基于双重注意力机制的图像超分辨重建算法
2021-05-13赵思逸
李 彬,王 平,赵思逸
基于双重注意力机制的图像超分辨重建算法
李 彬1,王 平1,赵思逸2
(1. 国防科技大学电子科学学院,湖南 长沙 410072; 2. 国防科技大学计算机学院,湖南 长沙 410072)
近年来,卷积神经网络(CNN)在单幅图像超分辨率重建领域(SISR)展现出良好效果。深度网络可以在低分辨率图像和高分辨率图像之间建立复杂的映射,使得重建图像质量相对传统的方法取得巨大提升。由于现有SISR方法通过加深和加宽网络结构以增大卷积核的感受野,在具有不同重要性的空间域和通道域采用均等处理的方法,因此会导致大量的计算资源浪费在不重要的特征上。为了解决此问题,算法通过双重注意力模块捕捉通道域与空间域隐含的权重信息,以更加高效的分配计算资源,加快网络收敛,在网络中通过残差连接融合全局特征,不仅使得主干网络可以集中学习图像丢失的高频信息流,同时可以通过有效的特征监督加快网络收敛,为缓解MAE损失函数存在的缺陷,在算法中引入了一种特殊的Huber loss函数。在主流数据集上的实验结果表明,该算法相对现有的SISR算法在图像重建精度上有了明显的提高。
单幅图像超分辨;特征监督;残差连接;通道注意力机制;空间注意力机制
单幅图像超分辨率重建(single image super- resolution,SISR)是一个低水平的计算机视觉任务,其目标是利用低分辨率(low-resolution,LR)图像,恢复出对应的高分辨率(high-resolution,HR)图像。由于硬件设备和信息传输条件的限制,通常获取到的多为LR图像。SISR技术在不增加硬件成本的同时能有效提升图像的成像质量,因而已经在社会安全[1]、医学成像[2]、军事遥感[3]等领域取得广泛应用。但由于LR图像丢失了大量的高频纹理信息,导致同一幅LR图像,可能存在多个HR图像与之对应,因而SISR是一个不适定的问题。目前已经提出的超分辨算法主要有3类:基于插值的算法、基于重建的算法和基于学习的算法。基于深度学习的图像超分辨率重建算法是基于学习算法的一种,该算法以机器学习算法理论为基础,通过建立输入的LR图像和对应的HR图像的样本数据库,学习LR图像与HR图像之间对应的映射函数从而获得有效的重建模型。DONG等[4]第一次将卷积神经网络(convolutional neural network,CNN)引入图像超分辨率重建领域,提出了SRCNN网络算法,由于SRCNN算法建立了一种端对端模型,同时也展现出良好的重建效果,因而引起极大关注,目前已涌现出如VDSR[5],DRCN[6],DRRN[7]等网络结构算法,已逐步发展成为该领域的主流算法。
虽然深度网络模型在图像超分辨率重建领域取得了非常好的效果,但其仍然暴露出许多问题,制约着模型效果的提升:①大部分的CNN网络模型主要通过加深网络结构的深度,通过重复的卷积操作,增大卷积核感受野以捕捉长距离邻域信息,使得图像重建质量有较大提升。但是加深网络结构往往会带来较大的计算量,同时使得网络优化训练难度加大;②现有的CNN网络多是通过卷积操作提取图像信号特征,对于各通道、位置特征采用均等处理办法,但实际上各特征有不同的重要程度,均等处理使得网络花费很多的计算资源在不重要的特征上;③随着CNN网络深度增加,不同的卷积层有不同大小的感受野,因而获取到的特征信息存在差异性,仅利用最后卷积层输出的特征映射实现重建任务,导致一部分可用信息被浪费。
Senet[8]网络将通道注意力机制引入深度神经网络,在卷积操作中输出每个通道的特征由一个卷积核与输入特征计算获得,因而不同卷积核提取的特征重要性不尽相同,Senet构建了Squeeze和Excitation结构学习代表各通道重要性的权重值,通过学习到的权重值自适应地增强对重建任务有用的特征并抑制用处不大的特征。由于Senet结构可以将有限的计算资源合理地分配到更需要的运算中,因而可以在有限计算资源条件下有效提升网络算法的学习能力,同时也适合构建轻量的网络架构,因而获得广泛地应用。Non-local[9]也是一种构建注意力机制的方法,但在实际应用中,由于需要对两两像素点之间进行权重计算,因而带来的大量的计算量,难以大规模在网络结构中采用。RCAN[10]第一次将通道注意力机制引入到图像超分辨率重建领域,使该算法展现出良好的重建效果。针对前面提到现有深度模型存在的一些缺陷,受RCAN算法的启发,本文提出了一个新颖的网络结构算法,以解决现有网络模型存在的问题。该算法通过构建一个基于通道注意力和空间注意力[11]的双重注意力机制模块(dual attention module,DAM),该模块通过捕捉不同通道或空间位置特征重要性以获取对应位置的权重参数,从而自适应地根据通道内特征的重要程度分配计算资源以增强有用特征抑制无用特征,同时算法中通过长跳跃连接[12]构建特征监督,将每个模块输出都自适应的用于图像重建,既有效监督每级模块输出,加快网络收敛,也充分利用各级特征进行图像重建,使得各分层特征能够得到有效利用。本文的主要工作包括:
(1) 提出一个新颖的基于双重注意力机制的深度网络算法实现图像超分辨率重建。通过在基准数据集上进行对比实验,验证了该算法相对目前最先进的SISR算法有了明显的效果提升。
(2) 构建了包含DAM的残差网络块。其包括2个基本的残差块和1个DAM。DAM模块包括空间注意力机制和通道注意力机制。空间注意力机制是通过自适应地学习不同空间位置像素的权重从而自适应地强化重要位置的特征,以对空间位置特征进行建模,通道注意力机制能够自适应学习调整中间通道内重要特征而抑制无用特征,从而更加高效地利用计算资源进行有效计算,提高模型的有效性。
(3) 构建了全局特征融合模块,通过跳跃连接将各分层提取到的特征直接送入全局特征融合模块。分层特征的引入使得本文模型能够从浅层就加强特征监督,促进网络收敛,同时浅层信息也可以有效加强图像重建效果,从而进一步强化图像重建质量。
1 残差双重注意力网络(RDAN)
1.1 网络基本结构
受RCAN算法的启发,本文提出了一个新颖的深度网络算法称为残差双重注意力网络(residual dual attention network,RDAN),该网络结构主要包括浅层特征提取模块、基于双重注意力机制的特征融合模块、上采样模块和图像重建模块。用I表示网络输入,用I表示网络输出,在浅层特征提取模块,网络用一个卷积层提取输入图像I的特征,即

