基于深度强化学习的汽车自动紧急制动策略*
2021-05-24黄舒伟何少炜金智林
黄舒伟 何少炜 金智林
(南京航空航天大学,机械结构力学及控制国家重点实验室,南京 210016)
主题词:高级驾驶辅助系统 自动紧急制动 深度强化学习 制动安全性 乘坐舒适性
1 前言
汽车自动紧急制动(Automatic Emergency Braking,AEB)系统作为一种新型主动安全技术,可以在驾驶员制动不及时的情况下对车辆进行自动制动,避免碰撞事故的发生。
当前,AEB系统的控制策略一般基于安全距离和安全时间对车辆的碰撞风险进行评估[1-2],其中基于碰撞时间(Time To Collision,TTC)的纵向避撞算法性能较好,使用广泛[3]。兰凤崇等[4]通过构建分层控制实现自动紧急制动,上层控制器基于设定的TTC阈值选取分级制动减速度,下层控制器对制动力进行控制,能够有效避免碰撞,但由于制动减速度为有限的离散值,不能很好地适应变化的工况,且制动过程的加速度波动较大,舒适性较差。刘树伟[5]使用模糊控制策略对制动压力进行控制,使制动减速度变化平缓,在一定程度上提高了制动过程的舒适性。杨为等[6]基于碰撞风险评估与车辆状态设计模糊控制制动策略,输出的制动减速度在一定范围内平稳变化,较定值分级制动策略舒适性更好,但制动减速度的变化范围仍然较小。通过设计制动规则的方式难以实现制动减速度在自动紧急制动过程中的连续变化,故考虑制动减速度的连续变化是AEB 系统制动策略设计中的重要问题。
强化学习是以目标为导向的学习工具,在学习过程中,智能体通过与环境的交互来学习更符合长期回报的策略[7-8]。谷歌团队提出深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法,实现强化学习在连续动作空间决策与控制中的应用[9],随后,越来越多的研究将强化学习应用于智能驾驶技术。其中,徐国艳[10]等在DDPG 算法基础上增大样本空间,进行无人车避障学习,在TORCS 平台进行避障效果仿真。Zhu[11]和Zhou[12]运用深度强化学习构建自动驾驶跟车系统,提高了智能车在交叉路口的行驶效率、燃油经济性和安全性。An[13]提出结合深度强化学习和车辆通信的变道系统,在不需要车辆动力学模型的情况下实现了直线驾驶和避撞动作的学习。
