面向订单的混流装配线多目标调度研究*
2021-05-24解占新闫玺铃陆春月
解占新,闫玺铃,陆春月*
(1.晋中学院 机械系,山西 晋中 030619;2.中北大学 机械工程学院,山西 太原 030051)
0 引 言
随着个性化市场的发展,越来越多的企业采用订单式生产模式来满足客户需求[1]。
为了以大规模生产的成本满足个性化定制的要求,企业需要在多品种的基础上来提高生产效率,又由于采用定制化生产,交货期相对较难确定,这就要求企业在产品品种、产量、工时、设备负荷均衡的前提下,利用一条流水线,科学地编排投产顺序,实行有节奏、按比例的混合连续流水生产。大部分产品一般需要经过部件装配,再进行总装,由于不同部件生产节拍不同,会在总装环节产生库存积压或缺料,靠传统的人工排产很难实现总装分装系统的生产流畅,需要对总装线和多条分装线进行协同计划与调度,才能有效地解决上述问题[2]。
目前,关于混流装配调度方面的研究较多,一般集中在装配线的平衡性及调度效率方面,优化目标多为装配周期、完工时间、成本等指标[3-6],优化算法大致可归为数学规划、启发式算法和智能算法[7]。订单交付的准时性在实际生产中很受重视,但这方面的研究较少。PENG Y F等[8]设计了一种以准时交付为目标的混流装配线启发式算法,比传统的周期交付算法更具优越性,但该研究为基于产线整体的单目标优化调度算法。实际生产中多条流水线协同组织生产,一般进行分装然后进行总装,因此该模型不能很好地描述混流装配线生产的实际过程。
本文将混流生产装配分为子装配和总装配两个阶段,并用两个目标函数来描述上述问题,通过改进社会粒子群算法对此进行求解验证。
1 面向订单的混流生产线建模
1.1 问题特点及描述
混流生产线的生产组织方式有两种:现货生产(MTS)和订单生产(MTO)。现货的需求量与交货期是确定的;订单生产的需求量与交货期事先是无法确定的。
本文研究按订单生产的产品,装配时先由零件装配成子装配,再将各子装配进行总装。对于不同的订单,其装配工艺流程、装配作业方法以及装配作业设备是相似的。