其中,H(·)为简单的单层卷积映射实现浅层特征提取。然后将浅层卷积提取到的特征作为基于双重注意力机制特征融合模块的输入,通过基于双重注意力机制特征融合模块得到特征映射后的高维特征,即

其中,H(·)为双重注意力机制的特征融合模块映射关系。该模块通过对每个子模块的特征进行融合得到新的高维特征,与现有的SISR方法相比,本文提出的双重注意力机制的特征融合模块使得网络可以更加有效地利用所提取到的有用特征,抑制无用特征,从而使得网络在不增加算力的同时能够有效加深网络的深度,从而增大卷积核的感受野。融合转变后的特征作为上采样模块的输入,通过亚像素卷积[13]的方法对输入特征进行上采样,得到尺度增大的特征映射,上采样后的特征为

其中,H(·)为上采样操作;F为上采样后输出特征。目前在超分辨率重建领域常用的上采样方式有插值操作[14]、反卷积操作[15]和亚像素卷积操作。亚像素卷积操作是一种像素重排的方式实现上采样,这种重排像素的方式使得其相对反卷积操作,减少了需要学习的参数。因而为了使网络在重建速率和精度方面达到较好结果,本文选择通过亚像素卷积操作实现上采样。最后通过一个简单的卷积层将输入特征转化为彩色图像对应的三通道的输出图像,即

其中,H(·)为图像重建模块的映射函数;H(·)为I到I的映射函数。
1.2 双重注意力机制的全局特征融合模块
在本文的网络算法设计中,基于残差双重注意力机制特征融合的模块(residual dual attention block,RDAB)是网络中实现特征映射的主要结构。该模块构建了残差双重注意力机制的全局特征融合结构,包括个双重注意力组(dual attention group,DAG)和个跳跃结构,如图1所示。每个DAG模块的输入经过特征拼接后由瓶颈层(1×1卷积实现)进行特征融合,有助于加强信息的流动,在有效降低特征通道数的同时也有助于提升重建图像效果,每个DAG模块包括个DAM和1个局部残差结构,在DAG模块中,残差结构有效加强了低频信息的传递。双重注意力、跳跃连接以及特征融合的机制使得本文的网络算法能够在不引入更多参数时,可进一步提高网络学习非线性映射的能力,从而获得更佳的重建效果。
为了更加充分地利用各分层提取到的特征,将每个DAG模块的输出进行融合,使得网络能够提取到更充分的特征信息以获得更佳的重建效果。网络模块中第个DAG块的输出特征可表示为
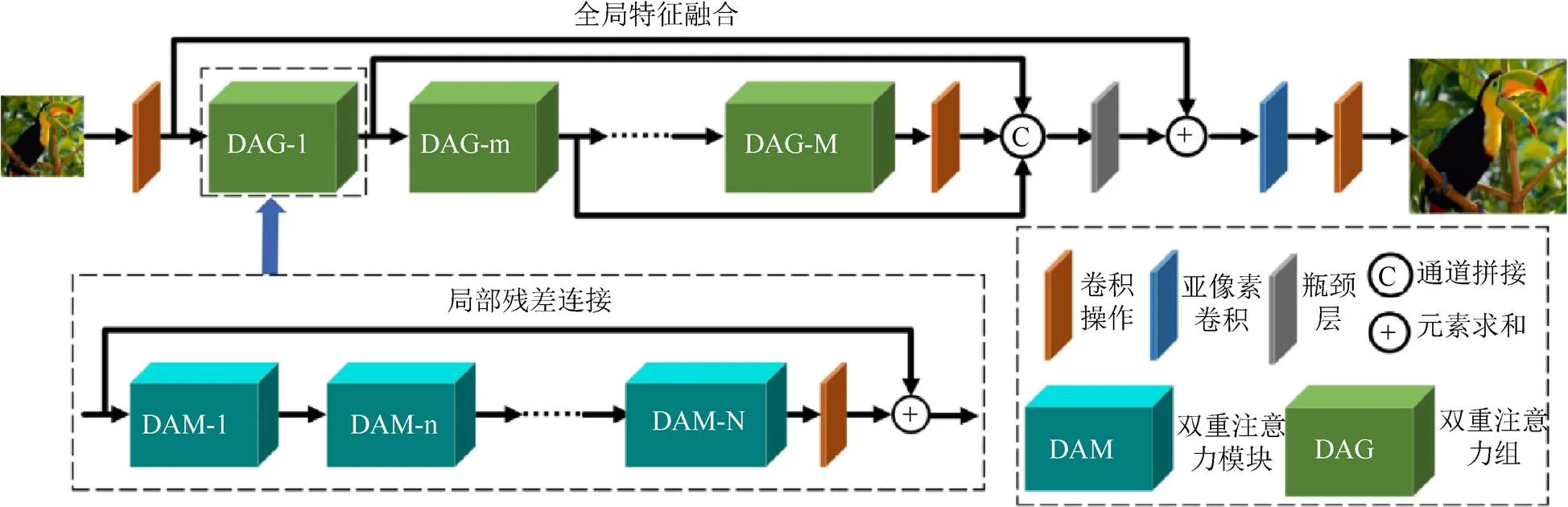
图1 残差双重注意力机制的网络结构
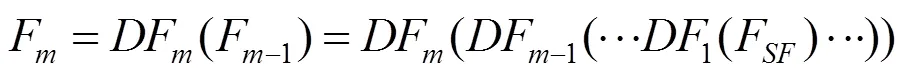
其中,F和F-1分别为第和第-1个DAG模块的输出映射,同时F-1也是第个DAG模块的输入;(·)为网络中第个DAG模块对应的函数映射。为了强化信息的流动,网络中有效利用跳跃连接对分层特征进行拼接,通过瓶颈层实现特征融合,使得网络能够充分利用分层特征,实现更佳的重建效果。具体RDAB特征映射可表达为