本文将深度强化学习应用在自动紧急制动系统制动策略的设计中,得到的制动策略可以根据车辆安全状态的改变实时调整期望制动加速度,实现对制动过程的更精细控制,提高乘坐舒适性。
2 AEB系统结构及动力学模型
本文构建的AEB仿真系统结构如图1所示,系统由强化学习制动决策模块、制动执行模块、主车动力学模型、前车运动学模型和奖励函数5个部分组成。强化学习制动决策模块基于两车信息和奖励函数输出的奖励值进行制动策略学习,输出期望减速度,经制动执行模块转化为制动力作用于主车动力学模型,实现车辆自动紧急制动。
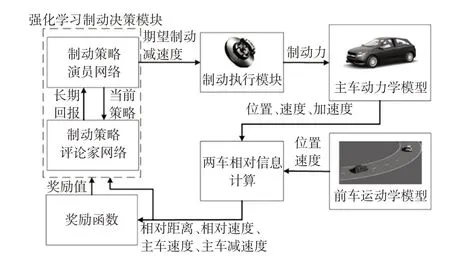
图1 AEB仿真系统结构
为了降低动力学模型的复杂度,且不影响模型准确性,作出如下假设:以前轮转角作为模型的输入;将车辆简化为单轨模型;忽略车辆侧倾、垂向和俯仰运动。
将动力学模型简化为具有纵向、侧向和横摆运动的3自由度模型,如图2所示,动力学方程为:
式中,m为车辆质量;vx、vy分别为车辆纵向与横向速度;Fxf、Fxr分别为前、后轮切向力;Fyf=k1α1、Fyr=k2α2分别为前、后轮横向力;k1、k2分别为前、后轮侧偏刚度;α1、α2分别为前、后轮侧偏角;δ为前轮转角;Iz为车辆绕z轴的转动惯量;ω为车辆横摆角速度;lf、lr分别为质心与前、后轴的距离。
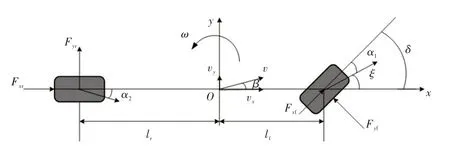
图2 3自由度动力学模型
α1、α2与车辆运动参数有关:
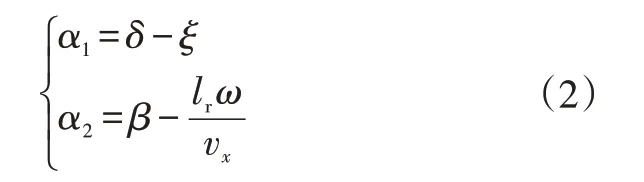
式中,β=vx/vy为质心侧偏角;ξ=β+lfω/vy为前轮速度与x轴的夹角。
车辆在紧急制动过程中发动机不提供扭矩,动力学模型的输入变量为制动力,则前、后轮纵向力为:
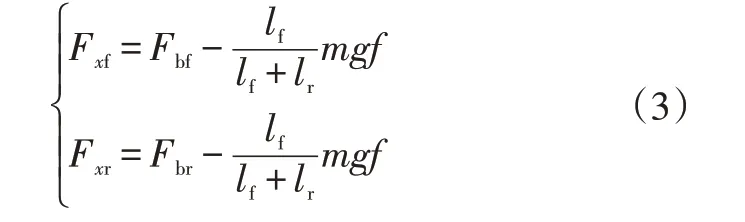
式中,Fbf、Fbr分别为前、后轮制动力;g为重力加速度;f为滚动阻力系数。
制动执行机构进行期望制动力的分配,前、后车轮制动力分别为:

式中,aμ为期望制动减速度。
3 制动策略
3.1 状态量及动作量设计
为了设计和验证自动紧急制动策略,使用MATLAB的驾驶场景设计器(Driving Scenario Designer)构建AEB仿真场景,在Simulink中搭建强化学习自动紧急制动策略,感知模块选用Simulink环境提供的标准信息,如图3所示,感知的状态量包括主车速度ve、主车加速度ae、主车与前车的相对距离dr和相对速度vr,其中:

式中,vf为前车速度。
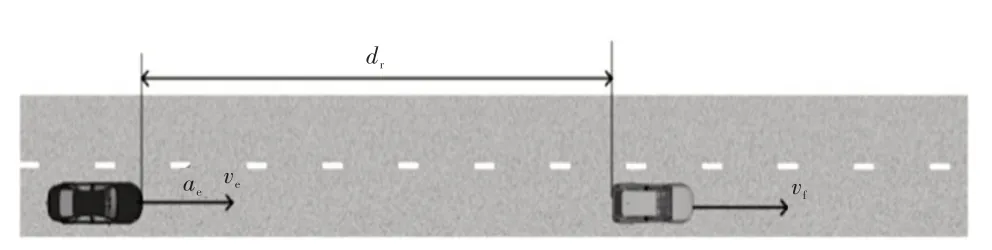
图3 AEB测试场景示意
状态量可表示为:

制动决策模块根据状态量St和当前学习到的制动策略μAEB,决定输出期望制动减速度aμ,减速度被限制在0~9 m/s2范围内,动作量可表示为:

3.2 奖励函数
奖励函数决定了制动决策模块的制动策略。奖励计算模块根据每一时刻的状态量计算奖励值输出至决策模块,引导决策模块学习规则制定者需要的制动策略。奖励函数为:
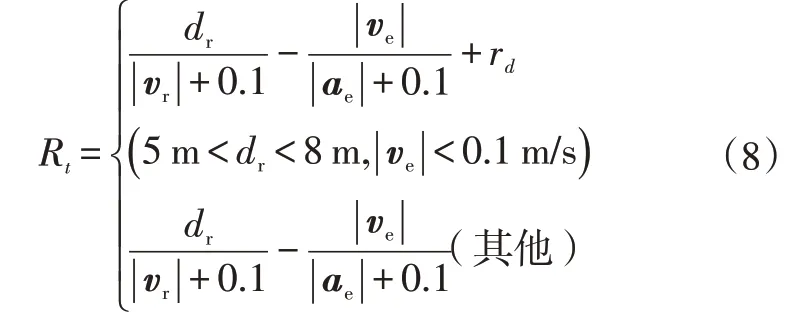
式中,rd为主车制动至停止时与前车距离的奖励值。
奖励函数计算了当前时刻碰撞时间与主车以当前减速度制动停止时间的差值,为防止出现分母为0,奖励值趋于无穷大的情况,统一在分母中加0.1。初始条件下,主车速度大于前车速度,且制动减速度较小,该部分奖励值为负,随着制动减速度的增大,主车速度下降,该部分奖励值逐渐增大,当主车速度降至小于前车速度后,该部分奖励值仍随主车速度的下降而增大,引导制动策略使主车制动至停止。若主车在距离前车5~8 m的区间内停止,则附加高额的奖励值rd。经试验,取rd=200可以使制动策略在该区间内使车辆制动至停止。
3.3 强化学习算法
