性研究,首先对持续学习的方法进行了综合的介绍,如介绍很多持续学习的方法,将各种持续学习的方法进行了总结并归为基于回放的方法、基于正则化的方法和基于参数隔离的方法;其次,为了公正地对比不同持续学习方法的效果,还提出了一种对比性研究持续学习性能的框架. Lesort等[51]综合性地研究了机器人中的增量学习. Parisi等[52]对基于神经网络的持续性终身学习做了一个综述,首先对生物的终身学习做了详细的介绍,如人类怎样解决弹性- 稳定性困境、赫布弹性稳定性、大脑互补的学习系统,这是该综述与其他类似综述最大的不同;然后,分析了神经网络模型中的终身学习方法,并将其分为:正则化方法、动态架构方法和互补学习系统及记忆回放. Belouadah等[53]对视觉任务的类增量学习做了一个综合性研究,提出了增量学习的6个通用属性,即复杂度、内存、准确率、及时性、弹性和伸缩性,并将增量学习的方法分为基于微调的方法和基于固定表征的增量学习方法. Masana等[54]提出了类增量学习所面临的挑战,即权重偏移、激活值偏移、任务间混淆和新旧任务失衡,并将类增量学习分为3类,基于正则化的方法、基于预演的方法和基于偏置- 校正的方法. 文献[50-54]虽然都对神经网络中的克服灾难性遗忘的方法做了综述性研究,但是它们均有一定的局限性,如文献[50]仅介绍了持续学习中关于图像分类的方法,且用来对比不同持续学习方法性能的框架也是针对图像分类任务的,文献[51]仅研究了针对机器人的增量学习. 另外,文献[50-54]都没有涉及生成对抗模型或强化学习克服灾难性遗忘方法的介绍.
2 减缓灾难性遗忘问题的方法
针对神经网络模型中的灾难性遗忘问题,相关学者提出了很多解决方法. 尽管相关文献大都声称提出的方法可以克服灾难性遗忘的问题,但实际上仅是不同程度地减缓神经网络模型中的灾难性遗忘问题,为了表述的严谨,本章的标题为减缓灾难性遗忘问题的方法. 由第1节的内容可以看出,不同的综述文献依据不同的规则,对减缓灾难性遗忘问题方法的分类并不相同,本节将减缓灾难性遗忘问题的方法分为4类,即基于样本的方法、基于模型参数的方法、基于知识蒸馏的方法和其他方法.
为方便下文的叙述,这里对下文中的符号进行统一,符号及其含义具体如表1所示.