其中,(·)为将各DAG模块输出的特征映射进行拼接;(·)为将拼接后的特征融合压缩,通过长跳跃连接将融合后的残差特征与输入特征F进行合并,使网络更加关注残差细节的学习。
由于超分辨(super-resolution,SR)图像与LR图像在低频信息方面基本一致,因而超分辨网络更加关注恢复图像的高频细节和纹理部分。为了更好地利用LR图像浅层特征包含的丰富的低频图像信息,在DAG模块内部也构建了局部跳跃连接,使得低频信号可以直接通过跳跃连接传递到模块尾端,每个DAG模块需堆叠了个DAM,第个DAG中的第个DAM可表达为
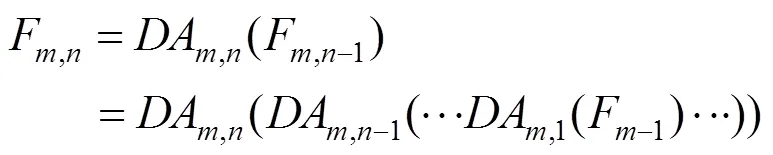
其中,F,n和F,n-1分别为第个DAG模块中的第个DAM块和第-1个DAM块的输出映射,同时F,n-1也是该DAG模块中第个DAM块的输入;,n(·)为第个DAG模块中的第个DAM块的映射函数。同样为了加快信息的传递,网络中构建了局部残差连接。则第个DAG模块可表达为
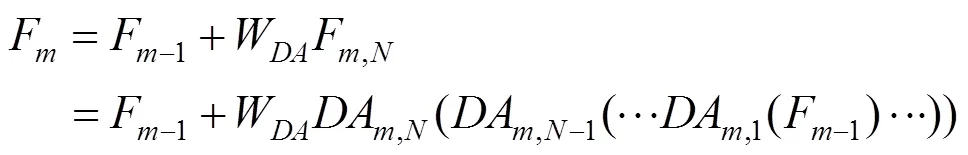
其中,W为第个DAG模块中最后一个卷积核的参数,其余参数含义与前面保持一致,本文构建的每个DAM中都包含双重注意力机制。
1.3 双重注意力机制
早期的基于CNN的超分辨网络结构主要关注点在提高网络深度和宽度,对于网络提取的特征在空间和通道间内采用的是均等的处理办法。该方法使得对于不同的特征映射网络缺乏必要的灵活性,因而实际工程任务中,极大地浪费了计算资源。注意力机制的提出,使得网络能够更多地关注对目标任务更加有用的信息特征,抑制无用的特征。从而使得计算资源可以更加科学地分配到特征映射过程中,因而可以在不增大计算量的同时进一步加深网络深度。
将注意力机制应用于SISR任务,目前已有部分网络结构进行了探索,例如RCAN,SAN[16]等网络结构通过注意力机制的应用使得SISR效果有了较大的提升。本文通过将空间注意力机制和通道注意力机制融合构建一个新的模块,并将其命名为双重注意力机制(dual attention,DA),进一步强化了SISR的效果,在基准数据集上与目前现有的SISR算法相比取得了更佳的重建质量。
1.3.1 通道注意力机制
为构建通道注意力机制,SE(squeeze-excitation)块通过聚合通道内的特征映射获得其描述,并利用通道全局描述有选择地加强有用特征抑制无用特征。图2(a)为Senet的通道注意力结构图,图2(b)为本文提出的通道注意力结构图,在图2(a)中,通过对输入特征的每一个通道进行平均池化操作,假设输入特征维度为××,则第个通道特征池化公式为

