图数据压缩格式对广度优先搜索算法影响的特性化分析
2021-05-24邓军勇
任 含,邓军勇
(西安邮电大学 电子工程学院 陕西 西安 710121)
0 引 言
在当前信息化时代,随着物联网和云计算的日益发展,生物医学、网络社交、网络信息追踪等许多领域内的数据信息量呈指数增长,并且越来越多的信息被连接起来,以图形形式存储在各个领域[1-2]。由于这些数据信息规模和计算的日益复杂化,给现代图处理系统提出了巨大的挑战。图计算是处理各种数据信息的常用手段之一[3-5],不同压缩格式的数据信息会对图计算问题产生不同的影响,如何选择合适的图数据压缩格式以达到最佳性能需求是一个不可避免的问题。
图可以表示不同实体间复杂的依赖关系[6-7]。图数据可以由不同的压缩格式来表示,不同的图数据压缩格式有不同的表示和复杂度。当前很多研究采用不同的图算法解决方案来提高图数据处理时的性能和效率,但是由于图算法的性能效率由不同图数据压缩格式中边和顶点的处理来确定,在执行过程中,程序的行为不仅会随时间变化而变化,更重要的是不同的图数据压缩格式复杂度会对图算法处理产生不同的影响,因此有效地应用图算法是一项艰巨的任务[8-9]。所以在图算法中如何快速选择合适的数据压缩格式以达到预期的最佳性能是本文的一个重要研究问题[10]。本文针对BFS算法处理不同压缩格式图数据时的性能指标进行特性化分析,为不同条件下应该选择不同压缩格式的数据集提供了依据。
大孔树脂是一种人工合成的具有多孔立体结构的聚合物,对一些芳香族化合物有很强的吸附能力,已广泛应用于很多活性成分如黄酮、内酯、生物碱等大分子化合物的提取分离[8]。对于红薯叶黄酮的研究大多集中在有机溶剂提取法[1]、超声波辅助提取法[7]、酶提取法等[5]方面,有关大孔吸附树脂对于红薯叶黄酮的吸附分离研究报道较少,尤其是缺乏其吸附、解吸特性的研究,因此,本试验研究了大孔树脂对红薯叶中总黄酮的吸附与解吸特性,优选出适合红薯叶总黄酮提取的树脂材料并确定了最佳吸附及解吸参数,以期为红薯叶的综合开发利用提供科学依据,为红薯叶黄酮的工业化生产提供理论参考。
图计算中有5种数据格式:双压缩稀疏列(doubly compressed sparse column,DCSC)[11-13];压缩稀疏列(compressed sparse column,CSC)[14];压缩稀疏行(compressed sparse row,CSR)[15-16];坐标表示(coordinate,COO)[17];独立稀疏列压缩(compressed sparse column independently,CSCI)[18-19]。