表1 符号及其含义

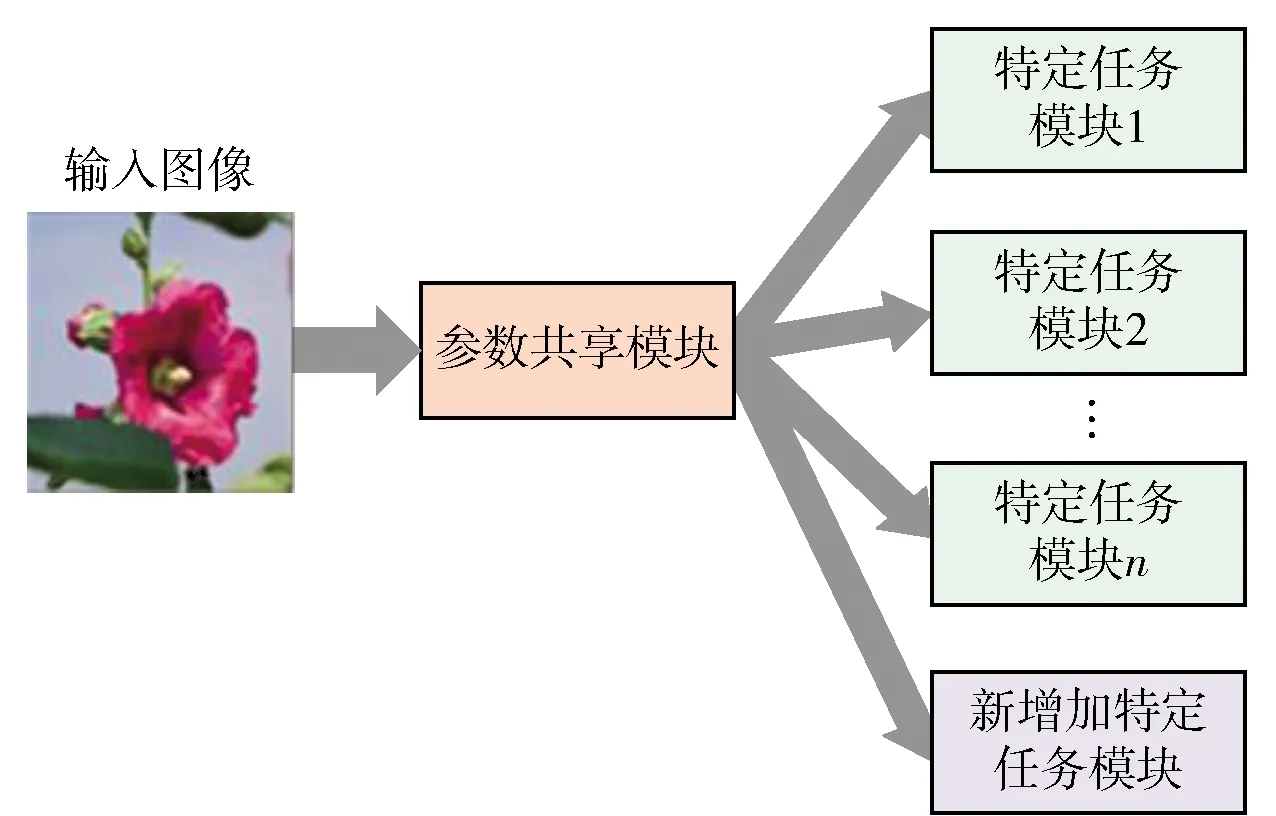
图2 参数共享模块和特定任务模块Fig.2 Parameter sharing module and task-specific module
注意,由于增加新任务与增加新类非常相似,在下文中不做特别区分,均使用增加新任务表示;有些时候为与原论文表述一致,也会使用增加新类表示.
2.1 基于样本的方法
本文将直接或间接地用到Tdatapre样本集中数据的方法称为基于样本的方法. 直接使用即为使用额外的内存存储Tdatapre样本集中的部分数据Tdataselect,在学习新任务时,将Tdataselect与Tdatanew混合,最后使用混合后的数据训练Modeltarget. 间接使用主要指生成伪数据或保存Tdatapre的特征,然后使用它们与Tdatanew或Tdatanew的特征混合训练Modeltarget. 在文献[50,52]中也将该方法称为回放. 注意:有些方法中虽然用到了Tdatapre中的部分样本数据,考虑到论文作者在克服灾难性遗忘中的主要思想是使用其他方法,因此这部分方法并没有被认为是基于样本的方法.
2.1.1 直接使用样本的方法
Guo等[56]为解决增量学习中的灾难性遗忘问题,提出了支持样本表征的增量学习(exemplar-supported representation for incremental learning,ESRIL)方法. ESRIL包括3个部分:1) 记忆感知突触(memory aware synapses,MAS)模块,该模块使用ImageNet数据集预训练的深度卷积神经网络(deep convolutional neural network,DCNN),是为了维持用之前任务Taskpre数据集训练的特征;2) 基于样例的字空间聚类(exemplar-based subspace clustering,ESC)模块,该模块是为了提取每个任务中的样本;3) 多质心最近类(the nearest class multiple centroids,NCMC)模块,该模块作为一个辅助分类器,当增加的新类数据与ImageNet数据很相似时,使用该分类器替代MAS中全连接层,减少训练时间. ESRIL的关键是每类数据中代表样本的选择,Guo等采用文献[57]中的方法进行样本的选择,通过迭代的方式不断优化
(1)

