基于网络流量预测的DASH 系统优化
2021-05-17耿俊杰李晓明颜金尧
耿俊杰,李晓明,颜金尧
(1.中国传媒大学 协同创新中心,北京 100024;2.北京华宇信息技术有限公司,北京 100024)
0 概述
随着网络带宽不断增加,人们对网络媒体的信息需求日益增长。根据2016 年CISCO 公司发布的基于网络应用分类的流量报告[1],网络媒体流量占整个网络流量的86%,各类媒体应用成为人们信息化生活必不可少的一部分。传统的RTP/RTSP[2-3]流媒体技术主要基于用户数据报协议(User Datagram Protocol,UDP),其传输具有不可靠性,且RTP/RTSP流媒体技术需要特定的流媒体服务器CDN,部署成本较高。此外,网络带宽实时波动会影响用户的视频播放体验,为了使用户获得更快速、流畅和清晰的媒体服务体验,改进流媒体技术提高用户的体验质量(Quality of Experience,QoE)成为研究热点。
用户的体验质量与重缓冲时长成反比,与视频清晰度成正比。用户期望获得较高的视频质量[4],而视频质量与视频编码速率成正比,当网络状况较差、视频编码速率较低时,客户端如果仍选择较高视频质量,则会造成当前回放的缓冲时长过度消耗而发生重缓冲,导致播放出现停顿[5],从而降低用户体验质量。近年来,超文本传输协议(Hyper Text Transfer Protocol,HTTP)自适应传输技术逐渐兴起,2011 年MPEG 组织联合3GPP 公司共同发布关于HTTP 自适应流化的公开草案MPEG-DASH[6],推出基于HTTP 的动态自适应流(Dynamic Adaptive Streaming over HTTP,DASH)[7-8]技术,其可通过感知当前客户端网络和缓冲等状况,动态选择相应编码速率的视频片段下载播放,在客户端网络状况较好或缓冲时间较长时会获得更高的视频质量,是提高用户体验质量的有效途径。
ABR 自适应比特率算法[9]是一种使用较广泛的自适应流媒体速率算法,其主要分为两类:第一类算法利用网络吞吐量预测并选择视频片段质量,即根据上一个视频片段平均下载速率选择下一个视频片段质量;第二类算法仅根据当前缓冲区的缓存状态选择视频片段质量。第一类算法对吞吐量的预测较简单,常会过高或过低估计网络带宽,导致发生重缓冲。第二类算法由于未对网络吞吐量进行实时预测,因此网络的动态性和DASH 基于HTTP 的渐进式下载方式会导致提前触发抛弃规则,从而损失带宽利用率,降低视频质量。抛弃规则是指在视频片段下载过程中实时监控下载速率,当下载速率无法满足一定条件时,则放弃当前所选视频片段,并根据当前网络状况重新选择视频片段。网络吞吐量的准确预测有助于提高用户的视频体验质量[10-11]。