为在连续动作空间输出期望制动加速度,强化学习算法选用深度确定性策略梯度DDPG算法。DDPG算法在演员评论家(Actor-Critic)网络框架的基础上,基于深度Q 网络的经验回放和目标网络结构对确定性策略梯度算法进行了改进[14]。
自动紧急制动策略强化学习算法如图4 所示。在每个仿真时刻,演员网络依据当前状态St输出动作量At到AEB 仿真环境,同时演员网络与评论家网络进行参数的迭代更新。演员网络与评论家网络都包含独立的评估网络与目标网络,以解决单一神经网络的训练过程不稳定问题。演员网络与评论家网络分别表征制动策略与制动价值函数。制动策略依据制动状态输出期望制动减速度aμ,制动价值函数计算出给定状态及采取的制动动作下的长期回报。在演员网络和评论家网络更新的过程中,首先计算提取出每份经验预估回报Uk:

式中,Sk、Sk+1、Rk分别为提取的第k组经验的初始状态、下一时刻状态和奖励;λ为折损系数,代表制动策略学习过程中长期价值所占的比重;Q′AEB为目标网络制动状态价值函数;μ′AEB为目标网络制动策略。
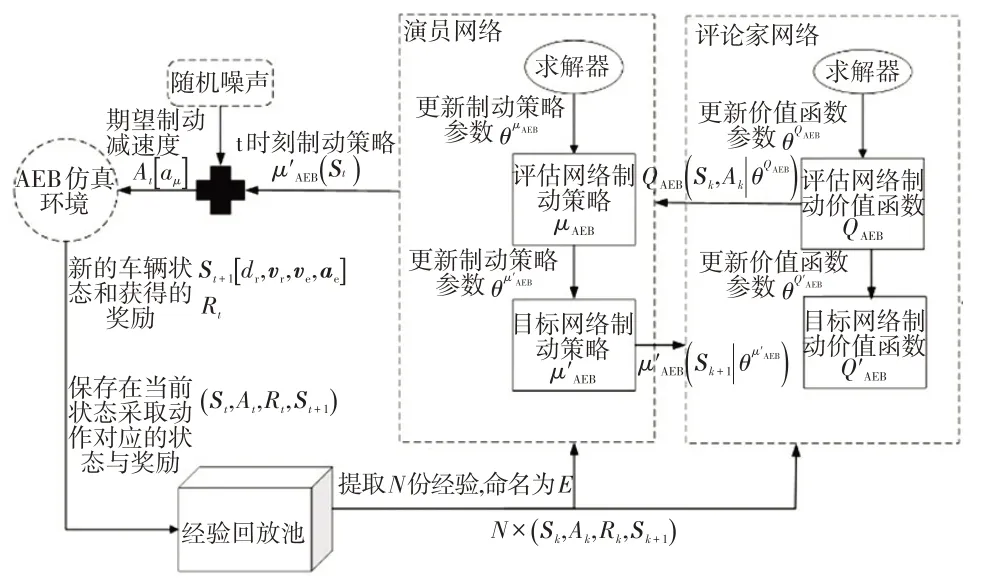
图4 自动紧急制动策略强化学习算法
随后,评论家网络的求解器使用式(10)计算制动价值函数与预估回报的偏差L,并运用梯度下降算法朝着偏差L减小的方向更新评估网络制动价值函数的参数:

式中,QAEB为网络制动价值评估函数;N为提取经验的份数;E为从经验回放池中提取出的多组用于训练的状态量与对应奖励的集合。
演员网络的求解器使用式(11)计算平均长期回报qa,并运用梯度下降算法朝着qa梯度下降最快方向更新评估网络制动策略参数:
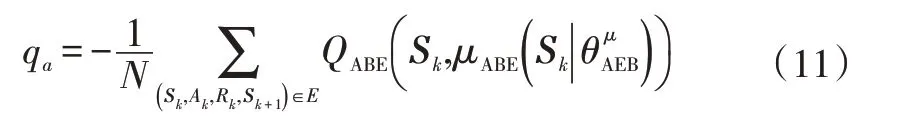
目标网络的参数值则是在完成了一个最小数据集的训练后,使用缓慢更新(Soft Update)算法进行更新:
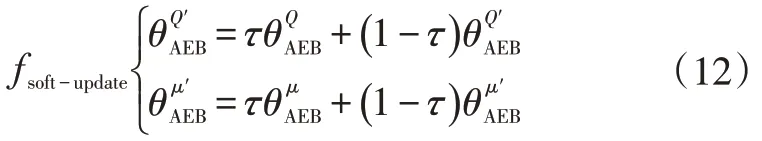
3.4 神经网络结构
