基于注意力机制和稠密卷积的视网膜微血管分割算法
2021-05-26王素玉董政伦刘涵宇
王素玉, 董政伦, 刘涵宇
(1.北京市物联网软件与系统工程技术研究中心, 北京 100124;2.北京工业大学信息学部, 北京 100124;3.河北工业大学机械工程学院, 天津 300401)
中国现在已经进入高速发展的时代,中国人民的生活水平越来越高,随着科技的发展,人民生活的节奏也变得越来越快,随之而来的就是各类疾病的发病率也越来越高,尤其是糖尿病、心血管类疾病和眼底疾病. 随着病人的增多和病情的多样化,人民需要更高的医疗水平,如果仅仅依靠医生来诊断疾病已经不现实了,需要依据科技进行精准而高效率的诊断,而想要实现精准、高效的诊断就必须有准确的病情数据. 因此,医疗领域迫切需要能辅助诊断的医疗图像分割算法.
在医疗图像分割中,新的卷积神经网络(convolutional neural networks, CNN)[1]框架中最著名的是Ronneberger等[2]发布的U- NET. U- NET中2个主要的体系结构创新是相同数量的上采样和下采样层的组合,使用跳跃连接将相对应的卷积和反卷积相结合,这样就可以把收缩和扩展路径的特征连接起来. 从训练的角度来看,这意味着整个图像可以由U- NET在一次正向传递中进行处理,从而直接生成分割图. 这使得U- NET能够考虑到视网膜图像的完整上下文,对于基于补丁的CNN来说是一个优势. U- NET网络还有一个巨大的优势就是适用于训练一些样本数量比较少的样本,能很好地解决视网膜图像数量少的问题. 另外,梁礼明等[3]还提出了一种融合U- NET和DenseNet的网络,并且取得很大的进步;Drozdzal等[4]除了常规U- NET中的长跳跃连接之外,还研究了使用类似ResNet的短跳过连接.
循环神经网络(recurrent neural network, RNN)[5]在医疗图像分割任务上也有很好的表现. 空间发条循环神经网络[6]对组织病理学图像中的膜周进行分割,该网络考虑了来自当前块的行和列的先前信息. 为了合并来自左/上和右/下相邻的双向信息,RNN在不同方向上应用了4次,将最终结果连接到全连接层,为单个块生成最终输出. Stollenga等[7]首次使用3D和长短期记忆(long short-term memory,LSTM)RNN,在6个方向上具有卷积层. Andermatt等[8]使用一个带有门控复发单位的3D RNN来分割脑磁共振成像(magnetic resonance imaging,MRI)数据集中的灰质和白质. Yang等[9]在各向异性三维电子显微镜图像中,将双向LSTM RNN与2D U- NET类似框架相结合来分割结构. Poudel等[10]使用带有门控复发单元的2D U- NET 框架来进行3D分割.
用于语义分割的全卷积神经网络(fully convolutional networks,FCN)[11]也扩展到了3D,同时应用在多目标方面. Korez等[12]利用3D FCN生成椎体似然图,驱动磁共振图像中椎体分割的变形模型. Zhou等[13]在人体躯干上分割出19个目标. Moeskops等[14]通过训练一个简单的 FCN来分割MRI、胸MRI中的胸肌和心脏电子计算机断层扫描(computed tomography,CT)血管造影术中的冠状动脉.
在过去的几十年里,研究人员提出了大量的视网膜微血管自动分割的方法,通常分为2类:一是传统图像处理方法,包括预处理、分割和后处理这3个步骤,如 Bankhead等[15]提出了利用小波变换方法增强对船舶前景和背景的检测. 另一种是基于机器学习的方法,主要利用提取的矢量特征训练分类器对视网膜中的像素进行分类. 例如:Lupascu等[16]为每个像素设计了41- D特征向量,训练AdaBoost分类器对视网膜图像中的每个像素进行分类.
近年来,基于深度学习的方法被用于视网膜微血管的分割,并取得了良好的效果. Fu等[17]通过使用带有条件随机场层和侧输出层的CNN提高了对微血管的分割能力. Zhang等[18]在U- NET中引入了一种基于边缘的机制来提高性能. Wu等[19]引入了多尺度网络用于视网膜微血管分割. Guo等[20]在扫描激光眼底镜视网膜图像中,提出了密集残差网络DRNet来分割微血管. 在DRNet中,采用一种名为双残差块(double residual block,DRB)的残差结构来深化网络,获得更复杂的语义信息,取得了显著的改进.
