基于PostGIS 的线要素空间聚合方法
2021-05-17王文荟钟少波宋敦江梅白帆
梅 新,王文荟,钟少波,宋敦江,梅白帆
(1.湖北大学 资源环境学院,武汉 430062;2.北京城市系统工程研究中心,北京 100102;3.中国科学院科技战略咨询研究院,北京 100190;4.江苏电力信息科技有限公司,南京 210000)
0 概述
随着工业化和信息化的迅速发展,人类社会运转速度越来越快,如物质、能量、信息等各种有形或无形的元素都处于不断加速移动过程中,而这些动态数据的集合称为空间流量数据[1]。随着传感器和GPS 技术的快速发展,时空数据的获取变得不再困难,面对海量的空间流量数据,如何提取有效信息和建立信息间的联系引起了众多学者的关注[2]。
线空间流量数据是指以线数据形式保存的含有流动属性的一种地理空间数据,利用线空间流量数据可以有效表达从出发地至目的地人流、物流和信息流等信息。如一列货车的行驶路径就是线数据,其载重量是它的属性。很多空间流量数据即线空间数据,它们来源于最短路径分析方法,比如知道两个中转站点的位置,可以通过最短路径分析方法计算得到这两点的最短路径,如果一辆货车要从其中一个站点转运货物到另外一个站点,那么一次运送货物产生的数据就是最短路径线空间流量数据。对于线空间流量数据,在大范围区域间,文献[3]通过对数线性模型方法,分析1990 年和2000 年美国和墨西哥的人口普查数据,探讨其人口迁移规律。文献[4]对覆盖绝大多数发达国家和发展中国家的约360 个港口之间的依存关系进行定量分析,以各港口的进出口贸易流量数据为依据,探索全球港口类型的分布规律以及交通网络和地方发展的内在联系。文献[5]基于铁路交通网络数据,以2003 年和2008 年省会城市铁路交通网络的最短旅行时间为度量指标,利用改正引力模型分析测算各省区域间空间可达性、空间格局、经济联系强度及其空间指向。
在研究大范围区域间关系时,一般是以区域间少数城市作为研究对象[6],或者间接统计分析点与点之间的关系,不直接通过线空间流量数据[4,7],究其原因主要是面对海量线空间流量数据时难以快速处理分析,将网络关系具体至每一条线路。而在小范围区域内,文献[8]采用基于网格索引的方法,利用里雅斯特市的道路路网,评估城市地区的网络密度并分析检索区域中心。文献[9]使用开放街道地图提供的网络结构数据,通过将交通网络与社区划分相联系的方法,利用ArcGIS 软件提供的“Line Density 线密度”工具,揭示吉隆坡市的路网发展。文献[10]根据出租车轨迹大数据中提取的短时非运营行为,采用线要素核密度分析和Ripley’s K 函数两种方法,研究出租车短时非运营行为的时空特征及其与加气站间的空间相关性。而上述研究中的方法,均为对线空间流量数据以栅格形式输出每个像元邻域内的线状要素的密度,并能指定权重值对线要素进行统计,有效地分析线数据的空间聚集效应和时空分布关系。然而,相较于栅格数据,矢量数据在表示空间位置关系和空间网络的相互作用关系上更为精确,并且易于进行拓扑分析和网络分析,更适合定量描述,为后续其他空间分析提供数据基础[11]。
