基于改进YOLO算法的多目标铁谱磨粒智能识别
2021-05-21张子杨魏海军贾风光
张子杨 魏海军 刘 竑 贾风光
(1.上海海事大学商船学院 上海 201306;2.山东交通学院船舶与轮机工程学院 山东济南 264209)
大量研究数据表明,机械设备的故障多数是由于磨损引起的。铁谱诊断技术,通过提取机械系统中的润滑油,分离出其中携带的磨损颗粒(磨粒),再对磨粒的尺寸、形态、颜色、粒度分布和磨粒浓度进行分析,即可以判断出设备的磨损状态、故障原因和位置[1-2]。但传统的铁谱磨粒图像分析,严重依赖人工经验,耗费大量时间,且分析结果主观[3-4]。
一些学者在磨粒图像的智能识别方面进行了研究。陈果和左洪福[5]运用C-均值有效实现了8种磨粒的聚类,但仅对少量磨粒图像样本进行了参数提取,且颜色、形状因子、尺寸等参数仍是人工测量。WANG等[6]使用蚁群算法提取磨粒边缘,对彩色图像的适应性较高,但需要进行人工阈值的选取预处理,不能达到智能化分割。安超等人[7]利用Inception-v3神经网络对严重滑动和疲劳剥块进行了有效分类,但由于类别较少,且是单目标磨粒数据集,不具有代表性。可见,以往的磨粒识别研究仍需要人工参数的测量与选取,且针对的多是背景简单的单目标磨粒,没有实现智能化。复杂背景下的多目标磨粒识别仍存在技术瓶颈。
近年来,卷积神经网络(Convolution Neural Network,CNN)结合深度学习在世界计算机图像识别挑战赛中屡次夺冠,在目标检测方面,表现日益良好[8]。深度学习的检测方法主要分为两大类,一类是两阶段检测,以RCNN(Regions with CNN)系列为代表,主要包括RCNN[9]、Fast RCNN[10]、Faster RCNN[11]等;另一类是单阶段检测,以YOLO(You Only Look Once)家族为代表,主要包括SSD[12](Single Shot MultiBox Detector)、YOLO[13]、YOLOv2[14]、YOLOv3[15]等。前者虽然有较高的检测精度,但网络繁冗,耗费较长的检测时间;后者计算参数少,检测速度快,但在重叠目标和小目标的检测上精度较差。目前,YOLOv3较好维持了检测速度与准确率的平衡。基于此,本文作者引入YOLOv3框架完成了铁谱磨粒的检测,并针对磨粒检测过程中特征尺度多变、过度下采样、模型计算量的增加等具体问题提出改进方案。
1 YOLO算法原理
YOLO将一幅图像分成S×S个网格单元,如果某个目标的中心落在这个网格中,则这个网格就负责预测这个目标。每个网格要预测B个边界框,每个边界框要回归其自身坐标及尺寸(x,y,w,h)和预测一个置信度值,置信度定义为式(1)。
(1)