整个装配过程的问题抽象模型如图1所示。
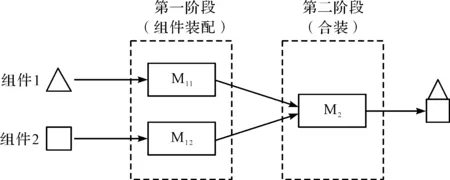
图1 问题抽象模型
由图1可知,装配过程为两个阶段:第一个阶段,根据装配工艺流程在各装配工位流转装配,各子装配和零件在到达总装配工位时间准确,且最大完工时间最短;第二个阶段,工件经过总装后,要求整个完工时间接近交货期,准时交货。
根据装配工艺的顺序要求,产品在分装线上装配之后分批次分阶段供应总装,部件齐套后才能进行总装线的生产。产品装配时,依次按一定速度通过每个装配工位,每个工位至少有一台设备工作。第一阶段由m台设备对m种零部件进行并行作业,第二阶段由1台设备进行产品总装,每个产品只有经过第一阶段m台设备的装配,才能进入到第二阶段,同一工序的设备功能相同,每个工位最多只能加工一个工件,实现一种部件的装配工作。每个工件在相应设备上的每道工序所需的加工时间已知,要解决在调度目标最小的情况下,确定所有工件的顺序和各工位的设备配置的问题[9,10]。
1.2 多目标优化数学模型
混流装配生产线生产过程分为分装和总装两个阶段,分装的部件到达最后工作台的时间或早或晚都会影响装配的最后环节,从而影响交货期。笔者用同时度来衡量第一阶段部件全部到达最后装配工作台的程度,用准时度来衡量整个装配阶段的时长之于产品交货期的准确程度;建立同时度和基于产品订单交货时的准时度,作为生产线的调度目标。
以第一阶段各零件装配成子装配的最早与最晚完工时间差为目标[11,12],同时度的优化函数可被定义为:
(1)
式中:MT—同时度优化函数,min;P—产品总数,个;J—产品的编号,J=1,…,P;BJ—产品J所需的工件总数,个;jJ—商品J的第j个工件,jJ=1,…,BJ;I—工件的加工工序总数;j—工件的编号,j=1,…,n;i—第i道加工工序,t=1,…,T;CT(j,i)—工件j在第i道工序完成时间,min;C(J)—产品J最后组合装配结束的时间,min。