通过观察可以发现,不同通道包含的特征信息存在差异性,因而具有不同的重要性,通过全局平均池化获得每个特征图对应的均值,及计算每幅特征图的标准差。图3通过4幅特征图对比发现,其对应的最大均值仅为最小均值的1.04倍,最大方差是最小方差的7倍,标准差也有2.6倍。由此认为标准差池化能为通道权重学习提供更加有效的信息。其表达式为
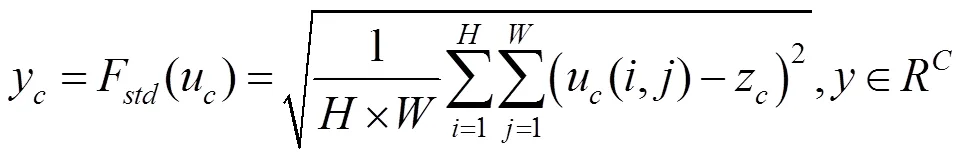
其中,y为第个通道的标准差;(·)为全局标准差;z为第个通道的平均池化结果。为充分利用其信息,在图2(b)中将全局平均池化和全局标准差池化的2个一维向量(C×1),通过特征拼接为二维矩阵(C×2),通过一个一维卷积操作将二维矩阵压缩成一维向量,为进一步捕捉基于通道的依赖关系及对应的权重值,需要构建学习各通道间的非线性关系的网络架构,以确保多个通道能被强化激活,从而有效学习非互斥的关系,因而本文采用了全连接的方式,并通过一个Sigmod[17]激活函数对权重值进行归一化后将权重作用到输入特征中。图2(b)包括注意力机制部分和一个残差结构,其注意力机制部分输出特征可表示为
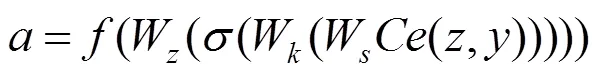
其中,为通道注意力结构的输出特征;和分别为经过平均池化和标准差池化后的结果;(·)为特征拼接;(·)和(·)为RELU[18]函数和Sigmod激活函数;W为一个一维卷积参数,将通道池化后拼接的二维向量压缩成一维;W和W为卷积核的权重参数,其表示对特征通道按衰减尺度进行压缩和扩增。

图2 Senet和本文的通道注意力结构图((a) Senet的通道注意力结构图;(b)本文的通道注意力结构图)

图3 卷积通道可视化结果
1.3.2 空间注意力机制
受Senet的启发,结合图3可以发现,不同通道之间存在不同的重要性,同样空间上不同位置的纹理细节也各异,因而其具有不同的重要性,由此在网络中构建和计算空间注意力机制时,需在网络结构中分别沿通道轴进行平均池化和标准差池化,即


本文将池化后的特征拼接经二维卷积将通道数目压缩为1,为了进一步减少计算量同时保证多个空间位置信息能够被强化,本文通过卷积操作来实现空间权重信息的非线性映射,同时也使用Sigmod函数对计算的空间权重特征图进行归一化。图4(a)为本文提出的空间注意力机制,包括注意力机制部分和一个残差结构,注意力结构的输出特征可表达为
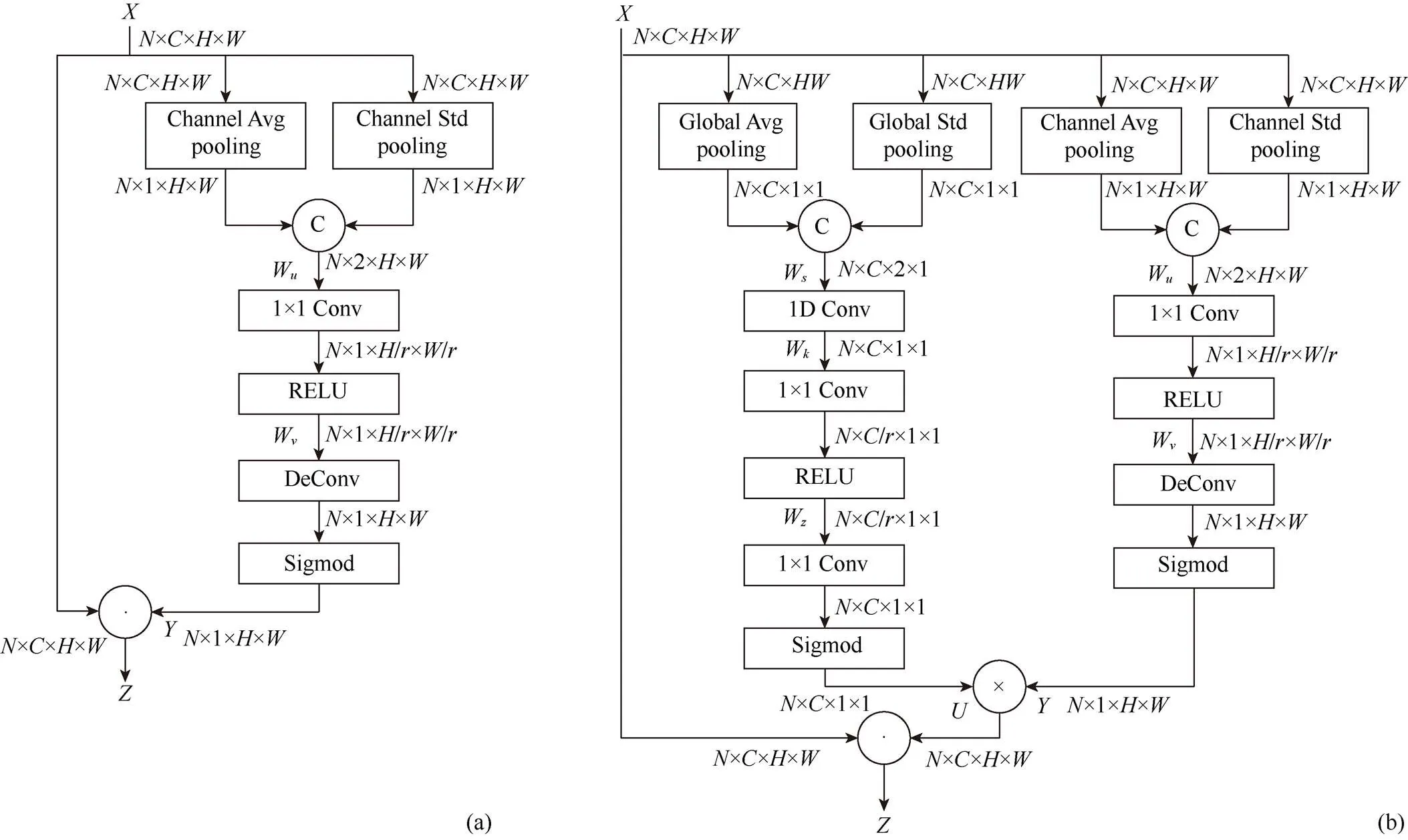
图4 本文提出的空间和全局注意力结构图((a)本文提出的空间注意力结构图;(b)本文提出的全局注意力结构图)
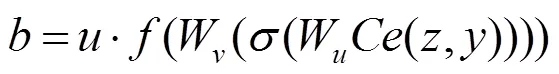
最终,通过通道注意力和空间注意力机制的组合,构建了具有双重注意力的网络结构,如图4(b)所示。空间注意力和通道注意力机制分别对空间位置像素和通道权重进行建模,将其组合对每个像素的位置权重进行建模,最后通过对应位置相乘将学习的权重值叠加到每一个对应的特征点位置,表达式为
与结构层透水混凝土施工间隔超过10h,摊铺前应对基层透水混凝土表面使用无机复合固化剂50倍加入稀释喷涂基层透水混凝土表面。


