一种顾及时间特征的船舶轨迹DBSCAN聚类算法
2021-05-11郭乃琨陈明剑
郭乃琨,陈明剑,陈 锐
(1.信息工程大学 地理空间信息学院,河南 郑州 450001;2.92493部队,辽宁 葫芦岛 125001)
近年来,全球卫星导航系统(Global Navigation Satellite System,GNSS)、北斗卫星导航系统(BeiDou Navigation Satellite System,BDS)等卫星导航定位系统迅速发展,已经成为国防军事、国民经济发展中必不可少的基础设施[1]。
随着世界海洋经济的迅速发展,各国海洋贸易中的船舶数量随之剧增,船舶自动识别系统(Auto Identification System,AIS)已被世界各国广泛采用。全球船舶轨迹数量庞大、内容丰富,除了与常见的陆上轨迹一样具有海量性、动态性、时序性特征外,还具有一系列的独特性,陆上轨迹主要反映对象在陆地上的时空变化规律与行为模式,而船舶轨迹主要反映对象在海上的相应规律与模式;船舶轨迹在形成过程中,更多地受到水系的固有约束,并且其数据相比陆上轨迹具有更多的字段,属性维度更高。因此,运用简单、常规的数据分析方法很难从船舶轨迹中分析出全面、有价值的隐含信息。
聚类分析是众多数据分析与挖掘方法中应用最广泛的方法,通过衡量研究对象之间的相似度(距离度量),将相似度高的对象划分为同类。按照聚类的目标、处理的数据以及具体应用领域的不同,聚类分析可分为基于划分的聚类、基于层次的聚类、基于密度的聚类、基于网格的聚类和基于模型的聚类。其中,基于密度的聚类是近年来在交通流挖掘、商业中心选址、图像分割与识别等诸多领域得到广泛应用的经典聚类算法,其中又以基于密度的对噪声鲁棒的空间聚类算法(Density-Based Spatial Clustering of Application with Noise,DBSCAN)最为常用。DBSCAN算法相比其他算法无需指定簇的个数,可以对任意形状的数据集进行聚类,常用于离群点监测。但经典的DBSCAN算法仅适用于空间聚类,对于具有时间、航速等多维、动态信息的船舶AIS轨迹而言不再适用。本文提出一种顾及时间特征的船舶轨迹DBSCAN聚类算法,在经典DBSCAN的基础上,通过定义船舶轨迹间的时间距离来衡量其时间相似度,进而定义时空距离来衡量时空相似度,实现船舶轨迹的时空聚类。
1 相关工作
1.1 经典DBSCAN算法
DBSCAN是一种典型的基于密度的聚类算法,最初主要用于点或可视为点对象的聚类,通过将簇定义为密度相连的点的最大集合,可以有效找到样本点的全部密集区域,这些密集区域即被视为聚类簇[2]。DBSCAN算法的聚类过程如图1所示。

图1 经典DBSCAN算法流程
目前的相关研究主要围绕对经典DBSCAN算法的聚类效果改进而展开。许虎寅等[3]在DBSCAN算法的基础上,提出一种改进的基于密度的聚类算法,有效减少核心点邻域的重叠区域的查询时间和次数;王光等[4]提出一种改进的自适应参数DBSCAN算法,对MinPts和Eps参数基于核密度估计进行确定,基于4种经典数据集的对比实验证明该算法在参数选择自动化和准确率方面的优势;李建伏等[5]基于马尔科夫链蒙特卡洛方法MCMC对DBSCAN方法进行改进,提出一种基于MCMC的DBSCAN算法DBSCAN++,并且与经典DBSCAN算法和OPTICS算法进行对比分析实验,结果表明DBSCAN++算法聚类的高效性与准确性。
1.2 船舶轨迹聚类算法
船舶轨迹聚类的目的是采用相关的聚类算法对轨迹数据进行聚类,找出具有相似船舶运动演化方式的轨迹簇[6-8],揭示船舶轨迹间潜在的关系,分析船舶交通流特征或个体船舶的行为。通过对船舶轨迹数据进行处理和聚类分析,可以对船舶的运动规律进行量化,并进一步探测船舶的异常行为,从而有效提升海上交通态势感知能力,为海事安全监控与预测提供决策支持。船舶轨迹数据一般是指基于AIS的轨迹数据[9],主要是从AIS基站获得,因此当前大部分的船舶轨迹聚类研究均为针对船舶AIS数据的聚类分析,其分析流程如图2所示。