将这5种数据压缩格式作为遍历类应用广度优先搜索(breadth first search,BFS)算法的输入数据格式进行运行性能事件统计,分析基于BFS算法处理不同压缩格式时的性能指标,性能指标参数包括每周期指令数、数据移动量、功耗、各级cache缺失率以及执行时间等,不同数据压缩格式在BFS算法处理中提供了不同的性能指标。
1 算法及压缩格式分析
1.1 BFS算法
广度优先算法是一种常见的图搜索算法,以一种系统的方式搜索图数据中的所有顶点,计算从源点到所有其余顶点所需要遍历的最小边数值,特别是在求解最短路径或者最短步数等问题上有很多的应用[20]。BFS算法的基本思想是给每个活动顶点分配一个深度depth,此深度代表从根节点s到其他所有顶点所需要遍历的最小边数。初始化时,根节点的深度设置为0,并标记为活动状态,将其他活动顶点的深度设置为无穷远,在移动到下一级相邻顶点之前首先对相邻顶点进行探索,在t次迭代后每个顶点与活动顶点的深度公式为[21]depth(v)=min(depth(v),t+1)。若更新导致深度发生变化,则顶点到下一次迭代中变为活动状态。BFS算法伪代码如下。
输入:Graph G(V, E),源顶点s。
输出:dis[n],从源顶点s到其他各个顶点的最短路径长度。
For all n∈V do
为了指导地勘单位践行绿色理念,全面推进我国绿色勘查工作,不久前中国矿业联合会正式发布了我国绿色勘查第一个团体标准——《绿色勘查指南》(T/CMAS 00012018)。
d[v]=min(d[v],le);
(5)各级cache的缺失率。MPKI(misses per kilo instructions)是一个用来分析cache性能的通用指标,造成cache缺失的因素有数据的大小、cache的映射策略等,因此很难从理论上预估cache的缺失率而导致的时间损耗。利用perf分析工具可以更真实地观察到cache缺失率的情况。用cache_miss表示cache丢失率,instructions表示使用指令数,各级cache的缺失率计算公式为
动态心电图检查采用美国BMS动态心电分析系统,无症状性心肌缺血的诊断标准为:①ST波段呈水平型或下斜型的下移,下移距离达到0.1 m V;②ST波
state[n]=0; ∥顶点n的活动状态
state[s]=1; ∥源顶点s的活动状态