这个置信度包含2个信息:一是边界框中含有目标的置信度,二是边界框的准确度。若网格中有目标则Pr(Object)=1,没有目标则Pr(Object)=0。另外,每个网格还要预测一个类别信息,记为C,概率记为Pr(Classi)。每个边界框的特定类别置信度采用条件概率计算,定义为式(2)。
(2)
最后得到S×S×(B×5+C)列的输出张量,通过设置阈值过滤低分的边界框,并对保留的边界框进行非极大值抑制(Non-Maximum Suppression,NMS)[16]处理,去掉重叠的边界框后得到最终的检测结果,完成目标的检测。
2 YOLO算法的改进
2.1 空间金字塔池化模块
磨粒的采集环境处于微米级光学显微镜下,而且受到背景、曝光、焦距等一系列因素影响,同一类型、甚至同一个磨粒,在不同的磨粒图片中会呈现出不同尺寸的形状特征。CNN网络提取到大量尺寸不一致的同一类别磨粒特征,必然会造成网络的震荡,难以收敛,影响模型训练效果。
空间金字塔池化(Spatial Pyramid Pooling,SPP)本是SPPNet[17]提出用来解决全连接层固定输出的问题。全连接层作为CNN网络中的分类器,需要将卷积层学到的分布式特征映射到样本标记空间,固定特征图尺寸。SPPNet在全连接层之前加入空间金字塔池化层,对任意尺寸的输入特征图,通过不同的池化结构提取特征并连接,生成固定大小的特征图送入全连接层。
文中借用其思想,引入空间金字塔池化模块(SPP Module)。通过对不同尺度的磨粒特征使用多个卷积核进行最大池化(Max pool),再将池化后的特征图维度扩充(concatenate),最终得到新的特征图组合,以达到多尺度特征提取统一大小的特征向量,解决磨粒尺寸的特征不一致,并在之后增加三层卷积,丰富特征图的语义信息,最后送入yolo检测层。SPP Module结构示意图如图 1所示。
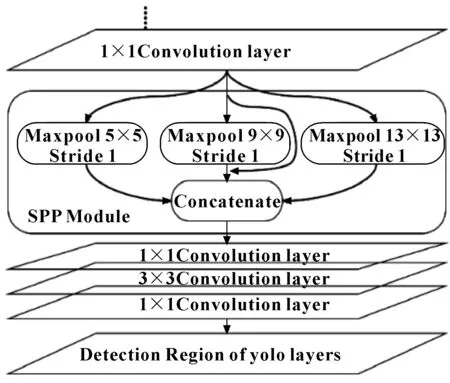
图 1 Yolo SPP Module结构示意
2.2 Yolo层拓展
随着CNN网络深度的加深,特征提取的能力也随之得到增强,这对相似磨粒的识别大有裨益,但过多的下采样层会导致密集磨粒和小颗粒磨粒特征消失,网络学习不到正确的特征,降低检测率,甚至导致错检、漏检。为此,文中提出2种解决方案,并进行了实验效果对比。
(1)大尺度yolo层检测(yolov3_mod)。原始yolov3中通过下采样送入yolo检测层的尺寸分别为13×13、26×26、52×52,对此文中拟采取增大第三yolo层检测的输入尺寸,同时保留前两层尺寸以确保网络的深度,不降低网络对相似磨粒的特征学习能力。具体做法是,增加97层网络的上采样(upsample)步伐(stride),提高特征图尺寸,再与11层浅层网络的特征图张量连接(concat),最后得到一个较大尺寸(104×104)的yolo检测层。
