考场环境下考生视线估计方法
2021-05-14付飞蚺
柴 旭,方 明,2,付飞蚺,邵 桢
1.长春理工大学 计算机科学技术学院,长春130022
2.长春理工大学 人工智能学院,长春130022
分析监控摄像头采集的视频数据,对于各种应用场景下的异常行为监控具有重要作用。例如对犯罪分子的快速搜索和追踪、各类安全检测、指定位置的物品丢失、违章停车等[1]。其基本思想是运用计算机视觉技术从视频图像序列中进行目标提取、识别和分析并对其行为进行描述和理解,从而发现特定行为,并做出相应的应对措施[2-3]。考场中的视频监控目的是辅助监考人员发现考场中的各类异常行为。然而,考场中的监控摄像头往往设置在房间的一角,视场内的人员也较密集,这对基于传统方法的视频行为分析带来很大的挑战。基于深度学习的方法能够对这些不良因素有一定的鲁棒性,但是考生异常行为发生频率较低,训练中正样本远少于负样本,数据的收集、标注也比较困难[4-7]。
针对考场环境的研究,部分学者已经做了大量工作。蔺永政等人[8]提出的考场作弊行为检测方法,通过背景减除法获取考场中考生的运动图像,再采用迭代阈值法确定分割的最优阈值,以此完成考场中考生作弊行为的检测。但是由于背景减除法对于环境的要求和依赖性比较高,因此很难对异常动作进行较精准的判别。Cai 等人[9]提出采用深度学习技术对考生异常行为进行检测。首先利用三维卷积提取视频中考生的运动特征,对得到的特征进行网络模型的训练,当训练完成后,采用该模型进行考场异常行为检测,该方法中对较小幅度的异常动作识别率不高。
近几年,随着计算机视觉领域的不断发展,头部姿态估计[10]、视线估计[11-12]等方向也有了新的进展。其中Recasens 等人[13]提出了一种基于双路径的深度神经网络注视跟踪方法,该网络结构将头部特征和头部位置与场景内容结合起来进行训练,然而该方法对数据集中包含的信息类别要求较高,且容易受到场景内无关显著性特征影响。Recasens 等人[14]提出一种视频中视线估计方法,在上述模型中加入了路径转换用于将目标帧与源帧相结合,经注视估计路径得出预测的注视位置。Masse 等人[15]利用眼睛的注视与头部运动的相关性,在结合贝叶斯模型进行注视跟踪。但是此方法运算复杂度高,计算量大。Fan 等人[16]提出一种社交场景视频中的共享注意力推断算法,主要针对两人或两人以上的个体同时进行视线估计,预测出人们共同关注的目标。此算法并没有完全地解决视频中人们共同关注推断任务。