基于聚类分析与迁移学习的入侵检测方法
2021-05-14黄清兰
黄清兰
(福建商学院信息技术中心,福建 福州 350012)
1 引言
在新的智能网络行为出现的情景下,基于异常的入侵检测要能有效地实现新网络攻击行为的检测,具有一定的挑战性。目前基于传统的机器学习、深度学习、集成学习、统计分析、迁移学习等技术被广泛应用于基于异常的入侵检测领域[1]。
传统的机器学习技术主要如聚类、支持向量机、决策树等。基于聚类的方法可以选择不依赖标签样本进行异常检测。依赖标签样本进行异常检测的技术主要是利用分类技术,研究比较多的是结合其他的机器学习技术进行应用。陈虹等[2]使用深度信念网络分别对训练集和测试集进行特征抽取,然后使用Xgboost算法进行分类检测。文献[3]是基于迁移学习技术,针对两个不同分布和特征空间的网络样本数据,通过分析源域和目标域之间的相似性,提出了一种将两者样本集映射到相同维度的特征空间方法,该方法能有效地迁移源域数据来预测目标域网络样本数据的分类检测。
基于统计分析、迁移学习的入侵检测技术相较基于传统机器学习来说研究比较少,由于传统机器学习技术在训练和测试样本分布不一致的情况下,表现效果不佳,而实际情况往往是分布不一致的样本,入侵检测领域也是如此。如何在数据分布不一致的情况,提高入侵检测分类的准确率。本文结合聚类、统计抽样技术和迁移学习,提出了一种基于聚类分析与迁移学习的入侵检测方法(Intrusion Detection Method Based on Cluster Analysis and Transfer learning,CATL)。
2 相关知识
2.1 K-means++和Xgboost
K-means算法是基于划分的经典聚类算法,在面对大数据聚类分析的情况,该算法相较于其他的聚类算法,更为高效。K-means算法是随机选取初始聚类中心,而聚类结果很大程度会受初始聚类中心的选择而呈现出较大差异,使其不能保证聚类结果的准确性。针对此问题,Arthur等[4]提出的K-means改进算法K-means++,该算法除了在初始聚类中心选取方式与K-means算法不一样,其它步骤是一样的。Kmeans++算法的初始聚类中心选取的基本思路是要使得选取的初始聚类中心相互间的距离要尽可能远。
Xgboost是经典的集成学习算法,被广泛应用于回归和分类问题,它是一个优化的分布式梯度提升决策树的改进算法,使用正则化提升技术来防止过拟合,具有高效、灵活等优点。
2.2 基于实例的简单迁移分类模型