图2 船舶AIS轨迹聚类流程
船舶 AIS轨迹数据采集的过程中,需要对船舶 AIS轨迹数据进行预处理,以提高数据质量,常见的预处理过程包括数据编码与清洗、缺失数据处理、降维处理、数据压缩等内容:船舶轨迹聚类方面,Huttenlocher等人[10]证明利用Hausdorff距离比其他度量两个点之间距离的相关算法具有更强的鲁棒性;Zheng等[11]将K-Means聚类算法用于船舶轨迹的聚类,用欧式距离计算船舶轨迹相似度,利用开源数据挖掘工具WEKA对长江某航段船舶到达时间、船舶吨位、船舶类型等属性分别进行聚类,获得有价值的交通特性信息[12];Vries等人[13]将船舶轨迹看作时间序列,采用态时间规整(Dynamic Time Warping,DTW)和ED来计算轨迹的相似度;Pallotta等人[14-15]对DBSCAN算法进行改进,采用增量DBSCAN算法对船舶AIS轨迹数据中的转向点聚类,在此基础上分析船舶的交通流模式。Liu等人[16]在考虑船舶轨迹数据中非空间属性(如船速、航向等)基础上,对DBSCAN算法进行改进,在输入参数中新增船舶最大的船速变化量(MaxSpd)和最大的航向变化量(MaxDir)两个变量。
1.3 相关研究分析
传统的轨迹聚类方法主要面向居民日常出行、活动和旅游等现实场景,如常见的出租车轨迹聚类、热点区域分析、居民出行模式挖掘、载客路径挖掘、重要兴趣点识别等,面对复杂问题时需要设置的条件和参数较多,并且大部分方法的可移植性较差,很难被应用到新的数据集上。上述船舶轨迹聚类的相关研究中,基于距离的聚类方法对船舶轨迹进行聚类具有算法简单、实现容易的优点,但由于基于距离的轨迹相似度度量方法本身的不足,仍然存在容易丢失轨迹局部特征信息等不足;与基于距离的船舶轨迹聚类方法相比,采用经典DBSCAN等基于密度的聚类算法对船舶轨迹进行聚类,其优势主要表现在能发现任意形状的船舶轨迹簇,且对异常的船舶轨迹鲁棒性较强,轨迹聚集的结构与样本轨迹的遍历顺序也无关。但DBSCAN算法主要适用于空间聚类,即通过定义空间距离对象的空间相似度进行衡量,对于具有典型的多维、时变和空间动态特征的船舶轨迹很难达到理想的聚类分析效果。
2 顾及时间特征的船舶轨迹DBSCAN聚类算法
2.1 算法概述
鉴于经典DBSCAN算法主要适用于空间聚类,对具有时变动态信息的船舶轨迹聚类适用性差的现状,本文提出一种顾及时间特征的船舶轨迹DBSCAN聚类算法。该算法在经典DBSCAN空间聚类算法的基础上,首先对船舶轨迹数据进行数据编码与清洗、缺失数据处理、数据压缩等一系列预处理,在此基础上提出了基于OD(Origin-Destination)点 、SP(Stay-Point)点以及TF(Trajectory-Feature)点的轨迹特征点提取方法,以此生成船舶AIS轨迹的子轨迹;然后提出船舶子轨迹段之间的时间距离度量方法,并通过设置权重调整时空特征敏感度,最后使用DBSCAN算法对时空邻域密度进行聚类分析,进而挖掘船舶轨迹的典型时空运动模式。相比于空间聚类,顾及时间特征的船舶轨迹DBSCAN聚类算法可以同时兼顾船舶轨迹的空间与时间特征,得到的聚类可以更加细化,移动通道更准确,有利于对船舶的移动规律做更进一步的分析,进而为合理规划航路及海事监管中的热点航道提取和异常事件预防提供有效的决策手段和参考信息。
2.2 算法流程
本文提出的顾及时间特征的船舶轨迹DBSCAN聚类算法流程如图3所示。

图3 顾及时间特征的船舶AIS轨迹聚类流程
2.2.1 船舶轨迹数据预处理
首先是数据准备工作,将采集到的船舶轨迹数据,利用空间关系型数据库(如PostgreSQL)进行存储,数据库表的内容主要包括MMSI码、船舶位置、航向、航速、船舶大小、UTC时间等。由于船舶AIS设备以“明码”和“暗码” 两种压缩编码的形式传输数据,运用AIS数据解析程序从原始数据中提取所需内容并导入数据库。
