物联网环境下电力数据安全分级算法的研究
2021-05-18王成化王华伟郭凯明
赵 明,宋 驰,王成化,王华伟,郭凯明
(1.国网安徽省电力有限公司滁州供电公司,安徽 滁州 239000)(2.中能博望(北京)科技有限公司,北京 102488)
随着电力公司对电力物联网建设的全面推动,数据中台建设的有序进行,各类数据的“融汇贯通”,跨业务、跨系统的数据“广泛共享”已基本形成,数据作为资产将逐步面向全公司、全社会开放应用[1]。在数据共享过程中,如何保障数据安全、提供高效的数据算法模型就显得尤为重要。目前,各行业纷纷开展了数据安全和隐私保护的深入研究,国内外针对电力数据的安全也进行了加密、脱敏、防泄漏等方面的研究[2-3],但是对于数据安全分级的技术研究尚未深入,运用自然语言处理技术开展电力数据安全分类分级研究还比较欠缺。电力数据量庞大,人工形式逐字段进行数据安全定级效率太低,且误差较大,借助数据安全分级工具可实现自动化或半自动化的安全等级划分,极大地减少人工工作量,同时可避免人为操作的主观性和不稳定性。
基于此,本文提出了基于词频参数的改进特征项降维方法,降低文本的噪声,并结合优化支持向量机模型,提高分类算法的准确率,建立了数据安全分级术语库,开发了数据安全定级工具,实现电力数据的自动化和智能化安全定级,并通过实验论证了本文算法具有较高的准确率,且分布均匀性明显增加,可以有效解决数据分析及安全分级存在的性能和效率问题,指导数据共享,促进数据管理水平持续提升。
1 物联网智能电力数据采集系统
首先采用智能传感器获取电网的数据,为后续安全分级提供数据支撑。使用物联网技术将具备智能判断与自适能力的能源统一入网络,采用智能电表作为物联网三层架构中的核心感知层获取电力负荷参数,测量传感器、电流互感器及电压、电流采集芯片采集电网和用户信息以及各类电力参数信息,对电网信息的实时采集可达到秒级,采集的数据通过网络层的无线传输网络、专用网、互联网进行传输,提供给表现层进行数据的分类分级和可视化展示。物联网电力数据采集系统架构如图1所示。
智能电表主要采用数据采集传感器感知外部电力参数并实现数据的实时上传,本文选择DTZ341、DSZ331三相智能电能表,该电表内置传感器采集芯片,能够实时采集电能量,包括正(反)向有(无)功的总电量、各时段电量、需量及发生时间、负荷曲线(根据电表中实际设置情况)、电表冻结值(冻结类型根据电表设置)、瞬时量(包括电压、电流、功率、功率因数、频率等)、失压断相记录、相序错误记录、电压合格率、电表运行状态等。无线通信模块采用联通公司生产的通信模块,负责将采集的电力业务数据实时上传到数据存储服务器,进行后续的电力业务数据的分类分级、可视化展示等数据分析处理工作。

图1 物联网数据采集系统架构图
2 混合特征项降维算法
2.1 特征项降维算法
进行文本分类需要训练海量的文本数据,训练时使用向量空间模型对文本进行分词、分类、分级,海量数据的特征项和特征维也是海量的,部分无价值特征项会降低算法的执行效率,影响命中率,消耗空间、降低性能[4-5],因此必须采用特征降维空间算法消除噪声。本文结合经典的互信息和卡方统计量降维法创新地提出了混合式降维算法。
1)互信息(mutual information,MI)特征选择算法。
互信息特征选择算法[6]描述了特征项fi与文本类别lj之间的关联程度,通过关联程度识别无价值的特征项,具体的算法公式如下:
(1)
式中:MI(fi,lj)为文本类别lj的全部文本中出现的特征项fi的互信息值,是二者依赖关系的量化值;P(fi∩lj)为在文本类别lj的全部文本中出现特征项fi的频率;P(fi)为在训练样本中包含文本特征项fi的概率;P(lj)为训练样本中含有类别项lj的频率。根据公式的设置,特征项fi与文本类别lj的关联关系与P(fi∩lj)呈正比,关联度较高时P(fi∩lj)的值较大,关联度较低时P(fi∩lj)的值较小,如果二者不存在关联,则P(fi∩lj)的值为0。