迁移学习[5]主要的概念是域和任务。域D={X,P(X)},其中X为样本集即特征空间,P(X)为边缘概率分布。任务T={Y,f(X)},其中Y为样本的标签集即标签空间,f(X)为预测函数表示的是条件概率分布P(X|Y)。假设源域Ds={Xs,P(Xs)},源任务Ts={Ys,f(Xs)},目标域Dt={Xt,P(Xt)},目标任务Tt={Yt,f(Xt)}。迁移学习从已学习的相关任务中转移知识用以辅助新任务的知识学习,在源域和源任务中转移相关知识用以辅助目标任务的知识学习。依据转移知识的不同,迁移学习可以分为基于实例的迁移学习、基于模型的迁移学习、基于参数的迁移学习等。
基于实例的迁移学习[6]是一种归纳式迁移学习方法,又分为基于单源实例和基于多源实例,研究比较多的是基于单源实例的方法,该方法假设存在部分的训练集Dd={Xd,P(Xd)}和测试样本分布一致,但该部分训练集不足以训练一个好的分类模型进行测试样本的分类预测的情况下,需要利用Dd来迁移有益的源域训练样本Ds进行分类模型训练。简单迁移策略[7]具体流程如图1所示。

图1 基于实例的简单迁移分类模型流程
通过使用目标域中部分有标记的训练数据集Dd进行分类模型训练,将训练好的分类模型用以预测源域的训练数据,将源域中分类正确的数据进行迁移,与Dd构成新的训练样本进行训练,将训练好的分类模型用于预测目标域中未有标记的数据Dt,但该方法的前提是假设Dd与目标域中未有标记的数据分布一致。该迁移策略简单易行,但是实际应用场景中,如何获取Dd使其分布相似于目标域中未有标记的数据,是影响其使用效果的重要方面。
针对简单迁移策略使用的关键问题:Dd的获取方式,CATL算法首先设计了基于聚类的统计层次抽样技术进行Dd的获取,而后利用简单迁移策略进行入侵分类检测,CATL算法是基于实例的简单迁移策略应用的算法,也是一种混合算法。
3 CATL算法
假设目标域D={X,P(X)},其样本量为N,固定比例R为Dd占D的比例,源域Ds={Xs,P(Xs)},Ts={Ys,f(Xs)},D和Ds的特征和标签空间一致,P(X)≠P(Xs)。
CATL算法实现的具体流程如图2所示,其设计主要有两大步骤:
(1)通过K-means++算法进行聚类划分X,X是不包含标签的样本数据集,若聚类个数为K,初始化依据式(1)产生,则聚类划分的子总体集合G={G1,G2,…,Gk},从所划分的每个子总体中按固定的比例R抽取样本,所抽取的样本集合并为Xd,Xd可以代表原总体样本X的分布,将所抽取的样本集Xd进行标记形成Dd,测试集Dt={X-Xd,P(X-Xd)}。

其中聚类个数之所以按式(1)进行初始化,是为了尽可能使聚类划分的每个子总体都能抽到样本并入Xd,若聚类个数远大于Dd样本量,导致Dd严重偏向于大类(子总体所含样本量比较大)。
(2)使用Xgboost算法对Dd进行训练,将训练好的Xgboost模型用于测试Ds,将Ds中分类正确的样本进行迁移,与Dd合并构成新训练样本,再用Xgboost算法对新训练样本进行训练,将训练好的新模型对测试集Dt进行分类检测。