然后是轨迹数据预处理工作,船舶轨迹原始数据通常存在噪声和偏差的问题。为了保证后续轨迹特征点选取的精度和速度,需要对船舶轨迹数据进行预处理:删除MMSI码错误的数据;删除船舶位置的经纬度出现负值或是经度大于180°、纬度大于90°的数据;删除航速为负值或大于60 kn的数据;删除超过研究水域范围的数据等。
2.2.2 特征点提取
将每条船舶轨迹按照OD点 、SP点和TF点的判定条件进行轨迹特征点的提取,将提取出的三类轨迹特征点组成代表该条轨迹运动规律的特征点集合。将集合中的相邻特征点按时间先后顺序排列依此连接生成该条轨迹的子轨迹。最终由这些特征点集合生成所有船舶轨迹的子轨迹集合。其中,通过如下方法对OD点、SP点和TF点进行筛选和提取。
首先,将每条船舶轨迹的起点和终点选取为该条船舶轨迹的OD点。然后通过设置时间阈值和速度阈值,如果相邻轨迹点之间时间差大于特定的时间阈值,而两个轨迹点的速度值都小于设定的速度阈值,则将两个相邻的轨迹点识别为该条船舶轨迹的停泊点,记为SP点。最后利用曲线边缘检测法对每条船舶轨迹的所有轨迹点进行识别,将符合判定条件的轨迹点选取为轨迹特征点,记为TF点,曲线边缘检测法的过程如下:
1)假设给定一条船舶运行轨迹,其中的P1(x1,y1),P2(x2,y2),P3(x3,y4)(x1 T12(x,y)=(y2-y1)(x-x1)+ (y-y1)(x2-x1). 2)计算轨迹点P3(x3,y3)关于正向直线方程T12的值,若T12(x3,y3)<0,则称轨迹点P3(x3,y3)是关于正向直线的内点;若T12(x3,y3)>0,则称轨迹点P3(x3,y3)是关于正向直线外点。 3)连接轨迹点P2(x2,y2)和P3(x3,y3)构成一条关于轨迹的正向直线T23,对应的正向直线方程为: T23(x,y)=(y3-y2)(x-x2)+ (y-y2)(x3-x2). 4)计算轨迹点P4(x4,y4)关于正向直线方程T23的值,并根据上述方法判断轨迹点P4(x4,y4)为内点或外点。 5)若T12(x3,y3)·T23(x4,y4)<0,说明轨迹在P3(x3,y3)处方向有所改变,则轨迹点P3(x3,y3)是特征点,即为TF点,否则P3(x3,y3)不是TF点。 6)依次循环判断,直到最后一个轨迹点,即可识别出船舶运行轨迹的所有TF点。 2.2.3 子轨迹段划分 根据上述提取出的三类轨迹特征点(OD点、SP点和TF点)组成该船舶运行轨迹的特征点集合,将特征点集合中的相邻特征点按时间先后顺序排列,依次连接生成该条轨迹的子轨迹,其中相邻两个特征点的线段称为子轨迹段,如图4所示。 图4 子轨迹段划分流程 2.2.4 时空距离定义与计算 这一步主要计算任意两子轨迹段之间的空间距离和时间距离,对得到的空间距离和时间距离进行加权求和得到融合后的时空距离。 1)空间距离定义与计算。本文中两子轨迹段之间的空间距离是根据船舶位置信息计算得到的,包括平行距离、垂直距离和角度距离3个方面。设两条子轨迹段Li和Lj,记为Li(si,ei)和Lj(sj,ej),其中si,ei和sj,ej分别为子轨迹段Li和子轨迹段Lj的起点和终点的位置信息,由子轨迹段Lj向Li垂直投影,如图4所示,其中,Ps和Pe为Lj在Li上的垂直投影点。则子轨迹段Li和Lj之间的垂直距离为: 子轨迹段Li和Lj之间的平行距离为: d‖(Li,Lj)=MIN(l‖1,l‖2); 角度距离为: dθ(Li,Lj)= 综上,得到子轨迹段Li和子轨迹段Lj之间的空间距离为: DS=d⊥(Li,Lj)+d‖(Li,Lj)+dθ(Li,Lj). Δtij=max(tie,tje)-min(tis,tjs). 则子轨迹段Li和Lj之间的时间距离DT为 其中,两子轨迹段之间的时间距离由时间跨度、时间差和航速的速度均值共同决定。为了更简单地计算时间距离,上述中的速度均值也可以采用子轨迹段中的任一点的速度,这是由于在短时间内,子轨迹段内的船舶航速基本不会变化。 使用均值绝对偏差对空间距离Ds标准化为: 其中,Dsn服从高斯分布;同理可按照上述过程得到时间距离的标准化值Dtn,则时空距离的算式为: DST=ωs×Dsn+ωt×Dtn. 