激活函数选用线性整流(Rectified Linear Unit,ReLU)激活函数与双曲正切激活函数:

评论家网络的结构如图5 所示,具有2 个输入与1个输出。演员网络结构如图6所示,为单输入单输出的神经网络,用以表达制动策略。选用Adam求解器进行优化求解,强化学习的训练参数如表1所示。
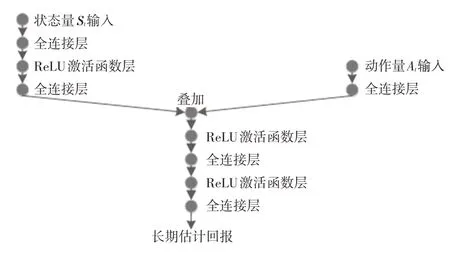
图5 评论家网络结构
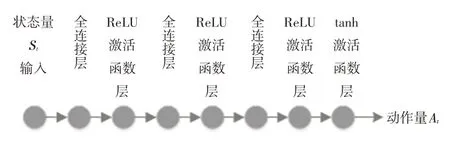
图6 演员网络结构
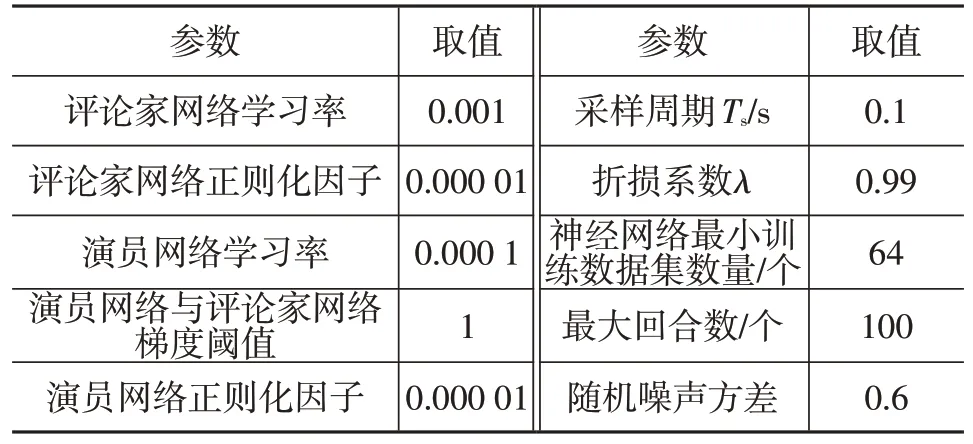
表1 训练参数
4 实例仿真分析
为验证自动紧急制动策略的控制效果,参考中国新车评价规程(C-NCAP)测试规则[15],通过改变两车的初始位置、初速度和初始制动减速度,设计了前车静止、前车慢行、前车减速3种直线工况。主车动力学模型参数如表2所示。
参考文献[4]中的分级制动策略,设计传统分级制动AEB制动策略与强化学习AEB制动策略的对比测试方案。碰撞时间tTTC、制动预警时间tfcw和各级制动时间tbn的计算公式为:
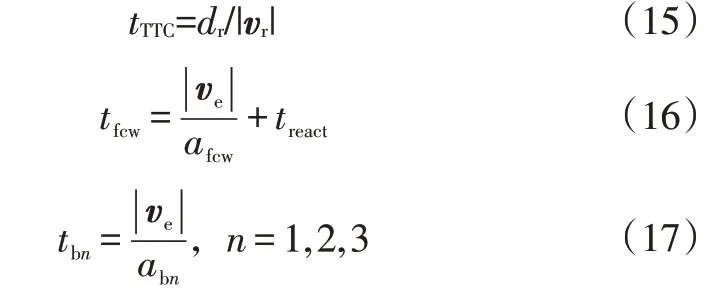
式中,afcw=4 m/s2为驾驶员制动预警减速度;treact=1.2 s 为驾驶员反应时间;ab1=3.8 m/s2、ab2=5.3 m/s2、ab3=9.8 m/s2分别为第1级、第2级、第3级制动减速度。

表2 车辆参数
tb1<tTTC≤tfcw时,传统AEB制动策略开始介入,采取第1 级制动减速度ab1;tb2<tTTC≤tb1时,传统AEB 制动策略采用第2 级制动减速度ab2;tTTC≤tb2时,传统AEB 制动策略采用第3级制动减速度ab3。
4.1 直线行驶工况
直线行驶前车静止工况两车初始距离为24 m,前车静止,主车以30 km/h 速度行驶。实例仿真得到强化学习各回合奖励如图7 所示,初始学习阶段,制动策略的奖励经历了振荡下降,10 个回合后,奖励大幅上升,并稳定在0 附近,制动决策模块获得奖励较高的策略,且实现收敛。
