基于深度学习的Web网页信息标注方法研究
2021-05-16董亚男
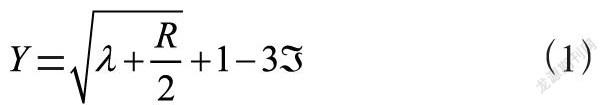
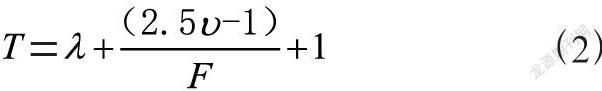

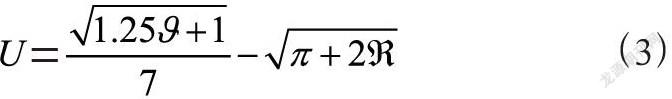


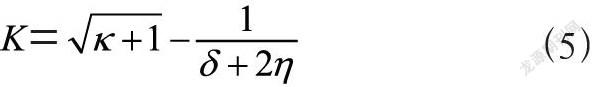

摘 要:为了提升网页信息标注的整体效果,同时降低标注失误的概率,通过三元组构造标注预处理,在深度学习技术下标注描述目标设定,设计深度重叠标注模型,在深度学习下通过逻辑回归实现Web网页信息的标注。相较于传统的特征提取标注测试组和传统的自定义标注测试组,文章设计的深度学习标注测试组最终得出的标注完成率相对较高,标注失误率相对较低,具有实际应用意义。
关键词:深度学习;Web网页;标注方法;深度控制
中图分类号:G202 文献标识码:A文章编号:2096-4706(2021)22-0089-03
Abstract: In order to improve the overall effect of web page information tagging and reduce the probability of tagging errors, the tagging preprocessing is constructed through triples, description goal setting is tagged under the deep learning technology, the deep overlapping tagging model is designed, and the tagging of web page information is realized through logical regression under the deep learning technology. Compared with the traditional feature extraction tagging test group and the traditional self-defined tagging test group, the tagging completion rate of the deep learning tagging test group designed in this paper is relatively high, the tagging error rate is relatively low, which has practical application significance.
Keywords: deep learning; Web page; tagging method; depth control
0 引 言
近年来,计算机技术和互联网技术的不断创新,极大地促进了我国网络环境的充分发展[1]。传统的互联网网页都是以关联静态的形式呈现的,同时网页中所承载的相关数据信息也是静态的,具有一定的稳定性,且大多数都是以HTML语言来书写,比较适合持续性阅读;另外,还有一部分网页,数据信息是以流动的形态存在的,且具有可下载的优势,当用户需要浏览或使用这部分网页中的数据信息时,可以通过特定的位置、按钮进行资料数据的检索及下载,而网页中的数据仍会继续存在,不会影响未来其他用户的使用[2]。
部分用户在应用过程中,需要对所阅读的内容做出标注,以此达到有序学习的目的。而传统的系统对于标注的设定较为单一,仅仅是对所阅读的段落或字数进行汇总整合,并做下脚标注,形式老化,缺少新意,虽然可以达到预期的目标,但在实际应用过程中,仍然存在一些问题和缺陷,给用户最终的使用带来较大的负面影响[3]。鉴于此,结合深度学习技术,进行标准方法的创新与优化。深度学习技术是一项较为严密的数据信息处理技术,近几年被广泛应用于各个行业,取得一定的成效。因此,深度学习技术可助力开发人员设计出更加灵活的标注方式,实现更为高效的处理效果。