1 提出算法
1.1 相关工作
视网膜微血管分割的目的是为了提取微血管信息,把微血管的真实情况客观地呈现出来,实现对糖尿病性视网膜病变智能辅助筛查和诊断,从而减轻医生工作量,提高工作效率和诊断准确度.
当前视网膜微血管分割算法主要基于U- NET架构,它采用编码器- 解码器结构,在编解码器之间通过一系列的密集跳跃连接进行信息的传递. 虽然U- NET已经在许多医疗图像分割问题上取得了较好的性能,也相继提出了许多改进方案,如循环剩余卷积、带有剩余块或连接密集块的U- NET等,但是这些网络通常只含有一对具有跳跃连接的编码器和解码器结构,信息流的路径数量是有限的. 在视网膜微血管分割中,随着网络深度的加深,会丢失部分微血管信息,这会极大影响医生的诊断.
为此本文以LadderNet为基础提出一种基于注意力机制和稠密卷积的视网膜微血管分割算法,从多个角度对网络结构进行了优化设计. LadderNet采用具有一系列U- NET,拥有多个编码和解码路径的架构,可以看成是由多个U网组成的,不像U- NET中只有一对编码器支路和解码器支路,而是有多对编码器- 解码器支路,每一层的每一对相邻的解码器和解码器支路之间都有跳跃连接,极大地促进信息传递,受 ResNet[21]和基于U- NET的递归残差卷积神经网络R2U- NET[22]的启发,本文使用了修改后的残差块,其中一个块中的2个卷积层共享相同的权重. 由于跳跃连接和剩余块的存在,有更多的信息流路径可以看作是全卷积网络的集合. 不仅提高了分割精度,而且减少了每个残差块内的共享权值参数.
本文加入注意力机制[23],是为了提高视网膜图像分割准确度. 在视网膜图像中,注意力机制可以把注意力集中到对特定任务有用的显著特征,抑制输入图像中的不相关区域. 在级联神经网络中[24],需要明确的外部组织或器官定位模块,而使用注意力机制就不需要了.
受稠密网络DenseNet[25]启发,本文融入稠密卷积,保障卷积过程中有用信息的传递,同时减少卷积过程中的冗余特征. 为了确保网络中各层之间的信息流最大化,将所有层直接相互连接. 为了保持前馈特性,每一层从前面的所有层来获得额外的输入,并将自己的特征图传递给后面的所有层. 至关重要的是,并不是在它们进入一个层之前,通过求和将它们组合起来,而是通过连接特性来组合它们. 因此,包括所有前面卷积块的特征图和其本身的特征图都被传递到后面的所有层,减缓了梯度消失,增强了特征传播,促进了特征重用,降低了网络参数,减少了冗余特征.
1.2 网络结构
视网膜图像的语义较为简单,结构较为固定,都是眼睛视网膜的成像,而不是全身的,由于器官本身结构固定和语义信息没有特别丰富,所以高级语义信息和低级特征都显得很重要,这样U- NET的跳连接和U型结构就很适合视网膜微血管分割. U- NET的下采样过程,是从高分辨率(浅层特征)到低分辨率(深层特征)的过程. U- NET的特点就是通过上采样过程中的级联,使得浅层特征和深层特征结合起来. 对于视网膜图像来说,U- NET能将深层特征用于定位,浅层特征用于精确分割.
视网膜图像数据量相比较少,视网膜图像的数据获取难度较大,因此,选择的模型不宜过大,参数过多,很容易导致过拟合. 本文也是选择以U- NET为基础,并在此基础上进行改进的LadderNet. 针对U- NET中信息流的路径数量有限的问题,本文让多组U- NET并联,这样就会有多对编码器- 解码器支路,从而产生多个信息流路径,更有利于信息流动. 由于跳跃连接和残差块的存在,有更多的信息流路径可以看作是FCN的集合. FCN集合的等价性提高了分割精度,而每个残差块中的共享权值减少了参数数量,也避免了过拟合. 本文以LadderNet作为基础网络的同时,通过引入注意力机制和稠密卷积,从多个角度提高网络性能,其具体结构如图1所示.