针对海量数据情况下数据处理效率较低和矢量数据输出存在的问题,本文提出一种基于空间操作的线要素聚合方法。由于线要素是由一个或多个相连或不相连的路径组成的有序集合,因此可以直接对线要素拆分后进行聚合操作。线数据均由节点按一定顺序连接形成,可以通过对节点进行聚合操作,再重新生成新的线数据。该方法分别基于ArcGIS和PostGIS 两个平台实现,并以北京到2 845 个县市(区)的交通路网数据为实例进行验证。
1 线空间聚合方法
线空间流量数据包含空间位置信息、属性特征信息和时域特征信息,本文暂不讨论时域特征信息。线空间聚合方法是将复杂多样的线空间流量数据细化,更直观地反映事物间的联系,同时压缩减少冗余数据[12]。本文的最短路径线空间流量数据是以原线空间流量数据的相交点或已有端点作为节点,重新连接相邻两个节点形成的线数据,且包含该线数据空间位置应保留的属性特征信息。经过线空间聚合方法生成的最短路径线空间流量数据是一种空间上无重叠的线数据,即两个直接相连的节点之间只有一条线,这条线的属性是所有落在这条线上的流量值的和。因此,线聚合后的线空间数据可以更精准地表达区域间或区域内事物的属性特征关系以及拓扑网络关系。
1.1 基于ArcGIS 的线空间聚合方法
在线要素分析研究中,将整体线数据拆分为单独的线要素甚至多组折线段的研究有很多,文献[13]利用历史和现实的交通流量基础数据,通过瓶颈识别算法、聚类相似特征数据和在线搜索算法预测各路段道路拥堵时间。文献[14]在为广义框架引入稀疏性概念的条件下,提出一种采用线段作为聚类代表,聚类数据点的距离作为代表线段的距离,分析处理二维空间中线性形状的聚类算法。文献[15]通过对每条线要素分别计算化简阈值范围,逐段化简,最后根据最高匹配相似度判断结果,实现矢量线要素匹配。本文基于这一思想,提出基于ArcGIS 平台下的线空间聚合方法。
基于ArcGIS 的线空间聚合方法有拆分线数据、按位置匹配线数据和融合线数据3 个步骤,从而完成线空间聚合。图1 所示为基于ArcGIS 的线要素空间聚合方法流程。本文基于ArcGIS 提供的ArcPy 站点包实现线空间聚合方法。
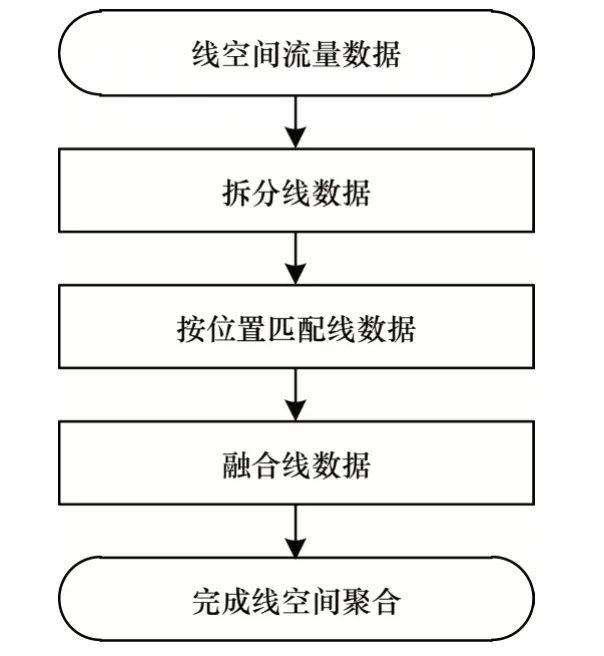
图1 基于ArcGIS 的线要素空间聚合流程Fig.1 Procedure of polyline spatial aggregation based on ArcGIS
基于ArcGIS 的线空间聚合方法具体如下:
1)通过属性“流量权重”表示线空间流量数据所包含的需要参与统计计算的属性特征信息。拆分线数据过程是指将线空间流量数据通过求取线要素与线要素的相交点,并在相交点处断开的过程,目的是将每一条线空间流量数据拆分成为以相邻节点为端点的弧段,拆分后的子弧段均继承父线的“流量权重”属性。
利用ArcGIS 中已有的“Feature To Line 要素转线”工具完成拆分线数据。基于ArcGIS 方法的线空间流量数据如图2 所示。以图2(a)为例,L1和L2是两条线空间流量数据,A、B、C、D是4 个节点。L1是起点为点A,经过点B,终点为点C的线要素,其属性“Id”为1,属性“流量权重”为20。L2是起点为点A,经过点B,终点为点D的线要素,其属性“Id”为2,属性“流量权重”为10。表1 是L1和L2集合列表。