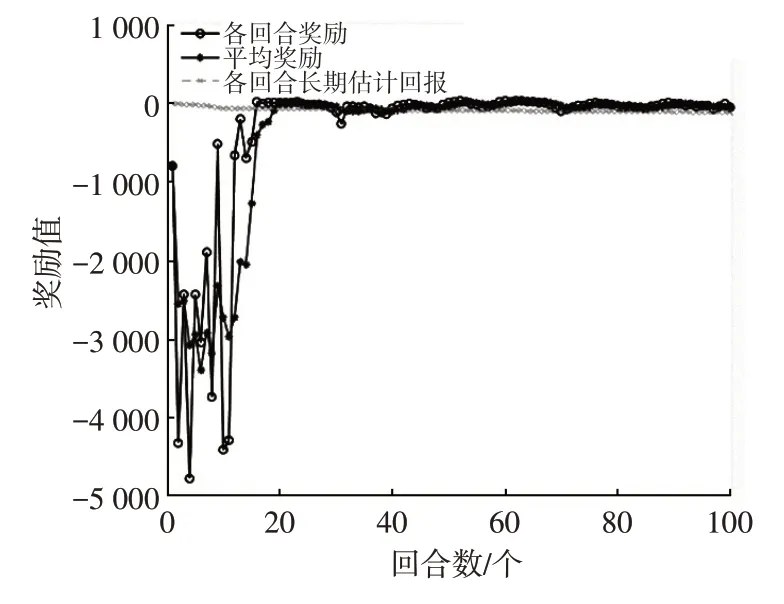
图7 前车静止工况强化学习奖励
图8所示为前车静止工况的主车制动减速度、两车相对距离及相对速度仿真结果。从图8中可以看出,前车静止时,强化学习AEB 与传统AEB 系统都能有效制动,车辆停止时与前车的距离都在8 m左右。传统AEB制动策略在tTTC<tfcw后开始介入,采用第1级制动减速度制动至车辆停止。强化学习AEB系统的制动策略是使用较小的制动力长时间制动,保持一定的制动减速度,车速变化均匀,具有更好的舒适性。
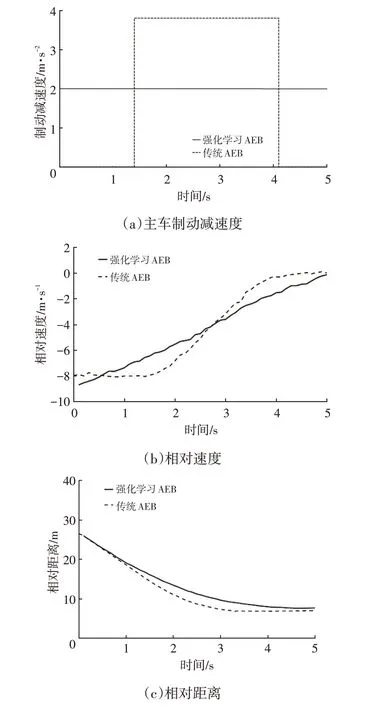
图8 直道行驶前车静止工况仿真结果
直道行驶前车慢行工况下,两车初始距离15 m,前车以20 km/h 速度行驶,主车以30 km/h 速度行驶,仿真结果如图9所示。由图9a可见,由于存在噪声引起的随机性探索,学习过程的奖励存在一定波动,但总体上策略收敛。传统分级制动AEB 系统在2 s后才开始制动,两车最小距离小于5 m,而强化学习AEB系统在两车相距较远时即以小制动减速度进行制动,随着两车距离的减小,制动减速度逐渐增大,保持两车相对距离大于7.5 m,将两车最小距离控制在更安全的范围内,并且制动减速度的增长是连续的,速度的变化也更平缓,制动过程舒适性更好。强化学习AEB系统的制动减速度在最初2 s 出现了小幅振荡,这是制动策略学习过程中加入的随机噪声带来的随机性探索造成的。若想减小振荡,可以减小随机噪声方差或在奖励函数中加入对制动减速度变化率的惩罚项。
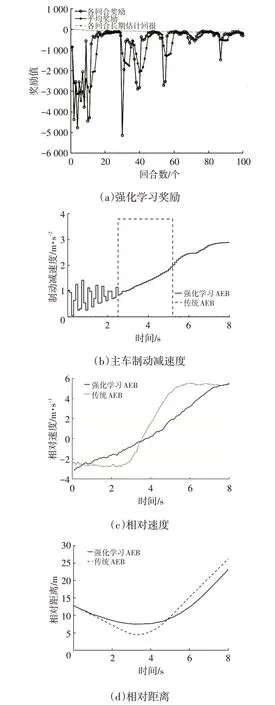
图9 直道行驶前车慢行工况仿真结果
直道行驶前车减速工况下,两车初始距离为40 m,主车与前车初速度均为50 km/h,前车以4 m/s2的减速度制动至停止结束,仿真结果如图10所示。由图10可知:制动策略实现了收敛;强化学习AEB和传统AEB系统都能使主车完全停止,保持两车5 m 以上安全距离;强化学习AEB 系统的制动减速度更小,但制动持续时间长,速度的变化更为平缓。仿真结果表明,强化学习AEB 系统满足C-NCAP 测试标准要求,同时兼顾了舒适性。