首先,通过LadderNet架构将多组U- NET并联,形成多对编码器- 解码器支路,并在各层的每对相邻解码器分支之间都设置跳跃连接. 然后,进一步针对视网膜微血管分割的特殊性,在上采样的过程中加入注意力机制,以突显微血管信息,增强对微血管信息的关注和特征提取. 同时,对U- NET的底部卷积层进行改进,使用稠密卷积增强卷积过程中特征信息的传递,促进了特征重用,降低了参数数量.
1.3 注意力机制
视网膜微血管分割的结果是辅助医生临床诊断的重要依据,因此,分割结果需要真实地反映视网膜情况. 为了突出显示微血管具体情况,本文引入注意力机制,增强对微血管信息的关注,更多提取和保留微血管特征信息.
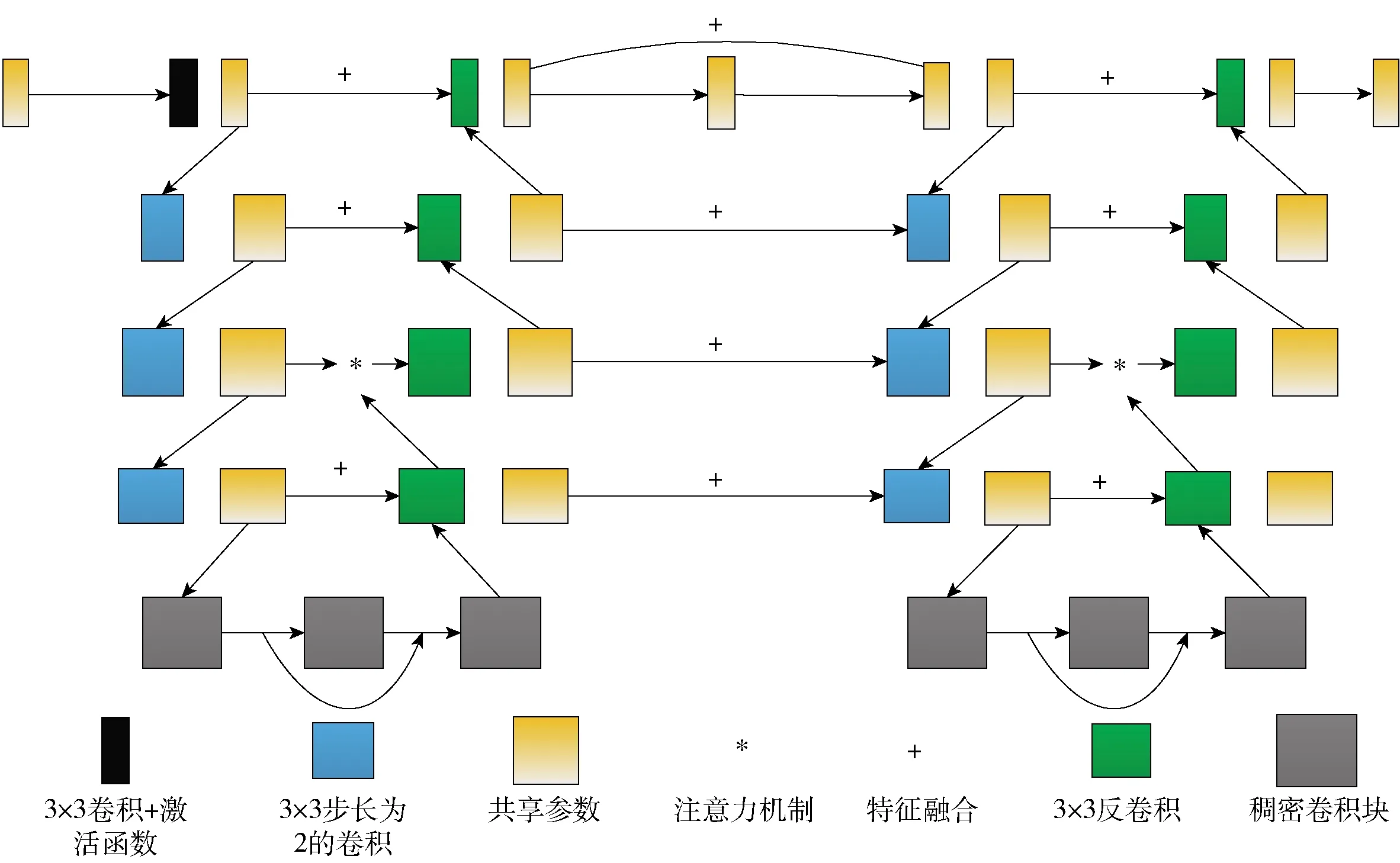
图1 网络结构示意图Fig.1 Schematic diagram of network structure
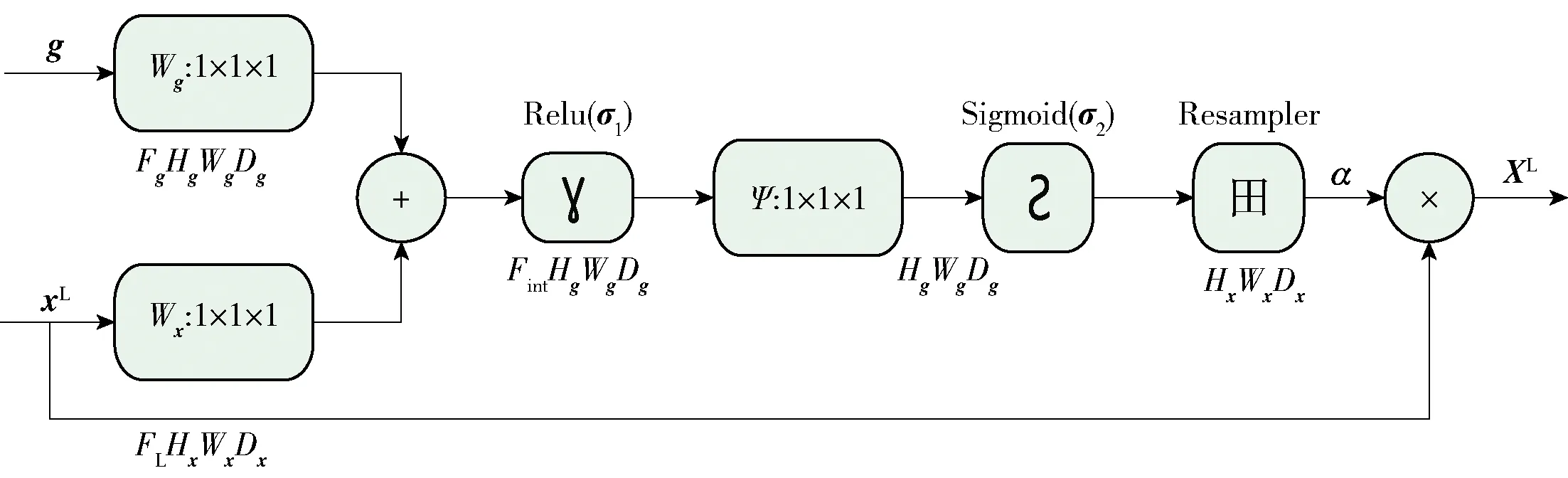
图2 注意力模块Fig.2 Attention block
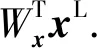
(1)
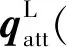
(2)
本文将注意力模块用在了跳跃连接上,对下采样层同层和上采样层上一层的特征图进行处理后再和上采样后的特征图进行融合. 注意力机制可以选择聚焦位置,产生更具分辨性的特征表示,通过加入注意力模块能够产生注意力感知(attention-aware)的特征,并且不同模块的特征随着网络的加深会产生适应性改变,渐增的注意力模块将带来持续的性能提升,不同类型的注意力信息将被大量捕捉到.
1.4 稠密卷积
为了确保网络中各层之间的信息流最大化,将所有层直接相互连接,进一步提升分割性能,本文加入了稠密卷积. 同时为了保持前馈特性,每一层从前面的所有层来获得额外的输入,并将自己的特征图传递给后面的所有层,增强了特征传播,促进了特征重用,降低了参数数量.