Chong等人[17]在上述模型基础上引入多任务学习框架,在头部图像特征提取的路径后又加入俯仰角损失、偏航角损失来约束视线方向。然后对显著性特征图与视线方向进行融合得到预测的显著性特征图,最后计算预测显著性特征图与真实值的损失。Lian 等人[18]根据人们第三视角位置判断注视点的行为方式,提出一种单路径的视线估计方法。其过程是,通过头部图像推断出注视方向,再由注视方向上的场景内容估计出注视点。此方法相比其他视线估计方法在性能上有很大的提升,但其在复杂场景下视线估计时仍会严重受到场景中无关显著性特征的影响。
显然,视线估计方法对考生的头部行为特征检测适用性强,能对考场环境中考生左顾右盼、前后扭头等行为进行精准检测和分析,但多数方法均采用场景内显著性特征作为注视点位置的判断依据。由考场的复杂性决定,场景中的显著性特征区域未必是考生注视区域。本文参照现实中监考人员发现考生作弊行为的思维过程,提出一种考场环境中视线估计方法。通过多个场景的实验结果表明,应用该模型有效抑制了多数方法对数据集信息种类及场景内无关显著性特征的干扰问题。促进了视线估计领域的发展,为考场异常行为分析提供新思路。
1 考生视线估计算法框架
生成对抗网络(GAN)[19]的思想是同时拟合两个概率分布,第一个为生成器,将样本从简单的分布转换为更为复杂的分布,例如,把高斯分布的噪声转换成图像。第二个为鉴别器,用来区分真实分布的样本和生成的样本。
本文算法借鉴这种模式,但与上述模式有重要的区别。首先,为了包含图像中更多的视线特征信息,采用注视向量的形式表示视线,同时,这样还能更好地突出视线的大小和方向。其次,目标是从头部图像中生成出“真实”的注视向量。因此,生成器的输入是图像而不是随机噪声,其网络结构也不同。最后,鉴别器的输入分为两类,第一类为真实注视向量和头部图像,第二类为生成注视向量和头部图像,设计鉴别器结构为“双路并一路”;这样不仅使生成注视向量与真实注视向量变的不可区分,而且能让生成注视向量与对应头部图像中的视线方向更为一致。
本文中真实注视向量T(S,θR)是指考生实际的视线,生成注视向量G(S,θR)是指生成出的视线,两种向量均包含两部分。第一部分是考场中考生注视位置到此考生头部位置的距离(记为S),为注视向量的大小;第二部分是注视向量与水平方向夹角的角度,表示注视向量的方向(记为θR,为弧度)。如图1 所示。假设点L=(xL,yL) 为考生的注视位置,考生的头部位置为H=(xH,yH) ,考生的真实注视向量中S与θR由公式(1)、(2)计算得出。