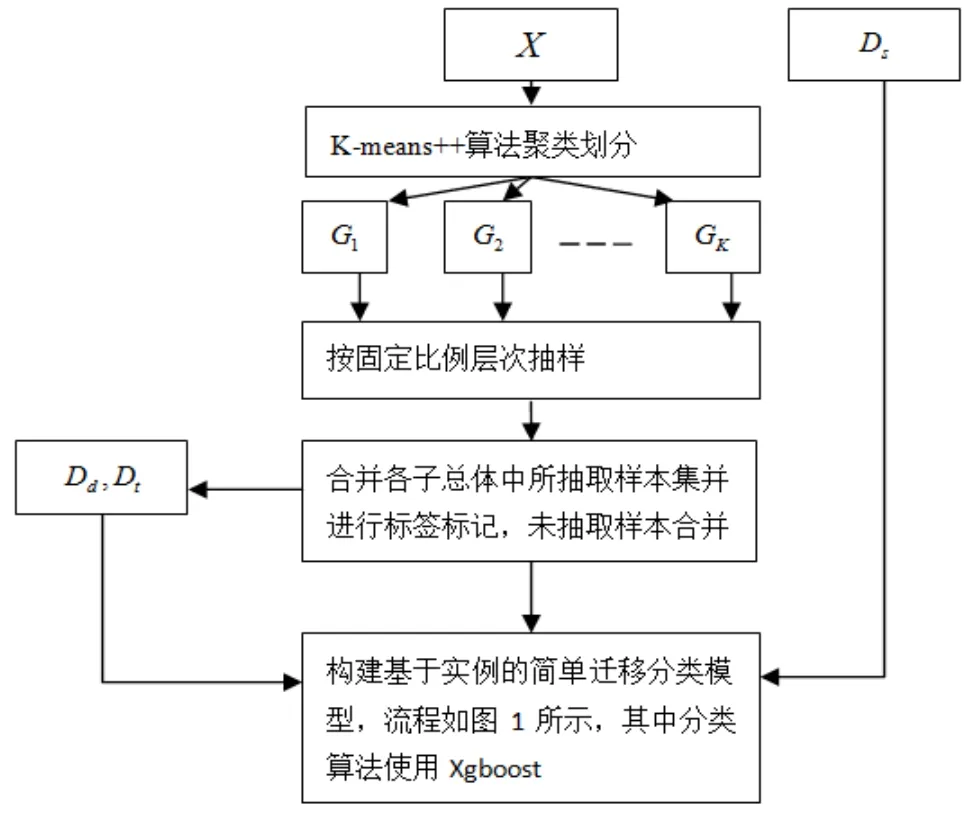
图2 CATL算法流程
4 实验分析
入侵检测数据集采用NSL-KDD,该数据集有41个特征属性和一个类别标签,类别标签值为正常和非正常,其中KDDTrain为训练集,KDDTest为测试集,两者的数据分布是不一致的[6]。KDDTrain可认为源域,都是有标记的数据,KDDTest为目标域。
CATL算法是基于实例的简单迁移分类模型,分类算法的评估指标常见的[8]有准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值。F1值权衡了精确率和召回率,其公示如式2。为了评价CATL算法的有效性,本文使用准确率和F1值作为评价指标。

使用Python语言进行编程实验,Xgboost算法使用的是Xgboost-0.82包,K-means++和对照实验的算法都在scikitlearn中已实现。在随机种子一样的情况下,设置两组实验。第一组实验:设置R为0.1%~1%间,步长为0.1%,不同比例下进行不同组迁移分类模型实验,每组实验执行100次,实验结果如图3所示。由图中可知,R为0.3%时准确率是最低的,出现异常值情况最多;在0.5%~0.9%间都有出现异常点,F1值和准确率平均值都在0.9左右;0.1%下波动性最小最稳定,准确率和F1值都在0.83左右。

图3 不同比例值下CATL算法的准确率和F1值的箱形图
第二组实验为对照组实验,设置R=0.1%,因为该值下CATL算法波动性最小也最稳定,对照实验算法有Xgboost、AdaBoost、RandomForest和SVM算法,CATL模型中,Dd的样本量为20,对照实验结果如图4所示。CATL算法相较于SVM准确率提高了9%左右,相较于Xgboost算法准确率提高了3%左右。
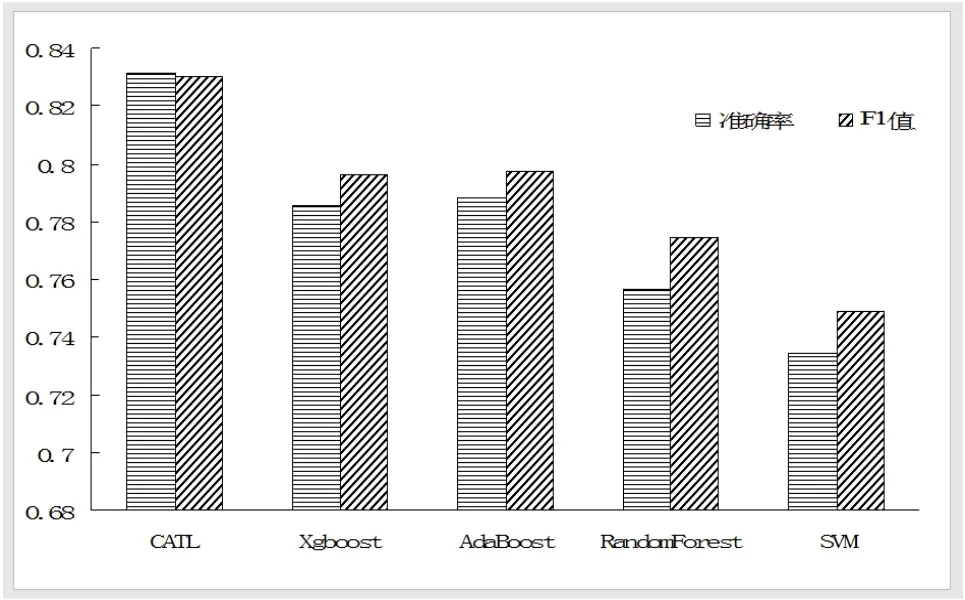
图4 CATL算法与对照算法的性能比较
CATL算法在使用不同比例的目标域标记样本下总体的执行结果相较于传统的分类算法性能都有明显的提升,但该算法的稳定性和精准性对比例值设置有很大的依赖性,结合实际需要进行设置。
5 结语
针对传统机器学习算法在入侵检测实际应用中,训练和测试样本分布不一致的情况下,检测精准性低的问题,提出了CATL算法。经过相关实验测试,该算法在从目标域中获取用于迁移分类训练的少量有标记数据20条的情况下,相较于SVM算法准确率和F1值都提高了9%左右,总体性能有一定的提高,但稳定性相较于现有的分类学习算法较差,稳定性比较依赖于比例值R。下一步工作,思考如何平衡CATL算法的精准性和稳定性,对其进行改进,并应用于高校的实际使用场景。