(2)全尺度yolo层检测(yolov3_5l)。考虑到各磨粒尺寸的大量不一致性,3层yolo层检测学习能力有限,对目标重叠、密集磨粒检测能力不强,故拟在第3个yolo层后,追加2个大尺寸(104×104,208×208)检测的yolo层,将原始的3个yolo层增加至5层,以达到全尺度特征图的覆盖。具体做法是,在102层卷积输出后,通过route连接到上取样层,再与11层网络张量连接送入第4层yolo检测,并将其后的121层网络与第4层网络张量连接送入第5层yolo检测,完成全尺度yolo层检测。改进的yolo模型结构如图 2所示。
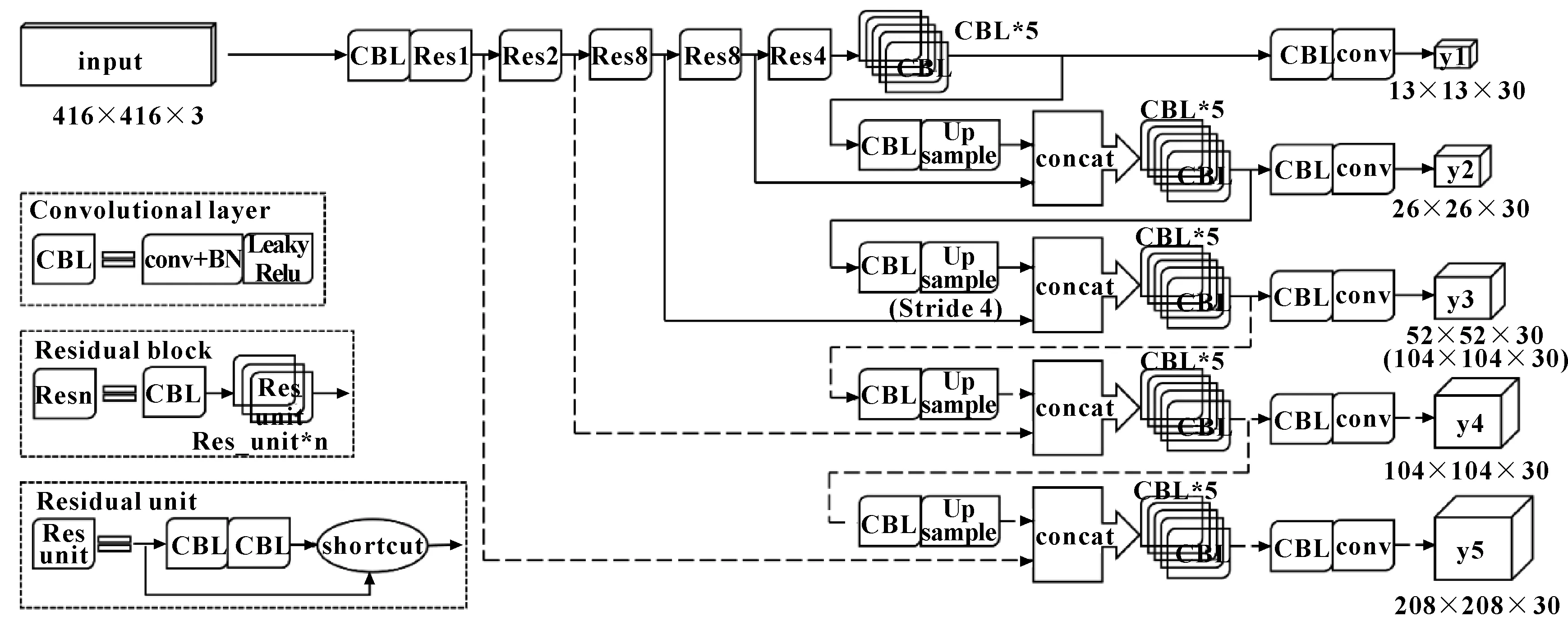
图 2 改进的yolo模型结构
2.3 卷积层与BN层的融合
YOLOv3通过批量归一化(Batch Normalization,BN)[18]将每层网络的输入归一化,使其分布在一定的均值与方差范围内,有效解决了CNN训练过程中梯度消失和梯度爆炸的问题,提高了网络模型稳定性,但BN层同时也增加了CNN网络中的层数,加大了网络前向推断的计算量,影响了网络模型的综合性能。
假设在一个Batch内的第i个样本内,神经元的输出为yi,则卷积层和BN层的输出可表示为式(3)与式(4)。
(3)
(4)
式(3)中:w表示权重;x表示输入神经元;b表示偏置。式(4)中:μ和σ2分别代表均值与方差;ζ代表一个很小的正数;γ和β为可学习的系数。
由于在推理过程中,BN层参数除卷积层的输入外,其余固定不变,故可将式(4)变形为式(5)。
BNi=ayi+c
(5)
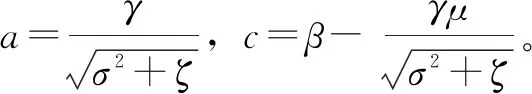
从式(3)和式(5)可以看出,卷积层和BN层的运算都是线性计算,将BN融入卷积层不会产生任何误差和偏移,融合后的卷积层输出如式(6)所示。
(6)
卷积层与BN层的融合过程如图 3所示。
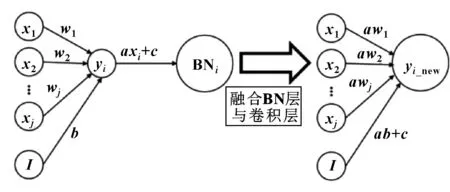
图3 Conv层与BN层融合示意
3 实验与结果分析
3.1 磨粒数据集及预处理
利用Bruker的UMT摩擦磨损试验机制作各种磨损颗粒。设备如图 4所示。环境温度为22 ℃,相对湿度为50%。盘销实验中,上销为标准416不锈钢圆柱,圆盘为合金钢E52100,润滑剂为Mobile Gard 412润滑油,在294 N的载荷下以900 r/min的速度持续25 h。盘销实验主要用于生成严重滑动和切削磨粒。四球实验中,球的材料是GCr15(硬度63HRC),最大负载和速度设置为900 N和300 r/min,实验时间为50 h。四球实验主要用于产生疲劳磨损颗粒,包括球形磨粒、疲劳剥块和层状磨粒。

图4 实验设备