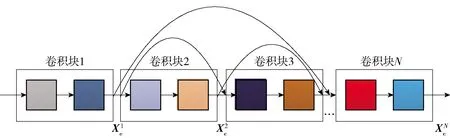
图3 稠密卷积Fig.3 Dense convolution
在稠密卷积中由于每一层都包含之前所有层的输出信息,因此,其只需要很少的特征图就够了,这也是使用稠密卷积可以大大减少参数量,但是与此同时会带来较大内存消耗的原因.
2 实验测试与分析
2.1 数据集介绍
本文采用DRIVE数据集对所提出算法的性能进行了测试分析. DRIVE数据集的照片来自荷兰的糖尿病性视网膜病变筛查计划. 筛查人群由年龄在25~90岁的400位糖尿病患者组成. 随机选择了40张照片,其中33张未显示任何糖尿病性视网膜病变的征兆,而7张显示了轻度早期糖尿病性视网膜病变的征兆. 这7种情况下的异常的简要说明如下.
25_train:色素上皮改变,可能是蝶形黄斑病并且眼球中央凹陷处有色素疤痕,或者是脉络膜病变,无糖尿病性视网膜病变或其他血管异常.
26_train:糖尿病性视网膜病变,色素上皮萎缩,视盘周围萎缩.
32_train:糖尿病性视网膜病变.
03_test: 糖尿病性视网膜病变.
08_test: 色素上皮改变,眼球中央凹陷处有色素性疤痕,或者是脉络膜病变,无糖尿病性视网膜病变或其他血管异常.
14_test:糖尿病性视网膜病变.
17_test:糖尿病性视网膜病变.
使用具有45°视场(field of view,FOV)的佳能CR5非散光且具有3片电荷耦合器件(charge couple device,CCD)相机获取图像. 使用每个色彩平面的8位以768×584像素捕获每个图像. 每个图像的FOV为圆形,直径约为540像素. 对于此数据库,图像已在FOV周围裁剪. 对于每个图像,提供了一个遮罩图像,用于描绘FOV. 这组40张图像已分为训练集和测试集,均包含20张图像. 对于训练图像,可以对脉管系统进行单个手动分割. 对于测试用例,可以使用2种手动分段:一种用作黄金标准,另一种可以用于将计算机生成的分割与观察的结果进行比较. 此外,对于每个视网膜图像都可使用遮罩图像,指示感兴趣的区域. 经验丰富的眼科医生对所有手动分割脉管系统的观察者进行了指导和培训,要求他们标出所有血管并保证至少70%是正确的.