本文在传统基于吞吐量的ABR 自适应比特率算法基础上,提出一种改进自适应流媒体速率算法。使用机器学习方法预测网络吞吐量并自适应流速率,建立基于浏览器缓冲时长和当前网络吞吐量预测的决策模型,将支持向量回归(Support Vector Regression,SVR)模型和长短期记忆(Long Short-Term Memory,LSTM)网络[12]相结合,在不发生重缓冲情况下获得较高的视频质量。同时,将评价指标SSIMPlus[13]作为不同编码速率下视频效用的客观度量,并设定阈值,当视频质量效用超过阈值时进行切换以减少视频播放抖动,最终采用带宽描述文件[14]进行实验验证。
1 相关工作
为提高基于HTTP 的视频流用户体验质量,研究人员提出众多自适应比特率算法。其中,传统基于吞吐量的自适应算法[15-17]使用上一个视频片段的平均下载速率作为下一个视频片段的选择标准,然而其吞吐量估计不够准确。BBA 模型[18]充分利用缓存信息,提出当缓存时间较长时应选择较高的视频片段下载速率,反之应选择较低的视频片段下载速率,并将缓存时长与所选速率映射为单调递增的分段线性函数。该模型虽然根据当前的缓存状态选择速率,但在带宽的预测上仍基于上一个视频片段的平均下载速率选择下一个视频片段。PANDA 模型[19]根据TCP 加窗原理,利用加窗函数对选择速率进行微调来测试网络性能。该模型能提高视频播放速率的稳定性,但由于其采用类似TCP 慢启动的特性,从启动到达到最高可用带宽需要一定时间,无法快速利用可用带宽,导致用户的体验质量有所降低。QDash-abw 模型[20]利用代理模块实时测定TCP 的延时特性,用于计算可用网络带宽,在一定程度上加大客户端的负担。
BOLA 模型[21]基于李雅普诺夫稳定理论证明在已知当前缓存的情况下,无需知道网络状况就可采用最大化效用函数选择相应的编码速率,从而达到在缓存稳定条件下时间平均效用的最大化。该模型需在缓存达到稳定状态时触发算法,由于前期缺少缓存信息,因此可采用传统算法选择合适的比特率。BOLA 模型可降低重缓冲率,并能保证在缓存相对稳定的情况下,实现用户体验质量效用最大化。为保证该模型在网络带宽波动较大时的有效性,在视频片段下载阶段会触发BOLA 抛弃规则,即通过实时监控网络吞吐量重新选择视频片段质量。由于TCP 协议具有慢启动的特性,因此在实际网络中BOLA 抛弃规则会提前触发,导致视频质量下降。