图5为本文构建的双重注意力模块(DAM)的主体网络结构,其包括卷积操作、双重注意力结构和残差连接,对于第个DAG中的第个DAM,其计算过程为

其中,DAm,n(·)为映射函数;Fm,n和Fm,n-1分别为模块的输出和输入;和分别为前后2个卷积操作的参数;s(·)为RELU激活函数;Rm,n(·)为双重注意力机制的映射函数;Xm,n为网络中间输出。
1.4 损失函数
超分辨率重建的目的是使重建后的SR图像I与真实图像I尽可能接近,其为回归问题,常用的损失函数有MAE(mean-absolute error)[19]、感知损失[20]、MSE(mean-square error)[19]等,基于MSE的损失函数对误差进行平方操作,如果数据中存在离群点,将被赋予更大的权重值,而离群点往往为噪声信息,因而牺牲了其他正常数据点的预测效果,降低了模型的鲁棒性。Lapsrn[21]和IDN[22]的实验证明了基于MAE的损失函数相对于基于MSE损失函数有更好的图像重建效果。由于MAE损失函数中的梯度信息为一个固定值,当模型计算的损失较低时,其梯度值较大,模型易在一个区间振荡,不利于网络收敛,在损失为0时,损失函数无法求解梯度。为应对MAE损失函数存在的缺陷,本文利用特殊的Huber loss[23]损失函数来保持MAE损失函数的鲁棒性,其可表示为
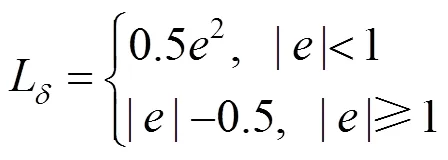
本文网络算法的损失函数为
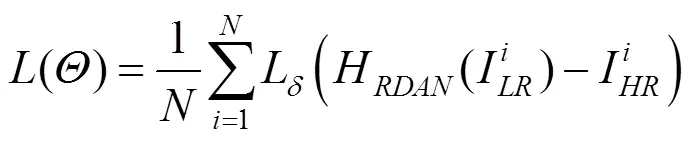
2 实验设置及结果分析
2.1 训练数据和测试数据
本文采用与RCAN,RDN,IDN等相同的训练数据集和测试数据集进行比较。训练数据采用DIV2K[24]数据集,其包含了丰富的场景和边缘及纹理细节的800幅训练图像、100幅验证图像和100幅测试图像。在训练模型时,本文使用该数据集的800幅训练图像,为了避免在训练过程中出现欠拟合现象[25],通过随机旋转90°,180°,270°和水平翻转,进行了数据扩增[26],使其扩充为原来的8倍,以保证足够的训练数据,同时解决不同倾斜角度的图像重建问题。训练数据中的LR图像为通过双三次插值下采样的LR图像。设置mini-batch为16,即每次训练中,抽取16幅48×48的LR图像的子图及对应标签图像进行训练。另采用常用基准数据集Set5[27]和Set14[28]作为测试数据集,其中Set5包含5幅不同风格类型的图像,Set14包含14幅图像。
2.2 网络超参数设置
实验的软硬件条件见表1,在网络结构中设置=10,=20,即主体的RDAN算法框架包括10个DAG模块,而每个DAG模块内又包含20个DAM模块,从而构成了一个复杂的深度网络算法结构。除了在通道注意力机制内通道压缩和扩增及特征融合的瓶颈层采用1×1的卷积核,其余卷积核大小均为3×3,在空间注意力机制采用的卷积和反卷积的卷积核大小也为3×3,其步长为3。在网络训练过程,为使得中间特征映射的大小保持一致,网络中应用了补0策略。除了空间注意力机制中使用1个卷积核滤波器,如图4(a)所示,输出特征为单通道特征映射,通道注意力机制中通道压缩层采用了通道压缩策略,压缩倍数为=16,即采用/=4个卷积核,如图2(b)所示,为确保最后一层输出为彩色图像,网络输出使用3个卷积核,其余结构均采用=64个卷积核,在上采样结构中,与ESPCN一致,采用亚像素卷积层结构实现特征上采样,从而获得HR的彩色图像。