二元论则强调对于当地的民族特色和文化传统的挖掘,在资源开发与产品设计过程中坚持文脉原则,以实现对于原生湿地生态资源的充分利用(实践中也只有在生态旅游资源开发中融入地域文化因素,才能够真正实现资源的科学和充分利用)。因此从长远计,加强对“黄河口”文化的系列研究,深入挖掘“黄河口”文化内涵,实现原生湿地生态资源充分合理利用,是黄河口生态旅游目的地发展为国际知名旅游目的地的必由之路和发展方向。
queue<—s; ∥源顶点s入队
while(queue !=φ)do
(3)计算量。在程序执行中,对于同一个算法处理同一个数据集的不同压缩格式时,计算量也是影响性能指标的重要因素之一。不同压缩格式下,数据集处理时计算量的公式为
queue<—v;
中国石油大学胜利学院是由国家教育部批准设立,教育部直属高校中国石油大学(华东)和国家特大型企业胜利石油管理局合作举办的按新的办学模式和运行机制运作的全日制普通本科高等院校,是山东省首家由重点大学申办的规范化独立学院。
state[v]=1;
d[s]=0; ∥源顶点s的距离
le=le+1:
s← v。
使用手动对焦模式拍摄,故意不让主体清晰锐利,旋转对焦环让画面中的一切都变得模糊,能够在明亮背景前特别出效果。
1.体验式教育实践课程体系设计思路。体验式教育实践模式的构建,对人才培养方案中课程设置的种类、数量、比例等都有一定的要求。课程设置应该遵循理论学习与教学实践相结合的原则,理念上强调“一体化”,达到“夯实基础课程、整合专业课程、强化教育实践课程”的目标,突出课程设计的师范性、实践性。比如专业必修理论课程应适当降低难度,增设兴趣选修课程,拓宽知识领域;教育实践课程强化专业技能训练,重视实践体验,实现特长发展。一体化的教育过程中,专业素养培养与教学技能训练既相对分离又相互渗透,最终实现人才培养的要求。
1.2 五种压缩格式分析
(1)DCSC压缩格式是CSC压缩稀疏列的拓展。该压缩格式可以有效存储大规模稀疏矩阵[7]。主要是使用JC、CP、JR、VAL4个数组来存储数据[12-13]。将图1所示的原始矩阵用DCSC压缩格式表示,表示结果如图2所示。其中:JC是至少有一个非零元素列的列索引;CP是列指针,可以访问非零元素的列索引;JR是非零元素的列索引中的非零元素相对应的行索引;VAL是列索引和行索引对应的数值。
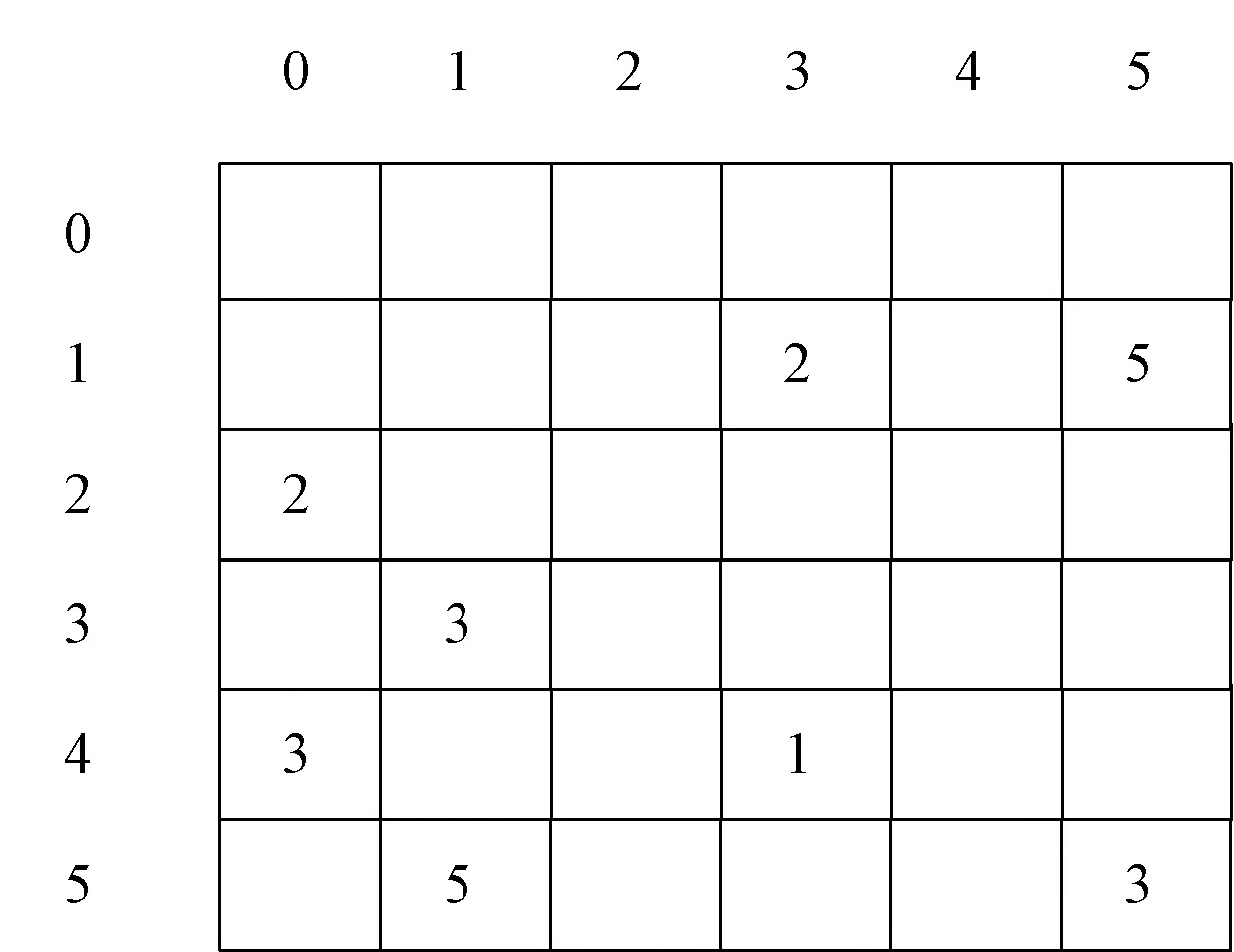
图1 原始矩阵
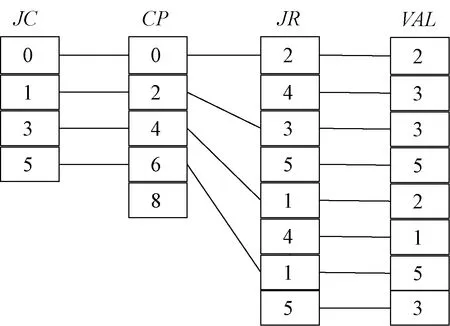
图2 原始矩阵的DCSC压缩格式
(2)COO压缩格式按坐标表示每一个非零元素,可以直接定位。用3个数组JR、JC、VAL分别表示非零元素所在的行号、列号以及非零元素的数值[17]。原始矩阵使用COO格式表示如图3所示。