相关研究表明吞吐量的准确预测有助于提高用户的视频体验[22],然而在网络流量预测方面,许多研究工作集中在如何理解网络流量的模式[23-24]以及通过建模来预测网络流量。传统网络流量预测采用统计学方法,根据网络流量时间序列之间相关性建立线性预测模型,例如移动平均模型MA、自回归模型AR 和自回归滑动平均模型ARMA 等。由于大部分网络的时间序列具有非平稳性和非线性的特点,因此研究人员提出基于原有线性预测模型进行差分处理的ARMA 模型[25]。此外,基于机器学习的时间序列模型也被应用于网络流量预测。文献[26-27]提出一种基于支持向量机(Support Vector Machine,SVM)的流量预测模型,在此基础上,研究人员针对视频流量进行预测[28]。文献[29]使用LSTM 深度模型对时间序列进行预测。文献[30]提出一种基于SDN 的DASH 模型,通过SDN 的网络架构实时调整网络服务质量策略,为客户端提供带宽保证,从而提高用户的体验质量。
2 系统模型
传统DASH 系统结构如图1 所示。客户端视频播放器向媒体服务器发送请求获取媒体文件并展示描述文件MPD,再根据当前网络状况向媒体服务器请求相应质量的视频片段。由于DASH 服务器与客户端之间的网络可用带宽在拥塞或者4G 传输等情况下存在实时变化,导致用户的体验质量发生变化,包括所看视频的质量降低以及出现重缓冲现象。
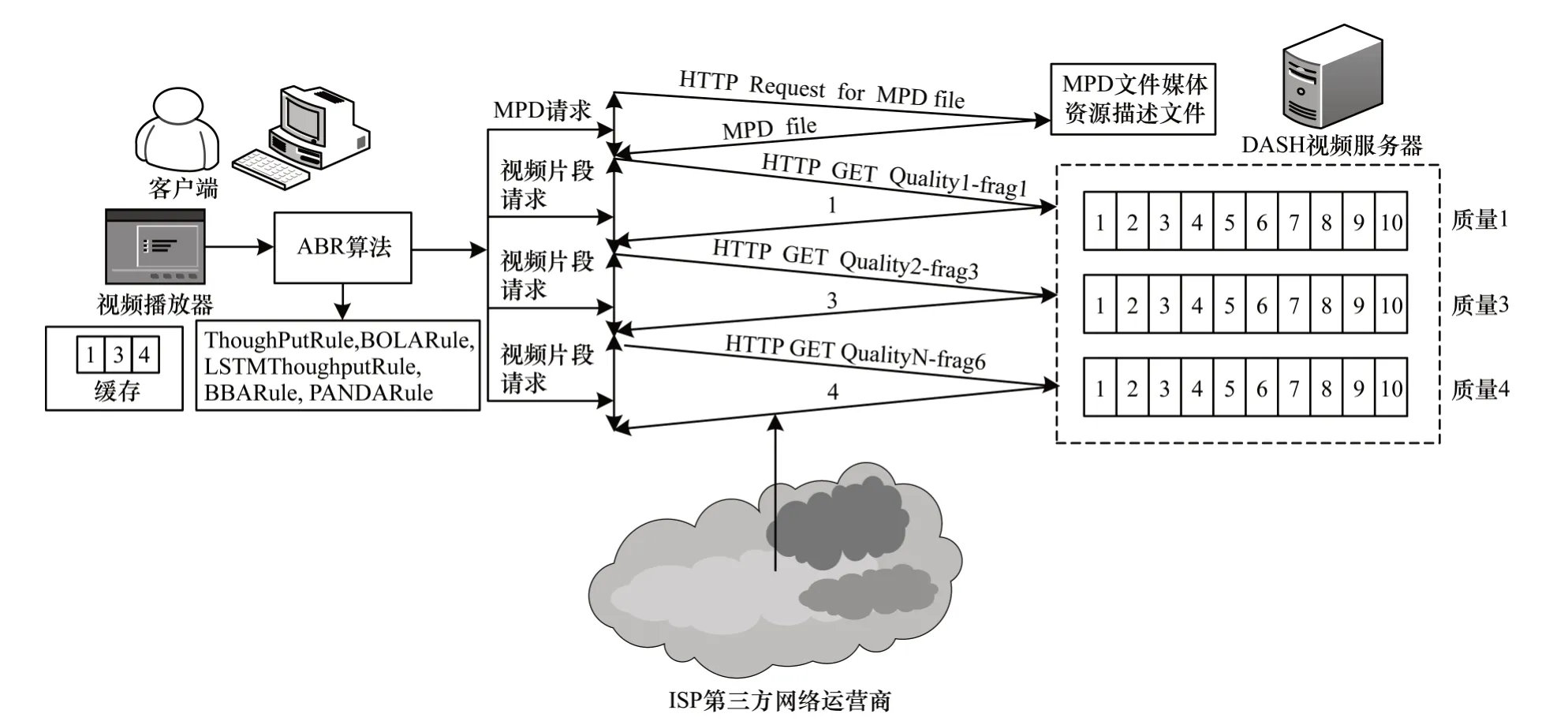
图1 传统DASH 系统结构Fig.1 Structure of traditional DASH system
2.1 传统DASH 模型
定义1(视频质量)一个完整的视频流被编码为代表不同视频质量的l种比特率,视频编码速率集合ℝ={r1,r2,…,rl},∀ri∈ℝ,1≤i≤l,ri为视频编码速率。各种比特率的视频流均可划分为N个视频片段,即∃ChunkSeti={chunki1,chunki2,…,chunkiN},每个视频片段有相同的时间间隔p,即∀chunkij∈ChunkSeti,1≤i≤L,1≤j≤N,Periodofchunkij=p。视频片段大小Sij=p×r,视频效用随视频片段增大而单调递增。其中,ri≤rj,1≤i≤j≤l,ui≤uj(ui为以速率ri编码的视频片段效用)。
定义2(网络可用带宽)网络可用带宽在服务器和客户端之间随网络波动不断变化,设网络带宽是一个随时间变化的随机过程bw(t),在t时刻请求选择下载编码速率为ri的视频片段chunkij,则在下载时间段下载的视频片段大小为:

下载时间为:
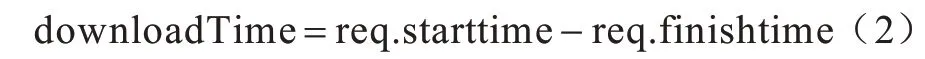
DASH 客户端处理过程为:视频播放器下载连续的视频片段在客户端进行回放,且每个片段在下载完成后才能播放。播放器根据当前可用带宽向服务器发送请求HTTP Request 来下载相应编码的视频片段,视频片段下载完成后以编码速率进行解码播放。视频播放器采用一个有限的缓存来存储下载的连续片段,如果缓存时长为0,则表明无内容可播放;如果缓存被占满已无可用空间,则需等待相应时长Δ。