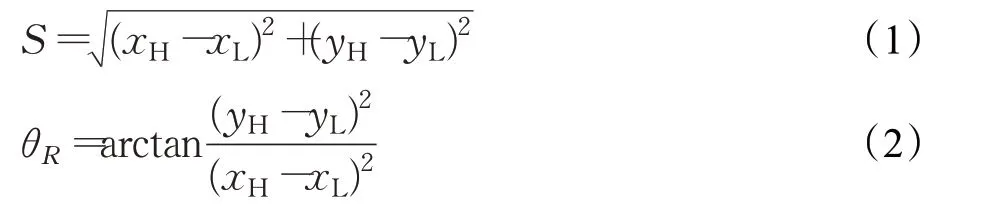

图1 注视向量示意图
考生视线估计模型由生成器(Generator)、视线合成模块(HG)和鉴别器(Discriminator)组成,网络结构如图2 所示。其中将考场中考生的头部图像(Headimage)作为生成器的输入,将考生的头部位置与注视位置输入到合成模块得到真实注视向量T(S,θR),然后把真实注视向量T(S,θR)与头部图像作为一类,生成器生成的注视向量G(S,θR)与头部图像作为另一类,分别把两类输入到鉴别器中,该网络模型整体为端到端结构。在训练过程中,使生成器与鉴别器形成生成对抗模式,得到可以生成真实注视向量的生成器模型。
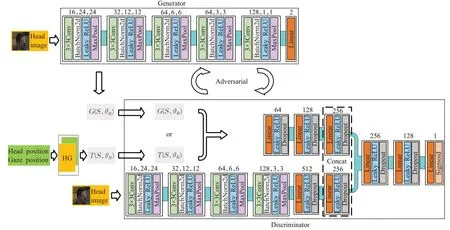
图2 视线估计网络架构
1.1 视线合成模块
为了更好地表示视线的大小和方向,减少图像中视线的信息损失,设计视线合成模块(HG)主要采用公式(1)、(2)对头部位置和注视位置进行计算得到真实的注视向量T(S,θR) ,然后把T(S,θR) 输入到鉴别器(Discriminator)。
1.2 生成器
生成注视向量G(S,θR)中S、θR由生成器(Generator)产生,本文生成器模型结构如图2 所示。前五层由3×3 卷积核、BatchNorm2d 层、LeakyReLU 激活函数及MaxPool 层组成,最后一层为Linear 层。该结构用于生成注视向量。输入图像为3 通道、大小为48×48。经过一次3×3卷积和池化后,得到特征图的大小为24×24,同时特征图的通道数增加到16;第二次卷积、池化后通道数为32,特征图大小为12×12;第三次后通道数增加为64,特征图大小降为6×6;第四次通道数没有变换,特征图大小减小到3×3;第五次后通道数为128,大小为1×1。最后经过Linear 层输出G(S,θR)。为了防止梯度消失或梯度爆炸,采用BatchNorm2d进行归一化处理。具体的网络模型参数如表1所示。
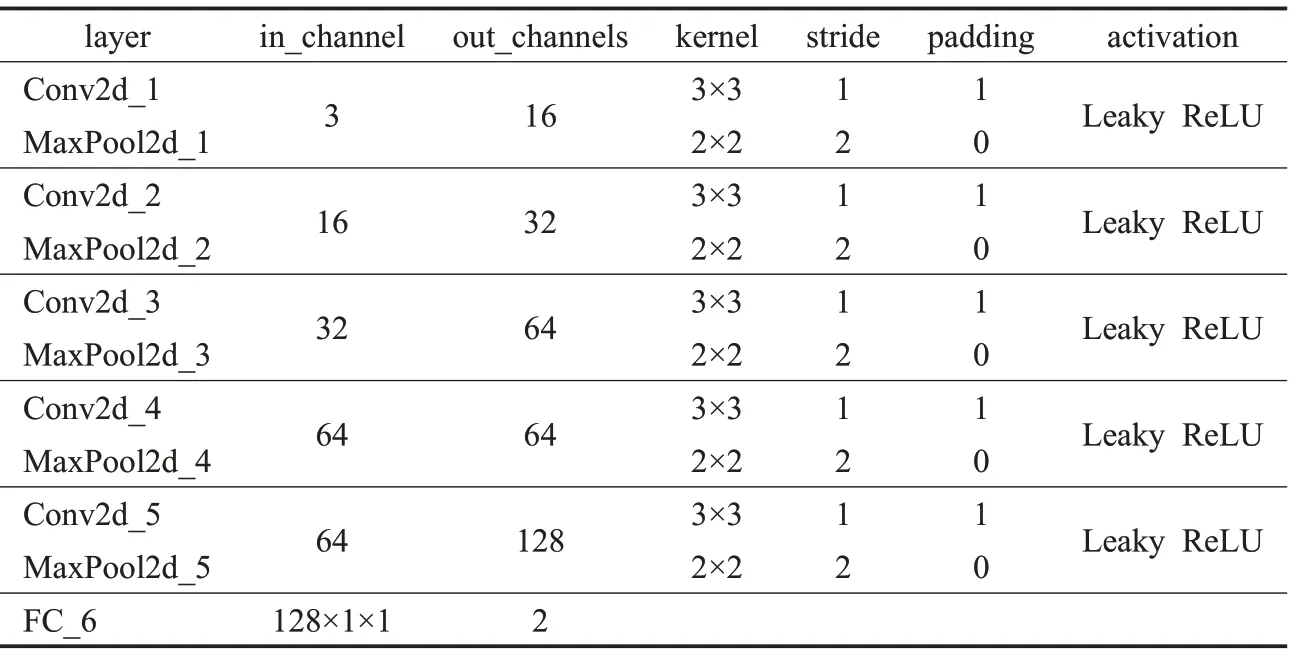
表1 生成器网络参数
1.3 鉴别器