Belouadah等[58]提出了一种基于双内存的增量学习方法,称为IL2M. 与普通基于样本的方法不同,该方法使用2个记忆模块:1) 第1个记忆模块存储之前任务Taskpre的部分样本Tdataselect; 2) 记忆模块存储之前任务Taskpre每类样本初次学习时的统计量. 存储之前任务Taskpre部分样本Tdataselect的目的非常简单,是为了与新任务Tasknew的数据混合,然后作为更新网络的训练数据;存储每类样本初次学习时的统计量,是由于初次训练时,该类样本的数据最全,相应地统计量也最准确;该统计量的作用是为了矫正更新网络时由于数据失衡(新任务Tasknew的数据多,而之前任务Taskpre的数据少)所造成的偏差.
Isele等[59]提出了一种选择性存储所有任务样本的方法,避免强化学习的灾难性遗忘. 该方法包括长时存储模块和短时存储模块. 长时存储模块称为情景记忆,存储的样本基于样本的等级(使用排序函数对样本排序). 短时记忆模块是一个先进先出(first-in-first-out,FIFO)区,该部分不断刷新,以确保网络能接触到所有的输入数据.
2.1.2 间接使用样本的方法
Hayes等[60]提出了一种别样的基于样本的模型,该模型称为使用记忆索引的回放(replay using memory indexing,REMIND). REMIND模型并不存储之前任务Taskpre的原始样本,而是存储样本的特征. REMIND模型将样本的特征经过量化后给予索引号并存储,增加新任务Tasknew时,将随机抽取r个存储的特征进行回放.
Atkinson等[61]提出了RePR(reinforcement-Pseudo-Rehearsal)模型. RePR模型使用伪数据- 预演的方式避免神经网络中的灾难性遗忘. RePR包括短时记忆(short-term memory,STM)和长时记忆模块(long-term memory,LTM). STM模块使用当前任务Tasknew的数据Tdatanew训练针对当前任务的深度强化网络(deep Q-networks,DQNs);LTM模块包括拥有之前所有任务Taskpre的知识和能生成之前所有任务伪数据的GAN. 结合迁移学习,将DQNs的知识迁移到Modelpre中;在知识迁移的过程中,真实的数据使得Modeltarget学习到新知识,GAN生成的伪数据维持Modelpre中之前任务的知识.
Atkinson等[62]和Shin等[63]均使用中GAN生成相应的伪数据. Atkinson等[62]使用GAN生成伪图像代替随机生成的伪图像,因为随机生成的伪图像明显不同于自然的图像,这将导致网络能学习到很少的之前任务的知识. 当训练第T1任务时,GAN被训练T1的数据集DT1,增加了T2任务后,GAN被训练使用T2的数据集DT2;增加了T3任务后,该方法显然就出现了问题,前一步中,GAN仅使用数据集DT2,意味着GAN生成的伪数据也是T2的伪数据. 为了不增加内存的消耗,作者将GAN也使用伪标签进行训练,这样GAN生成的数据就代表之前所有任务的数据. Shin等[63]提出的模型具有双架构〈G,S〉,G是深度生成器模型用来生成伪样本,S是解算器用来处理每个任务.
2.2 基于模型参数的方法
基于模型参数的方法根据是否直接使用模型参数进行分类:1) 选择性参数共享,该方法直接使用模型的参数; 2) 参数正则化,该方法约束模型的重要参数进行小幅度变动,以保证对之前已学习知识的记忆.
2.2.1 选择性共享参数
该方法在预训练神经网络模型Modelpre后,增加新任务Tasknew时选择性地使用神经网络模型的参数. 虽然神经网络模型的参数没有发生改变,由于针对不同任务所选择性激活神经网络中参数的不同,导致不同任务使用的神经网络的模型参数不同,进而使同一个神经网络模型的参数适应不同的任务. 可以看出,这种方式换一个角度解决神经网络中的灾难性遗忘问题. 这种方式的优点:1)不需要使用之前任务Taskpre的数据Tdatapre;2)没有对神经网络模型进行较大的改进. 这种方式也有一个显著的缺点,虽然不需要使用先前任务的数据进行训练,但是需要针对不同任务存储一个激活参数,即使在相关文献中,作者一再强调存储的激活参数很小,但当任务量非常多时,即使逐渐小幅度定量的增加也是非常可怕的.
Mallya等[64]提出了一种共享参数的方法,该方法不改变预训练骨干网络的参数Θ,而仅对每个任务训练掩模m,具体如图3所示. 以第k个任务为例进行说明:首先训练得到掩模mask′k;然后通过将掩模mask′k二值化处理得到二值化掩模maskk,如图3中maskk所示(红色实方框为表示1,深灰色实方框表示0);最后将二值化掩模maskk与预训练骨干网络的参数Θbackbone逐元素运算得到适用于任务k的参数集Θk,如图3中Θbackbone和Θk所示(Θbackbone中绿色实方框表示具体的参数,Θk中绿色实方框表示激活的参数,深灰色实方框表示未被激活的参数).

