基于数字化技术的农业大数据中心构建
2021-05-12丁作坤
丁作坤
(安徽省农业信息中心,合肥230001)
0 引言
大数据正快速发展为发现新知识、创造新价值、提升新能力的新一代信息技术和服务业态,成为推动我国经济转型发展的新动力、重塑国家竞争优势的新机遇和提升政府治理能力的新途径,是国家的战略资源[1]。农业农村是大数据产生和应用的重要领域之一,是我国大数据发展重要组成部分。随着信息化和农业现代化深入推进,农业农村大数据正与农业产业全面深度融合,逐渐成为农业生产的定位仪、农业生产的导航灯和农业管理的指挥棒,日益成为智慧农业的神经系统和推进农业现代化的关键因素[2]。
在国家政策和数据智能技术的驱动下[3-4],基于全省农业信息系统现状和数据增长趋势,应用数字化技术建设了安徽省农业大数据中心。通过对全省各农业业务系统的梳理和对农业大数据中心的架构设计,将农业相关各类型的数据汇聚到统一的数据库中,搭建分布式数据处理模块和在线数据建模挖掘模块,完成对数据规律和智能应用的探索与实现,并将数据价值赋能到各业务系统,推动安徽省智慧农业的发展。
1 农业大数据中心总体功能设计
安徽省农业大数据中心,通过搭建“一库”、“一图”、“一网”、“一平台”的整理体系,全面打通各部门信息资源的数据交换渠道,实现基础数据共享,业务流程闭环运行的格局。以农业、农村、农民、生态、改革五大领域为主线,面向各级领导建设科学决策平台,提供领导指挥舱;面向各级业务管理人员建设精准管理平台,提供业务直通车;面向生产经营主体、农民与社会公众建设综合服务平台,提供信息服务窗。平台通过海量的数据采集、有效的资源整合以及准确的数据模型,提供丰富的农业应用和多样的用户视图,让使用者能以更易读易懂的方式指导农业生产。
安徽省农业大数据中心功能架构主要围绕管理、服务、支撑、数据四大体系进行设计。支撑体系和数据体系是管理体系和服务体系的底层支撑。服务体系依托于农业应用与资源综合管理平台,提出在线数据建模平台、可视化定制平台、农业知识库、AI 能力开放等服务。管理体系依托图说数据平台,基于农业大数据库的信息支撑,实现对各类涉农主体图形化展示,为管理层的各种决策提供强有力的支撑。支撑体系有数据交换共享平台、在线数据建模挖掘平台、可视化平台三大平台。数据体系有农业资源数据库、农业知识专题库、数据建模专题库和地理图层专题库等四大库。具体如图1 所示。

图1 农业大数据中心功能架构图
数据作为系统的核心资产,在设计系统数据架构时,不仅需要满足事务型数据要求,也需要满足分析型数据的需求。因此在统一规划信息数据时,采用数据仓库[5]的设计思想,将各项农业数据源的数据经过数据整合后,存入不同的数据层,并基于分层数据创建相应的数据应用,整体设计如图2 所示。

图2 系统数据架构设计图
其中STG 层数据主要用来进行数据缓冲处理,是内部数据整合的基础,原则上增量抽取,支持接口表、文件等多种方式分布式采集。ODS 按照数据模型进行落地,主要是明细数据,分为种植业、园艺、畜牧、水产、农机、政务等主题域。DW 数据层存储企业运营的统计、汇总后的数据,是系统的重要组成部分。根据分析应用需求抽取ODS 相关数据所形成的数据集合(数据集市),主要用于数据分析、数据监控、自助取数、数据稽核等应用。通过数据分层设计实现了数据标准化保证数据的一致性、准确性、及时性、明确数据管理,实行生产与分析据的分离,增强数据的深度挖掘应用能力,满足了管理、运营、操作的各个层面的数据需求。