上式的含义为在装配发生的第一阶段,组成同一产品的不同部件及子装配之间完工的时间间隔最小。
整个产品准时交货的能力为截至到该生产周期期末,若总生产时间大于交货期则产生延期违约,产品拖期惩罚,若总生产时间小于交货期则提前完工,会增加产品库存成本。总生产时间要求尽可能地接近交货期,每一道工序并不是越早提前完工越好,若提前完工,则每道工序需要投入的存储成本越高,建模时通过给提前完工这一项的时间加权重,来降低提前完工的库存压力,权重取值范围(0,1),具体数值根据提前完工在实际生产中发生的概率来定。
设提前拖期惩罚函数为ET,准时度的优化函数为:
(2)
式中:ET—提前拖期惩罚函数,min;λ0—权重;E(J)—产品J提前完成时间,min;T(J)—产品J拖期完工时间,min。
上式的含义为产品的实际完工时间与客户要求的交货时间之间的差值最小。
该模型的约束条件如下:
(1)同一工序上只能有一台设备加工一个工件:
(3)
式中:Mi—加工第i阶段,并行设备的数量,台;m—第i道工序并行设备的数量,m=1,…,Mi;Yjim—1为在第i阶段,第m台设备上加工工件j;0为其他情况。
(2)工件的加工顺序是固定的,上道工序结束后才可进行下道工序:
C(j,i)≥C(j,i-1)+P(j,i)
(4)
式中:C(j,i)—工件j在第i道工序完成的时刻,min;P(j,i)—工件j在第i道工序的加工时间,min。
(3)一台设备一次只能处理一个工件:
(2-Yjim-Yrim+Xjri)+CT(j,i)-
CT(r,i)≥P(j,i)j>r
(5)
(3-Yjim-Yrim-Xjri)+CT(r,i)-
CT(j,i)≥P(r,i)j>r
(6)
式中:r—工件的编号,r=1,…,n;Xjri—1为在第i道工序上,工件j的优先级高于工件r,0为其他情况。
(4)产品的完工时间,也就是最后一道工序的完成时间:
C(J)≥max(0,dJ-C(J))jJ=1,…,BJ
(7)
式中:dJ—产品J最后合装对应的时间,min。