大量的研究结果表明,应用互信息进行特征项降维时,存在的典型问题是该算法未结合特征项在文本集中出现的频率,对于低频特征项维度的影响较大,容易出现低频噪声而降低分类算法的准确度。
2.2 开方检验算法
采用开方检验算法(chi-square test,CHI)[7]进行特征项降维的前提是分级特征项fi对于文本类别lj来说,二者存在一阶自由度的卡方对应关系,卡方值越高,说明特征项与类别之间的关联度越高,反之,二者关联度越低,特征项fi应该被降维。具体计算公式如下:
CHI(fi,lj)=[N(numa-numb·numc)2]/ [(numa+numc)·(numb+numd)·(numa+numb)·(numc+numd)]
(2)
式中:CHI(fi,lj)为类别lj与特征项fi的开方统计相关度;numa为类别lj中包含特征项fi的文本总量;numb为类别lj以外的其他类别中包含特征项fi的文本总量;numc为样本类别lj中从未出现特征项fi的文本总量;numd为类别lj以外的类别中不包含特征项fi的全部类别的文本总量;N为全部文本数量。
2.3 CHI-MI-P特征降维算法
由于卡方统计量特征项降维方法与互信息特征项降维方法存在的共同问题是算法未引入词频参数,文本中低频词的权重较高,导致整体分类准确率降低,因此本文对卡方检验和互信息算法进行优化,提出了基于词频参数的改进特征项降维方法(CHI-MI-P)来提高分类算法的准确率,以提高后续分类算法的执行效率。针对互信息引入词频计算参数和词频权重参数,如式(3)所示:
(3)
(4)
式中:∂(f)为词频参数;f(f,l)为类别l中存在特征项f的数量;R=p(f,l),为调节参数。式(4)中分母是全部文档的全部类别中出现特征项f的次数总和。词频参数的引入使得特征项在某一类别出现的频率作为该特征词与类别关联关系的体现,通过设置合理的参数,增加高频特征项的权重,降低低频特征项的权重,可减少低频特征项对训练集的影响。
针对CHI算法进行大量的实验论证,实验过程中发现,由于特征项的分类能力与词频、所在类别之间关系紧密,且特征项分类能力较高的分词会集中出现在某几个类别中,说明各个不同的类别下特征项的方差与词频成正比。基于此,在引入词频参数的基础上,本文又加入了方差参数来调节算法的分类准确性,降低分类误差。具体公式如下:
(5)
式中:使用函数r标识类别i中特征项f出现的频率;fi(l)为特征i在类别l中出现的频率;m为全部特征项数量值。应用概率论方差计算公式,计算特征项在不同类别中的方差,从而量化特征项在各个类别的分布频率对最终分类结果的影响。结合方差因子与词频参数后的改进互信息算法如下:
(6)
对优化改进后的MI算法与CHI算法进行整合,将MI算法清晰准确、改进后算法对低频词的有效过滤、能区分不同特征项在重点类别的分布情况等优势,与开方统计算法在特征项的关联性识别的高准确性的优势相结合,提出改进的MI-CHI-P特征降维算法,如式(6)所示:
O-MI-CHI(f,l)=MI2(f,l)×CHI(f,l)
(7)
优化的特征降维算法既避免了低频次项的高权重对分类结果的影响,又可以识别到均匀分布在类别文档中的高频特殊项,进一步摒弃噪声,降低特征向量集的维度。
3 O-SVM支持向量机分类模型
3.1 核函数改进方案
在本文设计的电网安全分类模型中使用了支持向量机(support vector machine,SVM)进行文本分类,SVM的核心在于核函数[5],本文采用全局与局部相结合的核函数算法O-SVM(optimization SVM,支持向量机分类模型),综合了全局核函数泛化能力强与局部核函数分类能力强的优势。结合核函数的算法推理过程如下:
1)输入前提:f1,f2,…,fn均为核函数。
2)调整公式f1到fn的和仍然为核函数。
3)设置参数值a,b,af1+bf2的结果也是核函数。

(8)