传统DASH 模型的交互过程如下[31]:
1)以初始化速率下载。初始速率通过预先设定的Defaultr∈ℝ 获得,先根据视频片段质量量化函数q(rinit)得到相应的视频质量,然后开始下载视频片段。
2)下载监控阶段。实时监控下载过程的网络吞吐量,如果下载相应比特率的视频片段所需时间超过阈值,则抛弃所选比特率,并根据当前网络吞吐量选择视频片段质量。
3)根据上一个视频片段的平均下载速率得到网络吞吐量估计值,并据此选择下一个视频片段的质量。下一个视频片段的平均下载速率rnext=LastSi(j-1)/downloadtime,通过质量量化函数q(rnext)得到相应视频片段质量并开始下载,然后重复步骤2。
4)调度阶段。如果客户端在下载第j个视频片段时缓冲时长B(j)大于最大允许缓冲时长Bmax,则等待且等待时长Δ=B(j)-Bmax,否则直接向服务器发送下一次请求HTTP Request,相关表达式如下:
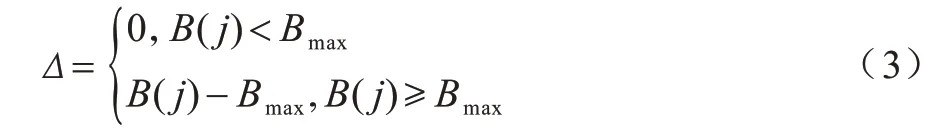
在传统DASH 系统中,各个视频片段采用基于HTTP 的渐进式下载模式,且在全部下载完成后才能回放。当下载下一个视频片段时,需重新发送请求HTTP Request,由于网络带宽的波动会触发DASH算法中的抛弃规则,因此会降低视频质量。
2.2 基于预测和缓冲状态的自适应算法
由于传统的DASH 算法未利用缓存状态选择相应的比特率,BOLA 模型仅根据当前缓存状态选择相应的比特率,而网络的动态性和基于HTTP 的渐进式下载方式会导致BOLA 触发抛弃规则,从而损失带宽利用率并降低视频质量,因此本文基于ABR算法使用有时间记忆的机器学习方法预测网络吞吐量,并建立基于缓冲时长和网络流量预测的决策模型,通过对网络吞吐量的有效预测减少抛弃规则的触发概率,从而提高用户体验质量。网络层阀门有遗忘阀门、输入阀门和输出阀门3 类。这些阀门可打开或关闭,用于判断网络的记忆态在该层的输出结果是否达到阈值,从而更好地预测网络流量。LSTM 网络是在循环神经网络(Recurrent Neural Network,RNN)结构的基础上增加各层阀门节点,其结构如图2 所示。
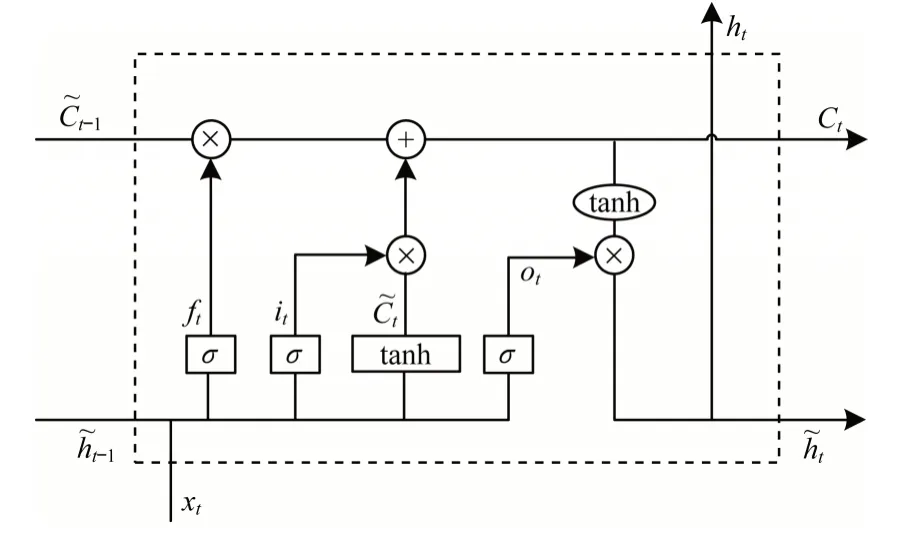
图2 LSTM 网络结构Fig.2 Structure of LSTM network
LSTM 网络具体处理流程如下:
1)采用Sigmoid函数控制遗忘阀门层,根据上一个时刻的输出ht-1和当前输入xt产生一个0 到1 的ft值,并利用上一个时刻学到的信息Ct-1进行计算,对部分信息进行去除或保留。ft的计算公式如下:

2)通过当前输入xt和上一个时刻的输出ht-1通知C需要更新的信息,包含两部分:(1)输入阀门层通过Sigmoid 函数确定需更新的信息值;(2)tanh 层用于生成新的候选值,其作为当前层产生的候选值添加到单元状态中,相关计算公式如下:
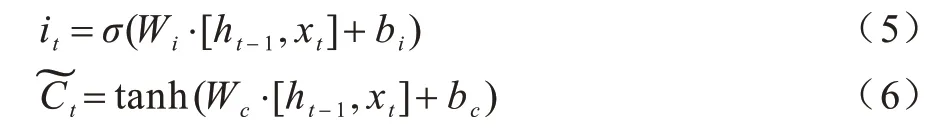
然后进行单元状态更新,将上一个时刻的单元状态乘以ft过滤冗余信息,再与相加得到候选值。
3)通过Sigmoid 函数获取初始输出,再与Sigmoid 函数得到的输出逐对相乘,从而得到模型的输出,计算公式如下:
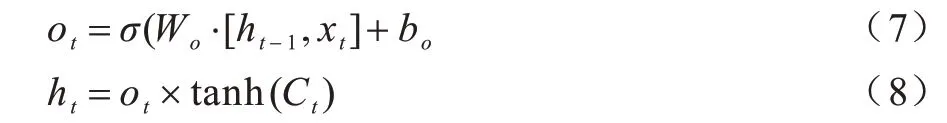
传统算法仅使用上一个视频片段的平均下载速率估计网络吞吐量来选择下一个视频片段的质量。本文DASH 系统使用SVR 和LSTM 模型预测网络吞吐量,结合当前缓存状态和优化模型选择合适的视频编码速率,同时在下载视频片段过程中通过预测模型实时预测网络吞吐量,以判定是否触发抛弃规则,进而决定是否放弃所选质量的视频片段,本文DASH 系统结构如图3 所示。
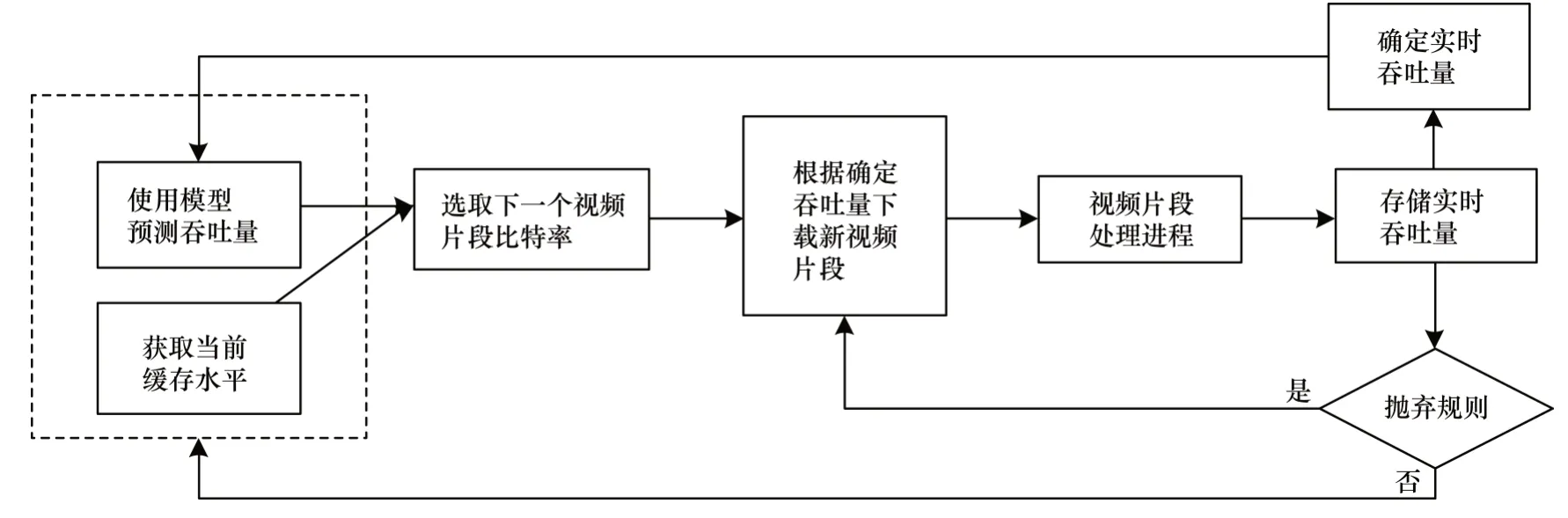
图3 本文DASH 系统结构Fig.3 Structure of the proposed DASH system
为确保用户体验质量最大化,根据预测的网络吞吐量bwest计算所有可选视频片段的下载时间估计值EDT,即∀ri∈ℝ,1≤i≤l,EDT=(ri×p)/bwest,并结合当前的缓冲状态B(j) 构建优化模型如下:

在当前缓冲状态下,采用合适的优化目标函数选择较高的视频质量,即下载时间估计值EDTj越接近当前缓冲时长B(j)越好。采用约束1 通过调节参数可实现缓存一定程度上的稳定性,约束2 可保证不出现再缓冲。
推论1由于B(j+1)=max[0,B(j)-EDTj]+p,为保证不出现再缓冲,应满足EDTj≤B(j),因此B(j+1)=B(j)-EDTj+p。
EDT 随缓冲相对稳定系数α的变化如图4 所示。可以看出,随着α不断增大(0<α1<α2<α3<1),EDT 曲线趋于平缓,表明当α较大时,缓冲相对稳定且视频质量较好。
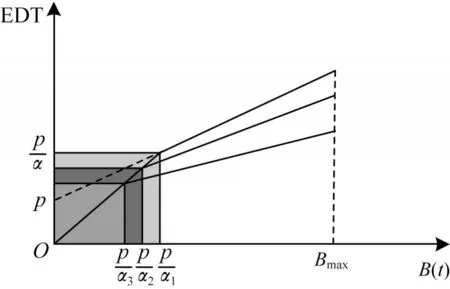
图4 EDT 随α 的变化Fig.4 Change of EDT with α
如果p-αB(j)>0,则0 ≤EDTj≤B(j);如果pαB(j)>0,则0 ≤EDTj≤p+(1-α)B(j)。约束2可修改为:
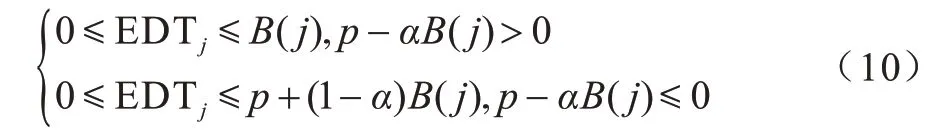