将制得的磨粒通过铁谱制谱仪制成谱片,再利用显微镜观察仪拍摄得到原始磨粒图片。由于实验所用光学显微镜拍摄的图片尺寸为2 568×1 912,分辨率太高,故对这些原始磨粒图片进行旋转、剪裁,并利用OpenCV进行数据增广后,得到4 920张416×416的磨粒图片,随机选出3 936为训练集,984为测试集。最后利用标注工具对这些磨粒图片进行标注、分类,整理成VOC数据集格式。最终得到5类磨粒数据集,分别是球形磨粒(spherical),切削磨粒(cutting),疲劳剥块(chunky),层状磨粒(laminar),严重滑动磨粒(sliding),其中球形和切削磨粒多呈现小颗粒,疲劳、层状和严重滑动磨粒为相似磨粒类型。各类别典型磨粒如图 5所示。

图5 磨粒数据集
YOLOv3采用K-means[19]算法对数据集进行先验框维度聚类,以加速模型收敛。但由于原始yolov3模型使用的VOC和COCO数据集分类众多,且实例尺寸较大,不适用自制的磨粒数据集。实验前,将磨粒数据集重新聚类,得到符合磨粒数据集特点的先验框数据,分别为(28,74)(31,41)(40,48)(50,86)(58,60)(70,152)(78,92)(127,164)(214,262)和(24,41)(26,81)(33,42)(39,30)(39,52)(40,76)(49,44)(53,88)(58,60)(68,152)(74,87)(94,110)(114,158)(152,170)(215,262)。
3.2 训练及结果分析
训练环境:CPU为Intel(R) Xeon(R) CPU E5410@2.33 GHz,显卡Tesla k80,内存16 G,Ubuntu18.04操作系统,CUDA10.1,cudnn7.6.2。
在目标检测中,总平均准确率(mAP)[20]是目标检测模型最重要的评价指标。True positives(TP)表示正样本被正确识别的数量,False positives(FP) 表示负样本被识别为正样本的数量,False negatives(FN)表示正样本被识别为负样本的数量。准确率(Precision)即为在测试集样本中TP所占的比率,召回率(Recall)表示是在测试集样本中,所有正样本被正确识别为正样本的比例。准确率与召回率如式(7)和式(8)所示。
(7)
(8)
平均精确率(Average Precision,AP),即各类样本的准确率均值,可以由Precision-Recall (PR)曲线所围成的面积表示,对各类的AP求平均值即为目标检测模型的总平均准确率(mAP)。
在完成yolo模型训练后,进行测试集上的精确度验证,得到各类磨粒检测的准确率和召回率,将结果绘制成PR曲线图,如图 6所示。
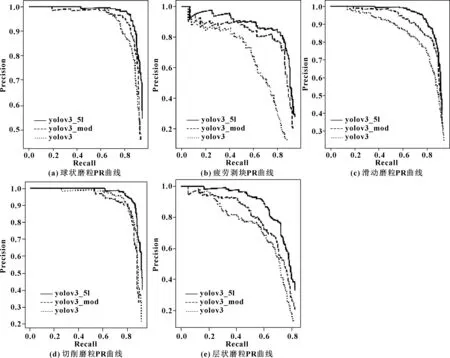
图6 磨粒PR曲线