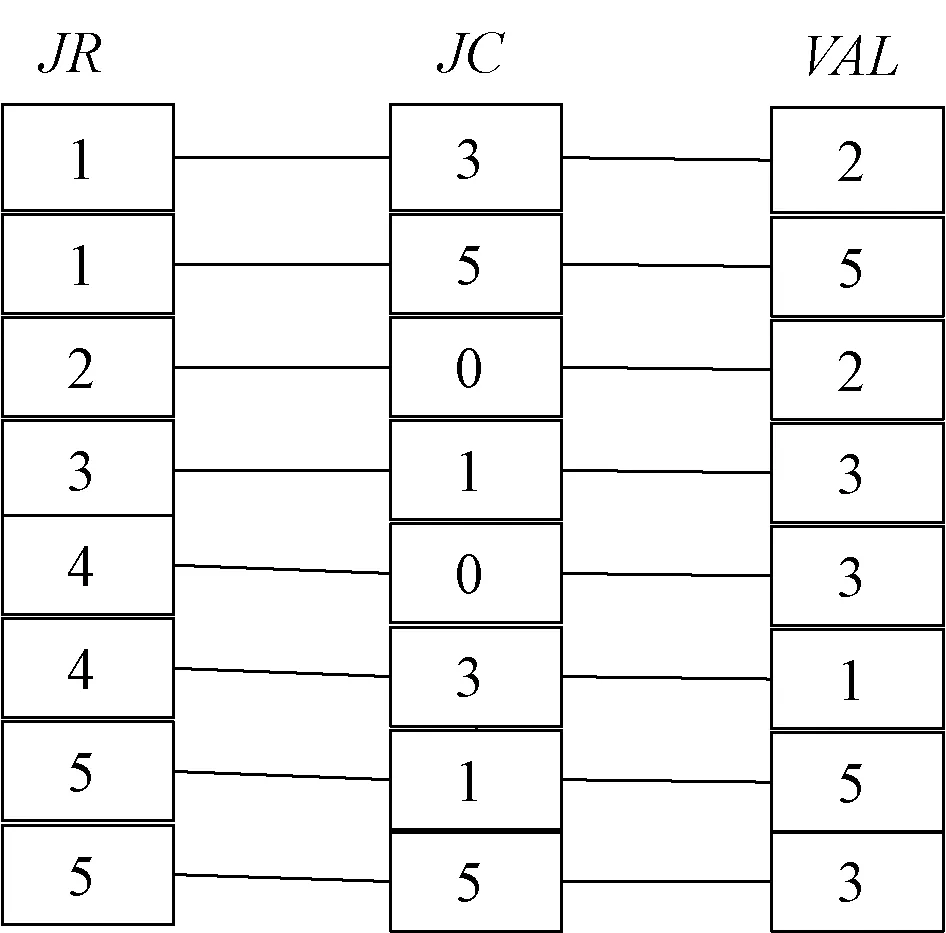
图3 原始矩阵的COO压缩格式
(3)CSC压缩格式主要是使用JR、CP、VAL3个数组来存储数据[14]。原始数据对应的CSC压缩格式表示如图4所示,其中:JR是非零元素列中的非零元素所对应的行索引;CP是列偏移值,表示某一非零列的第1个非零元素在当前列之前的非零元素的个数;VAL是行索引对应的数值。

图4 原始矩阵的CSC压缩格式
(4)CSR压缩格式按行压缩,与CSC相似,主要是使用CP、JC、VAL3个数组来存储数据[15-16]。原始数据对应的CSR压缩格式表示如图5所示,其中:JR是至少有一个非零元素行中的非零元素所对应的列索引;CP是行偏移值,表示某一非零行的第1个非零元素在当前行之前的非零元素的个数;VAL是列索引对应的非零元素值。
d[n]=∞; ∥顶点n的距离

图5 原始矩阵的CSR压缩格式
(5)CSCI压缩格式中每列独立压缩后的图数据包括列标识ioc、索引index和数值value,由列标识ioc指示index其余位与数值value的含义。当ioc为“1”,index表示为列索引,value表示邻接稀疏矩阵中该列的非零元素数目;当ioc为“0”,index表示为当前列的非零元素所在的行号,value表示稀疏邻接矩阵中对应的非零元素值[18-19]。基于图1原始矩阵,CSCI的压缩结果为(1,0,2),(0,2,2),(0,4,3),(1,1,2),(0,3,3),以此类推。
2 实验环境与性能指标定义
2.1 硬件平台
本次实验采用的分析工具是基于Linux系统的虚拟机中自带的系统性能分析工具perf[22],通过perf分析工具,应用程序可以利用pmu、tracepoint和内核中的特殊计数器来进行性能分析统计,不仅可以分析指定应用程序的性能问题,也可以分析内核的性能问题。
由于图书最终的购入分类是按照中图法的专业分类法对图书进行归类,因此本文进一步分析了不同学科类型中借阅量的占比变化趋势,从年份维度和月份维度上分别对该指标进行统计分析。
2.2 数据集选取
本文所使用的实验数据选自斯坦福大学的SNAP(Stanford Network Analysis Project)数据集中Collaboration net-works的ca-AstroPh(http:∥snap.stanford.edu/data/ca-Astro-Ph.html),以及Social networks的soc-Epinions1(http:∥snap.stanford.edu/data/soc-Epini-ons1.html),数据的顶点具体信息包括数据集的顶点个数、边数以及内存占用情况如表1所示。