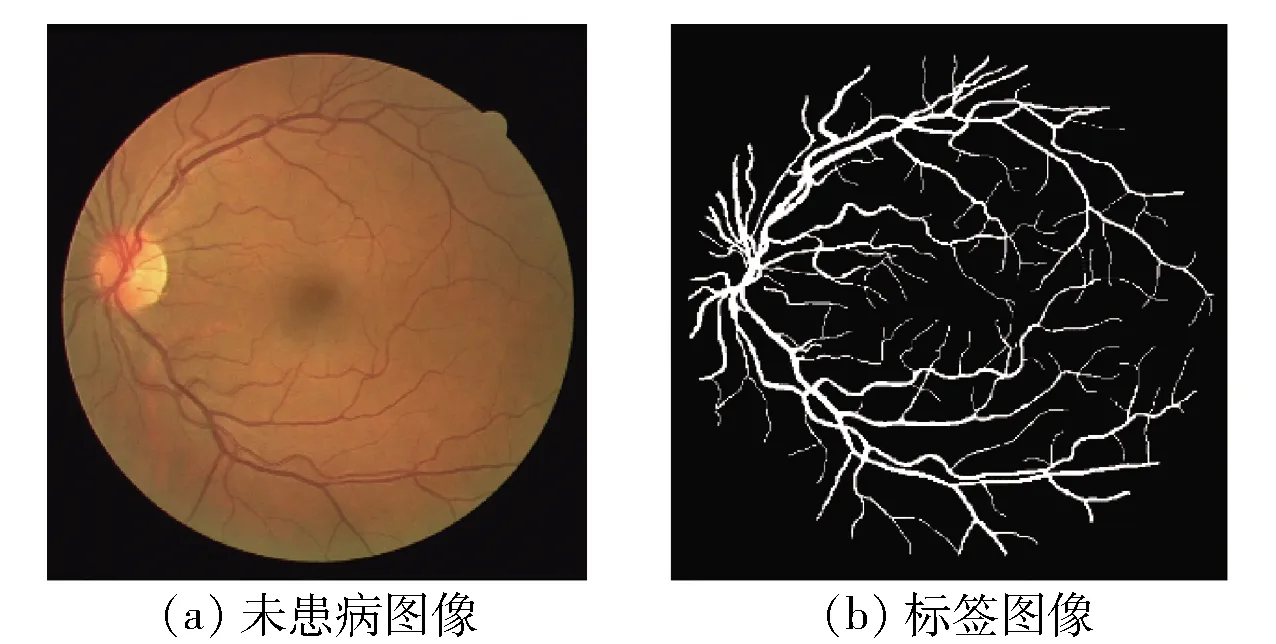
图4 未患病图像及其标签图像示例Fig.4 Example of a disease-free image and its label image
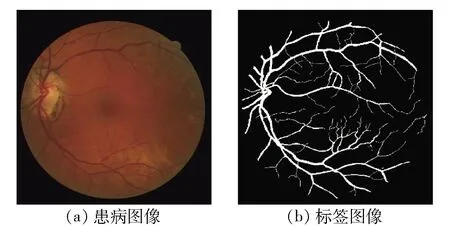
图5 患病图像及其标签图像示例Fig.5 Example of a diseased images and its label image
2.2 评价指标
为了与R2U- Net等进行比较,本文使用以下几个相同指标来评估性能,包括准确性(预测正确的概率A)、敏感性(预测患病正确的概率Se)、特异性(预测非患病正确的概率Sp)和F1评分(查准率P与召回率R的调和平均数). 首先计算真阳性(TP)、真阴性(TN)、假阳性(FP)和假阴性(FN),具体解释如表1所示.

表1 医学标准指标
计算不同的指标
(3)
(4)
(5)
F1得分的计算方法为
(6)
(7)
(8)
为了进一步评估不同神经网络的性能,还计算了受试者工作特征曲线下的面积SAUC.
2.3 注意力模块对算法性能的影响
本节首先对注意力模块对算法整体性能的影响进行了测试分析,相关结果如表2所示.
为了更好地适应LadderNet,本文选择在U型部分首先加入1个注意力模块,并在每一层都进行加入1个注意力模块的测试,从实验结果能够得出在第2层加入注意力模块是效果最好的. 之后便试着加入2个注意力模块,意图是进一步加强对血管特征的关注,但从实验结果看,效果不如只加入1个注意力模块好. 为了验证是否注意力模块增多会导致产生冗余的信息影响实验效果,于是选择进行加入3个注意力模块和4个注意力模块的实验,从最终结果可以看出,注意力模块的增多不但没有使微血管特征得到更好的关注,反而产生了更多干扰特征. 从表2可以看出,注意力模块的数量和加入位置对算法的整体性能有显著影响. 在位置1~4层分别加入1个注意力模块时,位于第2层时的效果是最优的. 当在不同位置加入2~4个注意力模块时,在第2、3层分别加入2个注意力模块的效果较好,但仍低于第2层加入1个模块的效果. 因此,对于本文算法来说,加入1个注意力模块是最优的选择,加入的最佳位置是在第2层上采样处.