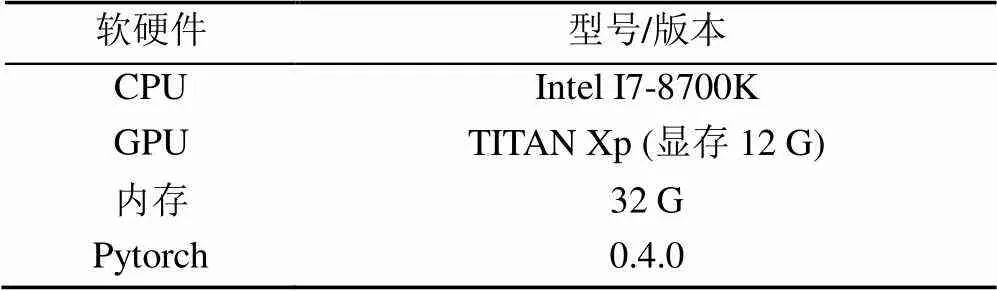
表1 实验的软硬件平台
网络使用ADAM[29]优化器,优化参数为1=0.9,2=0.999,=10-8设置初始学习率为10-4,每2×105次迭代后学习率下降一半,每1 000次迭代后在Set5数据集上做一次测试,以直观反映网络的训练效果,从而可以引导调整网络超参数。实验采用PSNR和SSIM[30]进行重建图像的质量方法的比较,本文需将重建图像转换到YCbCr空间,并在Y通道进行评价对比。
2.3 消融实验
对本文提出的几个改进点进行消融实验对比,以验证本文方法的有效性及可行性。
2.3.1 全局标准差池化及空间注意力机制的影响
本文在未设置空间注意力机制,使用MAE损失函数,无全局特征融合的基础网络框架上进行如下对比实验:①网络中只包括全局平均池化的通道注意力机制;②网络中只包括全局标准差池化的通道注意力机制;③在①的基础上继续引入全局标准差池化,消融实验结构见表2。
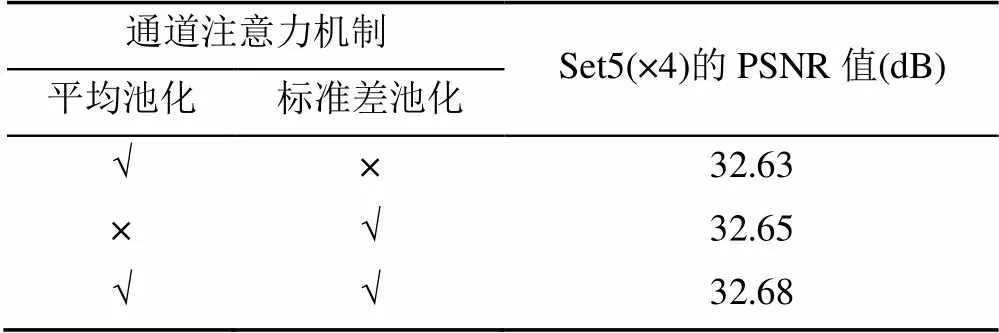
表2 通道注意力中不同池化方式在Set5数据集4倍放大的比较
注:√表示网络算法中包括该模块;×表示不包括该模块。
表2为Set5数据集4倍放大的评测指标对比,可以发现使用全局标准差池化相对于全局平均池化在PSNR指标上有0.02 dB的提升,说明本文提出的全局标准差池化相对于平均池化对通道权重学习具有更好的效果,通过自适应地将平均池化和标准差池化合并,网络算法相对于仅有平均池化的算法有0.05 dB的提升,同时与仅有平均池化的算法需要的参数(16 M)相比仅仅增加0.4 M的参数。因而该结构的改进说明构建标准差池化有利于提升图像重建质量。
最后在Set5数据集上比较了构建双重注意力机制的网络算法与仅有通道注意力机制的算法和仅有空间注意力机制的算法进行实验对比(表3),可以看到双重注意力机制相对仅有空间或者通道注意力机制的算法均有0.04~0.07 dB的提升,也说明双重注意力机制对于图像超分辨率重建具有更好的效果。
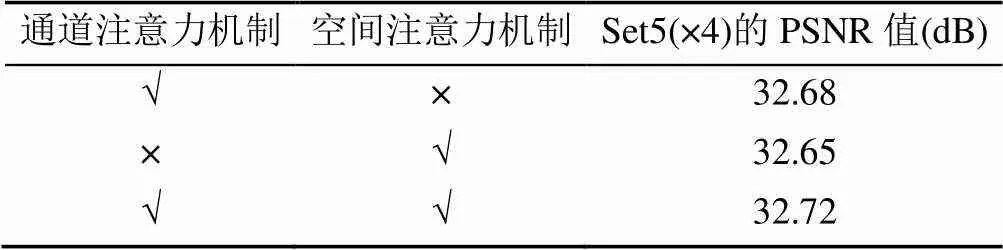
表3 双重注意力机制与部分注意力机制在Set5数据集4倍放大的比较
2.3.2 Huber loss损失函数和全局特征融合的影响
为了证明提出的基于Huber loss的损失函数和全局特征融合对于图像超分辨率重建具有更好的效果,算法与基于MAE的损失函数的模型和无全局特征融合的模型进行了比较。
实验结果见表4,可以看到损失函数相对于MAE损失函数在PSNR指标上有0.02 dB的提升;增加全局特征融合相对于无全局特征融合算法也有0.02 dB提升;本文提出的模型在Set5数据集4倍放大条件下可以获得32.76 dB的峰值信噪比。

