目标多种多值属性的端端快速识别网络
2021-05-14周伦钢孙怡峰黄维贵李炳龙
周伦钢,孙怡峰,王 坤,吴 疆,黄维贵,李炳龙
1.河南省工业学校,郑州450002
2.信息工程大学,郑州450001
3.郑州信大先进技术研究院,郑州450001
目标属性识别是指对图像或视频中特定物体目标外观特征的识别。例如,对图像中的行人,其性别、年龄段、衣着颜色、携带物品等外观特征属性需要进行识别;对图像中的车辆需要识别品牌型号、颜色、拍摄角度等属性。目标属性识别的研究具有很高的价值[1-2]。在科研方面,目标属性识别对于跨摄像头跟踪的研究具有重要的促进作用。在应用方面,目标属性识别可以应用在公安刑侦、寻找涉案车辆、丢失老人儿童等各类场景。
目标属性识别近年来主要采用深度学习方法。文献[3]针对行人目标的不同属性训练多个卷积神经网络,每种网络分别提取对应的属性特征。文献[4]将每种人体属性视为一个二分类问题,采用特征共享的方式,通过CNN提取目标特征,然后使用多个分类器用于不同属性识别。Sudowe 等[5]采用了联合训练实现了基于深度神经网络的多属性识别。Li 等[6]提出DeepMAR网络考虑了不同属性之间的相关性,改进的交叉熵损失函数促进提升神经网络的学习效果。Han等[7]提出一种针对行人属性识别的Pooling 方法,它整合了不同区域属性的上下文信息。Lin 等[8]采用残差网络提升了行人属性识别的效果。上述研究多是以直接拥有仅包括目标物体的图片为基础。而在现实应用中,目标属性识别是一个综合问题,例如在监控摄像头场景下,首先需要计算机从画面中检测到物体目标,然后再进行目标的属性识别,整个过程是全自动的,因此是一种端到端的目标属性识别;第二,目标的属性往往有多个取值,即多值属性,而现有研究往往将属性识别简化为多个二值分类问题,使用多个分类器,导致运算量很大;第三,目标的多值属性往往有多个,若进一步使用多个分类器,将导致时间消耗过大。
针对上述问题,本文提出一种目标多种多值属性的端到端快速识别算法。首先利用目标检测网络,确定大类物体目标的方位(boundingbox 框);然后依据物体方位,共享深层次特征,构造针对多值属性的子网络,进行多分类,确定属性取值;依据属性独立特性,设定子网络个数,实现多种属性识别;在训练过程中,三阶段采用了不同的目标函数(loss 函数),分阶段分目标进行训练。实验结果表明,在保证多种多值属性识别效果的前提下,本文的深层网络提高了运算效率,为实时应用打下了基础。
1 算法框架
1.1 网络总体结构与推断过程
当前研究比较成熟的是端到端的目标检测,Faster RCNN[9]为两阶段目标检测的典型代表,SSD[10]和Yolo[11-13]系列算法为一阶段的典型目标检测算法。可以将具有不同属性值的目标视为不同种类的物体,检测定位到某种物体目标,同时获得其属性值。但是,多种属性存在并且每种属性又有多个属性值的情况,将使每种物体的样本变得相对很少,这给训练带来了困难,导致识别准确度低。例如,若想识别车辆的品牌型号属性、颜色属性和拍摄角度等属性,需要将品牌型号、拍摄角度、颜色不同的车都单独标注成一种类别目标物体,这将导致目标类别非常多,而每种类别的样本就显得非常少。