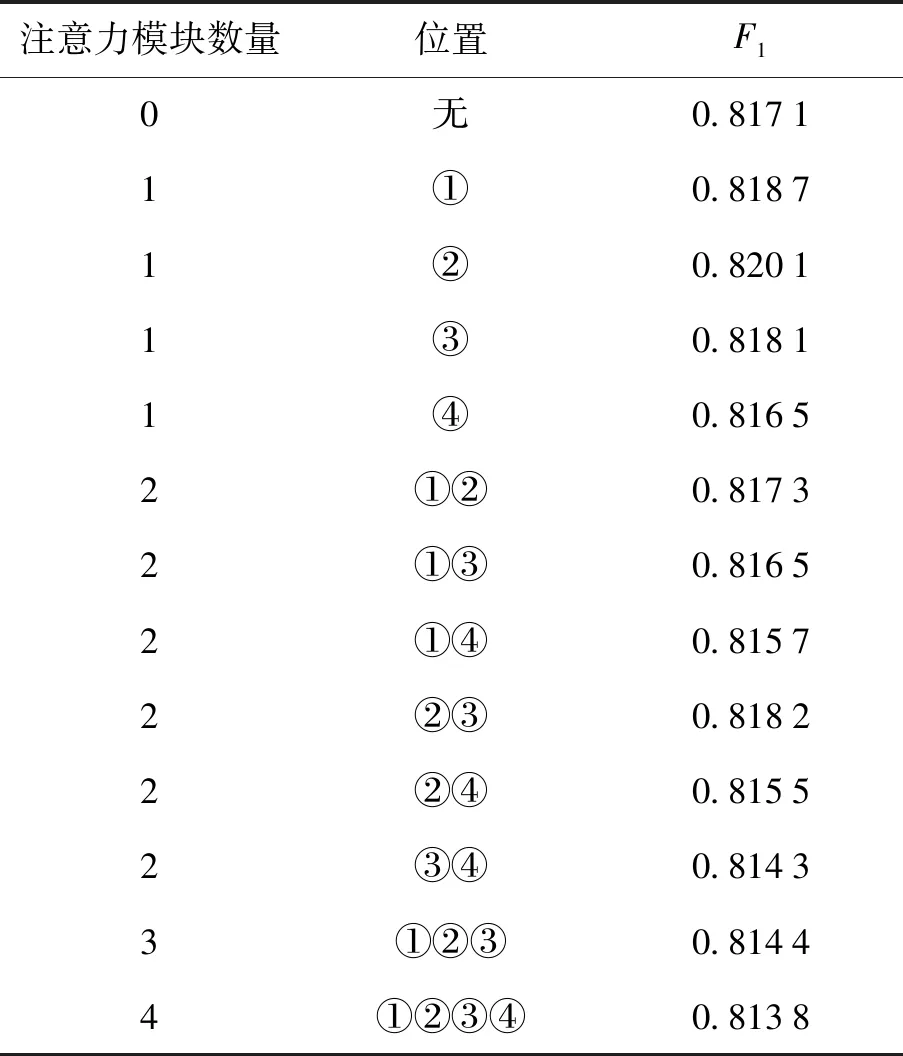
表2 注意力模块不同数量和不同位置测试结果
2.4 稠密卷积对算法性能的影响
本节测试了稠密卷积的效果,分析了不同数量的稠密卷积块对算法整体性能的影响. 在LadderNet中的U型部分中,其下采样之后有一个特征图大小不变的卷积,在经过该卷积操作之后再进行上采样部分,本文将这个部分换成稠密卷积,稠密卷积可以有效增强信息传递,增强了特征传播,促进了特征重用,降低了参数数量. 实验一开始就先进行了一层稠密卷积实验,即经过2次相同的卷积,之后把前2次卷积的结果相加,之后再进行一次相同的卷积操作,从实验结果看效果很好,仿照相同的模式叠加到2层稠密卷积,实验结果并没有越来越好. 于是进行了3层稠密卷积实验,从实验结果看,效果越来越差,相关实验结果如表3所示. 从表中可以看出,稠密卷积的加入可以不同程度提高算法的性能. 其中加入1层稠密卷积的效果是最优的,而稠密卷积的层数过多会导致信息冗余,造成F1下降.
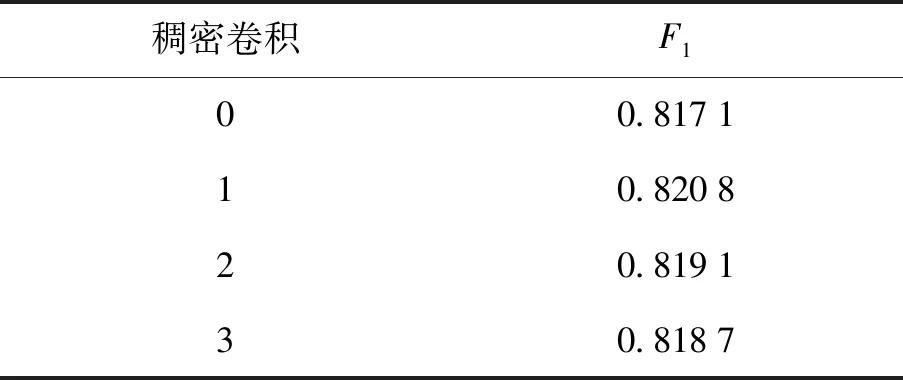
表3 不同层数稠密卷积实验结果
2.5 整体性能评估
在LadderNet的基础上同时加入注意力机制和稠密卷积后,算法的整体性能得到了进一步提升,最终实验结果与当前主流算法的对比结果如表4所示.