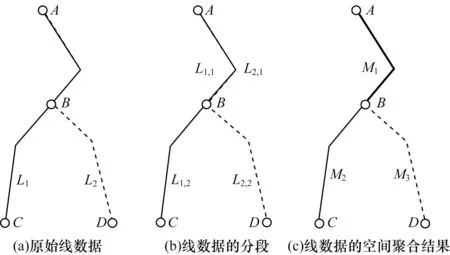
图2 基于ArcGIS 方法的线空间流量数据示例Fig.2 Example of polyline spatial flow data based on ArcGIS method

表1 线要素空间流量数据集合Table 1 Aggregate of polyline spatial flow data
对L1、L2进行拆分线要素步骤,得到4 条弧段,表2 是其拆分后的集合列表。根据拆分线要素的规则,L1拆分后得到两条弧段L1,1和L1,2,L1,1是起点为A,终点为B,属性“流量权重”为20 的弧段,L1,2是起点为B,终点为C,属性“流量权重”为20 的弧段,同理可得L2拆分后的弧段,如图2(b)所示。
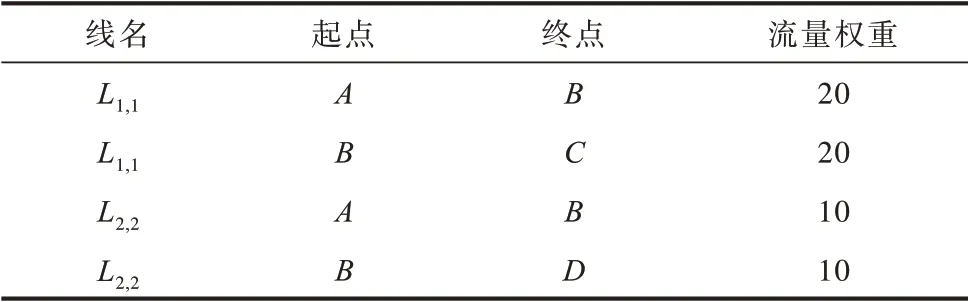
表2 线要素空间流量数据拆分后集合Table 2 Aggregate of polyline spatial flow data split
2)按位置匹配线数据。按照弧段的空间位置进行匹配,将完全重合的弧段分为一组,并为之添加唯一属性。由于直接判断线与线的位置关系较为复杂,因此采用弧段上某一点的坐标辅助判断弧段与弧段的重合关系,ArcGIS 软件提供工具可以得到弧段的起点、终点和弧段中点即将弧段分为长度相等的两个部分的点(不一定是折点)。此处,本文选用弧段中点辅助判断弧段间的拓扑关系。因为线状目标之间的拓扑关系可以简单分为相离、相邻、相交和重合[16],如图3 所示,此时所有线要素均已拆分,拆分后的弧段间不存在相交的拓扑关系,所以不完全重合的线段的中点坐标均是唯一坐标,同时若两条弧段中点坐标相同,则两条弧段完全重合。

图3 线状目标之间的拓扑关系Fig.3 Topological relationships between linear targets
利 用ArcGIS 中“Feature Vertices To Points 要素折点转点”、“Add XY Coordinates 添加XY 坐标”和“Spatial Join 联合”工具,为所有弧段添加属性“中点坐标”。
3)将属性“中点坐标”相同的弧段融合,即融合位置重叠的弧段。利用ArcGIS 中“Dissolve 融合”工具,并通过工具提供的属性统计功能,重新计算融合后弧段的属性,如SUM 方法可为新生成弧段添加指定字段的合计值。由于L1,1和L2,1两条弧段位置完全重合,因此将其融合,并通过SUM 方法,累加属性“流量权重”,为融合后弧段重新赋值,而L1,2和L2,2为单一弧段,所以无变化。L1、L2完成线空间聚合后形成3 条最短路径的线空间流量数据,如图2(c)所示,分别是线M1,起点为A,终点为B,属性“流量权重”为30 的线数据,线M2起点为B,终点为C,属性“流量权重”为20 的线数据,线M3起点为B,终点为D,属性“流量权重”为10的线数据,表3 所示为最短路径线空间流量数据的集合。
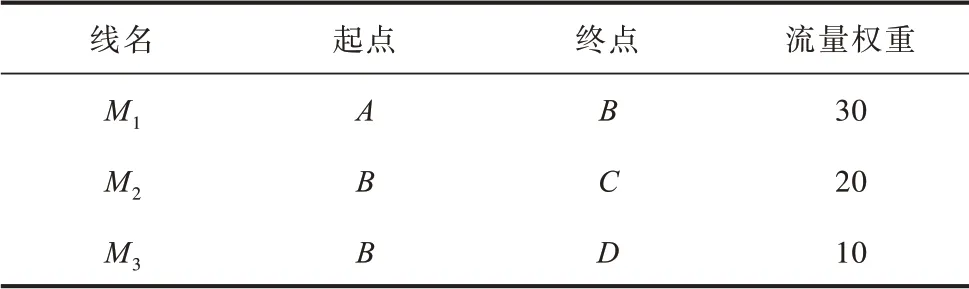