本文针对目标多种多值属性的识别问题,首先采用目标检测,确定大类别目标物体的包围框(boundingbox),这里的大类别目标物体指行人或车等;再由boundingBox 提取目标全范围(非局部)的特征,依据上述特征识别各个多值属性的取值。可以采用多个单独网络分别进行,如YoloV3[13]检测网络进行物体检测获得boundingbox框,其他单独训练的分类网络(如ResNet[14])根据boundingbox框确定的图像区域,重新提取特征,进行属性识别。无论从训练角度还是从推断角度,上述方式的计算量都非常大,本文提出将检测网络与分类网络合并,进行端到端(End to End)的训练,从训练和推断角度都提高了速度。
在YoloV3 基础上进行修改,增加了用于属性识别的子网络,实现端到端的推断与训练。YoloV3 网络结构如图1 所示,首先输入图像缩放为416×416(等比缩放,长边为416,短边居中,旁边补白色),采用不带全连接层的Darknet-53 网络[13]作为骨干网络提取特征,DBL处理代表了两次3×3 卷积、批归一化(Batch Normalization,BN)和Leaky Relu激活。resN代表了进行了N轮残差,每轮残差由1×1 卷积和3×3 卷积(含BN 和Leaky ReLU激活)以及short cut连接组成。DBL和resN中各卷积核尺寸与卷积核个数的详细情况,如图2所示。
由图1和图2可见,416×416的图像进入Darknet-53网络后产生3 个分支,图3 给出了一幅图像经过这3 个分支的特征图示例,从中可见第三分支特征提取层数最深,卷积运算提取的特征也最抽象,第一分支层数相对较少,特征图中还能看出汽车的一点痕迹。

图1 YoloV3的推断网络结构
在YoloV3中,3个分支的特征图又分别经过一系列的DBL 处理、上采样以及合并(concat)、DBL 处理等操作。在进入最后一次卷积前,3个分支的feature map尺寸分别为52×52×256、26×26×512、13×13×1 024。这相当于对输入图像进行了不同粒度的网格划分,第一个分支粒度最细,对应了52×52个网格,每个网格有256维特征向量;第二个分支的粒度折中,总共有26×26个网格,每个网格有512 维特征向量;第三个分支的粒度最粗,总共有13×13 个网格,每个网格有1 024 维向量来表征其特征。接下来,3个分支feature map均进行1×1核的卷积,本次卷积后的激活函数为sigmoid。YoloV3中1×1卷积核的个数为3×(5+num_class),它代表了每个网格将基于3 种尺寸anchor(以网格区域为中心的特定尺寸矩形框)进行输出,每种anchor 对应的输出有(5+num_class)个,这里“5”指输出boundingbox的4个坐标值及其为前景的置信度,“num_class”为目标类别数,指还要输出boundingbox是否是num_class个类别的概率值。
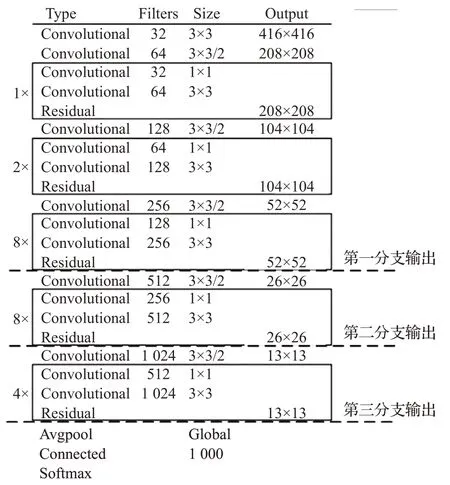
图2 Darknet-53网络的卷积层参数
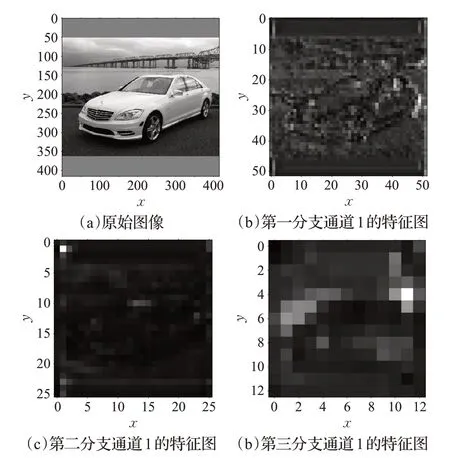
图3 Darknet-53网络3个分支的卷积特征图
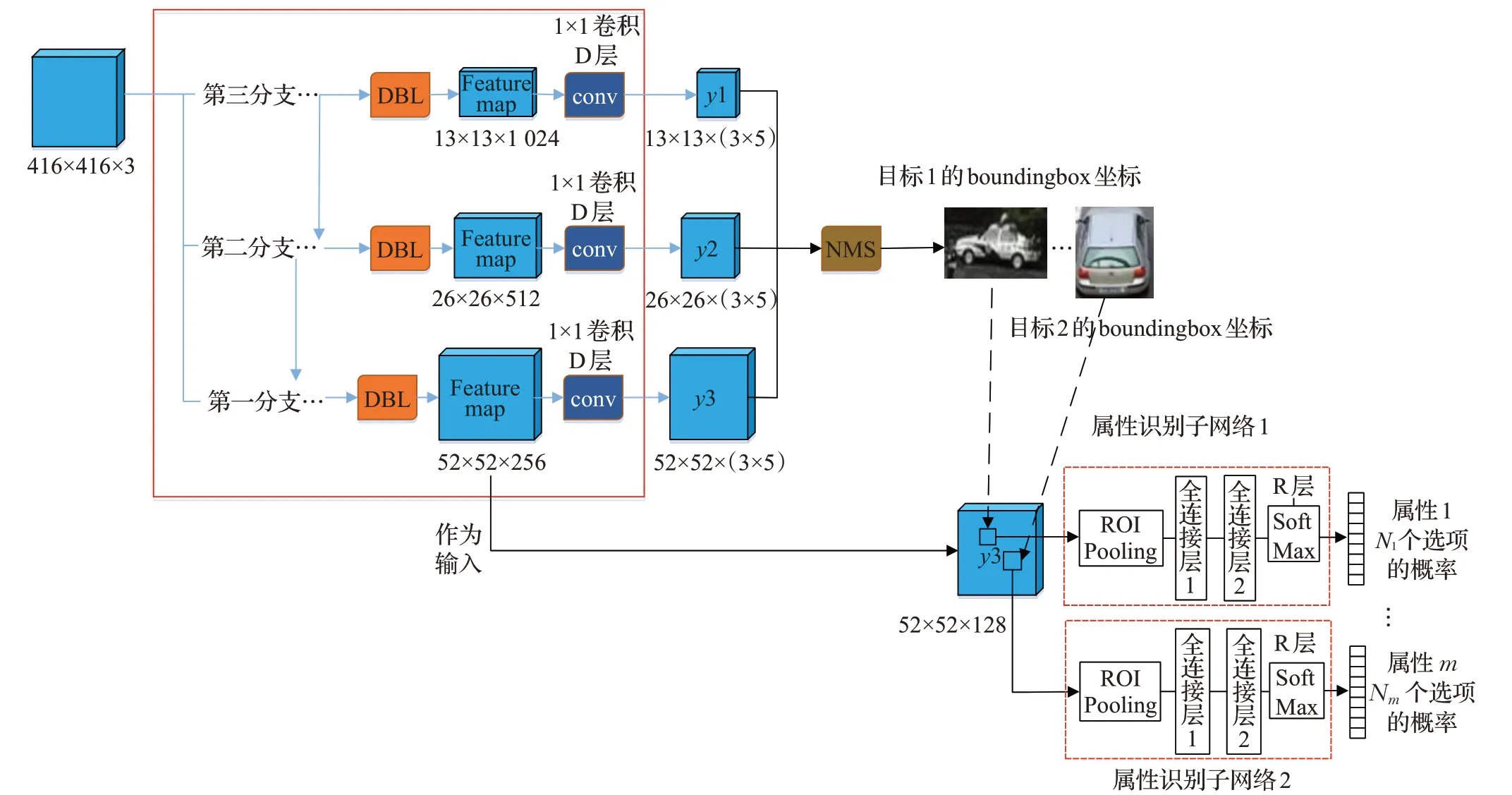
图4 端到端属性识别网络结构