表4 不同损失函数和特征融合在Set5数据集4倍放大的比较
2.4 实验结果
为了说明本文方法的有效性,特与VDSR、EDSR[31],RDN[32],RCAN等算法在Set5和Set14数据集不同尺度(×2, ×3, ×4)超分辨率重建结果在PSNR和SSIM评测指标上进行比较,见表5,最优结果加粗显示。从表5结果可以看出,本文提出的超分辨率算法在Set5和Set14数据集上,不同尺度的超分辨结果在PSNR和SSIM评测指标上均优于其他算法(PSNR和SSIM值越大,图像重建效果越好)。为了进一步说明本文提出的算法在实际SR重建图像具有好的效果,本文对Set5、Set14和Urban100的部分图像进行了可视化的重建,挑选了Urban100数据集中的天花板(img_073)和Set5数据集中的蝴蝶(butterfly)的进行了4倍尺度SR重建图像可视化,Urban100数据集中的高楼(img_062)和Set14数据集中书房(barbara)的进行了3倍尺度SR重建图像可视化,并与目前现有的Bicubic, VDSR, RCAN等重建图像进行比较,图6为4倍SR重建结果,在img_073图像中,对天花板重建细节进行比较,大多数的重建算法天花板的孔洞基本模糊,相对较好的RCAN算法的结果孔洞接近矩形,而实际孔洞应当为椭圆形,本文的重建结果不仅孔洞显示较清晰,形状也更接近椭圆。在butterfly图像中大部分重建算法的结果均丢失了右上角一条浅白色向上的纹理,RCAN虽然恢复了一部分,但是也非常模糊,本文算法基本恢复出该细节纹理。图7为3倍SR重建结果,本文对barbara中桌布的细节进行了对比,可以看到方格网状的桌布在绝大多数的SR重建模型(如RCAN,RDN)中重建为线状,EDSR虽然能保留一些方格状的信息,但非常模糊,而本文算法能较好地恢复出桌布的网格信息,同时可清晰地展现。在img_062图像的高楼重建细节中,大部分的算法未恢复出线状的高楼细节纹理,同时产生了横线的错误信息,而本文算法能较好地恢复出细节信息且不存在错误信息。通过定量和可视化的结果比较可知,本文提出的算法相对现有的超分辨率重建算法有了一定的提高。