1 Web网页信息标注方法设计
1.1 三元组构造标注预处理
在设计Web网页信息标注方法之前,需要先进行三元组构造标注的预处理。具体来说就是依据用户的需求,做出相应的结构创新。通常,网页后台均会设置自身的数据处理程序,同时也会配备一个数据库,数据库的作用不仅仅是提供资源信息,同时也会对相关的分词、语料以及词性进行相应的处理与标注[4]。这样在用户的实际应用过程中,一定程度上可以提升资料查询的速度与质量,方便于语句标注处理。可以结合Web网页自身的编辑结构,再加上对应的三元组构造模式,对资源库中的信息数据进行多重双向定位,每一组定位都需要设立独立的执行单元,同时可以结合标注实行分句处理。然而在此过程中,需要首先确定三元组的覆盖作用范围,并计算出三元覆盖系数,具体如式(1)所示。
其中,Y表示三元覆盖系数,λ表示覆盖范围,R表示三元处置指数,表示目标极限值。通过上述计算,最终可以得出实际的三元覆盖系数。随后,设定具体的构造标注处理范围,同时,根据实际情况与需求,进行三元预处理规则的描述。可以通过设定处理域的方式来划定相应的标注范圍,进而为后续的标注工作奠定基础。
1.2 深度学习技术下标注描述目标设定
在完成对三元组构造标注的预处理之后,接下来,需要在深度学习技术下标注描述目标设定[5]。可以先对Web网页中的信息资源数据库进行层级的划定,结合特定的信息抽取方法,将存在的文档关系形成预设的结构,在语句处理结构之中,建立词或词类间句法的关系,将标注的程序与执行的结构相融合,结合深度学习技术,设计深度自动化架构,但架构的设定不可以一味地遵循传统的标注描述方式,而是需要定期对架构内部的识别制度以及抽取规则进行更新,形成更加智能化的处理方式[6]。
基于此,将Web信息的抽取作为标注本体的核心,建立深度层级标注格式,根据分类层次、关系、函数、公理以及实例等划定控制范围,设定具体的描述目标,但是目标的执行也是独立单一的,这样做的目的是为了确保标注定位的精准性与稳定性,避免出现大范围的关联性故障[7]。将深度学习的层级与自然语言相融合,利用RDF的陈述模式对文章中标注的词语进行二次标注,此时,网页会留存相应的执行记忆,在这个过程中可以进一步完成对描述标注目标的执行与控制,进一步扩大了标注的范围。
1.3 深度重叠标注模型设计
在完成对深度学习技术下标注描述目标的设定之后,接下来,需要深度重叠标注模型的设计。通常情况下,在对Web网页信息进行标注的过程中,需要依据预设的结构设定(可以通过标注模型的规范来降低异常)。可以先依据用户的实际需求,划定具体的重叠标注范围,并计算出深度重叠系数,具体如式(2)所示。
其中,T表示深度重叠系数,λ表示双向应变指数,F表示预设标注时间,表示极限覆盖值。通过上述计算,最终可以得出实际的深度重叠系数。结合深度重叠系数设定深度重叠的网页标注范围,并设定具体的执行标注环节,具体如图1所示。
根据图1所示步骤,可以完成对执行标注环节的预设。可以在初始标注结构的基础之上,设计顶层的处理结构,分目标设定,确保在实际应用的过程中,可以深化标注的位置。
1.4 深度学习下通过逻辑回归实现Web网页信息的标注
在完成对深度重叠标注模型的设计之后,接下来,需要通过逻辑回归实现Web网页信息的标注。首先,在所建立的特定标注的模型中,设计相关的逻辑回归标注程序,在模型中设定相应数量的执行节点,根据编码,调整网页的处理极限标准,计算出交互的迭代回归指数,具体如式(3)所示。
其中,U表示交互的迭代回归指数,表示节点变化距离,π表示重叠范围,表示单一逻辑值。通过上述计算,最终可以得出实际交互的迭代回归指数,设立迭代逻辑回归范围,同时,根据相应的回归逻辑标注规则,构建与Web网页执行一致的深度作用结构。在深度重叠标注模型中,对文章中的标注划定层级,依据不同的目标标定对应层级的信息资源,提升整体的标注效果。
2 方法测试