从表中数据可以看出,本文算法通过引入注意力机制和稠密卷积,从增强对微血管特征信息的提取和加强特征信息传递两方面提高了网络性能,使网络的整体性能得到了显著提高. 算法的F1得分和Se、A、SAUC指标都显著优于其他对比算法,只有Sp指标略有降低. 然而考虑到SAUC和F1得分对网络性能的评价相比Se、Sp指标更加全面,因此,本文算法的整体性能是更优的.
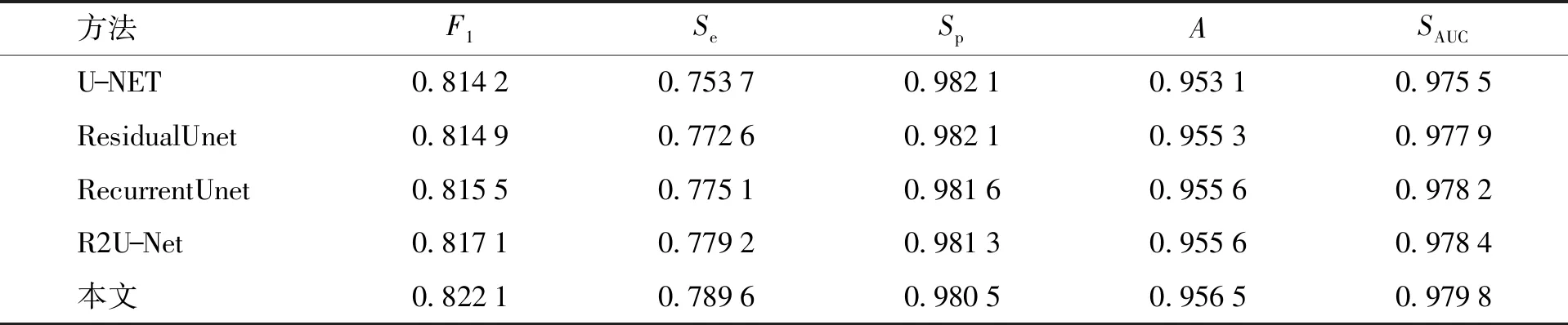
表4 不同方法在DRIVE数据集上评价结果
图6进一步给出了DRIVE数据集上的部分主观结果. 从图中可以看出,本文算法能够对视网膜图像中的血管进行精确的分割,所得的预测结果与标签图像基本一致,即使微小血管都能实现精确的分割.
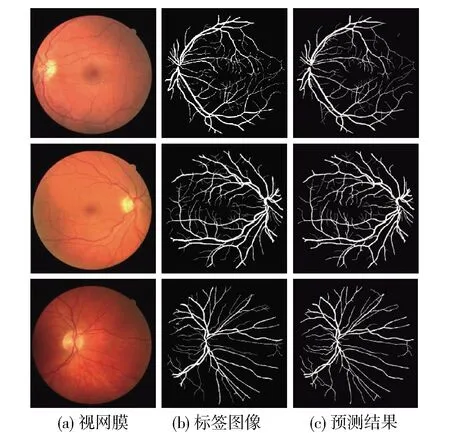
图6 DRIVE数据集上的测试结果示例Fig.6 Part of the test results on DRIVE
3 结论
1) 以LadderNet为基础网络,根据视网膜图像中微血管的特点和LadderNet的不足进行了改进,进一步提高了网络性能和网络适用性.
2) 为了更加突出微血管信息,加入注意力机制,使微血管的特征信息更加完整、准确地保留下来.
3) 使用稠密卷积在增强特征信息传递的同时减少参数数量,进一步提升了图像分割性能,增加了分割结果的准确性.