图3 共享参数的方法[64]Fig.3 Method of sharing parameters[64]

(2)

(3)
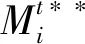
2.2.2 参数正则化
使用该方法时,Modelpre在添加新任务后,需要对神经网络进行重新训练;但是,由于添加了参数正则项,神经网络在训练的过程中会保证对重要参数进行小幅度的改变,以保证对之前任务Taskpre的效果.
Kirkpatrick等[66]参考生物对特定任务的突触巩固原理,提出了类似于该原理的人工智能算法,即可塑权重巩固(elastic weight consolidation,EWC). 小鼠在学习新任务后,一定比例的突触会增强,并且能保持一段时间;相应地,神经网络模型的参数并非全是等价的,有些参数可能是有用的,有些参数可能作用非常低甚至是没有作用. 因此,作者提出缓慢改变神经网络模型中的重要参数,以使得模型不忘记之前学习的知识. EWC使用损失函数来实现该目的,即
(4)

Chang等[35]为了使GAN避免灾难性遗忘,提出了记忆保护生成对抗模型(memory protection GAN,MPGAN) ,并设计了一种参数正则化方法(second derivative preserver,SDP). 考虑到已存在的参数正则化方法使用输出函数的一阶导数不能准确地评估参数的重要性,SDP使用输出函数的二阶导数. 使用F表示输出函数,θ表示模型的参数,则SDP表示为
(5)
由于汉森矩阵计算较为复杂,在实际操作中使用费雪信息E[(∂F/∂θ)2]近似汉森矩阵. SDP使用
(6)
El等[67]借用参数正则化的思想,提出了一种方式约束增加新任务后模型参数的改变. 作者将卷积神经网络的特征提取模块称为编码器,在编码器后由有2个分支网络,一个分支网络为了图像分类,另一个分支网络称为解码器,使用反卷积进行样本的重建. 为了训练该网络,作者在损失函数中添加了一个非监督重建损失,该损失的作用等同于参数正则化. 优化网络中的损失函数
L=Lcls(,y)+λLrec(,x)
(7)
式中:Lcls(,y)是图像分类的交叉熵损失,y为图像的真实标签,网络输出的预测标签;λ是超参数;Lrec(,x)是重建损失,为重建样本,x为样本.Lrec表示为
(8)
式中:N为样本x的数量;i、j、k三个索引分别为样本x的3个维度,D是样本x三个维度数的乘积;xijk为图像在索引(i,j,k)处的灰度值;ijk为重建后图像在索引(i,j,k)处的灰度值.
2.3 基于知识蒸馏的方法
Hinton等[68]于2015年提出了一种模型压缩的方法,即知识蒸馏. 该方法使用软目标辅助硬目标进行训练小模型modelsmall,软目标即将样本xi输入到预训练的大模型modelbig中得到的输出qi,硬目标即为样本的真实标签yi. 之所以这样做,是因为软目标中包含的信息量巨大;而硬目标包含的信息量较低. 如果modelbig中真实类的输出结果远远大于其他类的结果,那就不能很好地使用软目标中的信息了,因此需要平滑softmax的输出结果,即
(9)
式中:zi为softmax前一层(该层的神经元个数已被映射为训练任务的类别数)的输出;T为温度,T越大modelbig输出的结果越软. 知识蒸馏的方法被广泛应用于模型压缩[69-71]、迁移学习[72-74]等领域,也被广泛应用于解决神经网络模型的灾难性遗忘问题中[75-79]. 图4为知识蒸馏的示意图,将训练样本data同时输入到modelbig和modelsmall,通过知识蒸馏的方式将modelbig的知识迁移到modelsmall.

