基于属性感知辅助学习的细粒度性格推理
2021-05-24高晓雅王晶晶李寿山
高晓雅,王晶晶,李寿山
(苏州大学 计算机科学与技术学院 江苏 苏州 215006)
0 引言
性格推理任务是对用户自发产生的论述性内容进行分析、处理、归纳和推理性格的过程。随着互联网及社交媒体的迅速发展,用户习惯于在网络平台上发表自己对某事物的观点和评论,而这些观点和评论中往往反映了用户的实时性格倾向,通过捕捉这些性格倾向,可以应用在广泛的场景中,例如,优化推荐系统、AI虚拟人物性格建模、社交媒体分析[1-3]、心理学分析如焦虑症检测和抑郁症检测[4]。因此,性格推理任务得到了来自工业界和学术界越来越多的关注。
传统的性格推理任务集中于分析用户的大五人格体系[1,5-7],即:神经质、外倾性、经验开放性、宜人性、认真性。但是在现实应用场景中,大五人格体系中的性格特征较为抽象且粗粒度,在工业应用角度存在一定的局限性,例如,AI虚拟人物的开发中倾向于设定更细粒度且具体的性格特征,在商业场景下可以表现出“理性”或“善于洞察”的性格倾向,在医疗场景下可以表现出“富于同情心”或“慈爱”的性格倾向等。因此,本文提出了一种新的细粒度性格推理任务,致力于从用户的评论文本中分析用户实时的性格倾向(如浪漫、害羞等)。
首先,仅根据句子级文本来判断用户实时的细粒度性格倾向是本文的挑战之一。现今,性格推理任务方法主要分为机器学习方法和深度学习方法。机器学习方法中,常用的方法有朴素贝叶斯(NB)、支持向量机(SVM)和最大熵(ME),利用TF-IDF等方法构建文本特征后送入模型中训练,得到文本的最终表示用于分类任务[8]。深度学习方法中,常用的方法有卷积神经网络(CNN)、循环神经网络(RNN)和长短期记忆网络(LSTM),通过模型学习文本的上下文信息,将最终的表示用于分类任务[1,5-7]。上述方法均应用于文档级的文本性格推理任务中,没有考虑到句子级短文本场景。
其次,如何在拥有大规模标签的细粒度性格推理任务中区分相似的性格是本文的另一个挑战。例如文本“I feel like this is scared place that I shouldn′t be looking at! It’s beautiful!”(我觉得这是一个我不应该看的神圣的地方! 但很漂亮!)中,词语“scared place”和“shouldn′t be looking at”驱使模型预测为“胆小懦弱”或“害羞”等内向特征性格,但由于细粒度性格标签数量较大,性格之间含义有相似部分,传统的方法很难判断进一步正确的性格是“害羞”,因此,直观上可以引入粗粒度性格属性帮助模型学习细粒度性格之间的差异,“胆小懦弱”性格用粗粒度性格属性标注时,神经质与宜人性的分值同“害羞”性格有显著区别。
本文提出了一个性格属性感知的辅助学习方法(attribute-aware auxiliary learning, AAAL)。具体而言,首先对细粒度性格类别进行归纳标注,将其用多个粗粒度性格属性值表示(神经质、外倾性、经验开放性、宜人性、认真性、情绪正面倾向性)。其次,将细粒度性格推理视为主任务,细粒度性格与粗粒度属性之间的映射视为辅助任务。最后,通过辅助学习机制将该辅助任务和主任务进行联合学习。本文在personality-caption数据集上进行了实验,并和多种基准方法进行了对比,实验结果显示本文提出的AAAL方法在细粒度性格推理任务上相较于其他的基准方法有明显的提升。综上,本文的主要贡献为:1)提出了一种新的细粒度性格推理任务;2)提出了一种性格属性感知的辅助学习方法,以解决细粒度性格推理任务中大规模类别难以预测的问题;3)通过对比实验验证了本文提出的AAAL方法在细粒度性格推理任务中的有效性。
1 相关工作
1.1 性格推理
现今,在NLP领域有很多工作致力于性格推理任务(也称为性格分类任务)。具体来说,Liu等[1]基于字符级循环神经网络方法(Char-RNN),分别对英语、西班牙语和意大利语文本提取字符级特征用于用户的大五人格分析,解决了以往性格推理过程中不同语言文本需要构建不同语言学特征的问题;Zhang等[5]致力于研究推特信息中隐含的用户行为特征与用户性格之间的关系,提出了一个层次长短期记忆网络(HS-LSTM)方法,提取词语级和短句级文本特征用于预测用户的大五人格;Pizzolli等[6]试图对文学作品中不同人物角色的剧情片段及对话进行分析,推理出不同角色的大五人格。Majumder等[7]针对篇章级文本大五人格推理任务,提出了一个层次卷积神经网络(hierarchical CNN),通过使用不同大小的滑动窗口提取篇章级文本中局部相邻词之间的高维度特征。不同于以上的所有研究,本文提出了一种新的细粒度性格推理任务,即根据用户的评论文本推理用户实时的细粒度性格特征。