其中,Dsn为将空间距离通过Z-Score分数方法进行标准化处理得到,Dtn为将时间距离DT通过Z-Score分数方法进行标准化处理得到,ws为空间距离的权重系数,wt为时间距离的权重系数,两者表征空间距离和时间距离的敏感度,可根据实际情况进行设定,且满足ωs+ωt=1。 5)船舶轨迹聚类。这一步主要根据获取的时空距离,通过DBSCAN算法对各子轨迹段进行聚类。聚类时,从任一子轨迹段出发,计算与其他所有子轨迹线段间的时空距离,根据获取的各子轨迹段间的时空距离,给定ε-邻域范围和最小线段参数(MinLns),统计满足ε-邻域范围的线段个数,并与最小线段参数(MinLns)进行比较,当ε-邻域范围内的线段数目大于给定的最小线段参数(MinLns)时,该子轨迹段即为核心轨迹,形成一个聚类,其邻域内的直接密度可达线段也将聚类到该类中,再对剩余的其他子轨迹段按照同样的方式依次进行聚类扩展,得到最终的聚类结果;而其中未被聚成一类的子轨迹段则是孤立轨迹,不作处理。其中,关于DBSCAN的各项参数表示或计算如下:ε-邻域范围Nε(Li)为子轨迹段Li在线段集D(Li∈D)内所有与其时空距离不超过ε的轨迹集合,即表示为Nε(Li)={Li∈D|Ddist(Li,Lj)≤ε};子轨迹段Li的线段集为D(Li∈D),给定邻域范围ε和最小线段参数MinLns,若满足|Nε(Li)|≥MinLns,则认为Li为核心轨迹;子轨迹段Li的线段集为D(Li∈D),给定参数邻域范围ε和最小线段参数MinLns,若Li为核心轨迹且Lj在Li的ε邻域范围内,则称Lj从Li直接密度可达;子轨迹段Li的线段集为D(Li∈D),给定参数邻域范围ε和最小线段参数MinLns,若存在从Li到Lk直接密度可达,从Lk到Lj直接密度可达,则从Li到Lj密度可达;子轨迹段Li的线段集为D(Li∈D),给定参数邻域范围和最小线段参数MinLns,若存在Li和Lj均由Lk密度可达,则Li和Lj密度相连。 6)时间和空间距离权重系数确定。在上述流程中,时间距离和空间距离的权重系数需要确定。为了得到最佳的聚类效果,本文确定的原则是,基于戴维森堡丁(Davies Bouldin Index,DBI)指数[17]来量化不同权重系数下的聚类质量,而DBI指数与时空距离权重系数之间存在一一对应关系,含义是度量每个簇类最大相似度的均值,能够较好的体现不同权重系数取值的聚类质量。DBI的值最小是0,不同权重系数下求得的DBI指数越小,聚类效果越好,同时也证明权重系数更优。DBI指数又称分类适确性指标,是一种评估聚类算法优劣的指标,其计算方法为:首先假设实验数据有m个时间序列,这些时间序列聚类为n个簇,m个时间序列设为输入矩阵X,n个簇类设为N作为参数传入算法,则DBI指数的算式为: 其中,各项参数的计算公式如下: 其中Xj代表簇类i中第j个数据点,也就是一个样本点;Ai是簇类的质心;Ti是簇类中数据的个数。 2)距离值Mi,j定义为簇类i与簇类j的距离,算式为: 其中,ak,i代表簇类质心点的第k个值;Mi,j就是簇类i与簇类j质心的距离,即ak,i表示第i类的中心点的第k个属性的值,Mi,j则就是第i类与第j类中心的距离。 3)相似度值Ri,j用于衡量第i类与第j类的相似度,算式为: 4)在上述基础上,做一个基于簇类数n的n2的嵌套循环,对每一个簇类i计算Ri,j的最大值,记为Di=max(Ri,j),即簇类和其他类的最大的相似度值。然后对所有类的最大相似度取平均值就得到了DBI指数,算式为: 通过以上步骤,就能够直观地分析出不同权重下聚类结果质量的高低,从而确定聚类质量最优的权重系数,进而准确地对船舶运行的子轨迹进行聚类。 测试服务器为Thinkpad T440,AMD双核CPU,4 GB内存,256 G固态硬盘容量;操作系统采用Windows 10 64位旗舰版,实验程序运行环境为Pycharm 2018.1,程序语言及其版本为Python 3.6.2。 为对本文所提算法的有效性进行验证,选取东海某海域(113°45′37″E~130°23′43″E,17°47′29″N~38°52′59″N)2016年2月9日到2016年3月6日真实船舶AIS轨迹数据进行测试,其中每条轨迹由相互紧邻的样本点连接而成。