表1 实验所选的数据集
2.3 分析工具
性能事件统计的运行平台选为4核8线程Intel(R)Core(TM)i5-7200U CPU,该CPU具有6 MB的三级缓存、2.50 GHz时钟频率、4 GB内存,并运行linux内核4.15.0系统,perf性能分析工具,所有代码均使用Dev-cpp.5.11版本进行编译和运行。
2.4 性能指标定义
分析5种压缩格式的数据对BFS算法的影响。分析的性能和指标参数如下:执行时间(exec.time)、数据移动量(data.mv)、计算量(compute)、每周期指令数(IPC)、各级cache的缺失率(MPKI)、功耗(energy)等指标进行分析比较。
(1)执行时间。任务的执行时间是从开始执行到完成目标任务所占用的时间,单位为ms。不同压缩格式中每条边的执行时间计算公式为
exec.time=tota_exec_time/edges。
(2)数据移动量。受延迟和带宽的限制,同一数据集的不同压缩格式下数据移动量是不同的,分析程序性能指标时数据移动量也是一个重要指标,本文中数据移动量表示不同压缩格式下每条边的数据移动量。计算公式是
data.mv=(load+store)/edges。
for(state[v]=0&&v是s的邻近点)do
compute=(instructions-load-store-branch)/Nedges。
(4)每周期指令数。每周期指令数也称IPC(instruction per clock),是一个基本性能指标,是平均每一时钟周期所执行的指令数,计算公式为
IPC=instructions/cycles。
le=1;
突然间,“奉”的一声,很短促,很古怪。与之同步,几乎分毫不差,整个店堂里火光大盛。峋四爷成了一个火人,一个手舞足蹈、尖声锐叫的火人!
MPKI=(cache_misses*1 000)/instructions。
(6)功耗。功耗是图算法处理数据时的重要衡量性能的指标之一,功耗越小越有利于图计算的发展。功耗的计算公式为
Energy=(power/energy-all)/edges。