图4 知识蒸馏Fig.4 Knowledge distillation
Li等[42]结合知识蒸馏设计了学而不忘模型(learning without forgetting,LwF),该模型在增加新类Classnew时,仅需要使用新类Classnew的数据训练模型,且能避免对之前学习知识的遗忘. LwF模型使用前几层作为特征提取模块,为所有任务共享;之后几层作为特定任务模块,为不同任务的单独所有. LwF使用的损失函数
L=λ0Lold(Y0,0)+Lnew(Yn,n)+R(s,o,n)
(10)
式中:λ0为一个超参数,值越大,相应地对蒸馏损失的权重就越大;Lold(Y0,0)为软标签的损失,Y0为增加新类Classnew前模型的软标签,0增加新类Classnew后训练过程中模型输出的软标签;Lnew(Yn,n)增加新类别的标准损失,Yn为新类别数据的真实标签,n为训练过程中模型的输出;R(s,o,n)为正则项,s为共享参数,o之前任务的特定任务参数,n为新任务的特定任务参数.
Shmelkov等[75]和Chen等[76]分别提出了新的损失函数,将知识蒸馏的方法用到目标检测的灾难性遗忘中,这里以文献[75]为例进行说明. Shmelkov等[75]提出的损失函数使Fast RCNN网络在增加新的任务时,不用使用之前任务的数据,且表现出对之前任务知识的不遗忘. 将当前的网络称为CA,CA增加新任务后需要增加新的分类分支和使用新任务的数据进行重新训练,此时的网络称为CB. 由于目标检测任务中需要进行分类与回归训练,因此作者结合分类与回归提出蒸馏损失函数

(11)

Hou等[77]结合知识蒸馏与样本回放的方式提出了适应蒸馏的方法,该方法首先针对新任务tnew训练一个模型CNNexpert,然后通过知识蒸馏的方式将新任务的知识迁移到目标模型CNNtarget,与LwF不同的是,该方法在知识蒸馏时用到少量的之前任务的样本.
Castro等[78]使用之前任务的小部分数据和当前任务的数据设计了一个端到端的增量学习模型,由任务共享模块特征提取和特定任务模块组成. 针对该架构,作者提出了交叉- 蒸馏损失公式
(12)
式中:LC(ω)为新旧任务所有数据的交叉熵损失;LDf(ω)表示每个特定任务层的蒸馏损失.LC(ω)和LDf(ω)表示为
(13)
(14)
式中:N和C分别表示样本的数目和样本的类别数;pij表示样本真实标签,qij为模型的输出;pdistij与qdistij类比于pij和qij.

(15)
2.4 其他方法
除了上面所述的3类方法外,一些学者还提出了其他方法为避免神经网络中的灾难性遗忘. Muoz-Martín等[80]将有监督的卷积神经网络与受生物启发的无监督学习相结合,提出一种神经网络概念;不同于参数正则化方法,Titsias等[81]提出一种函数正则化的方法;Cao在将学习系统视为一个纤维丛(表示一种特殊的映射),提出了一个学习模型[82]. 该学习模型的架构如图5所示,该图根据文献[82]所画,与动态地选择模型的参数不同,该模型动态地选择解释器. 图5(a)表示了一个普通的神经网络,即输入x通过神经网络得到输出y;图5(b)表示作者所提出的学习模型的架构,该架构主要有以下几步:1)输入x通过生成器Generator被编码为潜在空间L中的xL,这里相似的样本会得到xL; 2) 基于xL选择神经网络中被激活的神经元,得到解释器Interpretor:fx; 3) 将样本x输入到解释器fx得到输出y. 为了使该学习模型能有对时间的感知,作者又在模型中引入了一个生物钟,
T=Tmin+σ[ψ(x)](Tmax-Tmin)
(16)
Yt=(Asin(2πt/T),Acos(2πt/T))
(17)
式中:x表示输入;Yt表示生物钟的输出;t表示当前时刻;T表示周期;Tmin和Tmax均为超参数,分别表示T的最小值与最大值;σ表示sigmoid函数;ψ表示可训练的神经网络模型. 通过实验作者发现该学习模型不仅具有良好的持续学习能力,而且还具有一定的信息存储能力.