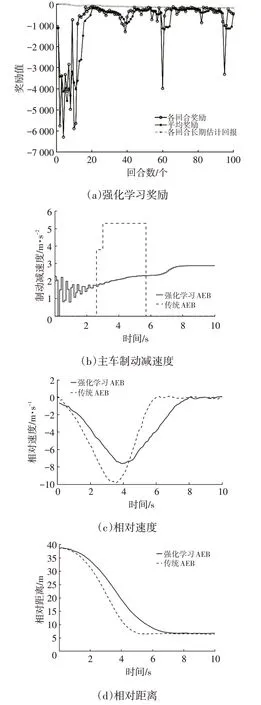
图10 直道行驶前车减速工况仿真结果
4.2 弯道工况
研究中,考虑车辆的侧向运动与横摆运动,以实现弯道自动紧急制动功能。在弯道工况中,设计前车静止与前车慢行2种工况进行仿真。前车静止工况中,主车在半径40 m的定曲率弧形道路上以恒定的前轮转角行驶,主车速度30 km/h,前车静止,两车初始距离25 m。前车慢行工况中,前车以20 km/h 的速度沿弧形道路匀速行驶,主车初速度为30 km/h,两车初始距离15 m。
在弯道行驶前车静止工况中,主车保持2 m/s2的制动减速度持续制动至停车,主车与前车保持了7.5 m 的距离。两车相对速度与相对距离如图11所示。
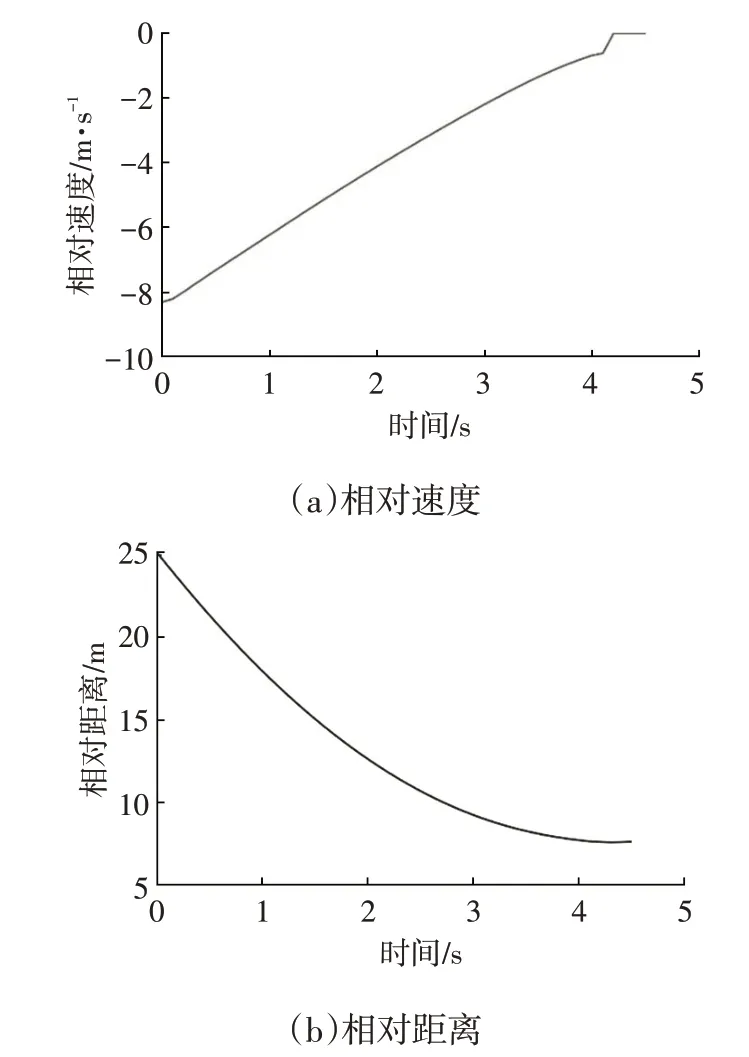
图11 弯道行驶前车静止工况仿真结果
弯道行驶前车慢行工况仿真结果如图12所示。在整个制动过程中,制动减速度控制在2 m/s2以下,速度变化平缓。制动减速度随着两车距离的减小逐渐增大,在主车速度降至前车速度以下后,强化学习AEB 系统减小了制动减速度将车辆制动至停止,两车的最小距离为8.7 m,保证了安全性。在这两种工况下,强化学习制动策略都实现了收敛。

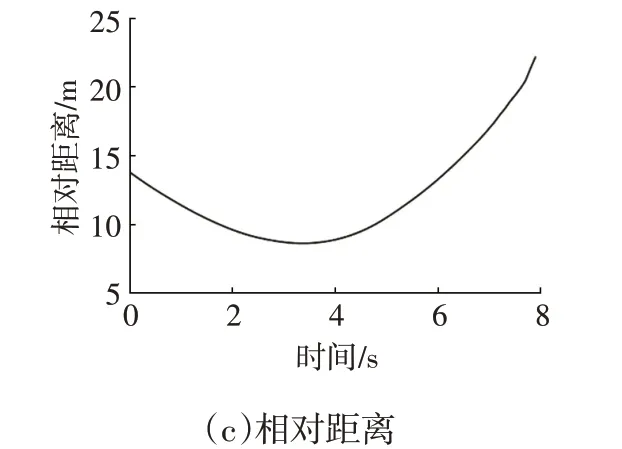
图12 弯道行驶前车慢行工况仿真结果
5 结束语
本文应用深度强化学习算法设计了适用于车辆3自由度动力学模型的自动紧急制动策略,得到的强化学习自动紧急制动策略满足C-NCAP 自动紧急制动测试标准,在弯道制动工况也能有效制动,且收敛性好,改善了制动过程乘坐舒适性。在后续研究中还需针对制动加速度的小幅振荡问题、奖励函数形式以及神经网络结构加以改进,力求得到更符合人类驾驶员习惯的制动策略。