1.2 多任务学习与辅助学习
多任务学习方法是自然语言处理领域中常用的方法,通过多个相关的任务学习共享表示,目标是提高所有任务的性能。具体而言,高晓雅等[9]提出了一个正逆向情绪分值回归的多任务学习方法,将情绪的三维分值(极性程度、唤醒度和可控度)与最大值相减得到逆向情绪三维分值,通过正逆向情绪分值回归任务的学习得到最终的表示,并用于情绪分值回归。Balikas等[10]提出了一个基于循环神经网络的多任务学习方法,将情绪三元分类(正面、中性和负面)和五元分类(非常正面、正面、中性、负面和非常负面)视为相关任务,通过联合学习解决五元情绪分类问题。与多任务学习不同,辅助学习的目标是提高主任务的性能,辅助任务仅用来帮助主任务的学习。具体而言,Coavoux等[11]为了提升多语言成分句法分析任务的性能,设置了两个有监督的辅助任务,分别是词性和词法标注任务和功能标签预测任务(判断词语与中心词之间的成分关系)。Hu等[12]针对法律文本类别庞大的问题,根据法律文本涉及的具体内容重新设计类别体系(是否发生死亡、是否存在暴力等),通过新类别体系分类辅助任务帮助法律文本分类主任务。
受文献[12]启发,本文提出了性格属性感知的辅助学习方法,但与上述工作不同的是,本文首先通过辅助任务学习细粒度性格与粗粒度属性间的映射关系,其次使用基于排序感知的交叉熵损失函数进一步提升模型性能。据我们所知,本文方法是针对细粒度性格推理任务的首次尝试。
2 性格属性感知的辅助学习方法
本文提出了一种属性感知的辅助学习方法(AAAL),主任务中预测215类细粒度性格类别,辅助任务中学习性格和属性之间的映射关系。本节首先介绍性格属性值标注规范,其次具体描述模型结构,模型结构如图1所示,包含以下三个部分:1)编码层,使用BERT模型将文本词序列映射为词向量;2)属性感知注意力层,通过注意力机制从文本中提取不同属性的相关信息;3)解码层,用于输出主任务和辅助任务的最终结果。
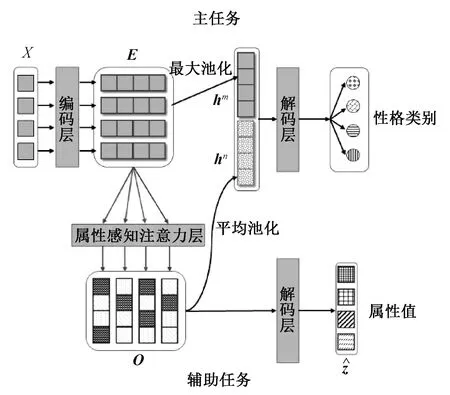
图1 性格属性感知的辅助学习方法模型
2.1 细粒度性格与属性值标注规范
为了解决215类细粒度性格难以预测的问题,本文引入属性信息,将细粒度性格用多个粗粒度属性分值表示,通过辅助任务得到属性感知的文本表示,从而提升细粒度性格推理任务的性能。由于标注规模较小,我们安排了两位标注人员分别对215类细粒度性格进行标注,针对标注不一致的情况,我们安排另一位人员对标注结果进行校对,以确保标注的一致性。
本文使用神经质、外倾性、经验开放性、宜人性、认真性、情绪正面倾向性这六种指标作为性格的粗粒度属性,如表1所示为性格各个属性的具体描述,对任意一个性格,若它是此属性的代表性格,则标记为1.0,若它是此属性的反面性格或者与此属性无明显关联则标记为0.0,例如,性格“焦躁”的属性可标注为[1.0, 0.0, 0.0, 0.0, 0.0, 0.0](属性的顺序同表中相同)。

表1 性格粗粒度属性的描述
2.2 编码层
BERT[13]是目前自然语言处理领域中性能最好的文本编码模型之一,通过对其公布的预训练模型进行微调可以适用于一系列下游的自然语言处理任务(例如文本分类、命名实体识别、阅读理解等)。本文使用BERT-base模型(uncased)作为主任务和辅助任务共同的编码层。给定文本词序列X={x1,x2,…,xn},n是文本长度,首先利用BERT中的深层自注意力变换层,将输入词序列映射为词向量E=[e1,e2,…,en],en∈Rd。其次,将词序列输入到最大池化层(maxpooling)中,在时间维度上进行最大池化操作后,得到文本无属性感知表示hm,E=bert(X),hm=maxpooling(E),hm∈Rd表示文本无属性感知。
2.3 属性感知注意力层