在此基础上,基于经典的全局和局部核函数以及上述正定函数的推理结论,提出本文的综合核函数算法,如式(9)所示:
(9)
式中:keep为高斯核函数;δ为高斯函数的宽度;x,y分别为核函数曲线幅度和位移;c为满足c(ak1+bk2)c=cak1c+cbk2c的正定参数。式(9)可以兼顾全局样本的整体特征,也能识别到训练样本的个性化特点。
3.2 改进SVM模型
SVM文本分类算法中常用一对一的规则,其核心原理为化整为零的二分法,将原本m个分类进行分解处理,分解后的问题有m(m-1)/2个分类。对于数据样本集合中不对称的文本集,此类文本集下的各个文本类别对应的文档数量各不相同,使用二分法能为所有的文本样本进行分类归集,不存在无法分类的问题。但是,该方法的重大缺陷在于分类训练的其他文本(不属于两个分类)的其他样本会归类到错误的类别中,导致分类结果误判率增加。为了解决此问题,本文提出了文本关联系数的概念,对于不属于二分类的其他待分类问题,引入向量夹角来表示向量之间的关联关系,计算其与二分类之间的关联系数,向量夹角越小,说明两个向量越相似,运用相似度值改善二分法对不属于其分类范围的文本分类识别力差的问题,具体如式(10)所示:
(10)
式中:ρ(x,y)为关联度值;yn为向量值。
算法实现步骤如下:
1)按照式(5)计算文本样本与全部类别的关联度值,并使用向量d=(d1,d2,…,dm)存储全部类别与文本样本的关联度系数。
2)循环迭代,每一次迭代剔除与各个文本关联度最小的类别,减少文本样本矩阵的维度。
3)循环迭代结束后的高关联度文本矩阵的后续处理使用权重选举算法,最终产生分类结论。
4 实验结果与分析
4.1 数据集
本文采用智能电表采集业务数据,对数据进行转换处理后形成文本对象,将文本对象进行拆分,其中85%的文本设为训练集,15%的文本作为测试文本。智能电表采集的数据主要包括全市减供、全市停供、区域性减供、区域性停供、重特大事故、重大事故、较大事故、一般停电几类,每个类别包含2 800个文本文件。
4.2 结果分析
对本文提出的CHI-MI-P特征降维算法以及支持向量机分类模型进行试验论证。首先对特征降维算法的性能进行对比分析,对比了DF(document frequency,词频提取)算法、IG(information gain,信息增益)算法和CHI-MI-P特征降维算法应用SVM时的分类准确率,结果如图2所示。
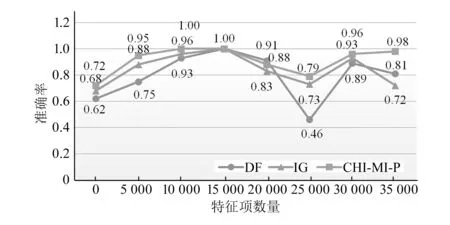
图2 不同特征选择算法应用SVM分类器准确率对比
由图2可以发现,DF算法比本文提出的算法的准确率低很多,当特征数量变得极大时,二者差距虽然缩少了,但依然存在,本文提出的算法优势明显。对不同类别下特征选择算法的准确率进行了对比,结果见表1,由表可知,在特征向量数量固定时,3种特征降维算法中,IG算法的准确率整体偏低,本文提出的算法准确率在80%以上,各个分类下的准确率都较高。

表1 CHI、MI和CHI-MI-P算法的分类准确率对比
实验过程中,重点对基于关联度值的SVM分类和本文提出的改进关联度SVM模型的分类结果进行比对。SVM模型与改进算法的查询准确率对比结果见表2 ,由表可以看出,改进算法的查询准确率提高较多,其整体结果较为均衡。这是由于改进算法中引入了关联度调节参数,使得分类准确率的差距变小,引入了方差后,使得分布均匀性明显增加。

表2 SVM和改进关联度算法分类结果对比
5 结束语
本文以电力数据安全分级策略研究为背景,基于物联数据分级和报表分析模型构建技术定义安全分级分类,形成电网数据安全词根库,结合自然语言处理分类分级算法,提出了混合特征分级算法,用于电力数据的安全分级,基于词频参数的改进特征项降维方法,降低文本分类的噪声,并结合优化的支持向量机模型,提高分类算法的准确率,实现电力数据的自动化和智能化安全定级,通过对比实验证实,本文提出的算法准确率达到80%以上,与其他算法相比极大地提高了分类的准确率,实现了对基础数据进行安全分级。