由于本文限定需要属性识别的目标都属于一个大类别,如车辆,将YoloV3 中1×1 卷积核的个数3×(5+num_class)修改为3×5=3×(1+4),形成图4 所示的网络结构。这里num_class=0,前景置信度就是boundingbox的置信度。这样,算法将得到3×(52×52+26×26+13×13)个候选boundingbox 及其置信度。以置信度大于0.3 以及其位置不超出图像边界为条件,来进行初次筛选候选boundingbox;剩余的进行非极大值抑制(NMS)处理,剩余的boundingbox 是需要识别属性的目标。在图4 中,将目标boundingbox框坐标和上述52×52×256的feature map作为多值属性识别子网络的输入,每个子网络均从boundingbox 对应的feature map 区域中取出特征数据,预测某个属性取值,由于共享了深层特征,将大大提高运算速度。首先采用Roi-Pooling 层[9]获取相同维数的神经元,然后采用两层全连接处理,最终采用softmax输出各个属性值(选项)的概率。第一个全连接的神经元个数为2 048,后一个全连接的神经元个数由多值属性取值的个数决定。
由上可见,本文采用端到端网络(图4)有两次重要的输出,一次是进行1×1卷积,预测boundingbox的置信度和位置;一次是用SoftMax 处理得到boundingbox 确定目标的属性选项值的概率。为了方便叙述,下面将1×1 卷积处理称为D(Detection)层处理,将SoftMax 处理称为R(Recognition)层处理。
1.2 待识别属性的构建与属性标注
一个物体往往有多种属性需要识别,有些属性是相互独立的,如车的拍摄角度就与品牌型号相互独立;有些属性间是存在依赖关系的,如通过品牌型号往往可以直接推出车型属性值,当识别出品牌型号属性取值为Audi Q5时,就由知识库可以直接推断出其车型是SUV。
本文选择相互独立的属性用于识别,目标物体有多少种属性相互独立,就对应构建多少个子网络,各子网络输出神经元个数由属性值的个数决定。例如,对车辆目标,假设有拍摄角度、品牌型号、颜色等3种相互独立的属性需要识别,则对应了3个一级子网络。根据各个子网络的输出值,将其经过Softmax 归一化处理得到各个属性值的概率,取最大(Top-1)或Top-N 就可获得目标物体各个属性的预测。这里需要说明的是,对现实商业中的特定车型,其颜色往往在特有范围内,颜色属性与车型属性有一定依赖关系,但现实中也存在个人改装、重新喷涂原有车型没有颜色的情况,导致存在车型与颜色相互独立的情况,因此这里将颜色作为多种相互独立属性之一举例是合理的。此外,车辆颜色也可以在车辆位置确定后通过颜色直方图进行推断,但本文探讨的神经网络识别颜色属性在工程应用中可以作为一种补充。
前面叙述了目标物体属性的推断框架,为了获得网络各层的参数值,需要进行训练,这里先叙述多独立属性下样本的标注方法。YoloV3目标检测可以采用如下标注方法:

首先是图像文件名,然后是图像中目标Ground Truth(下面简称为GT)所在的boundingbox 的4 个坐标以及类别。上例子中第一个图像有两个目标,第二个图像有一个目标。
本文假定只关注一大类目标,可省略类别,在GT boundingbox 的4 个坐标后面顺序标注各个属性的属性取值。以前述的品牌型号、拍摄角度、颜色属性为例,先标注品牌型号属性,再标注拍摄角度属性和颜色属性,得到如下标注:

其中36、116、868、587是4个坐标值,接下来的4代表拍摄角度属性的取值为前侧部,12代表品牌型号属性取值为VW Passart 8 Sedan(大众第八代帕萨特三箱),8 代表颜色为白色。为此,可以构建品牌型号、拍摄角度、颜色与数字的对应关系表,这里不再赘述。
2 训练过程
2.1 依据标注获取输出的期望值
本文端到端推断的输出包括两个部分,如图4 所示,一个是在D 层1×1 卷积处理后的输出,一个是在R层softmax处理后的输出。需要根据标注分别得到这两部分输出的期望值,从而为构建Loss函数、进行训练做准备。
第一部分,输入图像在D层处理前为13×13×1 024、26×26×512、52×52×256分辨率的feature map,即将整幅图像分成了粗粒度13×13个网格、中粒度26×26个网格、细粒度52×52 个网格,将每个网格对应3 个不同尺寸的anchor,记为anchor(x,y,wa,ha),其中x、y 为anchor中心点在feature map纵横坐标,wa、ha为anchor在feature map尺度上的宽高值。feature map在D层处理后,每个anchor得到5个量,记为:
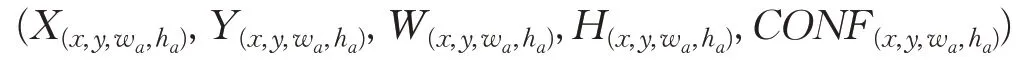
其中,X(x,y,wa,ha)和Y(x,y,wa,ha)为依据该anchor 预测的boundingbox中心点坐标,W(x,y,wa,ha)和H(x,y,wa,ha)为预测的boundingbox 宽和高,CONF(x,y,wa,ha)) 为依据上述预测boundingbox为前景目标的置信度。


其中δ 为参数,一般取接近于0的小数,如δ=0.01。
2.2 分阶段训练与各个阶段的loss
为了进行端到端的属性识别,首先需要推断目标所在的boundingbox框,第二步依据boundingbox再推断属性的取值。为此,训练分成3个阶段。
第一阶段,目的是在训练后能够检测到准确的boundingbox。使用coco 数据集训练好的YoloV3 模型参数值作为本阶段训练的初始权重,利用反向传播算法训练图4中第一层到D层的网络参数,其他网络参数保持不变。训练时的loss 仅仅考虑正样本anchor 的前景置信度和其预测的boundingbox框坐标误差。
某个anchor(x,y,wa,ha)得到的boundingbox预测值记为:

计算包含预测boundingbox 与GT boundingbox 的最小box的面积,如式(8)~(12):

第一阶段还要计算anchor 预测的前景置信度loss。设anchor(x,y,wa,ha)为正样本,其预测的boundingbox置信度值为CONF(x,y,wa,ha),其期望的置信度值应该为1,按下式计算置信度交叉熵:
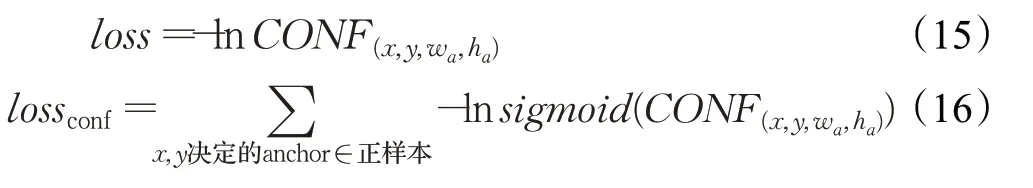
最终,第一阶段反向传播算法使用的loss函数为:
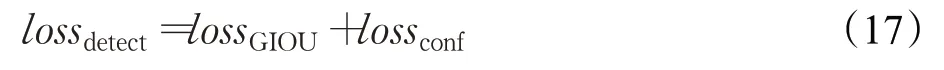
需要指出的是,式(14)和式(16)中的求和是针对输入图像在D 层处理前形成的粗粒度、中粒度、细粒度网格下的anchor,并且是与GT的交并比大于0.5的anchor,也称为第一阶段的正样本。