在辅助任务中,给定编码后的词向量E=[e1,e2,…,en],使用注意力机制[14-15]提取词向量中与不同属性相关的信息,
其中:使用满足正态分布的随机向量uk∈Rd初始化表示第k个属性的含义;ak=[ak,1,ak,2,…,ak,n]是第k个属性关于词向量E的权重分布,衡量了词向量E中每个元素ej和当前属性向量uk的相关程度;Wh∈Rd×d是所有属性共享的权重矩阵。
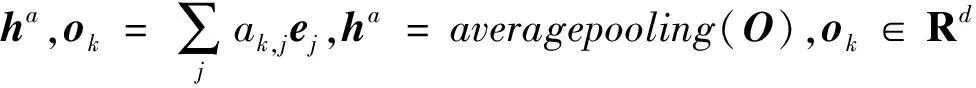
2.4 解码层
在主任务中,将无属性感知表示hm与辅助任务中的属性感知表示ha拼接后通过softmax层输出性格类别的分类概率
p(yri|ri),h=hm⊕ha,p(yri|ri)=softmax(Wmh+bm)n,
其中:yri是ri样本的真实性格类别;Wm∈R215×d和bm∈R215是softmax层的权重和偏置。
在辅助任务中,将所有属性的注意力词向量O=[o1,o2,…,oc]输入到全连接层中,得到每个属性值
其中:Wa∈R1×d和ba是全连接层的权重和偏置值。
2.5 训练与优化策略
本文模型的目标函数由两部分组成,分别是主任务中的排序感知交叉熵损失函数和辅助任务中的均方差损失函数。首先针对细粒度性格类别数量较大的特点,受文献[16]的启发,主任务中使用了排序感知的交叉熵损失函数,在模型训练过程中加重了对置信度最高的非真实性格类别的惩罚,目的在于进一步扩大细粒度性格类别的文本特征空间距离,函数定义为
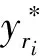
其次,辅助任务的均方差损失函数定义为

最后,将主任务损失函数和辅助任务损失函数相加作为本文方法最终的损失函数,
loss(θ)=loss(θ)main+βloss(θ)aux,
其中:权重β用来调节主任务和辅助任务之间的平衡,本实验中权重β设为1。
3 实验
3.1 数据集与实验设置
本文使用包含215类性格的personality-caption数据集[17]进行实验。此数据集中共包含201 795条样本,每条样本包含一幅图片、对此图片的一句描述以及此描述所呈现的细粒度性格标签。数据集划分了训练集、验证集与测试集,且各子集中性格类别平衡。
本文所研究的是文本细粒度性格推理任务以及解决性格标签数量大导致分类性能不佳的问题,因此只使用数据集中的文本信息。
实验中,文本词向量维度为768,模型中数据批量数为32,随机失活率为0.3,其余各层权重参数由Glorot函数[18]初始化,并在验证过程中进行微调。另外,我们采用学习率为0.000 1的Adam优化器[19]优化主任务中基于排序感知的交叉熵损失函数和辅助任务的均方差损失函数。实验结果采用准确率和F1值作为评价指标。由于数据集内共有215个性格类别,本文统计了TOP-1、TOP-5和TOP-10的准确率及F1值进行更全面地对比,TOP-N表示模型预测某一样本的前N个概率最大的标签中包含样本真实标签,则此样本视为预测正确。
3.2 实验结果
为了验证性格属性感知的辅助学习方法对于大规模性格类别语料任务的有效性,本文对比了几种常见的基于文本信息的性格分类方法以及利用消融实验分析模型各个模块的作用效果。其中,基准方法的文本词向量均使用随机向量初始化。
1)Char-RNN:一个基于RNN模型的性格推理方法,通过学习文本中的字符级特征,使得此模型无须依赖语言,无须创建针对具体语言的语言学特征,可对不同语言文本进行性格推理。
2)HS-LSTM:一个基于LSTM模型的性格推理方法,共有两层,分别是词语级LSTM和短语级LSTM。词语级LSTM中将词语连接为短语送入短语级LSTM中,通过识别文本中的子结构以获得更好的表示,由于短语的开始与结束位置是序列决策问题,最后在模型训练过程中引入强化学习方法实现自动优化选择短语。
3)Doc-LSTM:一个用于文档级情感分类任务的神经网络方法,使用多层双向LSTM模型提取句子级文本表示,再使用门控RNN模型学习得到句子间的内在联系与语义信息[20]。
4)Hierarchical CNN:一个基于层次CNN模型的性格推理方法,分别对当前句子和当前句子所在篇章中的所有词的词向量使用大小分别为3、4、5的滑动窗口进行卷积操作,得到局部相邻词之间的高维度特征后,经过最大池层后拼接,最后输出预测的性格类别。在本文中,用户的评论文本无篇章信息,因此我们仅对当前句子进行编码。