2 农业大数据中心核心模块架构介绍
在构建农业大数据中心时,针对需要将全省的农业相关数据汇聚到统一的数据库的要求,采用了分布式数据采集与汇聚技术来保证数据传输的效率;由于农业数据种类多、数据量大,使用了分布式数据库处理技术来保证数据处理的效率;针对数据挖掘建模需保证数据的安全性的要求,设计了在线数据挖掘建模平台来完成数据在离开平台的前提下完成数据价值挖掘;为了让模型能够赋能更多同类型场景,设计了场景化自动学习模块,使能模型在不同区域不同时间都能有较好的泛化性;为了将数据分析的结果快速地以直观的方式展现给决策者,研发了可视化定制模块实现通过图表编排的方式快速完成定制化大屏设计的需求。从数据生命周期来看,整体的核心技术关系如图3所示。
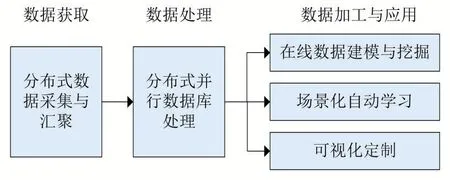
图3 基于数据生命周期的核心技术关系图
2.1 分布式数据采集与汇聚模块
分布式数据采集汇聚模块主要采用注册中心+分布式采集节点的架构设计,每个采集节点既可作为调度节点,同时也作为采集运行节点。由统一配置层进行数据采集任务及调度策略配置,并缓存到Redis。调度节点使采用quartz 集群调度的方式,由Redis 作为jobstore 存储定时任务配置,每个节点分布式进行任务的调度分配以及任务切分。同时利用Redis 集群作为注册中心,分布式节点启动后会自动注册发现,执行数据采集任务。
在任务调度过程中,会根据指定分割策略(包括时间、主键、切片等)进行任务切分,当执行大批量数据、文件采集时,会将任务切成多份,分布式并发采集执行,在软件层面提高传输效率。具体采集过程如图4所示。

图4 分布式数据采集调度流图
在任务传输过程中,采用数据流管道的模式,所有数据进入数据传输管道,由采集汇聚层,根据规则配置,进行读,异构转换,写操作,最终采集汇聚到目标数据源。具体过程如图5 所示。
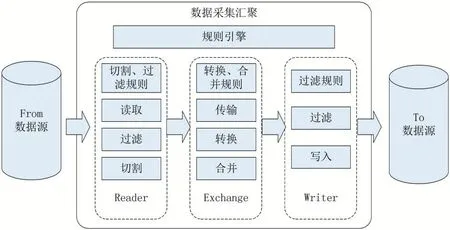
图5 数据汇聚流图
2.2 分布式并行数据库处理模块
由于农业数据具备种类多、增长快等特点,传统的基于Hadoop 体系[6]的数据处理架构不能够满足。因此在构建农业大数据中心的时候,应用了基于Click-House[7]的分布式并行数据库处理,使得数据处理底层具备向量化执行、减枝等优化能力,实现了强劲的查询和处理性能。如图6 所示,通过数据采集模块接入业务数据、政策文件、IOT 数据至相应的数据存储系统,然后使用clickhouse 实现对数据的快速查询与处理,为上层的在线数据建模、可视化报表和业务系统实现查询提供高速数据响应。
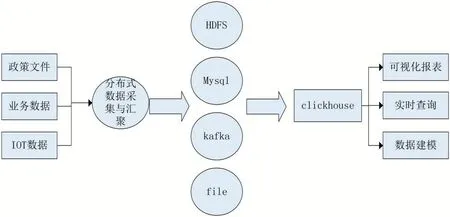
图6 分布式并行数据处理模块流图
