一种改进的基于肤色和模板的人脸检测流程
2021-05-12王韬胡紫薇王晔
王韬,胡紫薇,王晔
(四川大学计算机学院,成都610065)
0 引言
人脸检测的目标是在图像中快速准确地定位出人脸的位置,大致可以分为以下几类,艾海舟、梁路宏等人[1]提出的基于肤色和模板的人脸检测方法,首先对图像进行肤色分割提取出其中的肤色区域,再对肤色区域使用模板匹配和人工神经网络进行验证。对于灰度图像无法进行肤色分割的,梁路宏等人[2]提出了基于多关联模板的检测方法,首先用双眼的模板匹配做粗筛选,再使用模板匹配做精筛选,最后通过经验模型判定候选区域是否是人脸。姜军、张桂林[3]也提出了一种基于先验知识的人脸检测方法,主要利用了人脸的生理结构特征,提取人脸图像的灰度和边缘信息,使用镶嵌图(马赛克图)根据足够多的人脸样本建立的完备库做分析,以达到对目标区域的判别。崔晓青[4]则提出了改进的AdaBoost 人脸检测算法,这类方法主要基于对人脸的特征提取并联合机器学习的分类器工作,算法会依据某类特定的特征子,如AdaBoost 算法主要使用Haar 特征,并将多个弱分类器组合成为一个能够辨别人脸的强分类器。江伟坚[5]同样采用了类似的方法,改进了Haar-Like 算子,并分别训练了正脸和侧脸的级联分类器,获得了不错的效果。另外,还有基于统计模型的人脸检测方法,陈建华[6]则提出了一种在灰度图上使用高斯模型检测人脸的方法。最后,还有一类算法以机器学习的原理为核心,马勇、丁晓青[7]提出了一种基于层次型支持向量机的正面直立人脸检测方法,使用了一个线性的支持向量机和一个非线性的支持向量机联合工作,前者做粗检测,后者做精检测。王鲁许[8]则使用了基于神经网络的人脸检测方法。
本文对传统的基于肤色分割和人脸模板匹配的检测方法做出了系列改进,旨在于提升此流程的人脸检测精度。在肤色分割阶段提出一种改进的自适应二值化方法,以尽可能的将图像中的肤色区域提取出来,在之后的连通域分析阶段提出了一种基于能量分布的分析策略,进一步筛除低概率的人脸区域,最后模板匹配阶段使用了多尺度的模板匹配以获取更精确的人脸位置,并提出了一种联合的相似度判别法。
1 基于肤色分割和连通域分析的粗检测
1.1 建立肤色模型
人脸的肤色在数字图像中符合高斯分布,为建立肤色的高斯模型,首先需要收集肤色样本,对这些样本的统计分析以获得该高斯模型的参数。为减轻光照影响将RBG 图像转换到YCbCr 色彩空间。其中Y 是亮度分量,Cb 和Cr 分别是蓝色色度分量和红色色度分量,从RBG 转换到YCbCr 空间的关系式为:

本文直接采用了加利福尼亚大学信息与计算机科学学院提供的肤色像素数据集[9],该肤色数据集总共包含了50859 个肤色样本,包括了各类人种以及不同条件下的肤色。该数据集合转换至YCbCr 域后在CbCr平面的统计如图1 所示。

图1 肤色数据集分布
由图1 可以看出肤色在CbCr 平面具有良好的聚集特性。已知二维高斯分布的联合概率密度为式(2)。

其中μ1、μ2、σ1、σ2分别是随机变量x 和y 的均值和方差,ρ 则是x 和y 的相关系数,表示为:

其中E 表示均值,D 表示方差。由此,根据x,y 的均值和方差即可得到构建的关于x 和y 的联合概率密度模型。于是,以图1 中Cb 和Cr 为随机变量建立肤色高斯模型,如图2 右所示。
由2 图中可以看出高斯模型很好地表达了肤色样本在CbCr 平面的分布状态。如图3 展示了由肤色高斯模型处理得到肤色似然图,每个点的值代表了该点是肤色的概率,可以看出模型很好地区分了肤色区域和非肤色区域。

图2

图3
1.2 自适应二值化
获得了肤色似然图之后需要确定一个阈值以区分肤色和非肤色区域。阈值选择的太小则会造成大量的非肤色区域被选中,导致粗检测精度太低。阈值太大则可能导致真正的人脸区域未被判定为肤色区域。从图3 中也可以看出不同的人脸在不同光照下的肤色似然图强度有很大差距。
设计自适应的二值化方法,基于以下假设:
(1)图片内的肤色区域和非肤色区域的似然值存在较大差异
(2)图片内的肤色区域和非肤色区域似然值有较好的聚类特性,即对于两个区域的点而言,它们各自的似然值是比较接近的,方差较小。
我们期望肤色区域的均值和非肤色区域的均值差异尽量大,而二者各自的方差尽可能小。根据此原理王金庭等人[10]提出了Fisher 函数(式5)作为选择阈值t的标准:


式中skinNum 表示肤色像素的数目,w 和h 分别为图像的宽和高。为抵消(5)式更倾向于分配少量肤色区域的影响,本文在(6)式中增加了两个因子,以控制肤色区域被提取出来的面积。大部分情况下肤色区域和背景色之间差异很大,这时使用(6)式的肤色提取就会更准确。

图4
图4 是根据(6)式策略实现的自适应二值化,可以看到即使似然图中的肤色区域强度很低,该方法依然可以很好地将其提取出来。本文还对固定阈值分割、(5)、(6)三种方案做了对比实验。对比实验使用了Wei Ren Tan[11]的肤色数据集如图5 所示。
本文对这三种方法的对比实验使用了3 种参数,Recall(查全率)、Precision(查准率)和IOU(交并比)。图6 说明了这三个参数的含义。
对于固定阈值的二值化方法,本文测试了由0 到0.8 区间,间隔0.02 的所有阈值在肤色数据集上的表现,结果如图7 所示。IOU 参数作为Recall 和Precision 的综合,本文主要以IOU 比例为参考,对于固定阈值而言,选定IOU 最高的作为最佳阈值。

图5 肤色数据集

图6 测试参数
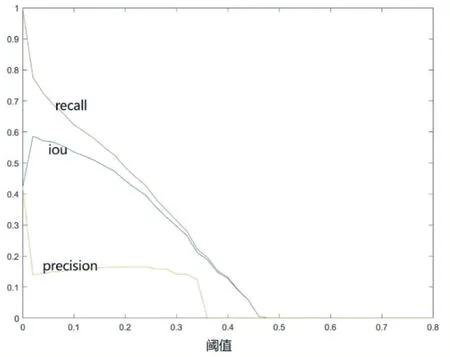
图7 不同阈值的二值化结果
三种方法的对比结果如表1 所示。可以看出本文的改进方法在IOU 和Precision 项目都得到了比较好的成绩,固定阈值二值化方法则Precision 值较低,说明其误检率很高。而(5 式)的方法则在各方面都差一些。
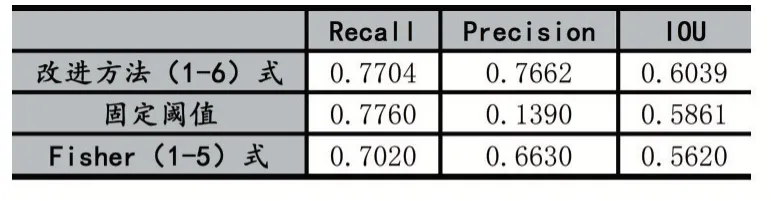
表1 三种二值化方法对照
1.3 连通域分析
二值化后的图片中包含了很多大小不一的连通域,要对这些连通域做进一步的筛查,然后求取其外接矩形以确定粗检测的范围。筛选规则包括以下几条:
(1)去除面积较小的连通域
(2)去除外接矩形横纵比不合适的连通域(人脸的横纵比大约为1:1,由于是粗筛选,连通域的横纵比本文采用0.6-1.2)

图8 形态学处理
基于以上两条筛选规则已经可以筛除大部分非人脸区域,但存在如图8 这样的特殊情况,会使得这样的筛选结果较差。可以看出a、b 属于将背景识别为了皮肤,c、d 属于两个人脸太靠近发生了粘连,这两种情况都会对下一步的精检测造成不利影响,对于图8 中的a情况,解决方案是:提取出来的肤色区域中,人脸区域应当是接近于矩形的块状区域,那么可能包含人脸的连通区域应当满足以下条件:

其中s 表示联通域的面积,rectangleArea 表示连通域外接矩形的面积,ρ 为一个经验值,本文取0.6。这一判定条件可以有效的去除类似图9 所示的非人脸区域。对于c、d 情况,解决的思路是:对外接矩形的区域不断地做形态学的腐蚀处理,直到该区域内原来的连通域出现断连,即原来的只有一个连通域的区域内由于做了腐蚀而出现了多个连通域,再分别判定这两个连通域是不是可能的人脸区域(判定的规则已有前文给出)符合要求的话就做形态学的膨胀处理以补偿腐蚀造成的损失。对于不符合要求的则直接抛弃。当然可能一直做腐蚀处理都没有分裂出多个连通域,那么直到连通域被腐蚀为0 就抛弃这个联通域。算法的实现效果见图10。