表3 最短路径线要素空间流量数据的集合Table 3 Aggregate of shortest path of polyline spatial flow data
1.2 基于PostGIS 的线空间聚合方法
线要素分析与点要素分析关系密切,文献[17]采用k-链最短路径的思想,利用平行点逼近的方法拟合折线。文献[18]利用基于位置的社交网络和出租车GPS 数字足迹组合,实现个性化、交互式和流量感知的旅游路线规划。文献[19]利用GPS 轨迹数据,通过一个合适的圆圈确定单个道路交叉口的边界特征点,重建道路交叉路口,同时保持道路网络的拓扑关系,生成高质量详细的道路路网数据。基于上述思路,本文选择将线空间流量数据离散为节点,对节点进行聚合分析,再由完成聚合分析后的节点重新连接生成最短路径的线空间流量数据,并且在PostGIS 平台的支持下实现该方法。基于PostGIS 的线空间聚合方法流程如图4 所示。
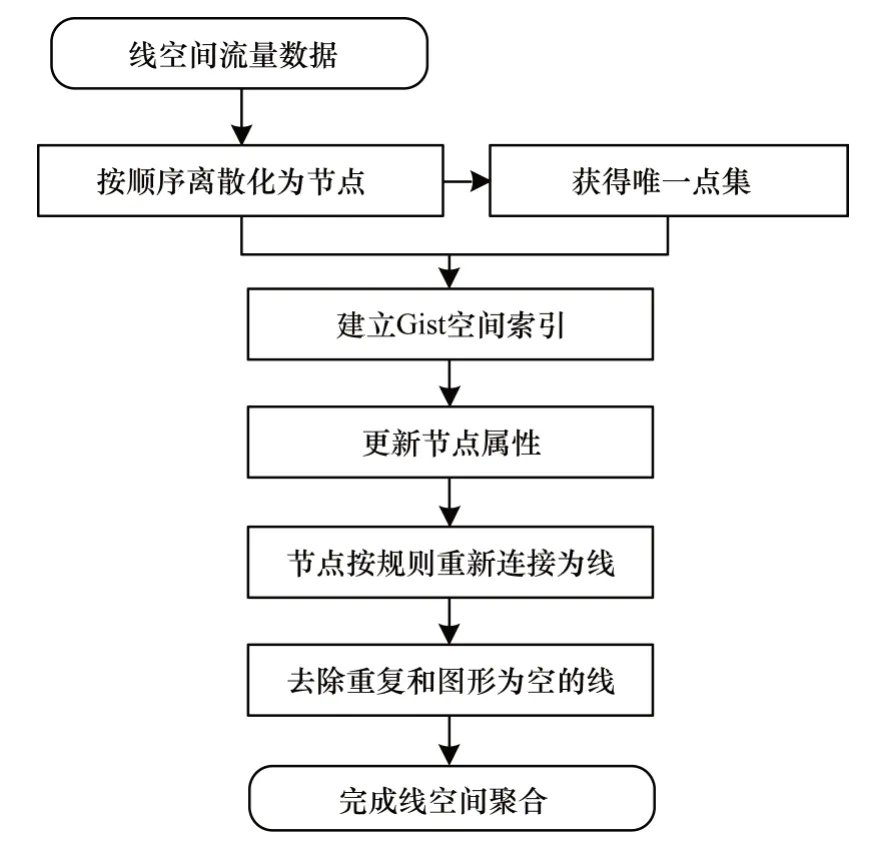
图4 基于PostGIS 的线要素空间聚合流程Fig.4 Procedure of polyline spatial aggregation based on PostGIS
1.2.1 PostGIS 空间数据库引擎
PostGIS 空间数据库引擎是在关系型数据库PostgreSQL 上的空间数据存储和各种数据操作的一个插件。PostGIS 通过SQL 语句进行数据操作,空间对象以表的形式储存,每个空间几何实体对应数据表中的一条记录,其中记录了坐标信息和属性信息,并支持多种开源投影库。PostGIS 提供大量空间函数,下面只列出本文所使用的主要函数:
1)ST_NPoints(geometry geom)。返回geometry的顶点总数,对所有的geometry 类型都支持。
2)generate_series(start,stop,step)。按照规则产生一系列的填充数据,生成一个数值序列,从start到stop,步进为step(若无step,则默认为1)。
3)ST_PointN(geometry a_linestring,integern)。返回单个linestring 的第n个point 对象,如果几个对象中不包括LineString 对象,则返回NULL。
4)ST_Equals(geometry,geometry)。判断2 个几何对象是否相等,如果相等则返回TRUE。
5)ST_MakeLine(geometry[]geoms_array)。利用一个数组的point 或line 生成一个LineString 对象。
1.2.2 线要素离散化节点
在OGC 的Geometry 类体系中有如下聚合关系:Point(2+)->LineString,即2 个及以上的点要素可以聚合成为线要素,反之,线要素亦可离散为点要素,将所有线段视为有序或无序的节点集合[20-21],相较于直接对线要素进行处理,点要素的聚合更为简单,通过搜索一定范围内的点即可完成点要素聚合。设线要素的节点序列形式为:
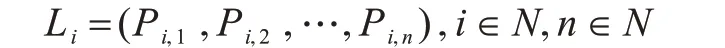
其中,Li由节点Pi,1,Pi,2,…,Pi,n按顺序连接而成,i和n均为自然数。