鉴别器(Discriminator)网络结构共分为三部分,第一部分的设计是为提取头部图像中视线特征,其结构与生成器类似。为扩增G(S,θR)或T(S,θR)的大小,设计第二部分网络为三层,每层由Linear层、Dropout和Leaky-ReLU激活函数组成。上述两部分均输出一个256的一维向量。第三部分的设计是为输出真假的概率,首先是对两个256 向量的拼接,后经由Linear 层、Dropout 和LeakyReLU激活函数组成的两层,得到一个128的一维向量,最后一层由Linear 层、Dropout 和Sigmoid 激活函数组成,如图2 所示。为了有效防止模型过拟合,采用Dropout方法暂时丢弃一部分神经元。在最后一层采用Sigmoid 函数,它的输出范围是0 到1 之间,用于概率的输出。模型参数如表2所示。
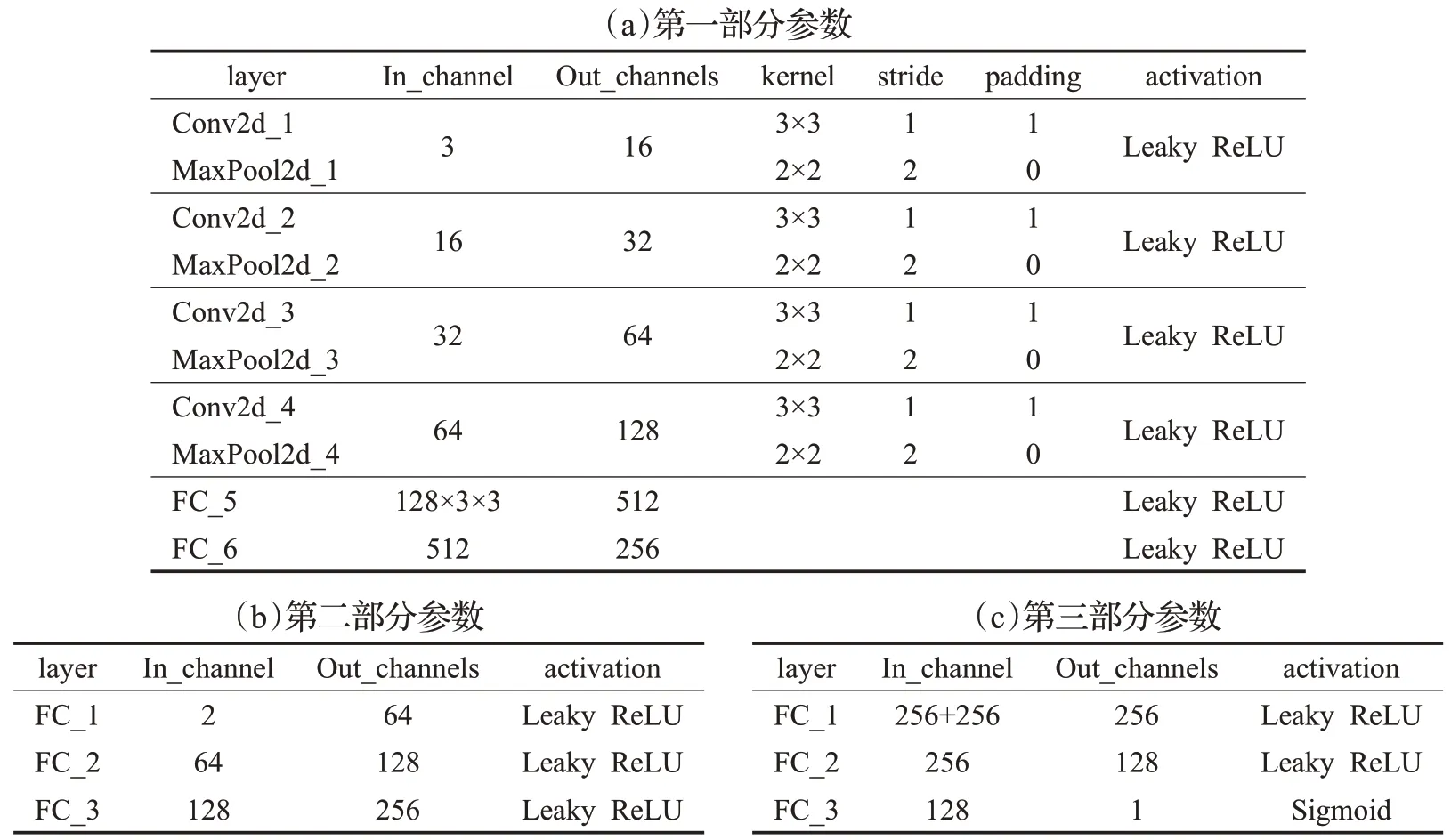
表2 鉴别器网络参数
1.4 损失函数
生成器损失如公式(3)所示:

其中,D表示鉴别器,G表示生成注视向量,I表示头部图像。L表示二元交叉熵损失函数,1 表示真实样本标签,0表示生成样本标签。这里希望生成器生成的数据越来越真实,所以在L(D(I,G),1)中标签值取1。
鉴别器损失如公式(4)所示:
4.1.2 喷气燃料冰点和结晶点检测重复性 对喷气燃料冰点和结晶点的检测结果重复性进行考察时,采用与柴油凝点检测相同的试验条件。研究过程中对长岭喷气燃料进行了4次重复性检测试验,结果见表9。
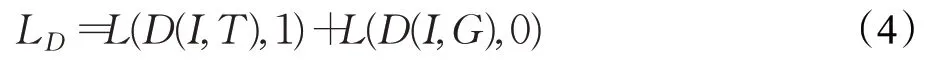
公式(4)中D、I、G、L与公式(3)中代表的含义相同,T表示真实注视向量。D(I,G)表示欺骗鉴别器的概率,鉴别器要区分出生成注视向量和真实注视向量,所以在L(D(I,T),1)中标签值取1,L(D(I,G),0)中标签值取0。
2 实验
2.1 数据集
为了验证算法在考场环境下的有效性,本文制作一个基于模拟考场的考生数据集。数据集中包含了25名考生志愿者和1 名监考教师。他们在考场环境中进行模拟考试,考生志愿者的动作分为扭头查看他人试卷、认真答题、观看教室中其他位置;其中作弊动作为扭头查看他人试卷,另外两个为正常动作。监考教师的动作是巡视考场发现考生作弊行为进行制止。在数据集标注过程中,根据每位志愿者对自己当时实际注视方向的描述标注出他们的注视点位置,确保数据的标注更具有真实性和可靠性。
随后,对监控图像通过Yolov3[20]进行头部检测,获得头部图像及头部坐标点;配合标注好的考生注视点,获得一个包含监控图像(Image)、头部图像(Head image)、头部位置(xH,yH)、注视位置(xL,yL)的数据单元。其中监控图像、头部图像如图3(a)、(b)所示,头部位置、注视位置可参考图1。本文数据集由2 000 个数据单元组成,其中训练集为1 800个,测试集为200个。