第二阶段,目的是使训练后的属性子网络能够较为准确的预测属性取值。第一层到D 层的网络参数权重值使用上阶段训练结果,并在本阶段一直保持不变,反向传播算法仅训练各属性子网络的权重参数。训练时的loss仅考虑属性预测相关的loss。采用第一阶段训练得到的第一层到D 层网络参数值,将其固定,根据第一层到D 层的网络输出得到候选boundingbox,保留超过门限值的boundingbox 并进行NMS 处理,计算剩余boundingbox 与GT boundingbox 的交并比,若交并比大于0.5,认为这些boundingbox为第二阶段的正样本。由2.1节标注的正样本属性期望概率q(x)xi,j∈{1,2,…,Ni}、属性子网络预测概率p(x)x=1,2,Ni,计算交叉熵作为loss:
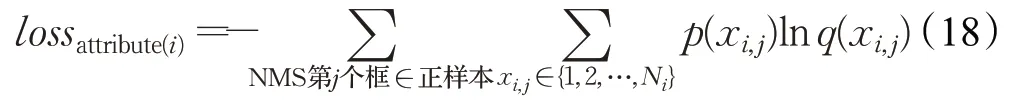
其中i 代表第i 种属性,Ni代表第i 种属性的取值个数,j 代表第二阶段正样本。若有相互独立的多个需要预测的属性,则:
到了年关,人们都在互相问候,在他的微信列表里看见丁柔的头像时,我冷冷地抽了一口气,没想到他们居然还有联系。没忍住好奇心点进去一看,只是最平常的问候,丝毫没有暧昧的气息。即便如此,我还是无法控制住情绪,脑子开始胡思乱想。
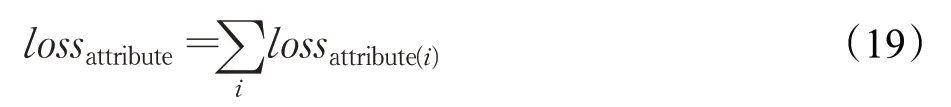
lossattribute用于本阶段的反向传播算法。
第三阶段,目的是在前两阶段训练的基础上,对所有的参数进行调优。使用第二阶段最后的权重作为本阶段所有参数的初值,然后一并考虑前景置信度、boundingbox 框、属性预测的loss,使用反向传播算法进行所有的网络参数进行微调。
本阶段计算loss时,要对前述的所有anchor正样本计算得到lossGIOU和lossconf,对所有boundingbox 正样本计算得到lossattribute,本阶段训练用的loss函数为:

3 实验过程与结果分析
3.1 实验环境与过程
实验采用Stanford Cars Dataset数据集[16],共16 185张图像,其中用于训练的8 144 张,用于测试的共8 041张,数据集中典型场景如图5 所示,既包含了车辆也包含了其他背景。需要说明的是,原数据集仅仅标注了每张图像中车辆所在boundingbox 的坐标以及品牌型号(共196种)。对品牌型号属性,有196种取值,符合多值属性的要求,但还不符合识别多种多值属性的需求。为此,针对每个boundingbox,课题组又标注了拍摄角度和颜色等两种相互独立的属性。拍摄角度属性有前部(front)、后部(rear)、侧部(side)、前侧(front-side)、后侧(rear-side)等5 个属性值,颜色属性有黑、红、黄、银灰、蓝、绿、白、橙、紫、混合色等10 种属性值。最终对每个车辆目标,有品牌型号、拍摄角度和颜色3 种相互独立的多值属性需要识别。

图5 Stanford Cars Dataset数据集典型样例
实验的硬件环境为:CPU 为至强E5-2620V4,内存32 GB,NVIDIA GeForce GTX 1080TI GPU;基础软件环境为Ubuntu14.04 系统、Pycharm5.0 集成开发环境、Python3.5 编程语言;深度学习框架为Tensorflow1.11.0。下载MS COCO 数据集训练好的YoloV3 模型,作为第一层到第D 层各卷积第一阶段训练的初始权重参数值,属性识别子网络参数在第二阶段训练时采用了Xaiver[17]初始化。反向传播更新参数使用了Adam[18]梯度下降算法。