创建一个空间对象数据表child_point 用于储存离散后的节点,该表中主要有属性“Id”、属性“weight”、属性“ptindex”和属性“geom”。其中,属性“Id”和“weight”分别继承父线的属性“Id”和“流量权重”,而属性“ptindex”为节点在原父线中的顶点序列号,属性“geom”几何对象为点空间数据。
利用PostGIS 中提供ST_NPoints(geometry geom)函数获取线要素的顶点总数,generate_series(start,stop,step)函数生成所有顶点的序列号,ST_PointN(geometry a_linestring,integern)函数获得第n个节点,将所有节点插入到创建的空间对象数据表test_pt 中。本文示例中L1和L2如图5(a)所示,与1.1 节中示例一致,其集合列表见表1,此处不再赘述。L1将离散为P1,1,P1,2,…,P1,5,它们继承父线L1的属性“Id”和“流量权重”,分别为1 和20。而L2将离散为P2,1,P2,2,…,P2,5,它们继承父线L2的属性“Id”和“流量权重”,分别为2 和10,表4 是离散后节点的集合列表。如图5(b)所示,点P1,1和P2,1完全重合,点P1,2和P2,2完全重合,点P1,3和P2,3完全重合。
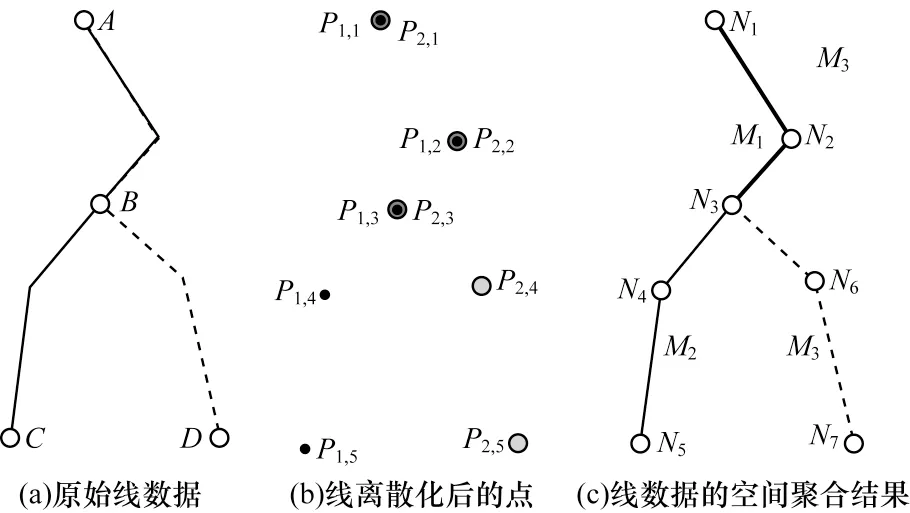
图5 基于PostGIS 的线要素空间流量数据示例Fig.5 Example of polyline spatial flow data based on PostGIS
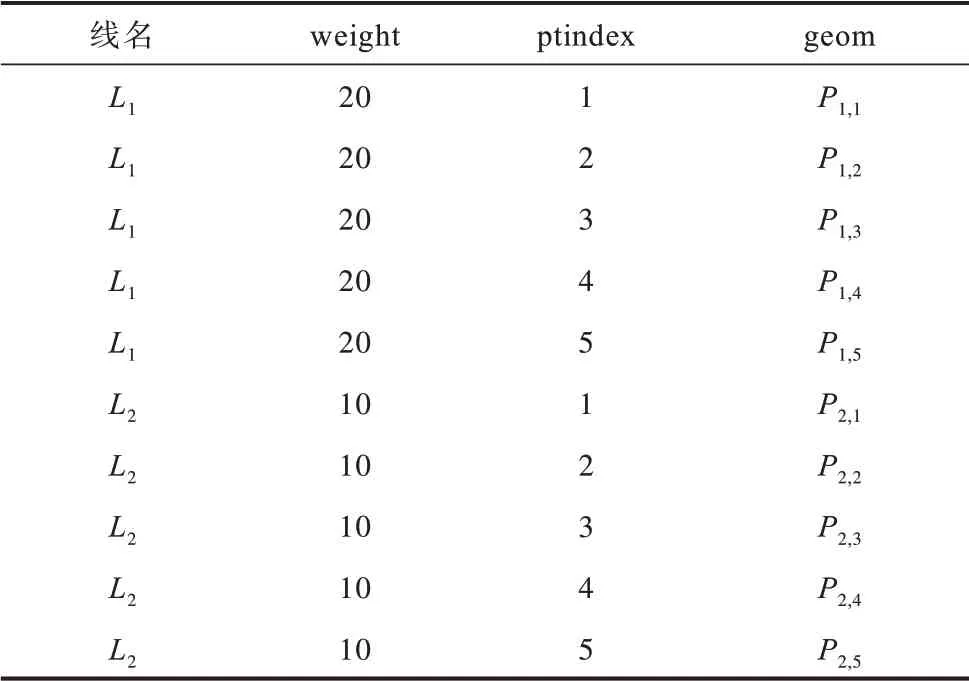
表4 节点集合Table 4 Aggregate of nodes
1.2.3 节点空间索引的创建
地理空间索引是指依据地理要素的空间位置、形状或地理对象之间的某种空间关系,按一定的顺序排列的一种数据结构,目的是为了快速定位地理对象,提高空间操作的速度和效率。
Gist 索引是一种平衡的树状索引,它易于扩展数据类型和查询类型,且B-Tree、R-Tree 以及其他索引形式也能作为Gist 的扩展实现。本文选用PostgreSQL 数据库中默认支持的Gist 索引来提高线数据空间聚合的速度,由于线要素离散化后的点数据的属性进行更新操作频繁,因此这里为空间对象数据表child_point 中的点数据创建Gist 空间索引。
1.2.4 节点聚合
点数据的空间聚合一般是通过一定规则,搜索范围内所有的点进行聚合,用少量的点表达多数点的方法。该节点的聚合是针对离散后的节点中属性“weight”的聚合。
父线是由节点按顺序连接组成,所以父线中位置完全重合的弧段,离散后的节点位置也完全重合。创建一个空间对象数据表temporary_point,辅助更新节点属性“流量权重”,该数据表仅包含2个属性:“weight”和“geom(点要素几何对象)”。通过PostGIS 中提供的空间数据查询和分析功能,将child_point 中位置完全重合的节点数据分为一组并统计计算属性值,如SUM方法可以用于累加属性信息,实现属性“流量权重”的聚合,将节点数据插入空间对象数据表temporary_point中。此时,保证该表中任意位置节点均为唯一节点,且有与之相对应的属性“流量权重”,即数据表child_point中该位置所有节点的属性“流量权重”之和。如图5(b)所示,P1,1和P2,1节点位置处,在空间对象数据表temporary_point 存在有一点数据与这2 个节点位置重合,其属性“流量权重”为它们的该属性之和,即P1,1.weight与P2,1.weight 的和等于30。