图3 数据集部分展示
2.2 实验与结果分析
实验环境为:NVIDIA GTX1060,Ubuntu18.04,CUDA10.1,Python3.7,Anaconda,Pytorch深度学习框架。
训练时,考生视线估计模型输入头部图像(Headimage)大小为48×48,训练次数(Epoch)设为300,每次处理64 个数据单元(Batch size=64)。由于网络模型为端到端结构,当网络训练完成后,只需要输入头部图像经过生成器就可以得到近似于真实的注视向量。
训练完成后,利用测试集对其进行有效性评估。该评估共分为两部分,第一部分验证所提方法在考场环境的有效性。第二部分是与视线估计方法针对考场环境进行比较。
根据真实注视向量T(S,θR)与生成注视向量G(S,θR)的夹角,对本文算法进行评估,如公式(5)所示。首先,根据G(S,θR)求出生成的注视点坐标;然后,把真实注视点坐标、头部坐标、生成注视点坐标代入公式(5)计算出夹角的弧度值α,以此评估算法的性能。显然,α值越小算法性能越优。
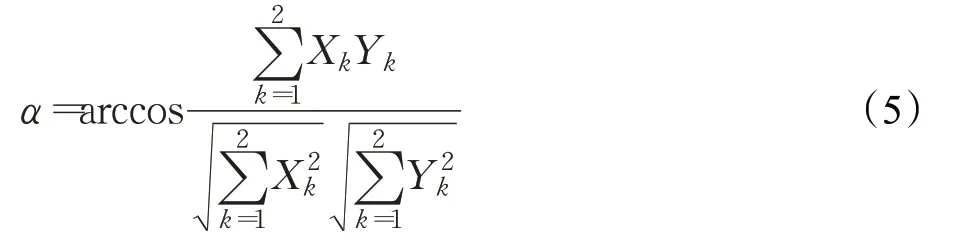
首先,对损失情况进行分析,找出最优权重大致所在的范围,然后,针对不同的权重对算法进行评估。损失曲线如图4所示。
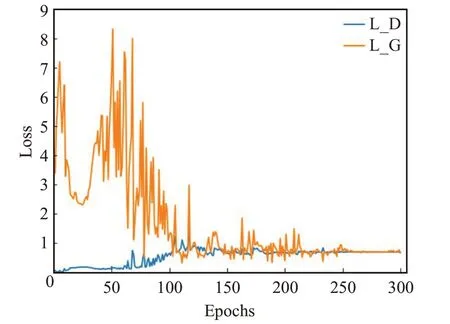
图4 损失曲线
图4 中L_D 表示鉴别器损失(初始纵坐标为0 的曲线),L_G 表示生成器损失(初始纵坐标为3.5 的曲线)。从中可以发现Epoch在[0,130]范围时,生成器损失下降比较快,浮动较大,鉴别器损失呈现平稳且缓慢的上升趋势。当Epoch逐渐增大时,生成器损失下降缓慢并且震荡幅度减小,鉴别器损失也为下降趋势,但幅度很小。在[150,250]范围内鉴别器损失、生成器损失处于逐渐趋于收敛的情况,Epoch 在250 次以后生成器损失与鉴别器损失几乎重合到一起,均没有出现大幅度的波动,其生成对抗模式接近最优。综上,可以确定Epoch在[0,130]范围时模型没有收敛,所对应的权重不是最优。然后,对Epoch从130到290的权重进行验证,找出其中的最优权重,分析模型的整体情况是否出现过拟合。