(5)产品的平均提前与延后的交货工期:
E(J)=max(0,dJ-C(J))J=1,…,P
(8)
T(J)=max(0,C(J)-dJ)J=1,…,P
(9)
2 基于二维编码的社会粒子群算法
2.1 社会粒子及吸引点
根据建立的混流装配线的数学模型,采用粒子群算法求解时其收敛速度快、鲁棒性好,但是其寻优策略在后期的搜索过程群中,各向同性的粒子容易聚集在最优解附近,易陷入局部的极值。因此,本文设计一种基于社会粒子群的改进算法,将“社会原子”引入到粒子群算法中。社会原子具备向社会整体主流趋近的特征,但每个原子具有不同的“趋向阈值”,阈值越高的个体独立性越高,阈值越低的个体更容易去跟从其他个体,即:
(10)
(11)
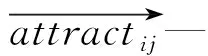
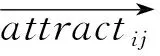
将社会原子中趋向阈值为零的粒子定义为自由粒子,能随机生成速度和位置,其他粒子对其更新迭代不产生影响。趋向阈值不为零的粒子定义为跟随粒子。吸引点在跟随粒子的迭代更新过程中会影响其状态。吸引点附近跟随粒子的数量是跟随粒子状态改变的判断依据,是维持现状还是跟随该吸引点。优化结果的快速寻找,只需要通过动态调整社会原子的趋向阈值来提高优化算法的搜索能力。
自由粒子在社会原子中的比例随着迭代的进行减小,其自适应调整策略如下:
(12)
式中:Tx—第x个粒子的初始阈值;K—常数;k—变量,与种群的最优解的适应度值的变化相关,当k=K时,粒子的趋向阈值减为0。
2.2 粒子编码与解码设计
2.2.1 二维编码
混流装配线上,不同的产品其装配工艺也有所不同,自然数1,2,…,n表示工件的序号,n个工件分别有i1,i2…,in道装配工序,则Sni表示第n个工件的第i(i<=in)道工序。装配线上有若干个产品需要装配,每个产品又包含若干个零件,这些零件的装配工序排序为一个粒子。