5)BERT:自然语言处理领域中最常用文本编码模型之一,模型在深层注意力变换网络层,通过遮蔽词预测和下一句预测两个自监督学习任务学习文本的表示,用于下游具体的自然语言处理任务。在本实验中,通过加载BERT预训练好的模型进行性格推理任务。
6)AAAL w/o BERT:AAAL模型中不使用BERT作为文本的编码层,使用随机向量初始化后送入双向门控网络(Bi-GRU)学习文本的词向量。
7)AAAL w/o auxiliary task:AAAL模型中不引入辅助任务,在解码层中仅使用主任务得到的无属性感知表示进行215类性格推理。
8)AAAL w/o rank-aware loss:AAAL模型中使用原始的交叉熵损失函数代替基于排序感知的交叉熵损失函数作为主任务的损失函数。
表2展示了性格推理任务中一些不同方法的实验结果(显著性检验p<0.05),通过比较此表中的数据可以发现:

表2 本文提出的方法与其他基准方法的比较
1)大规模数据预训练的BERT模型在性能上明显优于其他基准方法,因此在本文实验中使用BERT模型作为文本的编码层。
2)AAAL模型在性能上明显优于其他基准方法,TOP-1准确率相较于最好的基准方法BERT模型提高了2.31%,TOP-5准确率提高了1.45%,TOP-10准确率提高了0.38%,这验证了AAAL模型的有效性,以及适用于标签类别数量大的细粒度性格推理任务。
分析消融实验的结果可以得出以下结论。
1)本文提出的AAAL模型相较于AAAL w/o auxiliary task方法在性能上有明显的提升,其中,TOP-1准确率提升了0.6%,TOP-5准确率提升了1.04%,TOP-10准确率提升了1.76%。这表明辅助任务能有效地捕捉不同性格中的共有属性特征,并增强了文本的语义表示。
2)本文提出的AAAL模型相较于AAAL w/o BERT方法在性能上有显著的提升,其中,TOP-1准确率提升了2.66%,TOP-5准确率提升了5.81%,TOP-10准确率提升了6.82%。这验证了使用BERT模型作为文本编码层的有效性。
3)本文提出的AAAL模型相较于AAAL w/o rank-aware loss方法在性能上有轻微的提升,其中,TOP-1准确率提升了0.33%,TOP-5准确率提升了0.58%,TOP-10准确率提升了0.64%。这表明了基于排序感知的交叉熵损失函数适用于大规模类别的性格推理任务。
3.3 注意力可视化
为了更好地理解AAAL模型中的属性感知注意力机制,验证其是否能捕捉文本中与属性相关的信息,我们从验证集中挑选了一组样例,对其进行可视化分析。
如图2所示,对注意力权重进行归一化处理后,用不同背景颜色标记,词语的背景颜色越深表示该词语与当前属性的相关程度越高。例如文本“Too hot! I need the sand between my toes now.”(太热了!我现在需要沙子埋住我的脚趾)中,神经质属性与词语“Too hot!”、“need”、“now”的相关程度最大,并且这些词语暗含烦恼焦虑的语义,导致辅助任务中预测神经质属性分值趋向于1.0,最终帮助主任务得到正确的“焦躁”性格结果。

图2 属性感知注意力可视化图
4 结论
本文提出了一种性格属性感知的辅助学习方法,以解决personality-caption数据集中细粒度性格类别数目较大的问题。具体而言,首先对细粒度性格类别进行归纳标注,将其映射到多个粗粒度属性。其次,将细粒度性格推理视为主任务,细粒度性格与粗粒度属性之间的映射视为辅助任务。最后,通过辅助学习机制将该辅助任务和主任务进行联合学习,目的在于利用辅助任务信息提升主任务的细粒度性格推理性能。
在未来的研究工作中,我们将考虑引入常识知识图谱增强文本的语义表示,进一步提升性格推理的性能。其次,将探索其他粗粒度性格体系(例如,霍兰德性格体系将性格划分为社会型、企业型、常规型、现实型、研究型和艺术型)与本文细粒度性格之间的关联,通过增加细粒度性格的属性,提升主任务的性能。最后,我们将致力于personality-caption的多模态性格推理任务,使用模态间的交互信息帮助推理性格。