此时,利用数据表child_point和数据表temporary_point 中节点位置重合的特征,更新数据表child_point 中节点属性“weight”,目的是在实现点的聚合过程中,不破坏原节点的属性“Id”和属性“ptindex”。更新属性“weight”后,位置重合的节点该属性也是一致的,如表5 所示。表5 是聚合后的节点集合列表,可以得出更新后的节点P1,1,其属性“Id”为1,属性“ptindex”为1,属性“weight”为30,同理节点P2,1,其属性“Id”为2,属性“ptindex”为1,属性“weight”为30,以此类推。而原节点位置仅有唯一节点时,不发生变化。
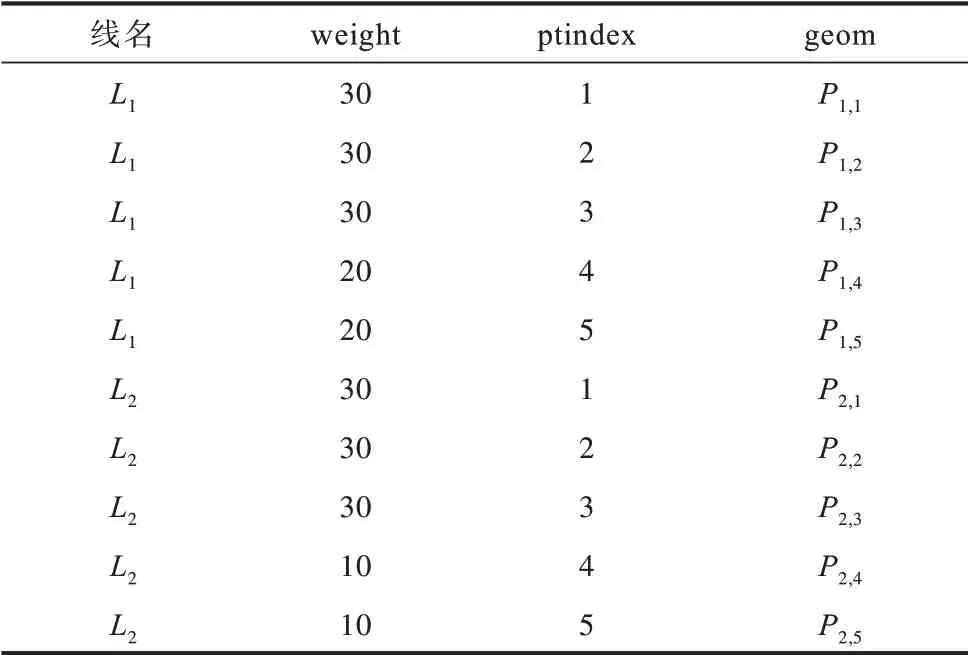
表5 完成节点聚合后节点的集合列表Table 5 List set of completed nodes aggregation
1.2.5 节点重新连接生成的线要素
完成节点的聚合后,需要将节点按照规则重新连接成为折线,并赋值属性“流量权重”,具体流程如图6所示。
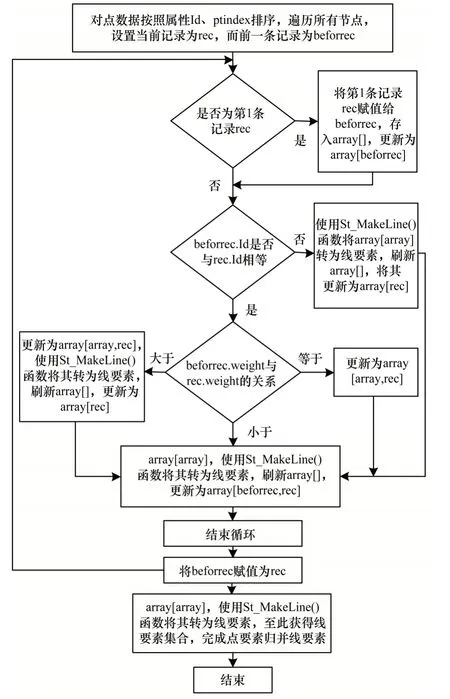
图6 节点重新连接生成线要素流程Fig.6 Procedure of reconnecting nodes to generate polylines features
首先创建一个空间对象数据表connection_line用于储存节点按规则连接后生成的新线要素。该表包含属性“Id”、属性“weight”和属性“geom”。其中属性“geom”几何对象为线空间数据。
然后按照如下步骤将节点连接生成新的线要素:
1)创建一个用于存储点数据的数组array[]。按照节点数据的属性“Id”排序,再根据节点的序列号即属性“ptindex”进行遍历,将第1 条记录赋值给beforrec,存入array[]中,更新为array[beforrec]。
2)将相邻(序列号相连)且属性“weight”相等的节点依次存入数组array[]中,直至属性“Id”或属性“weight”发生改变。有以下3 种情况:
(1)当前记录rec 的属性“Id”与前一条记录beforrec 的属性“Id”不一致。如图7(a)所示,当前记录为点C,前一条记录为点B,设此时数组为array[A,B],利用ST_MakeLine(geometry[]geoms_array)函数将array[A,B]转为折线AB,插入储存线要素的空间对象数据表中,属性“weight”为节点B的属性“weight”。刷新array[],将当前记录C存入,成为下一条折线的起点,更新为array[C]。虚线部分是辅助标识下一条折线的轨迹,不再赘述。