每次取6 幅图像(batchsize=6)计算loss、更新参数,遍历完训练集的8 041 张图像为一个Epoch,需要1 358次。第一阶段训练为30 个Epoch,第二阶段训练为28个Epoch,第三阶段训练为20 个Epoch。图6 展示了第一阶段lossconf、lossGIOU随训练次数增多而下降的过程,其中横坐标代表了当前训练的次数,置信度conf 损失在开始训练时接近60,之后迅速下降,而GIOU 损失值一直很小,随着训练次数增加有一定波动,但整体趋势为下降,约在33 920 次后减小到0.09 附近,对应模型参数可以用于作为下一阶段的初值。图7 展示了第二阶段三种属性的loss随训练次数增多而下降的情况,选用28 个Epoch 的最后一次对应的模型参数作为下一阶段的初值,虽然不是最小loss,但由于第三阶段还可以调优,这是可以接受的。图8展示了第三阶段losstotal随训练次数变化情况,从中可见虽然有波动,但是整体还是处于下降趋势,并在25 880 次达到最低,选用其对应的模型作为最终的推断模型。
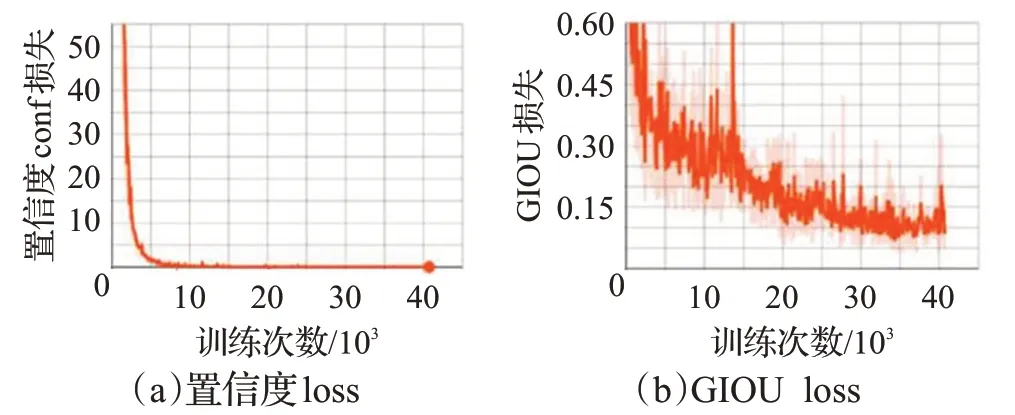
图6 第一阶段训练的置信度与GIOU loss变化
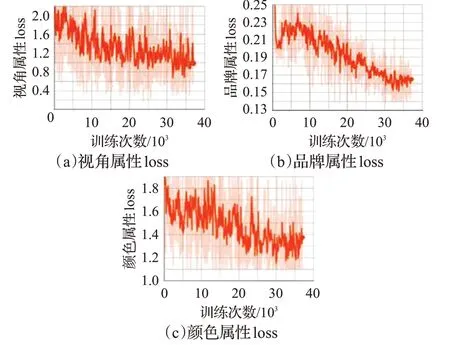
图7 第二阶段视角、品牌和颜色三种属性loss变化
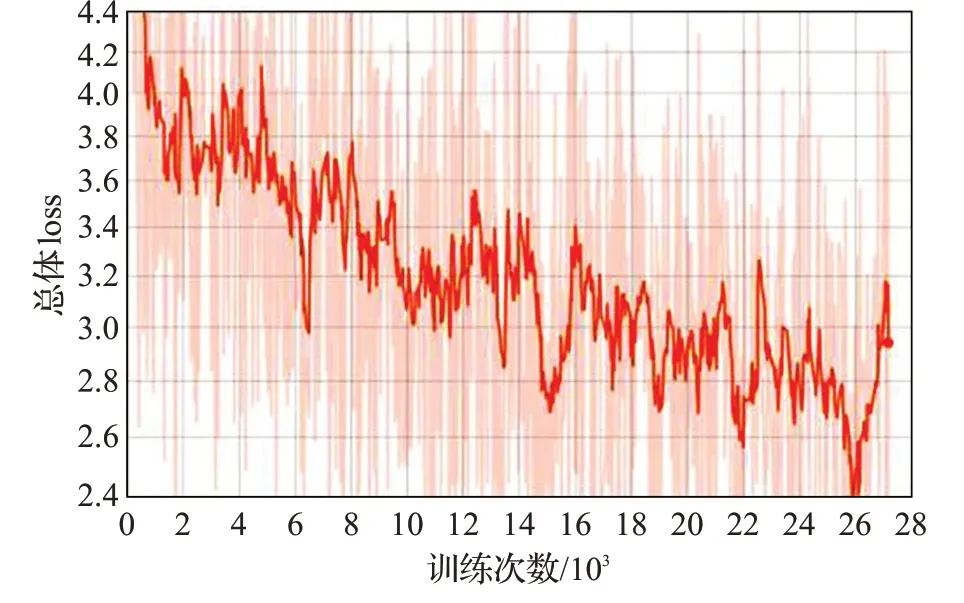
图8 第三阶段总体loss变化情况
最终得到端到端网络,可用于一次性推断目标boundingbox坐标、置信度、属性取值。典型属性识别效果如图9所示,目标boundingbox紧紧包围着目标,置信度为0.99,品牌型号属性取值为奥迪S5 2012 款(Audi-S5-Coupe-2012),颜色属性取值为白色(white),视角属性取值为前侧(front-side)。

图9 属性识别效果
在比较基准上,选择了目标检测的一阶段YoloV3和两阶段的Faster RCNN。YoloV3 综合运用了上下层特征融合、多分辨率等技术,是一阶段目标检测的典型代表,本文也是基于它改进的。另外,还选择两阶段算法Faster RCNN,它通过先提供候选Proposal,在RCNN(区域卷积)进行目标类别判别,判断和boundingbox 位置回归,在之前图像库上具有定位较准的特点。
3.2 定位准确性分析
AP(Average Precision)反映目标boundingbox 的定位准确性,且不受置信度阈值取值对结果的影响。AP是mAP(mean Average Precision)的特例,即当只有单类目标需要检测定位时,mAP就是AP。
AP 计算的过程如下:对每张图片,先得到图3 中D层输出,即目标boundingbox的4个坐标值和置信度值,用NMS 过滤掉绝大部分boundingbox。将测试集所有图片对应的上述boundingbox,按其置信度进行从小到大排序。然后根据boundingbox 与GT 的IoU 是否大于等于0.5,决定它被标记为正样本(True Positive)还是负样本(False Positive)。统计各种置信度下True Positive(TP)和False Positive(FP)数量,按下式计算检测精度P与查全率R:

按置信度从小到大,依次绘制精度P与查全率R,得到PR曲线,PR曲线下的面积即为AP值,AP值越大,反映算法的目标定位越准确。
用于比较的YoloV3 算法和Faster RCNN 算法同样用Stanford Cars Dataset 数据集进行训练,同等情况下Faster RCNN 训练时间更长,这与其每批只训练一幅图像和用于NMS 的候选Proposal 较多有关。另外,需要指出的是,上述两种检测算法每次只能用于一种属性的识别,以品牌型号属性为例,将属性每种取值都作为目标类别,共196 类目标进行检测,检测目标的同时就得到了属性值;对颜色和视角属性,需要再训练两个单独的检测器,用于颜色属性、视角属性取值的获取。YoloV3 和Faster RCNN 需要计算mAP 值,即计算各个属性值的AP,然后对所有属性值的AP 求平均值,得到mAP。
表1 是分别针对品牌型号属性、拍摄角度属性、颜色属性三种属性的mAP值与本文AP值的对比。从表中数据可见,本文算法AP值大于YoloV3算法的mAP值,说明本文算法定位具有高准确性,同时也说明了YoloV3的mAP 值受到属性值的影响。还可以看出,Faster RCNN 对196 种取值的品牌型号属性性能较低,分析其原因在于Faster RCNN 的目标输出方法与YoloV3、本文方法差异较大。Faster RCNN 对每个提议都要输出196 个boundingbox 框,经过softmax 处理后为196 种属性值的置信度,这196 种置信度加上为背景置信度,其和为1。这种情况下各置信度的差别容易比较小,对目标重复检测情况比较多,导致检测不准;而对视角属性和颜色属性,它们取值均较少(为5 种和10 种),则上述情况不存在。
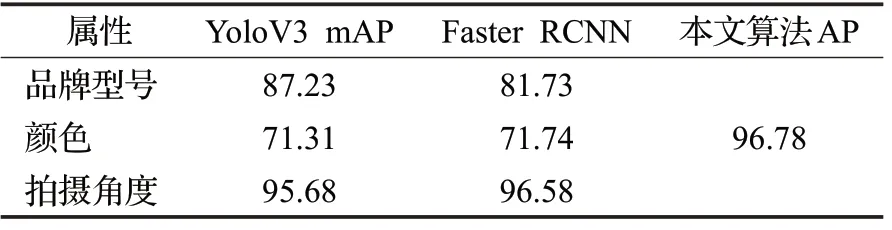
表1 AP和mAP的对比%
3.3 属性正确率与耗时结果分析
属性正确率的计算方法如下:对每张图片,先得到D 层输出的boundingbox,用NMS 过滤掉绝大部分boundingbox,再用R 层输出针对剩余boundingbox 的属性预测;计算预测boundingbox与GT的IoU,若IoU大于0.5,则看其属性预测的Top-1 与GT 属性标注是否一致(或Top-3 预测中是否含有GT 的标注属性取值),若一致,记为正确预测boundingbox;对所有测试图片,统计单种属性Top-1或Top-3下正确预测boundingbox个数,将其除以测试集预测boundingbox 总数,就是单种属性预测的正确率;统计三种属性预测同时正确的boundingbox数量,除以测试集预测boundingbox总数,就是三种属性同时正确的正确率。
计算YoloV3 算法下的单种属性正确率。为此,使用YoloV3 算法进行单属性下各属性值目标物体的检测,在boundingbox 与GT 的IoU 大于0.5 条件下,查看boundingbox 所属物体与GT 是否一致,统计一致的boundingbox 个数,除以测试集预测boundingbox 总数,得到YoloV3 Top-1 下的正确率。同时,查看上述预测boundingbox的第二、第三高可能性的物体,若前三种有一个与GT 标注值一致,也记为正确boundingbox,统计其个数,除以测试集预测boundingbox 总数,由此得到YoloV3 Top-3下的正确率。