推论2当B(0)=0,B(1)=p,B(N)=0 时,得到:
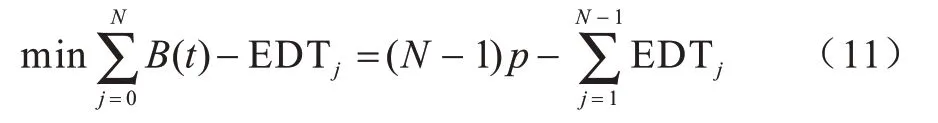
EDT 随缓冲时长B(j)的变化如图5 所示。可以看出,EDT 随B(j)的增长呈分段线性变化。当pαB(j)>0 时,选择的视频片段所需下载时长EDT 接近B(j),即会耗尽当前缓冲时长;当p-αB(j)<0 时,为保证所选下一个视频片段具有较高质量,不会完全耗尽当前缓冲时长B(j),EDT 增长减缓,即选择的视频片段质量较低。
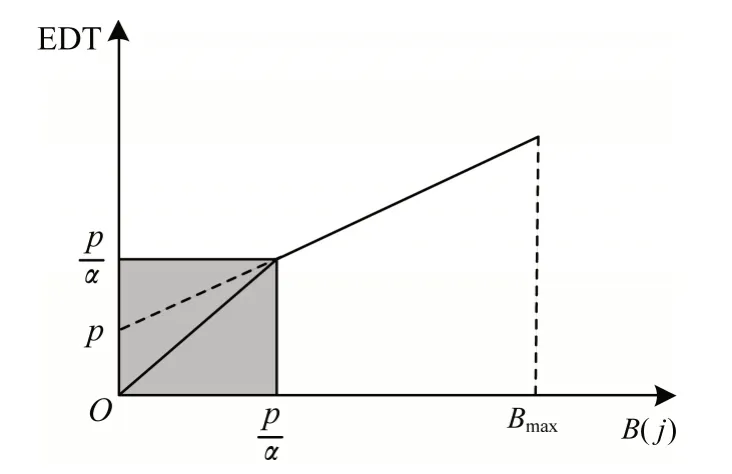
图5 EDT 随B(j)的变化Fig.5 Change of EDT with B(j)
本文DASH 系统算法如下:
算法1本文DASH 系统算法

上述算法具体步骤如下:
1)初始化速率
通过预先设定的Defaultr ∈ℝ 设置初始速率,根据量化函数q(rinit)选择相应的视频质量,等待下载。
2)下载监控阶段
实时监控下载过程的网络吞吐量并存储下载的网络轨迹信息,使用预测模型进行预测,相关表达式如下:

在初始阶段req.index=1,如果所选视频片段下载所需时间超过阈值,即ri1×p/recentthoughput >β×p(β为初始下载时间阈值系数),则抛弃当前所选的比特率,并根据当前网络吞吐量重新选择视频片段质量qi1=q(recentthoughput)。在非初始阶段req.index=j,N≥j>1,如果(Bnow为下载阶段的实时缓冲时长),则重新根据优化模型minimizeBnow-EDT选择视频质量。当视频片段完全下载后,根据优化模型minimizeBnow-EDT 选择下一个视频片段的质量,并通过质量量化函数q(rnext)得到相应视频质量并开始下载。为减少视频质量变动,假设当uqij-ulastquality>0.01(qij为以速率ri编码的第j个视频片段的质量)时,返回新的视频片段质量;否则保持原来的视频片段质量,重复执行步骤2。
3)调度阶段
如果B(j)>Bmax,则等待且等待时长Δ=B(j)-Bmax,否则直接向服务器发送下一次请求HTTP Request,表达式如下:
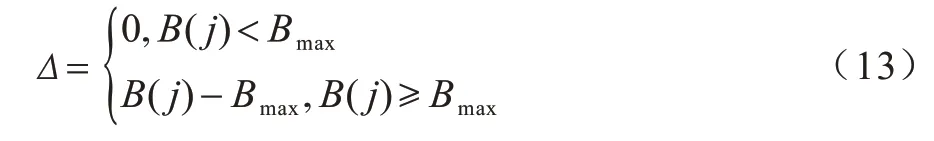
3 实验与结果分析
本文使用mininet2.2 平台构建网络拓扑如图6 所示。DASH 服务端使用Apache 软件,采用DASH 数据集[32]提供的视频片段Big Buck Bunny 进行测试,并根据DASH 提供的网络带宽描述文件,用网络性能测试工具Iperf 发送相应的动态流量作为背景流量。