为了描述该粒子,可定义为一个二维向量。该粒子的第一维向量由n个工件按其序号将各自工序依次罗列组成,则第一维向量由N=∑n·in个数据组成。第二维向量由一组随机数产生,该组随机数由N个(0,1)之间的数组成,将其按降序排列得到粒子的位置矢量。随着粒子位置矢量的排列变动,粒子对应的第一维向量也随之变动。粒子相应位置上的随机数为生产权重,其值的大小决定了被安排生产任务的优先权,值越大,其优先级越高。
设某生产线上有产品1和产品2两个工件需要装配,其测试数据如表1所示。
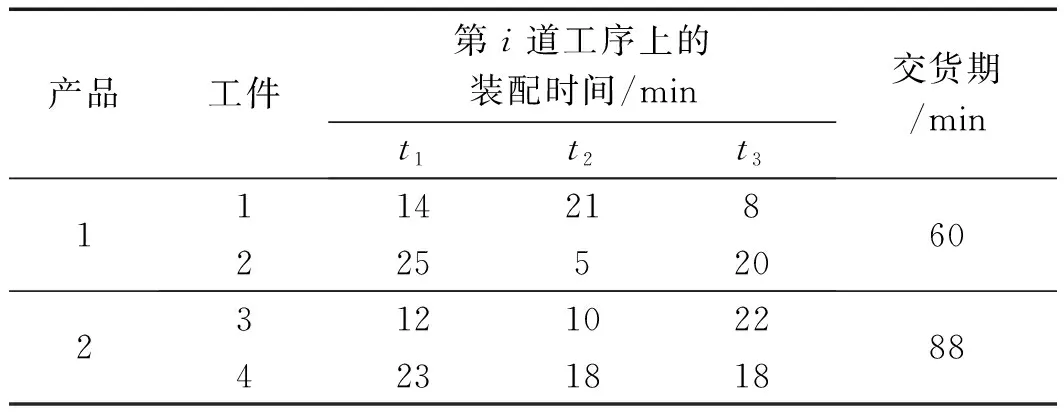
表1 测试数据
由表2可得产品1由工件1和2组成,产品2由工件3和4组成,每个工件有i1=i2=i3=i4=3道工序组成。
根据测试数据对粒子进行二维编码,粒子的二维编码如图2所示。
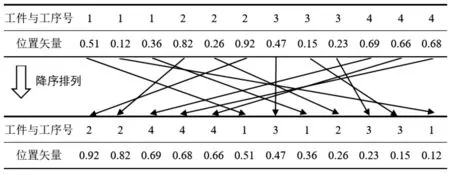
图2 粒子的二维编码
粒子首先生成初始编码,图2中的第1个的表所示,第一维向量的初值为图中第1个表的第1行数据,其第i个1表示第1个工件的第i道工序,其后的第i个2表示第2个工件的第i道工序,以此类推。粒子的第二维向量的初值为图中第一个表的第2行数据,是一组随机数,将这组随机数按递减顺序排列,此为一个粒子的二维编码位置矢量,第一维向量即为工件工序序列。排列完成后得到一个粒子的编码,图2中的第2个表中的数据排列。
2.2.2 解码
粒子的解码就是按粒子的惯量权值大小的优先级进行排列,其相应的工序与工件号也依此顺序排序。
设工件号为Rs,其含义表示第s个产品的第R个工件。解码完成后,在序列第一次出现的工件号即为该零件的第一道工序,当这个工件号再次出现时,就是该零件的第二道工序,以此类推。降序排列后随机粒子的可行解的序列为S21,S22,S41,S42,S43,S11,S31,S12,S23,S32,S33,S13。
工件加工调度方案如表2所示。
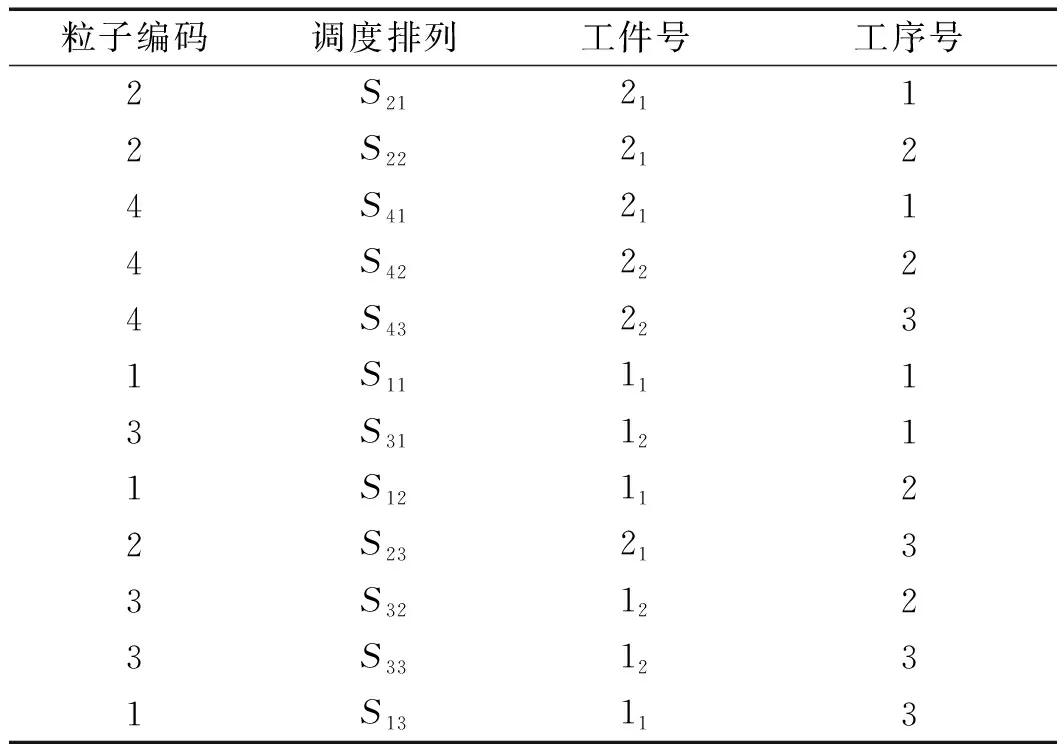
表2 调度方案
2.3 惯量权值