图9 非人脸连通域的外接矩形(虚线)

图10 改进的连通域分析
2 基于模板匹配的精检测
经过了肤色检测以及连通域分析之后我们已经初步得到了人脸检测的区域。但这些区域中有非人脸部分,为了获得更准确的人脸定位,还需要对这些可能的区域做人脸的精检测,本文采用的是模板检测。
2.1 人脸模板
本文采用了英国剑桥Olivetti 研究实验室创建的ORL 人脸数据集构建平均人脸模板。数据集的部分图像如图11 所示。从该数据集中选择40 个人的正脸图像,首先对这些图像做灰度直方图标准化,以使得它们之间的灰度分布统一,减少光照色度的影响。之后再对这些图像做平均就得到了人脸模板。

图11 ORL数据集
灰度直方图均衡化是指对原始图像做式(8)的变换:

其中,σ0、μ0分别是图像的方差和均值,σˉ、μˉ则表示标准的灰度直方图方差和举止。本文中,σˉ、μˉ为所有图像的方差、均值的平均。图12 就是制作的平均人脸模板。

图12 平均人脸模板
2.2 自适应多尺寸模板匹配
本文所设计的人脸检测系统在初始阶段将会把输入图片统一到250×250 像素。粗检测获得了图像中的肤色区域,精检测通过设置一系列尺寸的模板和区域的子窗口图像逐一匹配,选取相似度最高的一个窗口,检查其相似度是否超过经验阈值,作为判定为人脸的依据。
本文设计了一种对人脸模板的缩放规则:人脸模板的尺度空间和待搜索区域(粗检测区域高h,宽w)的尺寸相关。这种关联规则为:
(1)人脸模板的横纵比尽可能保持不变
(2)人脸模板的高bh 和宽bw 由式(9)确定
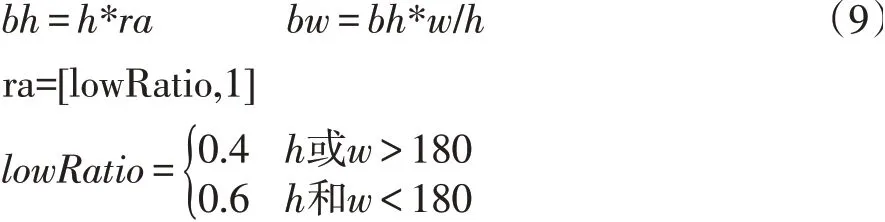
其中ra 为一系列值,间隔一般为0.1,由式(9)说明,人脸模板的最小尺寸是和待搜索区域相关的。由于本文所处理的图像都是统一250×250 像素的,并规定在这一尺度下的人脸尺寸基本在100×100 像素左右。因此,待搜索区域的长或宽超过180 像素则表示粗检测区域较大,区域内包含的信息也更多,因此采用更小尺度的精检测模板。当待搜索区域较小时,整个带搜索区有很大的可能就是人脸,则没必要用更小的模板去搜索。
2.3 联合相似度模型
在模板检测的流程中,系统需要从众多的扫描窗口中选取出和模板相似度最高的一个。图13 为搜索的示意图。

图13 模板匹配的搜索窗口
在基于肤色的人脸检测算法[12]一文中采用了式(10)的度量方式。其中Win 表示窗口图像,T 表示人脸模板,M、N 表示窗口的高和宽。这种度量方式是计算了窗口图像和模板之间的欧氏距离。R 的取值范围在[0,1],R 越小说明二者的相似度越高。

在基于多关联模板匹配的人脸检测[2]中采用的则是一种联合的相似度度量如式(11)(12)(13)所示,α取经验值35。式(11)中μ、σ 是对应图像的灰度均值和方差。式(11)首先用减去了图像的均值,使得窗口图像和模板的灰度分布得到了一定的统一,消除了部分光照差异的影响。
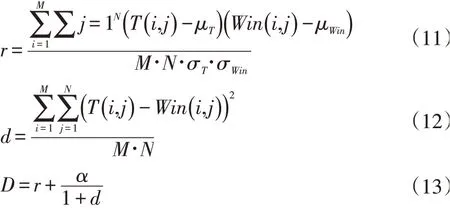
但是基于(9)或(13)设计的相似度标准,选择所有窗口中相似度最大的窗口,最终的检测结果会倾向于选择那些尺度更小的窗口,如图14 的上半部分测试样例。更小的搜索窗口会获得更高的相似度。这是由于本文所采用的不同尺度的人脸模板都来自于标准模板的缩放得到。如果是比标准模板小的,则通过间隔采样完成,如果是比标准模板大的,则通过双线性插值完成。由于模板的尺寸和粗检测的区域大小有关,有可能造成实际的人脸模板被缩得很小。对模板的缩小造成了信息的损失。在这种情况下小模板与小窗口图像匹配的值通常大于大模板和大窗口的匹配值,也就造成了图14 上半部分的实验结果。