该模块的主要特点是支持主键索引和稀疏索引功能。其中主键索引功能是将每列数据按照index granularity(默认8192 行)进行划分,每个index granularity 的开头第一行被称为一个mark 行。主键索引存储该mark 行对应的primary key 的值。对于where 条件中含有primary key 的查询,通过对主键索引进行二分查找,能够直接定位到对应的index granularity,避免了进行全局扫描从而加速查询。
稀疏索引功能是指对任意列创建任意数量索引。其中被索引的value 可以是任意的合法SQL Expression,并不仅仅局限于对column value 本身进行索引。之所以叫稀疏索引,是因为它本质上是对一个完整index granularity(默认8192 行)的统计信息,并不会具体记录每一行在文件中的位置。
2.3 在线数据建模与挖掘模块
对于汇聚到大数据中心的农业相关数据,需要在平台里直接完成数据规律探索和价值挖掘,形成数据能力并赋能业务应用。通过将在线数据建模和挖掘相关算法、方法进行封装成可视化算子,研发基于可视化算子编排的在线数据建模与挖掘模块,构建了包括数据处理、特征工程、模型训练、模型评估、模型部署的全流程AI 开发组件[8]。主要是将数据建模过程中常用的数据处理方法、特征工程方法、算法封装成可视化算子,开发者根据需要将相应的算子拖到工作区,并根据数据流程将相应的算子连接起来,即可构建相应的数据探索或数据挖掘的流图。通过数据在数据图中流动处理实现数据的探索与建模。具体如图6 所示。
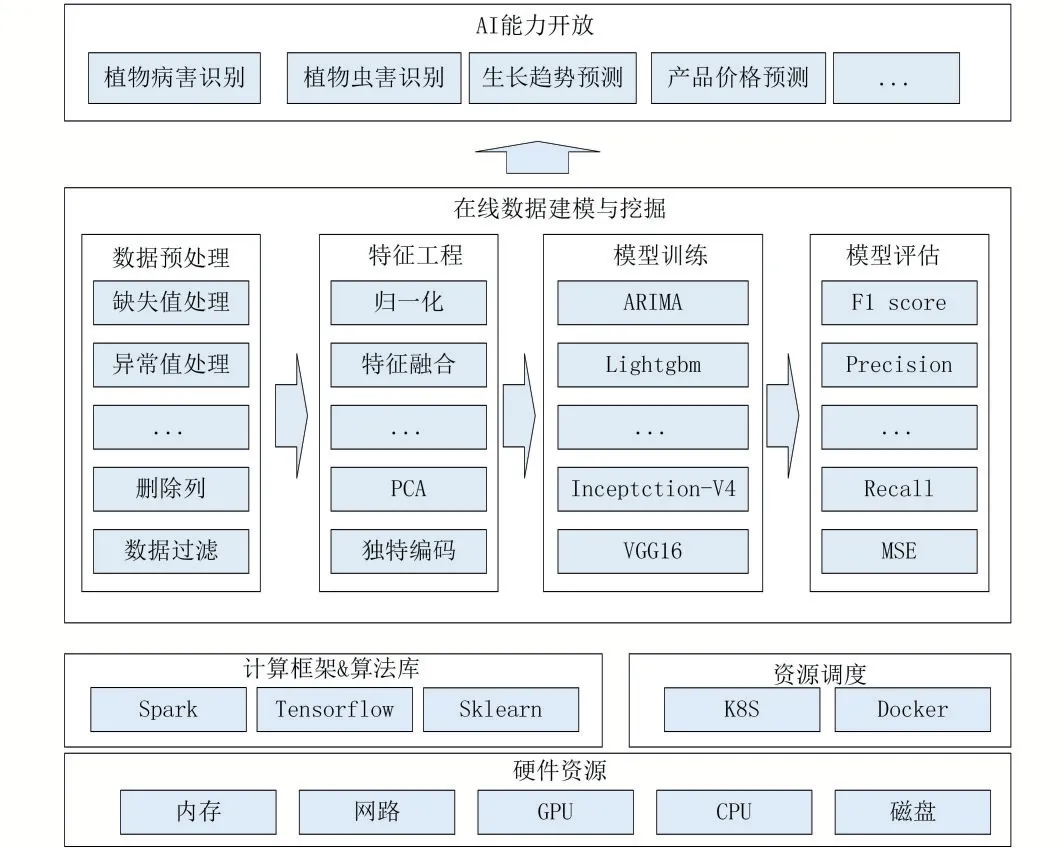
图7 基于可视化算子的在线建模与挖掘功能架构图
数据准备部分主要包括从本地导入、从大数据中心导入两种方式。数据处理部分主要包括删除重复行、删除列、数据过滤、缺失值填充、异常值处理、上采样、下采样、ADF 检验、数据拆分等算子。特征工程部分主要包括数值化映射、归一化、卡方、信息熵、特征融合、离散化、独热编码、PCA 降维、孤立森林等算法。
模型训练主要分类时序预测、分类预测、图像分类三个类型,时序预测算法主要有ARIMA、prophet、LSTM[9]等算法,分类预测主要有LightGBM、XGboost、Catboost[10]等算法,图像分类包括ALexNet、VGG16、InceptionV4[11]等算子。数据可视化部分主要包括数据透视表、柱状图、折线图等。模型评估主要包括MSE、MAE、F1-score、查准率、查全率、AUC 等主要算子。模型部署主要包括在线部署、离线SDK 部署两种方式。
2.4 场景化自动学习模块
通过平台的在线建模功能构建的农业智能应用,由于其是基于特定场景下的数据训练得到的,在不同的时间点和区域的应用条件下,无法得到最好的预测效果。另外传统的方法是只能重新经过数据建模过程构建具体场景的应用模型,费时耗力。因此提出了场景化自动学习的方法,用户只需要选择相应的场景,提供相应的数据即可快速得到一个高可用的模型能力。