(2)当前记录rec 与前一条记录beforrec 的属性“Id”一致,但属性“weight”小于前一条记录。如图7(b)所示,当前记录为点C,前一条记录为点B,设此时数组为array[A,B],利用ST_MakeLine(geometry[]geoms_array)函数将array[A,B]转为折线AB,插入储存线要素的空间对象数据表中,属性“weight”为节点B的属性“weight”。刷新array[],将前一条记录B和当前记录C顺序存入,成为下一条折线的初始点,更新为array[B,C]。
(3)当前记录rec与前一条记录beforrec的属性“Id”一致,但属性“weight”大于前一条记录。如图7(c)所示,当前记录为点C,前一条记录为点B,设此时数组为array[A,B],将当前记录C存入数组中,数组更新为array[A,B,C],利用ST_MakeLine(geometry[]geoms_array)函数将array[A,B,C]转为折线ABC,插入储存线要素的空间对象数据表中,属性“weight”为节点B的属性“weight”。刷新array[],将当前记录C存入,成为下一条折线的起点,更新为array[C]。
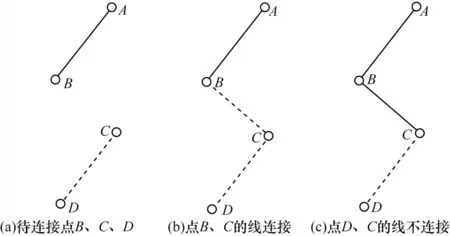
图7 节点连接为线要素示意图Fig.7 Schematic diagram of nodes connected to polylines
3)遍历所有节点后,利用ST_MakeLine(geometry[]geoms_array)函数将最后一次刷新的数组中的点按顺序连接成折线,插入储存线要素的空间对象数据表中,属性“weight”为前一条记录的属性“weight”。
至此,所有节点均重新连接为折线。在本文示例中,节点连接成为新的线要素集合如表6 所示,共有4 条线要素,分别为折线P1,1P1,2P1,3、P2,1P2,2P2,3、P1,3P1,4P1,5和P2,3P2,4P2,5,对应属性“weight”见表6。

表6 节点连接为线要素后的集合Table 6 Aggregate of nodes connected to polylines
1.2.6 线空间聚合
由实现节点重新连接为折线的集合列表可知其中存在位置重复的线,因此通过空间数据查询和插入功能,将位置重复的线去除,获取唯一折线。
在点归并为线的过程中,会出现一种情况,当array[]中有且仅有前一条记录beforrec,而此时当前记录rec与前一条记录beforrec的属性“Id”一致,但属性“weight”小于前一条记录,函数ST_MakeLine(geometry[]geoms_array)依旧会执行,但由于数组中仅有一个点,从而形成一条图形为空的线,因此将其删除。
如图5(c)所示,采用基于PostGIS 的线空间聚合方法后,共获得3 条最短路径的线空间流量数据,分别为:起点为N1,经过N2,终点为N3,属性“流量权重”为30 的线要素;起点为N3,经过N4,终点为N5,属性“流量权重”为20 的线要素;起点为N3,经过N6,终点为N7,属性“流量权重”为10 的线要素。其中,N1,N2,…,N7仅为节点位置,如N1与P1,1、P2,1重合,依此类推。