(7)皮尔森相关系数(PCC)。皮尔森相关系数(Pearson correlation coefficient,PCC)是一种线性相关系数,是用来反映两个变量线性相关程度的统计量[23]。相关系数用r表示,描述的是两个变量间线性相关强弱的程度,其中n为样本量,r的绝对值越大表明相关性越强。皮尔森相关系数的计算公式为
3 不同压缩格式的内存占用情况及特性化分析
3.1 不同压缩格式内存占用情况
两种不同的数据集在不同压缩格式下的内存占用情况如图6所示。根据图中统计结果:COO压缩格式占用的内存最大,这是因为COO压缩格式是与原始数据最相近的压缩格式,将原始数据的所有边和顶点的信息以最直接的坐标方式,利用3个数组输出,对数据的压缩程度最小,占用内存较大;DCSC压缩格式占用的内存最小,对数据的压缩程度最大,这是因为DCSC输出4个压缩数组,分别是压缩后的非零列、非零列的偏移值、非零列元素值对应的非零行以及非零元素。若是原始数据足够稀疏,则经过DCSC压缩格式输出后的非零列及非零列偏移两个数组都会进行很大程度的压缩,因此DCSC压缩格式输出数据占用的内存比其他4种压缩格式会更小;CSC和CSR两种压缩格式的输出均是包含偏移值、列/行索引值和权值的3个数组,当稀疏矩阵中的行数和列数相近时,两种压缩格式输出的数据占用的内存大小也趋于相近,所以CSR与CSC两种压缩结果较接近,从图中可以看出CSR与CSC两种压缩格式占用内存相对较小,对数据的压缩程度较大;CSCI压缩格式保证每列独立压缩后的数据,包括列号及该列的非零元素个数、非零元素所在的行号以及非零元素的属性值对应存储全部输出,占用内存空间比DCSC、CSC和CSR大。
保持涂料配方体系中聚氨酯丙烯酸酯(B-286c)和三丙二醇二丙烯酸酯(TPGDA)的质量比不变,逐步增加2-甲基-1-(4-甲硫基苯基)-2-吗啉-1-丙酮(907)的用量,配制出一系列紫外光固化涂料。2-甲基-1-(4-甲硫基苯基)-2-吗啉-1-丙酮(907)对涂料固化膜柔韧性、耐冲击性和硬度的影响见表3。

图6 两种数据集五种压缩格式下的内存占用情况(归一化到COO格式)
3.2 不同压缩格式的特性化分析
如图7所示,本文通过雷达图的形式显示了COO、CSC、CSR、DCSC以及CSCI 5种不同压缩格式在BFS算法处理中的性能特性并对其进行分析。雷达图中性能参数包括每个压缩格式实现的ipc、数据移动量、执行时间、功耗以及L1、L2和L3三级数据缓存MPKI。其中,每个指标中度量最大的值为比较标准并视为100%。

图7 两种数据集下五种压缩格式的性能指标