根据上述分析,针对不同Epoch 所对应的权重,在测试集进行算法验证。统计出α的最小值、最大值、平均值,测试集总数为200,具体如表3所示。
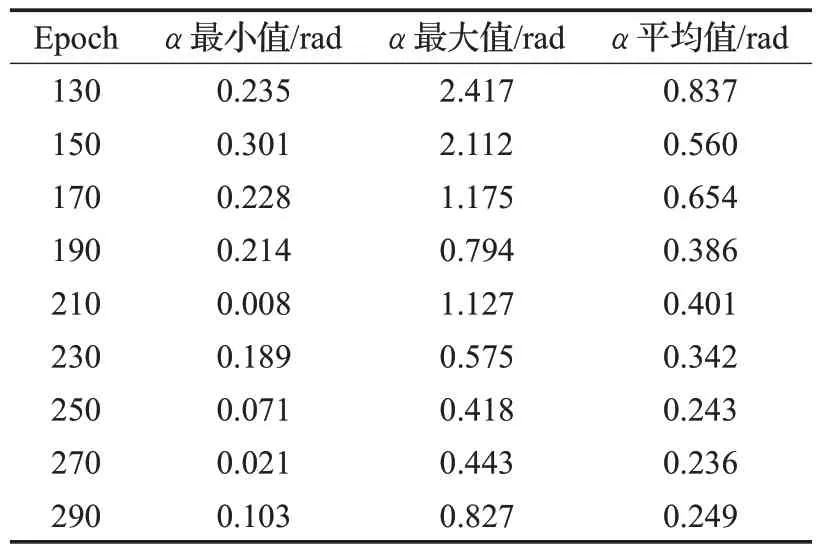
表3 不同权重算法性能情况
根据表3 中数据表明,随着Epoch 的增加α的平均值整体呈下降趋势,其中也有异常值出现,但对整体影响不大,说明模型没有发生过拟合。α的最小值、最大值、平均值均为值越小算法性能越优,模型的表现越好,在Epoch为270时对应的权重最优,算法表现最好,α平均值为0.236 rad,最大值为0.443 rad,最小值为0.021 rad,综合分析可知,本文考生视线估计模型生成注视向量与真实注视向量之间偏差较小,在考场环境下是有效的。
图5(a)是模拟考场环境下考生视线估计情况,其中,红线(浅灰)表示的是生成注视向量,黄线(明亮)表示的是真实注视向量。左侧第一幅图像为摄像头在右上角情况,左侧第二幅图像为摄像头在左上角情况,右侧第一幅图像为摄像头在正前方情况,右侧第二幅图像为摄像头在左上角情况。从中可以发现在不同视角下的头部图像,经本文生成器输出的生成注视向量与真实注视向量之间角度误差较小,算法整体效果较好。也说明了本文采用5 个3×3 卷积层与LeakyReLU 激活函数组成的生成器,能提取更为丰富的特征,同时,也增加了网络的非线性表达能力,有效减少了生成注视向量中视线信息的损失,使生成的生成注视向量更为真实。
图5(a)中4幅监控图像中均存在一些遮挡情况,很难获取考生的面部特征以提取视线。此类难题最能体现出本文算法的优势。其中,提出视线合成模块来得到真实注视向量,将其作为真实数据输入到鉴别器中,以此来更好地训练生成器模型。设计鉴别器的两类输入分别为:真实注视向量和头部图像组成的真实数据,生成注视向量和头部图像组成的生成数据。此结构相比其他单输入的鉴别器,增加了头部图像处理部分,以此来增加视线特征。同时,也增加了网络深度,提升了网络非线性表达能力。通过这种方法来提高鉴别器判别真实数据和生成数据的能力,促使生成器产生更接近真实视线的生成注视向量。通过上述的改进,即使头部图像中存在一些遮挡情况,生成器也能生成出与实际视线最为接近的生成注视向量。从图中可以发现,大部分生成注视向量与真实值较为接近,整体误差情况较小,证明本文算法能有效解决此类难题,也说明了模型具有较好的鲁棒性。但是不排除有一些与真实值偏差较大的情况发生。