2 实验分析
2.1 实验1
为验证本文方法的有效性,本文实验数据选取两组不同规模的真实线性空间流量数据集进行测试,其特征信息如表7所示。数据集1是由武汉市市辖区至长江中游城市群其他182个县级单元的最短公路路径组成,包含182条轨迹,每条轨迹流量属性为2015年终点县级单元的年末人口数。数据集2是由长江中游城市群31个市级单元(包括湖北省省属直辖市天门市、仙桃市和潜江市)两两间最短公路路径组成,包含465条轨迹,每条轨迹流量属性为2015年两端点市级单元的年末人口数之和。模拟实验针对上述两组数据集采用常见商业软件ArcGIS方法和本文方法进行对比分析。实验环境如下:操作系统为Windows10,主频为3.4 GHz的CPU i7-6700,内存为16 GB,方法分别利用ArcGIS10.5和PostgreSQL10.6、PostGIS2.5基于Python语言编程实现。

表7 两组数据集信息Table 7 Two sets of dataset information
两种方法在两组数据集上的实验结果如表8所示。

表8 两组数据集下不同方法的效率Table 8 Efficiency of different methods under two data sets
由表7、表8 可以看出,对于不同数据量和不同网络复杂度的两组数据集情况,本文方法相对于常见商业软件ArcGIS 的方法在时间效率上具有较大的优势。
2.2 实验2
本文选用北京市至全国2 845 个区县(市)的交通线路路网数据作为实验数据,共计2 845 条线要素,每条线路的属性值是该区县(市)2010 年常住人口,数据来源为2010 年的《第六次全国人口普查公报》。通过线要素聚合方法,对2 845 条线进行聚合,得到共计5 085条线要素,并按属性值大小将线聚合结果分为4个等级:将属性值为20×108人~80×108人设为三级轴线;5×108人~20×108人设为二级轴线;2×108人~5×108人设为一级轴线,可以得到一级轴线的终点城市为西安市、驻马店市和徐州市,二级轴线的终点城市包括长春市、无锡市、荆州市、成都市、重庆市、永州市、广州市、吉安市等。二级轴线的终点城市太多,这里不再列出。本文未考虑江河湖海的阻隔作用,因此,若不考虑沿江沿海的作用,这些一级和二级轴线上的城市将会发挥重要的“桥头堡”作用。
由于是矢量数据输出,可以直接进行查看,精确到每座城市间,并且能为后续空间操作提供数据基础。
在全国实例数据分析中,基于ArcGIS 的线空间聚合方法共需43 min,而基于PostGIS 的线空间聚合方法仅需4 min。充分说明在面对海量数据时,基于PostGIS 的线空间聚合方法具有明显优势。
3 结束语
本文提出一种基于PostGIS 的线要素空间聚合方法,该方法在面对大型数据时处理速度较快,比当前GIS 领域常用的ArcGIS 软件更适合处理地理大数据,能够适应海量数据环境下的线空间流量数据分析。PostGIS 是一款开源GIS 软件,功能丰富可扩展性强,能够较好地应用于地理空间数据处理研究。下一步将在并行计算环境下提高GreenPlum 的计算效率,同时把线要素的空间聚合方法扩展到面要素的空间聚合任务中。