(1)执行时间。两种数据集在不同的压缩格式下每条边的执行时间如表2所示。可以看出CSCI格式的数据边的执行时间最长,而CSC与CSR压缩格式的数据执行的时间最为接近,两者的边的执行时间最短。在数据量足够大并且数据足够稀疏的时候,DCSC压缩格式的执行时间会越来越短;在数据量较小的时候,DCSC对数据的压缩程度不是很大,因此DCSC的执行时间较长。对于遍历类BFS应用而言,在考虑选择边的执行时间时,优先选择CSC压缩格式或者CSR压缩格式作为数据集的输入格式。
采用1982-2010年时间序列数据,分别选用第一产业生产总值、农村固定资产投资、第一产业从业人数和农作物总播种面积,作为上述生产函数中的农业生产总值(Y)、资本投入量(K)、劳动投入量(L)和农业土地投入量(M)。其中,第一产业生产总值以1982年不变价格计算,剔除物价因素的影响。所有数据均来自《安徽统计年鉴》及《中国统计年鉴》中的相关统计指标(表1)。

表2 两种数据集在不同压缩格式下的执行时间
(2)数据移动量。两种数据集在不同压缩格式下每条边的数据移动量如表3所示。对比5种不同的压缩格式,可以发现CSR压缩格式的数据移动量小于其他4种格式,CSC 和CSR的数据移动量接近,数据移动量均偏小。COO、CSCI和DCSC 3种压缩格式的数据移动量相对较大,CSCI压缩格式的数据移动量最大。因此对于遍历类应用而言,在考虑边的数据移动量时,应选择CSR压缩格式作为数据集的输入格式。
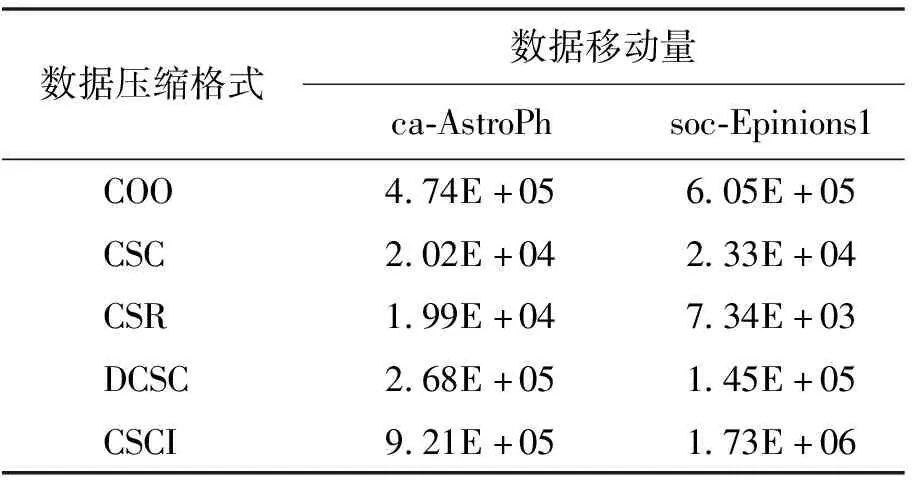
表3 两种数据集在不同压缩格式下每条边的数据移动量
(3)计算量。表4列出了两种数据集在不同压缩格式下每条边的计算量。可以看出CSR与CSC压缩格式的计算量相对较小,其中CSR压缩格式的计算量最小,而COO与CSCI压缩格式的计算操作相对较多,会成为BFS算法处理时的性能阻碍。因此在优先考虑计算量的情况下,遍历类应用BFS应优先选择CSR压缩格式作为数据集的输入结构,可达到性能最优。
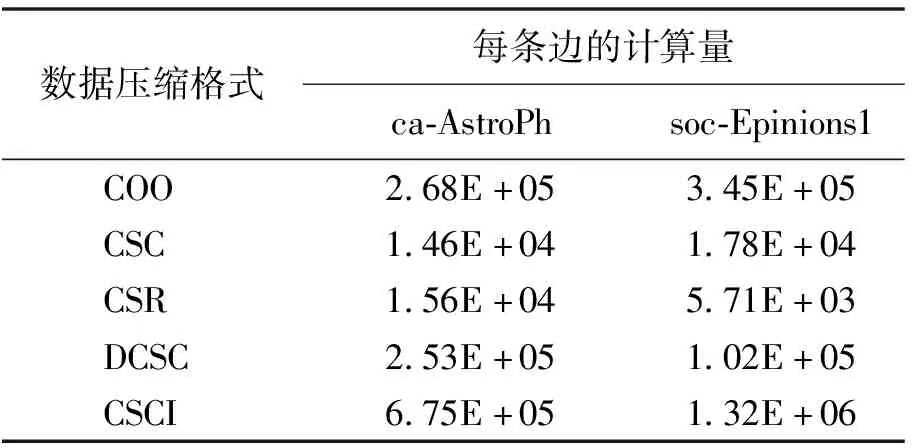
表4 两种数据集在不同压缩格式下每条边的计算量
(4)各级cache的缺失率。两种数据集在5种压缩格式的L1、L2和L3级cacheMPKI分别如表5、表6和表7所示。可以看出,在所有压缩格式下,L1级cacheMPKI整体大于L2级cacheMPKI和L3级cacheMPKI;L2级cacheMPKI平均小于2,L3级cacheMPKI均小于1,综合各级cacheMPKI结果对比分析,可以发现COO压缩格式的缺失率最高,DCSC压缩格式具有更小的各级cacheMPKI,缺失率低可有效减少时间损耗,因此针对有效提高遍历类应用的缓存命中率可以优先选择DCSC压缩格式。