为了避免后续遍历过程中局部优化能力的降低,必须降缓其收敛速度,才能不遗漏粒子群的最优位置。因此,式(10)中的惯量权值λ1就要重新赋值,使得粒子种群迭代序列逼近其局部最优值的速度自适应调整。
构造线性递减的λ1表达式,兼顾搜索效率和搜索精度,即:
(13)
式中:λmax—惯量权值的极大值;λmin—惯量权值的极小值;Q—最大迭代次数;q—当前迭代次数。
2.4 适应度函数设计
在粒子群算法中,用适应度值用来判断算法的优劣,适应度函数的构造尤为重要。本文设计的适应度函数以车间调度的问题为基础,将涉及到的求解问题转化为函数关系式,将不同的目标函数加上合适的权重,最后求和得到最终的适应度函数,通过适应度函数的计算得到最优解。
适应度函数如下所示:
f(x)=ω0×f1(x)+(1-ω0)f2(x)
(14)
式中:ω0—权重。
该适应度值为同时度与准时度两个目标函数的求和,在适应度函数中,用权重来设置其所占的比重,其取值范围为(0,1)。
2.5 自然选择
自然选择就是将达尔文进化论中的思想应用到粒子群算法[9]中,在每次寻优迭代算法过程中,根据上述适应度值的大小,将粒子进行升序或者降序的排序,用种群中适应度值最优的1/2粒子取代剩余适应度值最劣的粒子,并保存每个粒子遍历后的历史最优值。
2.6 算法流程
社会粒子群算法求解分段混流装配的车间调度改进粒子群算法的流程,如图3所示。
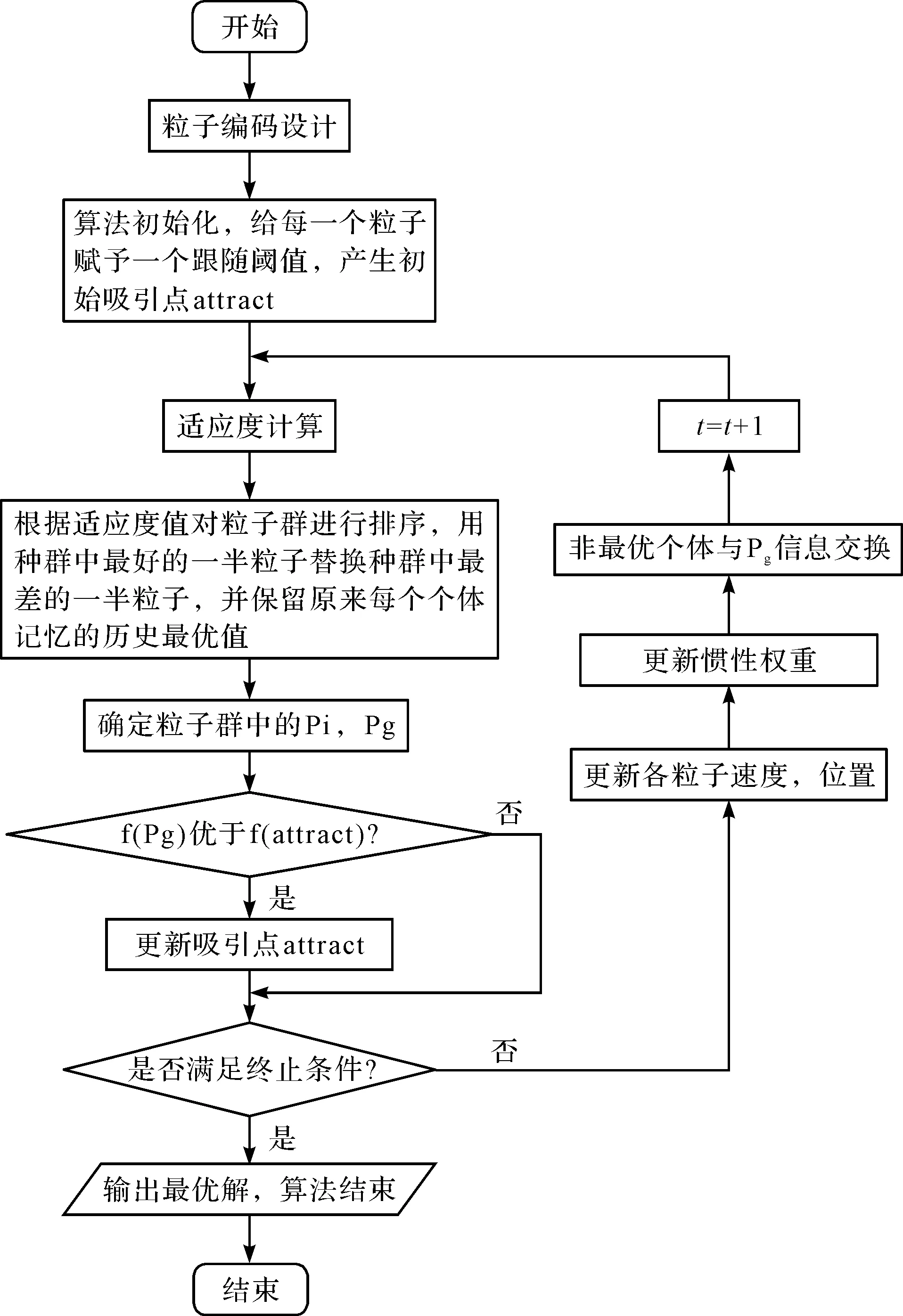
图3 改进粒子群算法的流程图
改进粒子群算法计算机实现的主要步骤如下:
步骤1:粒子二维编码设计;
步骤2:初始化粒子群。设置群体的规模N,粒子的初始位置xi和速度vi。将跟随阈值赋给每个粒子,从而产生初始吸引点;
步骤3:适应度值f(xi)计算。根据适应度函数,在迭代中计算粒子的适应度值,依此对粒子群进行排序;
步骤4:自然选择。根据步骤3经过排序的粒子群,用种群中适应度值最优的1/2粒子替换种群中适应度值最劣的粒子,并且保留个体最优;