本次测试的主要目的是对基于深度学习的Web网页信息标注方法应用效果进行验证与分析,测试共分为3个小组:第一组为传统的特征提取标注方法,将其设定为传统特征提取标注测试组;第二组为传统的自定义标注方法,将其设定为传统自定义标注测试组;第三组为本文所设计的标注方法,将其设定为深度学习标注测试组。在相同的环境下同时采用3组标注方法进行测试,测试的系统也一致,对得出的结果进行对比分析,最终完成方法的验证。
2.1 测试准备
在进行测试前,需要先搭建相应的测试环境。对所应用的网页标注特征进行提取设定,具体如表1所示。
根据表1中的数据信息,最终可以完成对应用网页标注特征提取的设定。随后,可以在网页中建立相应的依赖标注关系,主要是将网页标注结构与深度学习技术相关联,可以先计算出标注的路径距离,具体如式(4)所示。
其中,M表示标注的路径距离,α表示深度范围值,表示标注预设系数,d表示变化比。通过上述计算,最终可以完成对标注路径距离的测定。结合得出的数值,设定相应的网页标注路径,進行标注训练,可以在相同的网络环境下,依次训练3次,并记录下相应的训练结果。
设定消岐标注框架,所谓消岐标注主要是指用户在实际应用过程中,自动识别文章内部的歧义数据资源目标,消岐标注还会通过设定不同的框架和层级来分离划分,在用户对相关的数据信息做出标注时,系统会依据资料的层级进行单一标注,不同层级的标注均是不同的,具有一定的差异,体现在各个方面,例如颜色、大小、结构等,用以区分对应的资料重要程度。完成消岐标注的层级框架设定之后,进行实体测试资料的预处理。可以利用扫描装备来扫描文章,以特殊的格式将其导入系统的网页之中,随后,结合相应的架构,对标注的召回率进行分析,具体如式(5)所示。
其中,K表示对标注的召回率,k表示默认节点极限值,δ表示召回范围,η表示实际覆盖范围。通过上述计算,最终可以得出实际的标注召回率。
2.2 测试过程及结果分析
经过上述测试环境的搭建,接下来开始实施具体的测试。选取300名用户作为本次测试的目标对象,准备一份材料进行标注,预设需要标注的位置共45处。在测试的过程中,同时采用三种测试方法分别对100名用户进行标注测试。可以先对文章中相似度极高的词语进行排序,以避免对测试造成不同程度的影响。可以采用设立目标的方式实现,选取一个词作为单一目标,通过特区词语的特征,设定在识别的程序之中,结合排序的处理结构,关联成为一个更加精细的标注处理结构,同时还可以明确对应的标注范围。在所设定的范围之内开始测试,并对最终得出的测试结果进行对比分析,具体如表2所示。
根据表2中的数据信息,最终可以完成对测试结果的分析与验证。从测试结果分析可以看出,本文设计的深度学习标注测试组最终得出的标注完成率相对较高,标注失误率相对较低,具有实际应用价值。
3 结 论
综上所述,相较于传统的标注方法,本文设计的方法更加灵活多元,在面对复杂的网络环境时,可以通过多目标共同执行的方式来降低网页数据信息标注的实际误差。同时,在网页处理更改的过程中,深度学习还可以最大限度地保证网页的执行程度,以此来提升整体的应用效果。
参考文献:
[1] 陈前华,胡嘉杰,江吉,等.采用长短期记忆网络的深度学习方法进行网页正文提取 [J].计算机应用,2021,41(S1):20-24.
[2] 印杰,蒋宇翔,牛博威,等.基于深度学习的网页篡改远程检测研究 [J].南京理工大学学报,2020,44(1):49-54.
[3] 严靓,周欣,何小海,等.基于集成分类的暴恐图像自动标注方法 [J].太赫兹科学与电子信息学报,2020,18(2):306-312.
[4] 赵颜利,董博,雷燕.我国语义标注领域研究现状分析 [J].福建师范大学学报(自然科学版),2020,36(4):17-24+36.
[5] 桂思思,张晓娟,王鑫.查询歧义性程度自动标注指标的替代性验证研究 [J].数据分析与知识发现,2019,3(2):79-89.
[6] 俞鑫,吴明晖.基于深度学习的Web信息抽取模型研究与应用 [J].计算机时代,2019(9):30-32.
[7] 南楠.基于SPOC与深度学习的“网页设计与布局”课程教学模式重构 [J].内江科技,2019,40(8):62-63.
作者简介:董亚男(1987.05—),女,汉族,吉林长春人,讲师,硕士,研究方向:计算机系统结构。