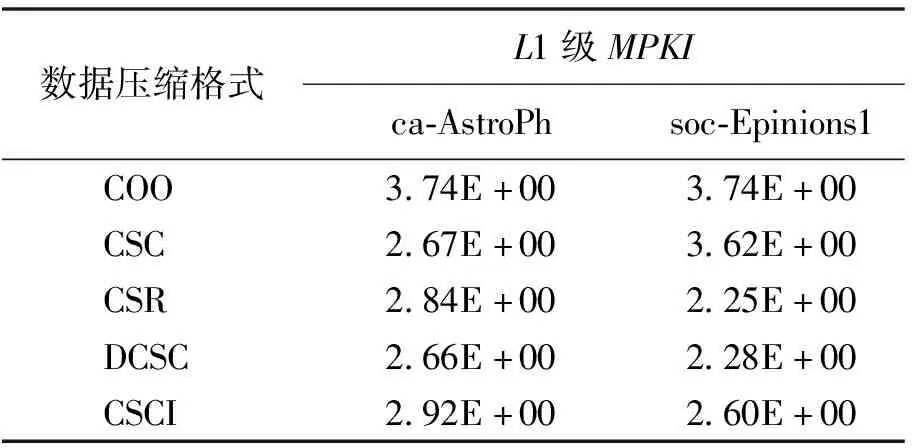
表5 两种数据集在不同压缩格式下L1级cache MPKI

表6 两种数据集在五种压缩格式下L2级cache MPKI

表7 两种数据集在五种压缩格式下L3级cache MPKI
(5)功耗。表8所示的是5种压缩格式的两种数据集在遍历类算法BFS处理时每条边的功耗。可以看出CSR和CSC压缩格式的数据功耗相对较小,其中CSR功耗最小,CSR压缩格式输出3组数据,输出了行偏移值、每一行非零元素对应的列号以及非零元素的属性值,所以在BFS算法搜索时可以快速找到需要搜索定位的活动顶点与活动顶点连接的点,有效降低了功耗。CSCI压缩格式消耗的能量最大。因此对于遍历类应用BFS而言,减少功耗可优先选择CSR压缩格式。
很快就到了检验他们的时候。我和他们商定,月考之后,解忧杂货店就要开展第一次活动。我向他们保证,家委会会提供足够的物力、财力、人力,让他们放心大胆地折腾。他们满心欢喜,个个摩拳擦掌,恨不得马上一试身手。
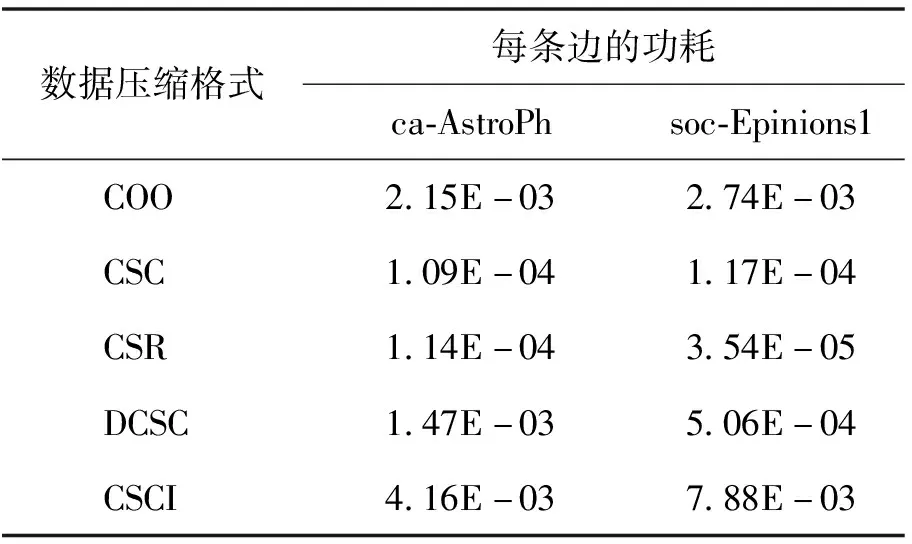
表8 两种数据集在不同压缩格式下每条边的功耗
(6)PCC分析。本文将得到的不同性能指标数据继续进行相关系数(PCC)的相关性分析,分别对性能相关与能量相关进行具体分析,如表9所示。相关系数的取值一般在-1到1之间,若r>0表示正相关,即一个变量随着另一个变量的变化而同方向变化;若r<0则表示负相关,即一个变量随另一个变量从相反方向变化,r的绝对值越大表示相关性越强。可以看到,各级缓存缺失率总体上与性能和功耗呈现正相关,当性能和能量加强时缺失率也加强,并且IPC、exec.time、data.mv、compute、energy指标与性能和能量密切相关。

表9 性能和能量与不同指标的相关性
4 结语
本文通过对两种数据集的五种压缩格式(COO、CSC、CSR、DCSC、CSCI)在BFS算法上的性能分析发现:处理5种不同压缩格式时,应当优先选择CSR和CSC压缩格式,能有效减少算法的执行时间、计算量、数据移动量以及有效减少功耗;当考虑数据结构算法的应用缓存命中率和内存容量时,可优先选择DCSC压缩格式作为BFS的输入格式,可以有效减少内存使用情况并提高命中缓存率。在进行遍历类应用算法时,可以根据不同的应用环境、性能需求和软硬件条件选择不同的压缩格式,进而可以有效地应对实际需求以提高图计算加速器的性能。