从图 6可以看出,原始的yolov3模型对于形态和颜色特征明显的球形磨粒和切削磨粒的识别率较高,但对严重滑动、层状磨粒和疲劳剥块等相似磨粒的识别率较低。改进后的yolov3_mod模型和yolov3_5l模型有效提高了相似磨粒的识别率。
各模型的准确率和检测速度如表 1所示。表2展示了2种改进模型融合操作前后的平均推理时间。
表1显示yolov3_mod和yolov3_5l两模型对相似磨粒的识别率分别提高了8%和14%,mAP提高了5%和10%,充分证明了改进yolo模型的有效性。表2显示改进后的两模型较融合前,推理时间提升8%左右,表明模型融合操作,降低了网络计算量,加速了模型检测。
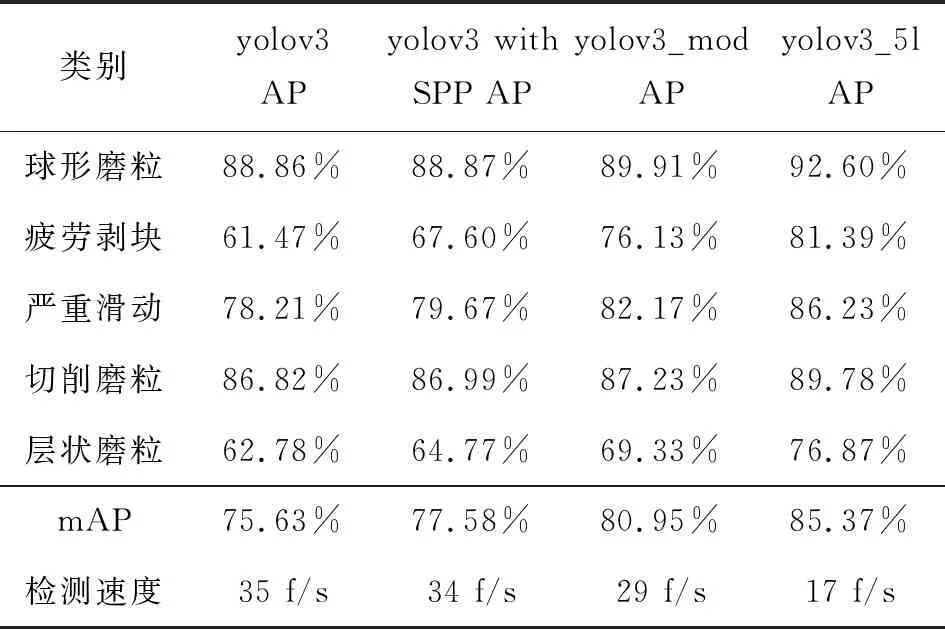
表 1 各模型检测结果
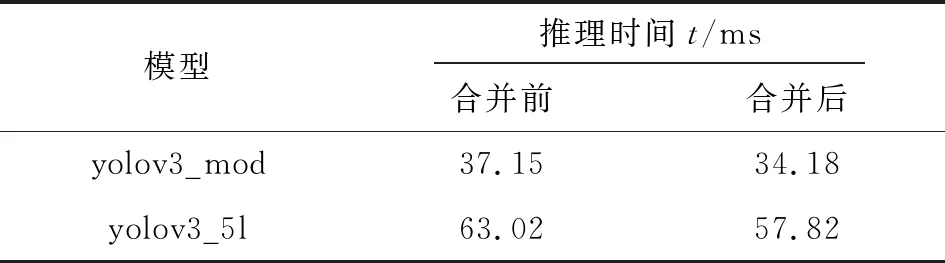
表2 模型融合前后推理时间
图7—9展示了各yolo模型在测试集中的部分可视化检测结果。可以看出,原始yolov3模型对密集磨粒和小目标磨粒的漏检较多,对相似磨粒的错检率也较高。如图7(a)、(b)显示,原始yolov3模型分别漏检了一个切削磨粒(cutting)和层状磨粒(laminar),而在图7(c)中,至少漏检了8个球形磨粒(spherical),且将2个球形磨粒错检为疲劳剥块(chunky)。

图7 Yolov3检测结果

图8 Yolov3_mod检测结果

图9 Yolov3_5l检测结果
改进后的yolo模型有效地检测出了密集磨粒和小颗粒磨粒。如在图8(b)中,yolov3_mod模型正确识别出所有层状磨粒(laminar),图8(c)中仅漏检了2个球形磨粒(spherical)。又如,在图9(a)中,yolov3_5l模型识别出所有切削磨粒(cutting),图9(c)则正确检测出了所有球形磨粒(spherical)。
另外,对比同一被正确识别出的磨粒,不难发现,改进后的yolo模型所预测的边界框,相比原始yolov3模型更贴近真实的磨粒边界,说明改进后的yolo模型不仅提高了相似磨粒的检测效果,而且定位更加精确。
4 结论
(1)基于YOLO算法提出了yolov3_mod和yolov3_5l两种改进模型,有效提高了相似磨粒的识别率,降低了小颗粒磨粒的漏检率,且磨粒的定位更加精确,基本实现了复杂背景下多目标磨粒的识别。
(2) 改进的模型融合了卷积层和BN层,简化了网络结构,一定程度上缓解了添加模块带来的额外计算量,提高了模型的检测速度。
(3) 由于引入了较多的添加层,yolov3_5l的检测速度降低了较多,但拥有较高的精度;yolov3_mod虽然精度比yolov3_5l低,但拥有更快的检测速度。根据实际工况需求可进行精度和速度的取舍。
(4) 模型对相似磨粒,特别是层状磨粒的识别率还有待进一步提高。同时,量化模型,降低添加模块的计算量也值得进一步深入研究。