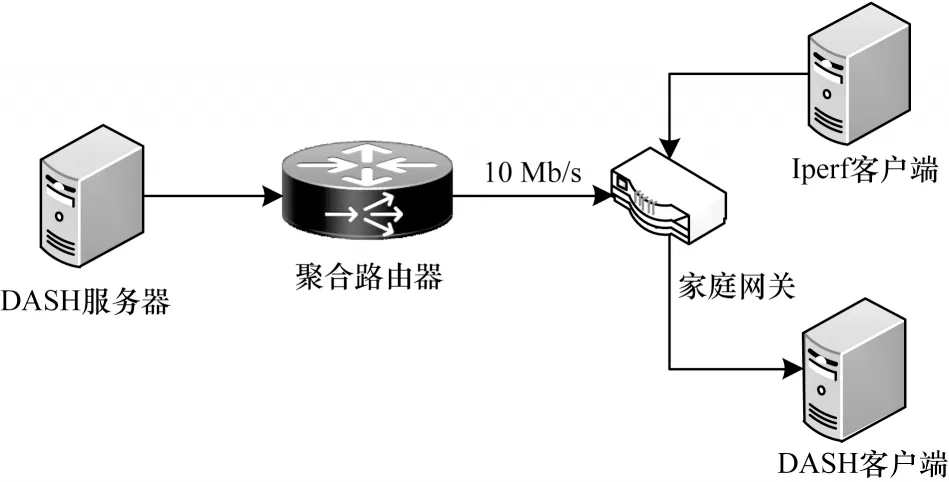
图6 网络拓扑Fig.6 Network topology
Big Buck Bunny 视频时长为600 s,被编码为5 种分辨率和20 种视频质量,视频片段间隔为10 s,划分为60 个视频片段,视频编码如表1 所示。采用SSIMPlus 评价指标作为不同编码速率下视频效用的客观度量。
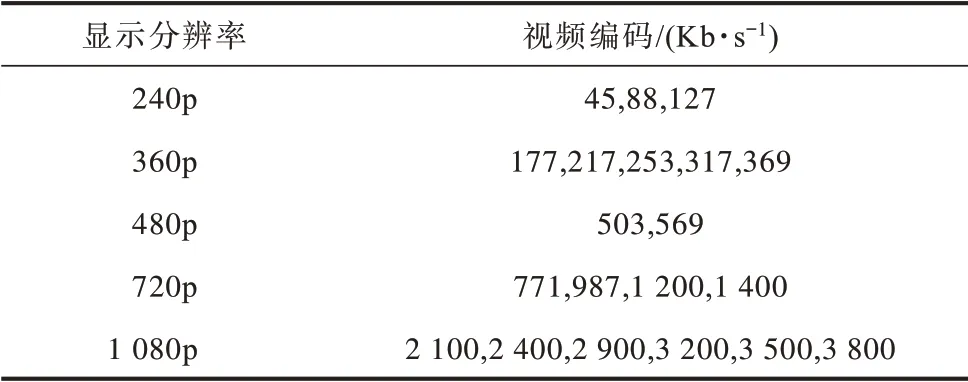
表1 Big Buck Bunny 视频编码Table 1 Big Buck Bunny video codings
对不同编码速率的Big Buck Bunny 视频进行线下客观质量测定,结果如图7 所示。可以看出,视频的客观质量随编码速率的升高呈非线性递增趋势。
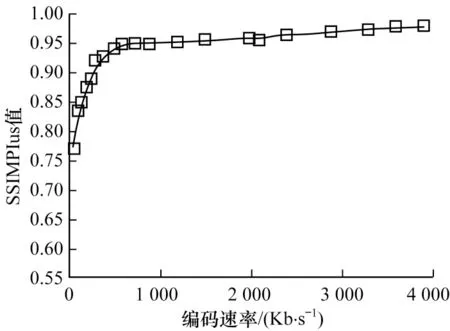
图7 Big Buck Bunny 的客观质量Fig.7 Objective quality of Big Buck Bunny
使用开源的DASH.js2.0 作为客户端视频播放器,采用Node-webkit.js 作为浏览器。由于DASH.js2.0适用于传统的ABR 算法和新兴的BOLA 算法,因此本文在此基础上进行扩展形成基于预测的自适应算法,并通过文件日志记录视频片段质量和重缓冲事件,具体参数设置如表2 所示。
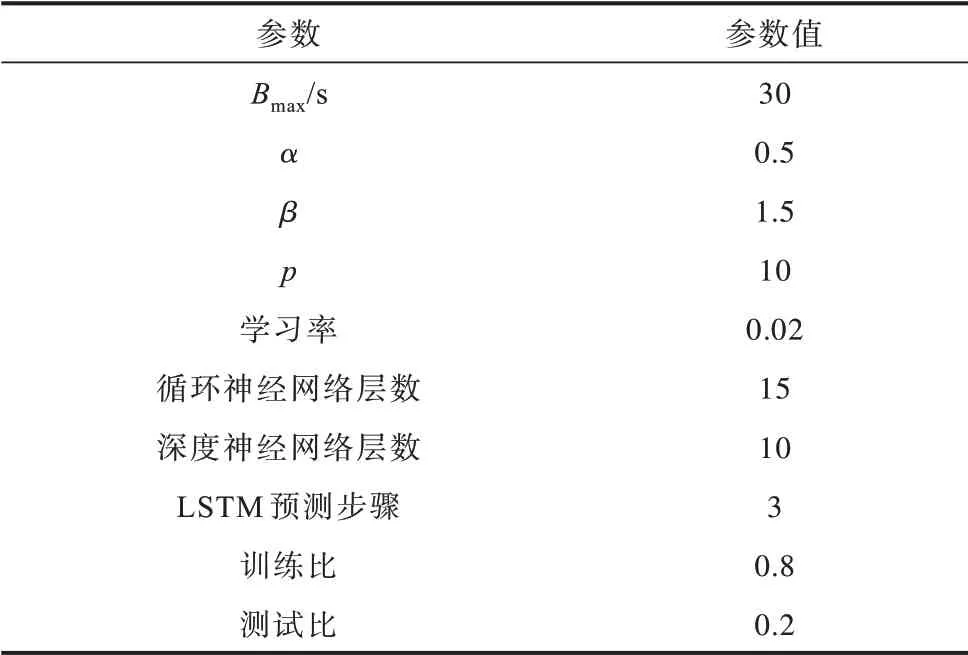
表2 实验参数设置Table 2 Experimental parameters setting
根据网络带宽描述文件使用网络性能测试工具Iperf 发送背景流占用带宽,并采用Mininet 平台仿真进行网络轨迹测试,每隔250 ms 采样一次,实验结果和带宽描述文件具体信息分别如图8 和表3 所示。

图8 不同网络轨迹测试指数下的吞吐量Fig.8 Throughput under different network trajectory test indexes

表3 带宽描述文件具体信息Table 3 Specific information of bandwidth description file
4 种不同算法得到的60 个视频片段的质量如图9所示。可以看出传统算法的视频片段质量的选择较平稳且质量较高,这是因为传统算法只根据上一个视频片段的下载速率来确定下一个视频片段的质量,并设置固定的下载阈值β×p,而本文设置β=1.5,表示当视频片段的下载时长估计值超过视频片段时长的1.5 倍才会触发抛弃规则,此时,客户端缓冲时长已被过度消耗导致发生重缓冲。
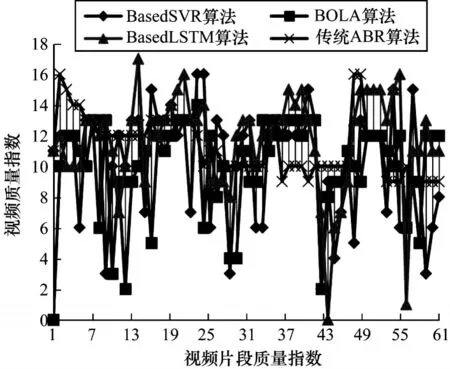