对于Faster RCNN 算法,可类似计算Top-1 下(目标置信度门限为0.6)的单种属性正确率,但如3.2 节叙述,由于其每次输出的boundingbox 只有一个类别目标置信度,这种情况下无法计算Top-3下的正确率。因此表2 给出了本文算法与YoloV3算法、Faster RCNN算法的Top-1 单种属性正确率,表3 只给出了本文算法与YoloV3算法的Top-3单种属性正确率。

表2 Top-1下单种属性正确率的对比%
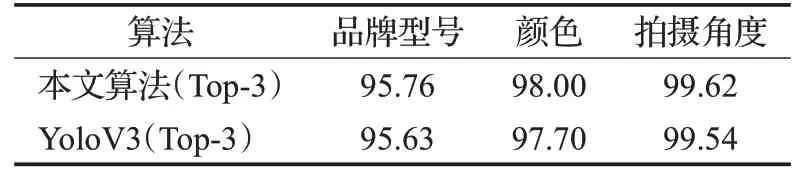
表3 Top-3下单种属性正确率的对比%
从表2 可见,本文算法超过了YoloV3 算法和Faster RCNN算法,这一点应与使用了目标所在区域提取特征进行属性识别有关,针对品牌型号这种较细粒度的属性,使用整个区域特征对其进行分类更有帮助。另外,三种属性中拍摄角度属性最容易判断,这是因为拍摄角度取值一共只有前、后、侧、前侧、后侧五种取值,并且每种品牌型号的车基本都有五种角度的样本,训练的样本量最大,规律性也相对最强。从表3 可见,本文算法与YoloV3 算法针对单种属性的Top-3 正确率对比情况,与Top-1 下基本一致,但表3 中颜色的Top-3 准确度超过了品牌型号,说明易于混淆的颜色集中在输出概率的前三位。
表4给出了三种属性同时判断正确的正确率,本文只需要推断一次,而YoloV3 和Faster RCNN 算法则需要使用对应不同属性的模型推断3 次,同样Faster RCNN 无法给出Top-3 下的正确率。从表4 可见,判断三种属性同时正确的情况要显著低于仅仅正确判断一种属性,无论是本文算法还是YoloV3 算法、Faster RCNN算法。

表4 三种属性正确率的对比%
最后,表5给出了算法速度方面的实验结果。判断三种相互独立的属性,YoloV3 算法和Faster RCNN 都需要进行三次,YoloV3 总耗时75.71 ms(对所有测试图像的平均值),Faster RCNN总耗时435.36 ms,而本文算法仅仅耗时27.93 ms,充分说明了本文算法在速度方面的优势。这与多个多值属性识别时,使用了共享的深层特征和按属性种类构建子网络密不可分。
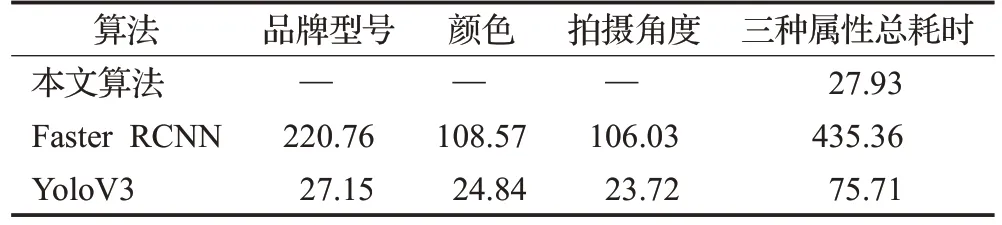
表5 三种属性耗时对比ms
4 结束语
发现目标、识别目标的属性是计算机视觉的重要研究内容,本文对目标的属性进行了梳理,提出了针对目标多个独立属性的识别网络,每个属性均为多值属性。通过使用多个共享深层次特征的子网络提升了推断过程速度,通过提取目标boundingbox的区域特征,使得其对多个属性识别准确度优于多次使用目标检测算法。
需要指出的是,当前本文针对的目标属性表现在全局,如汽车目标的品牌型号属性,是通过全局的外观特征确定的。随着研究的深入,一些细粒度难以区分的物体属性可能还需要通过注意力机制聚焦于局部,还有一些目标的属性本身就是对局部的描述,比如人是否戴眼镜。下一步,将针对具体局部属性特征以及细粒度的属性特征识别,加强注意力机制方面的研究。