步骤6:更新参数。将新的位置xi和速度vi及权值代入式(10,11);
步骤7:判断若到达终止条件(结果得到较优或循环次数已经到达设置的最大循环次数)则退出,否则返回步骤3,继续进行计算。
3 实验与分析
以某企业装配线为例验证算法的有效性。设有不同型号的4种部件,每种部件有不同个数的零件组成,已知每个部件的装配顺序,每个工件有4道工序,每道工序上的分装时间及交货期根据企业实际数据给出。
产品工件的分装时间和交货期如表3所示。
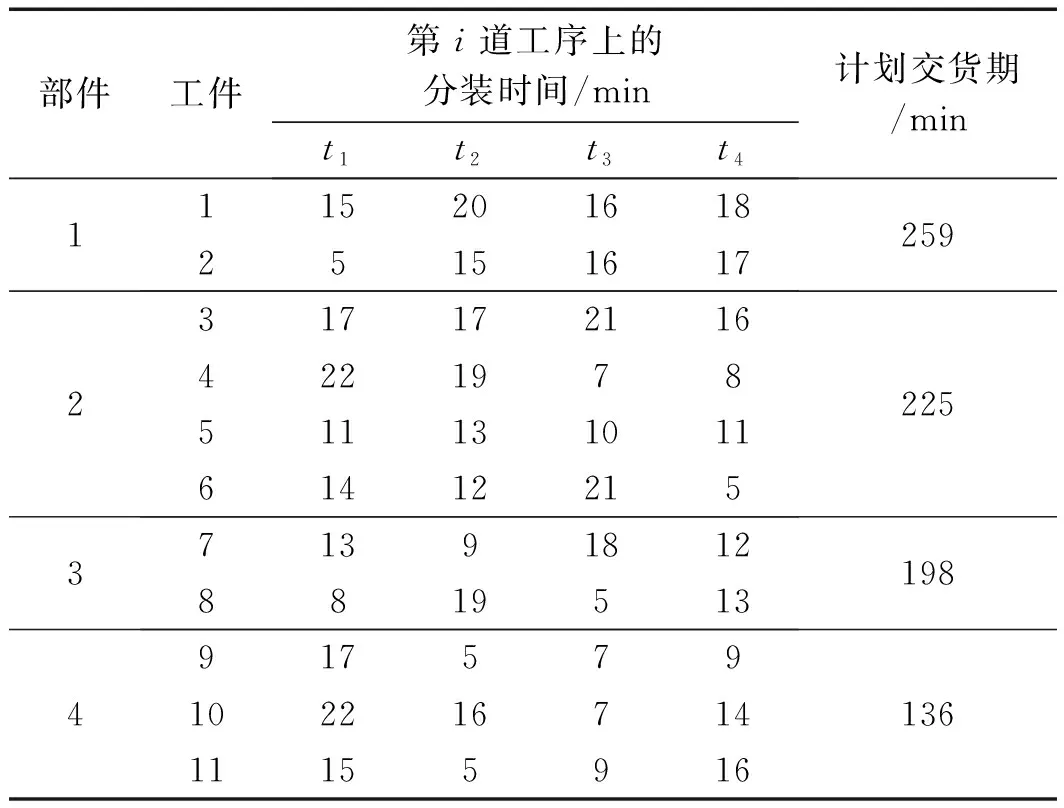
表3 产品工件的分装时间和交货期
各产品的总装时间分别为9 min、11 min,17 min和6 min。将上述数据的信息进行编码写入算法程序中,用Matlab2017b版编程,程序运行环境为i5处理器、8 G内存、2.5 GHz主频。程序算法主要参数设定为种群个数20,迭代次数Q=500,惯量权值最大λmax=0.625,惯量权值最小λmin=0.450,加速度常数c1=2,c2=2.1,提前完工权重λ0=0.3,适应度函数中的f1(x)的权重值ω0=0.65。
该调度计划生产的4种部件共11个工件,用改进社会粒子群算法求解与标准粒子群算法,文献[14]中的混合粒子群算进行10次对比。
仿真结果对比如表4所示。
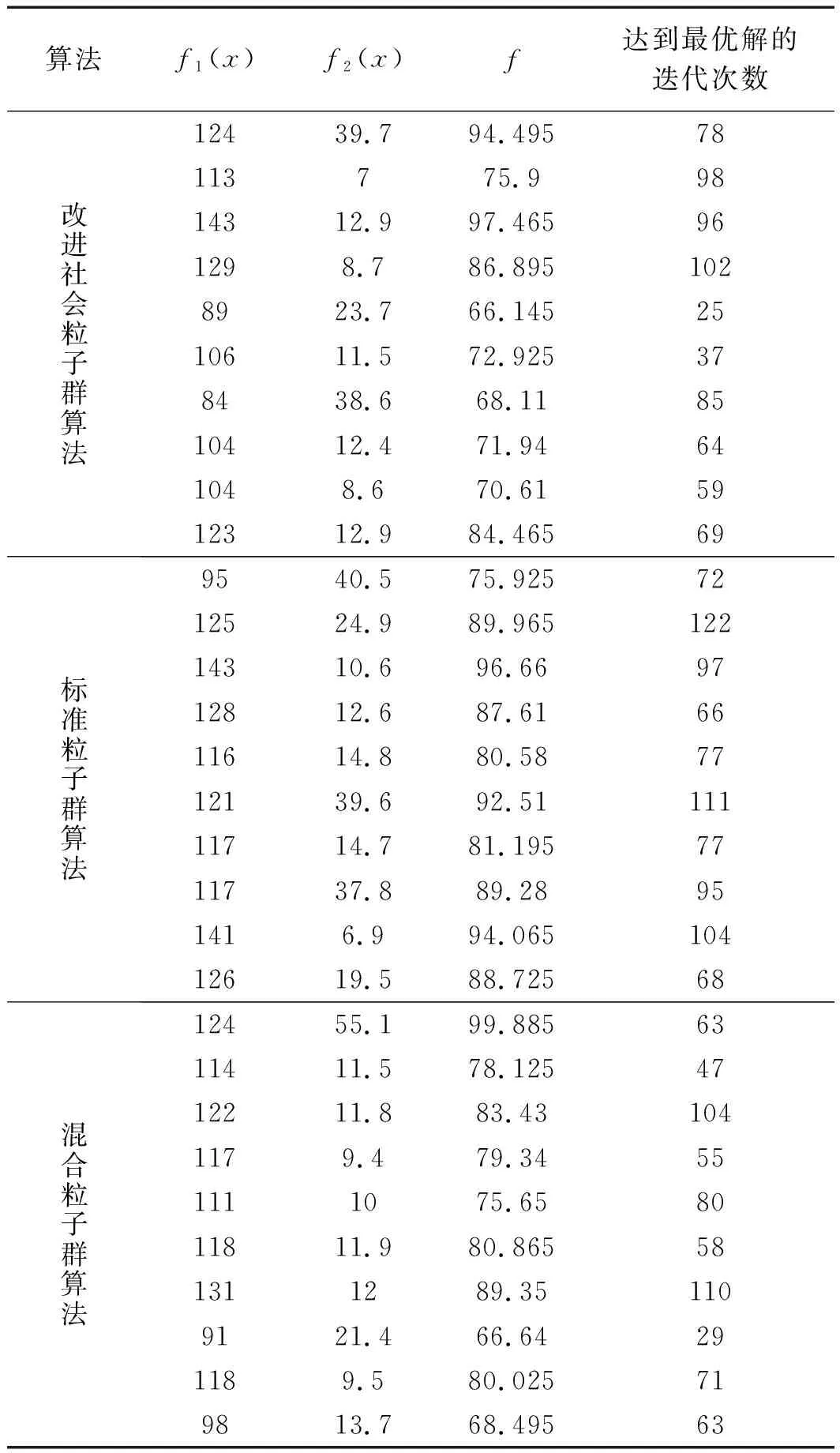
表4 仿真结果对比
由表4的仿真数据可得:在标准粒子群算法的仿真实验中,第1次实验的适应度值最小为75.925,结果最优,达到最优解的迭代次数为72次;改进社会粒子群算法的10次仿真实验中,第5次实验的适应度值最小为66.145,结果最优,达到最优解的迭代次数为25次;混合粒子群算法的10次仿真实验中,第7次实验的适应度值最小为66.64,结果最优,达到最优解的迭代次数为29次。
3种算法仿真得到的算法迭代图如图4所示。
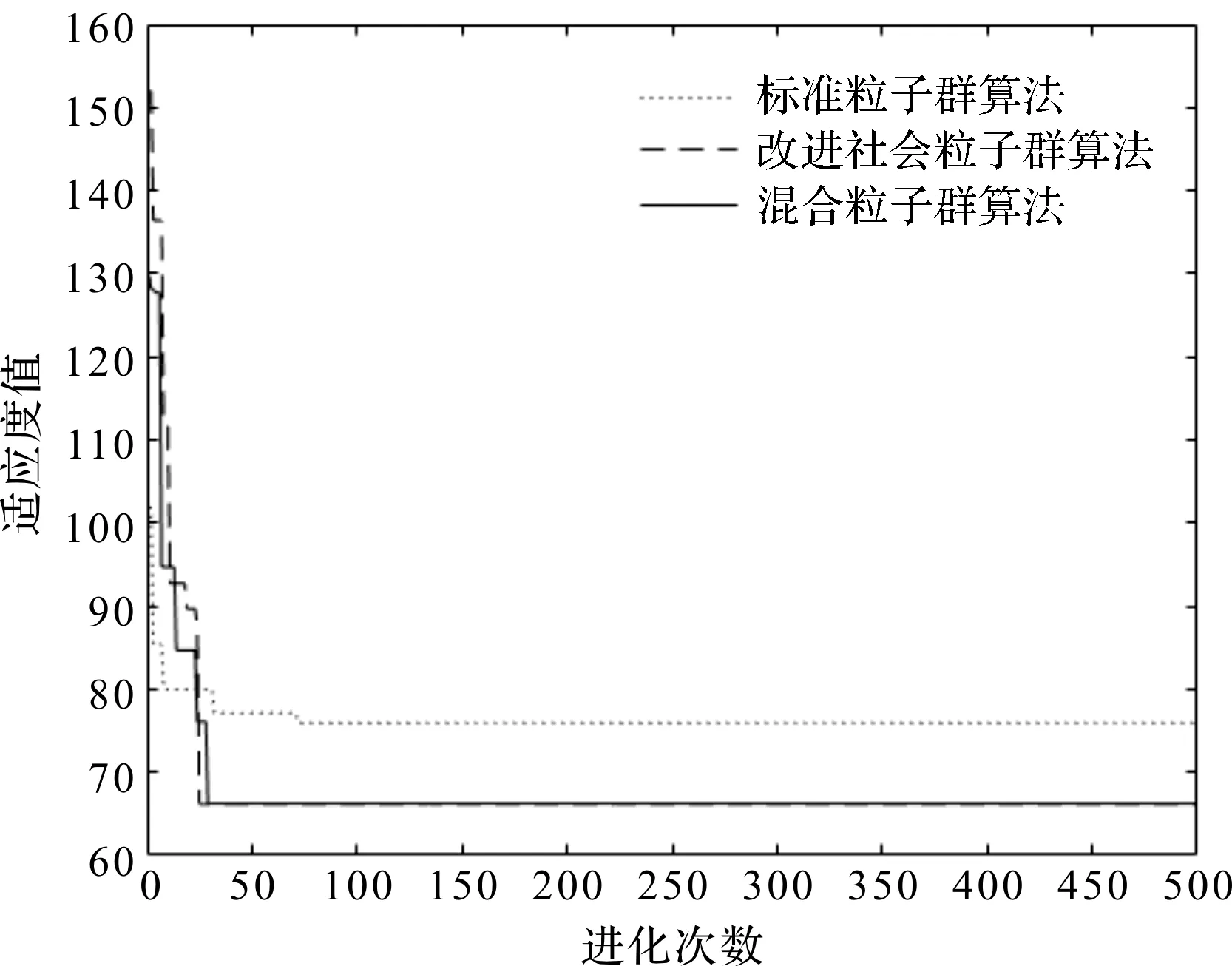
图4 算法迭代图