图14
针对以上问题本文根据实验对模板检测的相似度度量方式做出了式(14)的改良。

其中的常数为实验获得的经验值,r 来自式(11),ra 来自式(9),d 来自式(12),式(14)的设计思路是:
(1)式(11)作为主要的判别方式
(2)对于较小的人脸模板将给予一定的惩罚,也就是(14)的第二项,窗口比例小于0.6 的都会导致第二项为负数,这样可以减轻小窗口的影响
(3)实际应用中,单独使用式(12)的d 难以得到好的结果,但d 值作为判别的标准之一时可以使得系统的精准度更高
最终使用式(14)的结果如图14 下半部分所示,可以看到由于加入了对小窗口的惩罚,使得系统不再倾向于选择小窗口,检测精度得到了提升。在图15 中给出了人脸模板检测的具体流程。最后,图15 中所示最大的窗口模板相似度记为maxSimilarity,当满足maxsimilarity>ρ 时,即判定该窗口为人脸,ρ 取经验值0.45。
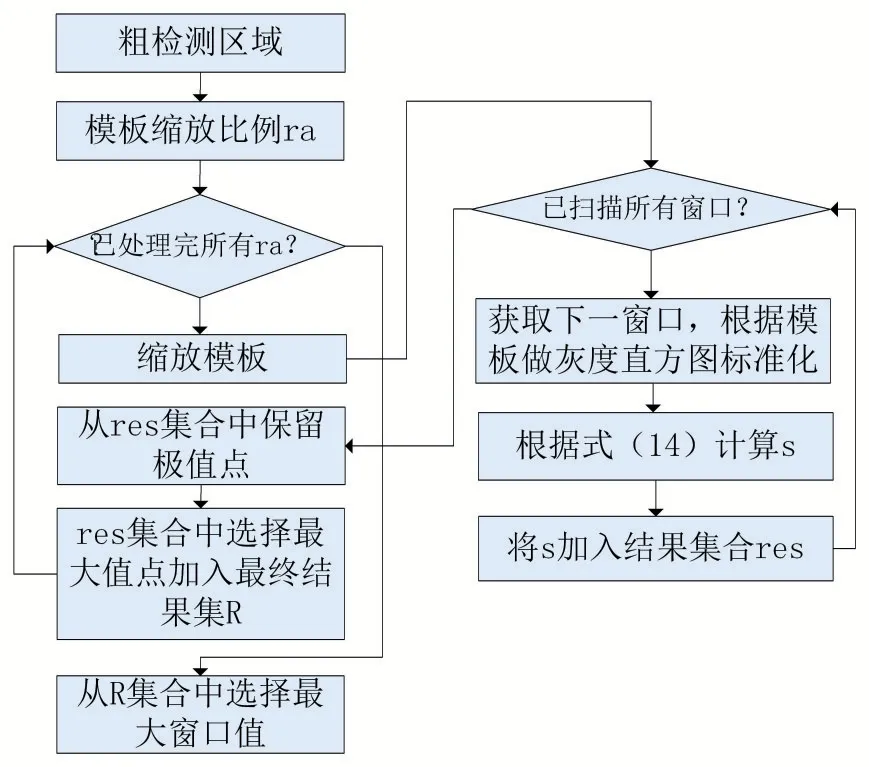
图15 模板检测流程
3 实验结果和总结
本文实现的系统在Multi-Task Facial Landmark(MTFL)dataset[13](后简称MTFL 数据集)数据集上做了人脸检测测试。并对比了基于式(10)、(13)和(14)三种相似度度量的系统,以说明本文改进方法(14)的有效性。

表2 各方法测试结果
由表2 所示,本文在MTFL 数据集中随机抽取了4321 张单人脸图片对三种方法实现的人脸检测系统做了测试,可以看到改进的方法(14)在查准率和查全率两方面都有更好的效果,说明了改进的有效性。图16是一些图片的检测结果展示。

图16 检测结果展示
最后,人脸检测是一个复杂的系统需要应对复杂的检测环境,不论是神经网络还是传统方法都有各自的应用场景。本文给出了对于传统人脸检测方法的一些改进思路,在人脸检测的流程中还有很多可以改进和尝试的,这些都有待于更进一步的研究。