为了更好地观察和分析出现偏差的原因,单独对不同方向的视线进行整理,随机选出其中的27张照片,如图5(b)所示,共分为视线向右、视线向下、视线向左三个方向。图中可以看出,第一排视线朝右和第三排视线朝左时的整体偏差无法稳定在一定的范围内,第一排最后三张图像视线估计偏差较大,最后一张图像基本上没有面部特征信息,虽然偏差较大,但是方向朝向与实际视线方向基本上相同,第三排5、7、8、9这四张图像中视线估计也存在偏差较大的情况。第二排视线向下的情况优于其余两排,整体偏差较小。
通过调查分析得出,偏差较大的情况主要是由于标注真实注视点位置时,每个人认为的注视位置不同,从而导致真实视线方向各有不同,因此会产生标注误差。
2.2.2 算法比较
为了进一步评估算法在考场视线估计中的性能,基于自制考场数据集将本文算法与SVM+shift grid[13]、Recasens[13]、Lian 等人[18]提出的算法进行对比,如表4 所示。Lian等人的算法具体为:首先通过头部图像预测出视线方向,生成多尺度视线方向场,然后将多尺度视线方向场与图像内容结合生成显著性特征,以此预测出注视位置。

图5 模拟考场考生视线估计情况(黄线:真实注视向量,红线:生成注视向量)
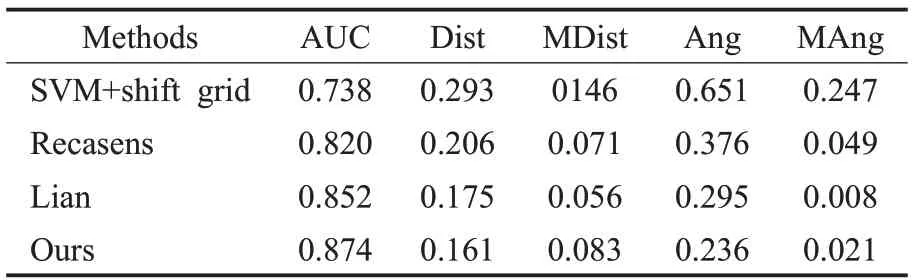
表4 算法评估指标
评估算法性能时采用AUC、Dist、MDist、Ang、MAng等指标[18]。AUC表示ROC曲线下面积,其值越接近1算法性能越优,最大值为1;Dist为预测注视点与真实注视点之间欧几里得距离的平均值,其值越小算法性能越好;MDist是预测注视点与真实注视点欧几里得距离的最小值;Dist与MDist中先对图像进行归一化;Ang表示预测注视向量与真实注视向量之间角度误差平均值;MAng 为预测注视向量与真实注视向量之间角度的最小值;Ang和MAng的单位均为弧度(rad)。
由表4 可知,本文算法在AUC、Dist、Ang 指标上优于对比算法,其中在Ang指标上本文算法比Lian等人算法减少了0.059 rad,Dist 其值越小算法越优。在考场环境中本文算法优于所对比的几种算法。
图6是两个算法的效果对比图,左侧列为Lian算法结果,右侧列为本文算法结果。蓝线(深黑)表示的是Lian算法预测的注视向量,黄线(明亮)表示的是真实注视向量,红线(浅灰)表示的是本文算法生成的注视向量。从图中可以直观地发现左侧列中黄色线与蓝色线夹角偏大的居多,有的黄色线与蓝色线成两个相反方向,误差较大的情况居多。左侧图一中由左至右第一排中两名考生均为误差较大的情况,第一名考生的视线估计情况误差最大,预测视线与实际视线成两个相反方向,第二名考生的注视区域为第二排第二名考生所在区域,预测区域与实际情况不符。同一环境中右侧图一中这两名考生的视线估计情况误差均很小。因此本文算法优于Lian 算法,对Lian 算法中误判情况进行如下分析。