由图4可知:改进社会粒子群算法[15]的收敛速度较快,求解较为稳定且求解精度高,保证了所有得到的解尽可能接近最优的解;改进社会粒子群算法迭代到第25次得到最优解,其结果优于标准粒子群算法和混合粒子群算法。
最优结果为:总的调度目标函数为f=66.145,同时度f1(x)=89,提前拖期函数f2(x)=23.7。
最优解的甘特图如图5所示。
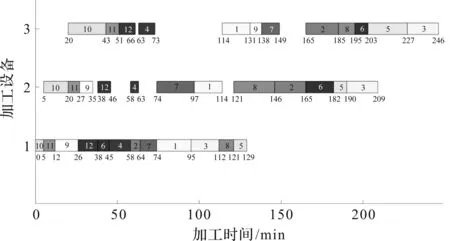
图5 最优解的甘特图
从图5可知:每个工件每个工序开始加工的时刻、加工时间、加工完成的时刻:工件在设备1上的加工顺序为:3→10→11→9→2→5→8→7→1→4→6;在设备2上的加工顺序为:3→10→11→9→2→7→5→4→8→6→1;在设备3上的加工顺序为:10→11→9→7→2→4→3→8→6→5→1;在设备4上的加工顺序为:7→10→2→11→6→5→9→4→3→8→1。
设备1开始加工的时刻为0,结束时刻为159 min,机器设备率为100%;设备2开始加工的时刻为17 min,结束时刻为215 min,机器设备率为74.75%;设备3开始加工的时刻为55 min,结束时刻为244 min,机器设备率为72.49%;设备4开始加工的时刻为135 min,结束时刻为303 min,机器设备率为82.74%;4个产品分装完工时间为[178,223,285,194],加上总装时间[9,11,17,6],则,每个产品最终完工时间为[187,234,302,200]。
4 结束语
本文针对面向订单的混流装配线调度的问题进行了研究,建立了多目标的数学模型;设计了一种二维编码方式,将生产信息用特定的方法进行了编程;在社会粒子群算法中引入了吸引子,使得自由粒子和跟随粒子的比例实现了自适应调节,在此基础上惯性权重采用线形递减的方式;采用自然选择的方式将粒子进行选择替换,提高迭代的效率,更有可能得到较优的结果。
通过与标准粒子群算法及混合粒子群算法的对比,验证了本文模型及算法的可行性与优越性。