图5 普通神经网络和纤维束学习系统[82]Fig.5 Common neural network and learning system with a fiber bundle[82]
3 减缓灾难性遗忘的评价准则
针对神经网络中的灾难性遗忘问题,大量学者提出了自己的方法,无论是基于样本的方法,或是基于模型参数的方法,又或是基于知识蒸馏的方法等等;总之,解决方案有很多,那么这又产生了一系列问题:如何确定哪种方法最优?如何确定某种解决方案所适应的环境?如何评价不同方法的优劣?
针对如何评价不同方法这个问题,也有一些学者进行了相应的研究. Kemker等[83]提出了衡量灾难性遗忘问题的实验基准和评估指标. 这里只介绍3个评价指标,该评指标主要有3个新的评估参数
(18)
(19)
(20)
式中:T表示任务的数量;αbase,i表示训练第i个任务后,神经网络模型对第1个任务的准确率;αideal表示训练基础数据集(也即第1个任务)后,神经网络模型对基础数据集的准确率;αnew,i表示训练第i个任务后,神经网络模型对该任务的准确率;αall,i表示模型对当前所能得到所有数据的准确率. 这里式(18)中的Ωbase表示神经网络模型在训练T个任务之后,对学习到第1个任务知识的遗忘程度;式(19)中的Ωnew表示神经网络模型在学习到新任务后,对新任务的适应能力;式(20)中的Ωall计算模型保留先前学习的知识和学习到新知识的能力. van de Ven等[84]也指出,虽然有很多针对神经网络中灾难性遗忘问题的解决方案,但是由于没有统一的评价基准,导致直接对比不同解决方案的效果非常困难. 为了能结构化地比较不同的解决方案,van de Ven等提出了3种困难度逐渐加大的连续学习的情景,每个情景包含2种任务协议. 3种任务情景分别为:1)测试时,已知任务ID;2)测试时,任务ID未知,且不需要判断任务ID;3)测试时,任务ID未知,且需要判断出任务ID. 第1种实验情景针对的是任务增量学习(task-IL),即每个任务在输出层都有与之对应的特定的输出单元,而其余网络是共享的;第2种实验情景是针对域增量学习(domain-IL),即任务的结构相同但输入分布却不相同;第3种实验情景针对类增量学习(class-IL),即递增地学习新类. 在文献中,作者将第1种任务协议称为分割MNIST任务协议,该协议将MNIST数据集中分为5个任务,每个任务包含2类;作者将第2种任务协议称为置换MNIST任务协议,该协议包含10个任务,每个任务包含10类,将原始MNIST作为任务1,在MNIST基础上随机生成另外9组数据即任务2~9的数据集. Pfülb等[85]也提出了一个评价深度神经网络(deep neural networks,DNNs)灾难性遗忘问题的范例. 该评价范例主要是针对实际应用层面,主要包括:1)在DNNs上训练序列学习任务(sequential learning tasks,STLs)时,模型应能保证能随时增加新类;2)模型应该对先前学习过的任务表现出一定的记忆力,即使灾难性遗忘不可避免,至少应该缓慢的遗忘之前所学习的知识,而不是立即遗忘;3)DNNs如果应用到嵌入式设备或机器人中,应该满足内存占用低、添加任务时重新训练的时间或内存复杂度不应依赖于子任务的数量等. 除了提出新的评价方法,也有学者提出了用于测试神经网络模型中灾难性遗忘问题性能的新数据集,如Lomonaco等[86]提出了基准数据集CORe50,该数据集用于测试不同持续学习方法对目标检测的效果.
4 讨论
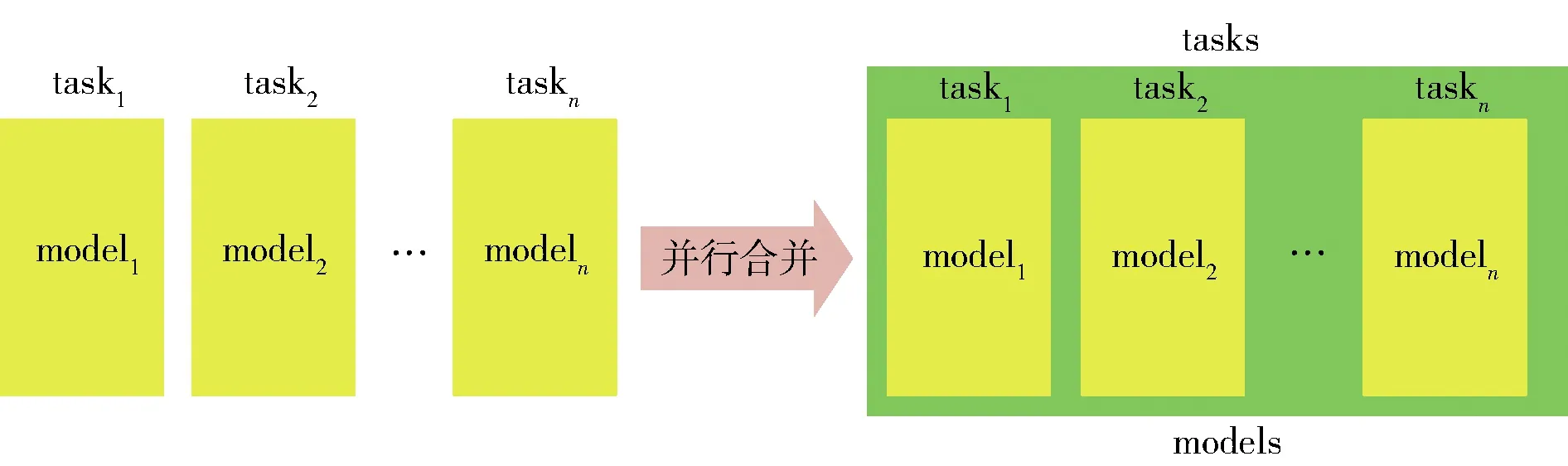
图6 无限扩大的神经网络模型Fig.6 Infinitely expanding neural network model