表5 不同超分辨率模型重建效果比较

图6 在Urban100和Set5数据集4倍超分辨重建可视化比较

图7 在Urban100和Set14数据集3倍超分辨重建可视化比较
3 结束语
本文针对现有的基于深度学习的图像超分辨率重建算法中网络特征由于对不同位置、不同通道的特征采用均等处理的方法,从而使得网络将大量的计算资源浪费在不重要的特征上,受Senet结构启发,本文提出了基于双重注意力机制的深度网络超分辨算法,该算法构建并融合了通道注意力机制和空间注意力机制,从而可以有效获取不同特征的权重值,使得网络可以根据权重精准分配计算资源,在仅仅引入极少参数的同时有效提升了超分辨率重建的质量。特征监督的引入使得网络能够对低维特征有效监督,加快网络收敛,针对MAE损失函数存在的局限性,引入一种特殊的Huber loss损失函数,该损失函数可以实现在损失值较低时梯度递减,从而提高网络重建质量。实验证明本文提出的超分辨率重建算法不仅在评价指标上有所提高,同时在视觉上也有较好的结果。
[1] ZHANG L P, ZHANG H Y, SHEN H F, et al. A super-resolution reconstruction algorithm for surveillance images[J]. Signal Processing, 2010, 90(3): 848-859.
[2] PELED S, YESHURUN Y. Superresolution in MRI: Application to human white matter fiber tract visualization by diffusion tensor imaging[J]. Magnetic Resonance in Medicine, 2001, 45(1): 29-35.
[3] THORNTON M W, ATKINSON P M, HOLLAND D A. Sub-pixel mapping of rural land cover objects from fine spatial resolution satellite sensor imagery using super-resolution pixel-swapping[J]. International Journal of Remote Sensing, 2006, 27(3): 473-491.
[4] DONG C, LOY C C, HE K M, et al. Learning a deep convolutional network for image super-resolution[M]// Computer Vision – ECCV 2014. Cham: Springer International Publishing, 2014: 184-199.
[5] KIM J, LEE J K, LEE K M. Accurate image super-resolution using very deep convolutional networks[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 1646-1654.
[6] KIM J, LEE J K, LEE K M. Deeply-recursive convolutional network for image super-resolution[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 1637-1645.
[7] TAI Y, YANG J, LIU X M. Image super-resolution via deep recursive residual network[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 2790-2798.
[8] HU J, SHEN L, ALBANIE S, et al. Squeeze-and-excitation networks[C]//IEEE Transactions on Pattern Analysis and Machine Intelligence. New York: IEEE Press, 2019: 2011-2023.
[9] WANG X L, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 7794-7803.
[10] ZHANG Y L, LI K P, LI K, et al. Image super-resolution using very deep residual channel attention networks[M]//Computer Vision – ECCV 2018. Cham: Springer International Publishing, 2018: 294-310.
[11] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[M]//Computer Vision – ECCV 2018. Cham: Springer International Publishing, 2018: 3-19.
[12] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 770-778.
[13] SHI W Z, CABALLERO J, HUSZÁR F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 1874-1883.
[14] FADNAVIS S. Image interpolation techniques in digital image processing: an overview[J]. International Journal of Engineering Research and Applications, 2014, 4(10): 70-73.
[15] ZEILER M D, KRISHNAN D, TAYLOR G W, et al. Deconvolutional networks[C]//2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2010: 2528-2535.
[16] DAI T, CAI J R, ZHANG Y B, et al. Second-order attention network for single image super-resolution[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 11057-11066.
[17] HAN J, MORAGA C. The influence of the sigmoid function parameters on the speed of backpropagation learning[M]// Lecture Notes in Computer Science. Heidelberg: Springer, 1995: 195-201.
[18] GLOROT X, BORDES A, BENGIO Y. Deep sparse rectifier neural networks[C]//Proceedings of the 14th International Conference on Artificial Intelligence and Statistics. Heidelberg: Springer, 2011: 315-323.
[19] WILLMOTT C J, MATSUURA K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance[J]. Climate Research, 2005, 30: 79-82.
[20] JOHNSON J, ALAHI A, FEI-FEI L. Perceptual losses for real-time style transfer and super-resolution[C]//European Conference on Computer Vision. Heidelberg: Springer, 2016: 694-711.
[21] LAI W S, HUANG J B, AHUJA N, et al. Deep Laplacian pyramid networks for fast and accurate super-resolution[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 5835-5843.
[22] HUI Z, WANG X M, GAO X B. Fast and accurate single image super-resolution via information distillation network[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 723-731.
[23] ONARAN I, INCE N F, CETIN A E. Sparse spatial filter via a novel objective function minimization with smooth ℓ1 regularization[J]. Biomedical Signal Processing and Control, 2013, 8(3): 282-288.
[24] TIMOFTE R, AGUSTSSON E, GOOL L V, et al. NTIRE 2017 challenge on single image super-resolution: methods and results[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC: IEEE Computer Society Press, 2017: 114-125.
[25] AALST W M P, RUBIN V, VERBEEK H M W, et al. Process mining: a two-step approach to balance between underfitting and overfitting[J]. Software & Systems Modeling, 2008, 9(1): 87-111.
[26] SHORTEN C, KHOSHGOFTAAR T M. A survey on image data augmentation for deep learning[J]. Journal of Big Data, 2019, 6(1): 1-48.
[27] BEVILACQUA M, ROUMY A, GUILLEMOT C, et al. Low-complexity single-image super-resolution based on nonnegative neighbor embedding[C]//Procedings of the British Machine Vision Conference 2012. British Machine Vision Association, 2012: 132-143.
[28] ZEYDE R, ELAD M, PROTTER M. On single image scale-up using sparse-representations[M]//Curves and Surfaces. Heidelberg: Springer, 2012: 711-730.
[29] KINGMA D P, BA J. Adam: a method for stochastic optimization[EB/OL]. [2021-03-12]. https://xueshu.baidu.com/ usercenter/paper/show?paperid=37a73866f09edd03830b234716447e4f&site=xueshu_se.
[30] WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612.
[31] LIM B, SON S, KIM H, et al. Enhanced deep residual networks for single image super-resolution[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). New York: IEEE Press, 2017: 1132-1140.
[32] ZHANG Y L, TIAN Y P, KONG Y, et al. Residual dense network for image super-resolution[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 2472-2481.
Image super-resolution reconstruction based on dual attention mechanism
LI Bin1, WANG Ping1, ZHAO Si-yi2
(1. College of Electronic Science and Technology, National University of Defense Technology, Changsha Hunan 410072, China; 2. College of Computer Science and Technology, National University of Defense Technology, Changsha Hunan 410072, China)
In recent years, the convolutional neural network (CNN) has achieved desired results in the field of single image super-resolution (SISR). Deep networks can establish complex mapping between low-resolution and high-resolution images, considerably enhancing the quality of reconstructed images, compared with the traditional methods. Since the existing SISR methods mainly increase the receptive field of convolution kernels by deepening and widening the network structure, and employ equal processing methods in spatial domains and channel domains of varying importance, a large number of computing resources are wasted on unimportant features. In order to address the realistic problems of the existing models, the algorithm proposed in this paper captured implicit weight information in channel and space domains through dual attention modules, so as to allocate computing resources more effectively and speed up the network convergence. The fusion of global features through residual connections in this network not only focused on learning the high-frequency information of images that had been lost, but also accelerated the network convergence through effective feature supervision. In order to alleviate the defects of the MAE loss function, a special Huber loss function was introduced in the algorithm. The experimental results on benchmark show that the proposed algorithm can significantly improve the image reconstruction accuracy compared with the existent SISR methods.
single image super-resolution; feature supervision; residual connection; channel attention; spatial attention
TP 399
10.11996/JG.j.2095-302X.2021020206
A
2095-302X(2021)02-0206-10
2020-08-25;
25 August,2020;
2020-10-19
19 October,2020
李 彬(1991-),男,陕西渭南人,硕士研究生。主要研究方向为计算机视觉。E-mail:libin10@nudt.edu.cn
LI Bin (1991-), male, master student. His main research interest covers computer vision. E-mail:libin10@nudt.edu.cn
王 平(1976-),男,湖北公安人,研究员,博士,硕士生导师。主要研究方向为智能目标识别。E-mail:wangping@nudt.edu.cn
WANG Ping (1976-), male, researcher, Ph.D. His main research interest covers intelligent target recognition. E-mail:wangping@nudt.edu.cn