图9 4 种算法的视频质量Fig.9 Video quality of four algorithms
4 种算法得到的平均视频质量如图10 所示。可以看出基于LSTM 预测模型的自适应算法的平均视频质量最高,这是因为该算法不仅使用预测的吞吐量信息,还使用缓存时长作为算法的输入,当缓存时间较长时会选择较高的视频质量,同时实时监控下载阶段的网络吞吐量,当网络出现波动时触发抛弃规则重新适应网络状况。
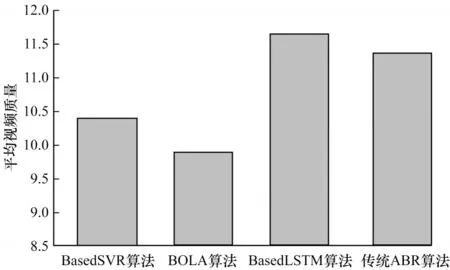
图10 4 种算法的平均视频质量Fig.10 Average video quality of four algorithms
4 种算法的重缓存率如图11 所示。可以看出,虽然基于LSTM 的ABR 算法平均视频质量最高,但其与传统ABR 算法均出现重缓冲现象。这是由于LSTM 算法在实际运行过程中预测时间约为1.5 s,不能进行实时预测,无法提前感知判断,因此导致出现重缓冲现象。BOLA 算法仅使用缓存信息动态选择视频质量,虽然未出现重缓冲现象,但由于其不能对网络吞吐量进行实时预测,导致提前触发抛弃规则,在一定程度上降低了平均视频质量。
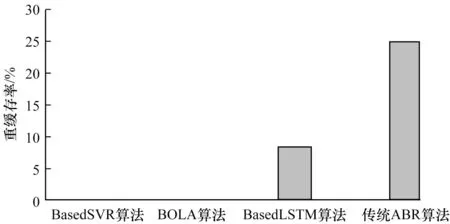
图11 4 种算法的重缓存率Fig.11 Recache rates of four algorithms
4 种算法的抛弃规则触发次数如图12 所示。可以看出,BOLA 算法触发了20 次抛弃规则,由于其在视频片段下载初始阶段提前认为网络变差不符合当前缓存需求,因此过早抛弃当前所选视频质量。结合图11 和图12 可知,本文基于SVR 的自适应算法综合表现最好,通过SVR 预测模型结合缓存状态选择的平均视频质量较高,同时通过实时在线预测减少了抛弃规则命中次数且未发生重缓冲。
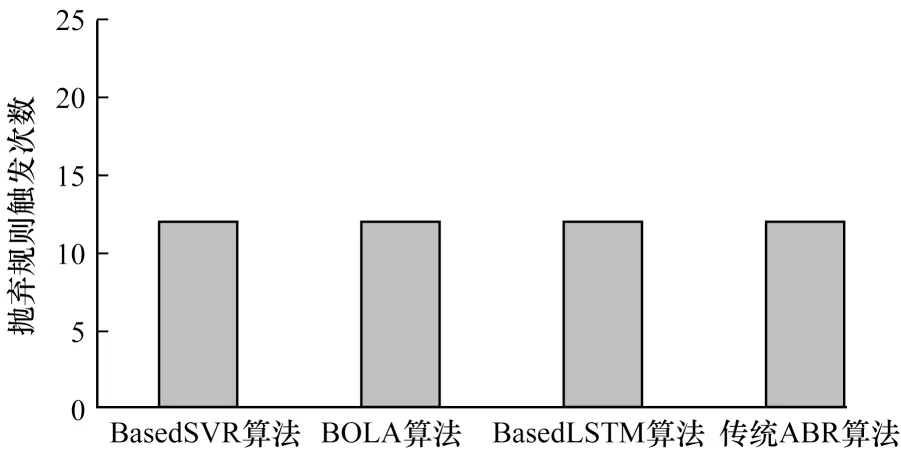
图12 4 种算法的抛弃规则触发次数Fig.12 Trigger times of discard rule of four algorithms
4 结束语
本文提出一种基于机器学习的改进自适应流媒体速率算法。在分析基于HTTP 动态自适应流媒体技术标准的基础上,利用机器学习方法建立网络吞吐量预测模型,并结合当前缓冲状态选择合适的视频质量,在视频下载阶段实时预测网络吞吐量,降低因TCP 慢启动提前触发抛弃规则的次数。实验结果表明,该算法可有效提高用户视频体验质量。随着软件定义网络和可编程网络等下一代网络技术的发展,网络将变得更加智能与可控,后续将结合机器学习和下一代网络技术进行研究,进一步提高网络吞吐量预测准确率。