场景化自动学习主要分为两部分,一部分是场景化,另一部分是自动化机器学习[12]。其中场景化主要是指基于农业大数据中心的数据创建农业智能应用场景,主要包括价格趋势预测、植物虫害识别、植物病害识别、植物生长预测等。自动化机器学习是将自动化和机器学习相结合的方式,将数据建模过程中的数据处理、特征工程、算法选择、模型评估的复杂过程封装成一个黑箱子,仅需输入符合要求的数据即可得到相应的模型。
为了充分利用场景下历史模型的价值,将模型根据实际的场景进行细分,结合自动机器学习技术和迁移学习技术,实现在历史模型的基础上,使用新场景数据进行参数微调,快速训练具体数据条件下的有效智能模型。具体如图8 所示。
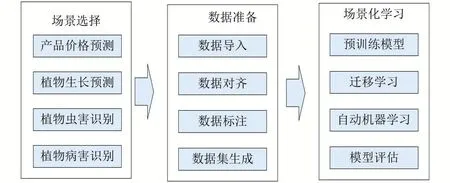
图8 场景化自动学习流程图
2.5 可视化定制模块
通过从地理空间、时间序列、逻辑关系等多种角度分析数据,把不同维度的数据规律以适当的视觉方式呈现出来,以便决策者理解数据背后蕴藏的价值、规律、趋势和关系。针对农业大数据的数据种类多样、分析场景丰富等特点,平台应用了可视化定制技术,实现对农业涉及的种植业、畜牧业、渔业、科技教育、农业机械等专题数据的定制化大屏快速创建。
基于大屏可视化定制技术的大数据可视化平台,总体功能从逻辑上分为支撑层、平台层和应用层。支撑层主要提供数据访问能力,支持多种数据源的连接。实现数据交换、数据分析与计算、数据存储及数据建模的能力。平台层主要提供可视化编排/运行的能力。通过基础管理保障平台安全,而开放服务提供了强大的代码注入能力和可视化组件开放能力,集成框架使得编排的页面可以无缝的集成到第三方业务系统。应用层为最终成果产物,支持Dashboard、交互式Web 应用、自助式分析、可视化大屏、高级数据可视等多种表现形式。具体架构如图9 所示。

图9 可视化定制模块架构图
3 结语
通过构建农业大数据中心,一方面实现将农业各类型数据汇聚到统一大数据库中,消除数据孤岛,实现各业务系统数据互通互联,能够有效提升业务办理效率;另一方面,通过在线建模挖掘技术和可视化定制技术,实现对数据价值的充分挖掘,赋能农业智能化生产,辅助管理者精准决策。
目前,安徽省大数据中心已打通数据接口,建立部、省、厅属涉农数据的交换共享建立数据交换标准和规范,实现农业农村部数据、省政务数据、厅属业务数据的汇聚和交换。基于大数据中心,建立线上业务流程,将传统的线下纸质的报告信息工作转变为线上的信息填报审核流程,全面提供办公人员工作效率。融合分布式数据处理和可视化定制,建立图说平台,搭建领导驾驶舱,实现将数据规律以直观易懂的方式呈现,辅助精准决策。基于在线数据建模组件和场景化自动学习,融合大数据中心数据,实现了小麦病虫害识别、小麦生长趋势预测、填报异常数据检测等一些AI 能力应用,赋能农业智慧生产。
随着大数据中心数据的积累,为进一步释放数据价值,后续将从两方面探索数据应用。一方面是融合农业的业务数据、图像数据、农技数据等多模态知识数据,应用知识图谱技术[13],构建农业智能助手,实现自动业务办理;另一方面将农业数据进行价值共享,应用联邦学习技术[14],在数据不可见的前提下共享数据能力,助力农业相关领域的智能化演进。