图7 逐渐增加模型的任务Fig.7 Gradually add tasks to the model
在尽量小地改变神经网络模型自身的情况下允许神经网络模型适应更多的新任务且不发生灾难性遗忘. 如直接使用样本回放的方法,并非简单地将所有任务的样本混合而是想要找到每个任务中具有代表性的样本,并使用不同的方法对样本进行排序,进而选择具有代表性的样本;在使用生成伪数据的方法中,想要生成适量的伪数据而不是无限扩展网络;参数正则化的方法中,想要找到神经网络模型中最重要的参数,并对其进行约束,而不是简单地约束所有参数;在知识蒸馏中,想要将知识由一种网络迁移到另一种网络,而不是简单地将2个网络并联. 另外,第3节中的很多方法依据生物的认知记忆等原理进行改进创新,以期达到克服神经网络模型中灾难性遗忘的目的[66,80,82]. 注意:对减缓灾难性遗忘方法的分类并不是绝对的,如文献[77-78]既用到了知识蒸馏的方法,也用到了样本的方法;这里的分类依据是作者解决神经网络模型中灾难性遗忘问题的主要思想,以文献[78]为例,作者在文中主要的关注点是使用知识蒸馏的方法避免灾难性遗忘,而使用之前任务所组成的小样本集仅是作者使用的一个辅助的方式,因此将该方法归类为知识蒸馏的类中.
5 总结与建议
首先将减缓神经网络模型灾难性遗忘的方法分为四大类,并对不同大类的方法进行了介绍;然后,介绍了几种评价减缓神经网络模型灾难性遗忘性能的方法;接着,对神经网络模型中的灾难性遗忘问题进行了开放性的探讨.
如果将人类的大脑看成一个复杂的神经网络模型,可以观察到人类并没有灾难性遗忘的问题. 这说明现在的神经网络模型与人脑相比仍有非常大的缺陷,仍有非常大的进步空间. 对于怎样解决灾难性遗忘的问题,本文最后提出了几个解决思路:1) 探索生物怎样避免灾难性遗忘的机制,并根据该机制设计相似的神经网络模型. 2) 探索神经网络模型存储信息的新机制,如果神经网络模型在学习新知识后仍能保持对之前学习的知识不遗忘,必然需要存储一些关于之前学习的知识的一些信息,怎样高效地存储和利用这些信息值得研究. 3) 选取具有代表性的样本也是一种方法. 该方法不仅存在于生物的认知中,也广泛存在于社会生活中. 如社会生活中的选举,某一社会团体通常推选出该团体中的某几位成员而不是全体成员代表该社会团体,这也从另一个角度说明,部分样本往往可以近似代表总体样本. 对比到神经网络模型中,选取某一任务中具有代表性的样本,而不是使用所有样本代表该任务;该方法需要确定推选机制,即怎样确定样本集中的某些样本具有代表该样本集的能力. 一个显而易见的事实是,神经网络模型是对生物神经网络的模仿,而现在神经网络模型出现灾难性遗忘的问题,说明对生物的神经网络研究的并不彻底,还有很多盲点. 思路1)进一步研究生物的避免研究灾难性遗忘的机制,应该是研究的重点和趋势.
为彻底解决神经网络模型中的灾难性遗忘问题,需要人工智能等方面学者们的努力,也需要脑科学、心理学等方面学者们的支持.