图6 视线估计对比情况(左:Lian算法,右:本文算法)

图7 Lian算法误判情况(左:视线估计,右:显著性特征)
在图7(a)左侧中第二排第一名考生,该考生的实际视线为黄线(明亮),预测的视线为蓝线(深黑)。在图7(a)右侧显著性部分中白色区域表示的是该考生注视的显著性特征,显著性特征的区域是该考生自己桌面的答题区域,而实际注视区域是他人桌面。此算法对考生进行视线估计时容易受到场景中其他显著性特征的影响,如其他考生、考场中的桌椅、考生的文具等。在复杂的考场情况下,显著性特征有时会干扰视线估计的准确性,因此会造成误判。图7(b)中误判情况与上面基本一致,显著性特征定位的区域是照片中粉色书包所在的最后一排,实际的注视位置是在自己桌面上的试卷区域,预测视线与实际视线成两个相反方向。可以得出此算法对考生进行视线估计时容易受到场景中无关显著性特征的干扰。
上述实验证明了本文算法在考场环境的有效性,也验证了本文算法能有效避免无关显著性特征造成的误判情况,在AUC、Dist、Ang评价指标上优于目前几种视线估计算法。综上,说明本文算法具有鲁棒性。
3 结论
文中提出的考场视线估计方法,采用注视向量与生成对抗模式相结合进行考场视线估计。实验结果表明,可以有效地减少人工筛查的工作量。该算法为解决考场环境下异常行为检测问题提供了新的思路。极大地促进了视线估计领域的发展。
实验结果证明:在考场数据集中本文算法优于所对比的几种算法,其中与Lian 等人算法相比Ang(Angular error)和Dist(Euclidean distance)指标上分别有效降低了20.3%和8.0%,AUC(Area Under Curve)提升了2.6%。
经实验证明本文算法在考场环境下具有鲁棒性、有效性,基本上达到了预期目标,但还有一些不足之处。例如,生成注视向量与真实注视向量还是有一些偏差,主要体现在视线的大小(长短)方面。人为标注的问题。缺少对于考生肤色问题的研究,比如黑人考生的头部图像。
未来的研究将以解决上述问题为主,并将本文算法应用于考生异常行为检测中。同时也将展开针对人与人之间互相交流时视线情况的研究。