原始数据共计320 001个采样点,按照船舶MMSI标识整理后共得到260条轨迹;由于部分轨迹中的船舶点位过少,生成的轨迹无法代表其航行轨迹,因此对这部分无效轨迹进行剔除,得到249条有效轨迹。 由于从上述初步得到的每条轨迹中提取关键点需要迭代的次数较多、工作量较大,需要对每条船舶轨迹进行压缩。数据压缩有多种方法,在GIS领域常见的矢量数据压缩方法有道格拉斯-普克法(Douglas-Peucker Algorithm)、垂距法、光栏法等,其中道格拉斯-普克法较为经典且使用较广。对于一条曲线轨迹,道格拉斯-普克法通过循环连接首尾两点,并计算中间各点到上述连线的距离,将最大距离值dmax与限差D进行比较,若dmax 图5 船舶AIS轨迹数据压缩前后对比 在上述数据压缩的基础上,接下来对实验船舶轨迹进行特征点提取。首先,通过对实验数据的分析,将SP点的提取采取的时间阈值为8 min,航速阈值为0.8 kn。然后,通过对每条轨迹的OD点、SP点和TF点进行提取,从而得到能够代表每条船舶轨迹的特征点集合,以此形成子轨迹集合。众多子轨迹在某些子段处会出现重叠,因此按照上文的子轨迹段划分方法对249条轨迹进行划分,共得到2 396条子轨迹。然后利用本文提出的顾及时间特征的船舶轨迹DBSCAN算法对子轨迹段实施聚类,在确定时间距离和空间距离各自的权重系数时,利用DBI指数来进行判定,部分试验结果如表1所示。 由表1可知,当空间距离权重ωs=0.56、时间距离权重ωT=0.44时,DBI的值最小,聚类效果最佳。因此,最终时空距离计算中的空间距离权重系数确定为0.56,时间距离权重确定为0.44。在此基础上,利用本文的算法对上述所有的船舶子轨迹段进行聚类,最后对相似的子轨迹进行融合形成。实验过程中发现该算法对聚类参数ε和MinLns较为敏感,因此通过反复试验,最终确定ε=0.003 nmile,MinLns=3时,聚类效果较为理想。结果如图6所示。 表1 基于不同时、空距离权重取值的部分DBI指数计算结果 图6 船舶AIS轨迹数据聚类前后对比 此外,为了验证本文算法的优劣,将其与经典的DBSCAN空间聚类算法的效果进行对比。在选用相同的数据集的基础上,两者在耗时、准确度、分类数等方面的对比如表2所示。 表2 本文算法与经典DBSCAN算法的优劣对比 由图6可知,在实验船舶轨迹数据集上,通过本文的聚类算法,成功将轨迹数据集分成4个有效类簇(每个类簇以一种颜色表示),即本文算法成功地从原始轨迹中提取出4条典型轨迹,这4条轨迹可以形象地反映出该船舶在1个月时间内的空间位置变化规律和航行模式。由表2可知,本文提出的顾及时间特征的船舶轨迹聚类算法在耗时上略逊于经典DBSCAN算法,这是由于本文算法除了要计算空间距离外,还需要计算两子轨迹之间的时间距离,然后计算时空距离,其中涉及的相似性度量相对复杂,因此使得算法的复杂度升高。但由于本文算法同时兼顾时空距离,更易于发现经典DBSCAN算法无法发现的隐蔽群,使得算法的准确率和聚类数目有较大提升。 此外,考虑本文算法随着船舶轨迹数据集增长时的效能变化,分别在前文数据集27 d,45 d,60 d数据集上进行实验,实验流程与上述流程保持一致,统计不同数据集上的原始轨迹数、划分子轨迹数和耗时如表3所示。 表3 基于不同规模数据集的本文算法性能对比 由表3可知,随着数据集的增大,本文算法的耗时呈现急剧上升的趋势,因此在后续研究中,需要关注如何优化算法的过程与结构,从而有效降低聚类的时间消耗。 作为时空大数据范畴中对地理信息环境中社会感知数据的重要表现形式,轨迹数据能够有效表征时空对象的移动规律,具有重要的应用价值。船舶轨迹数据具有多维、动态特征,能够表征船舶的时空移动状态,为预测船舶的出行规律和行为模式提供信息支撑。本文在现有经典DBSCAN聚类算法的基础上,设计并实现一种顾及时间特征的船舶轨迹DBSCAN聚类算法,通过引入时间相似性度量方法,对船舶轨迹数据进行分段并计算其时空距离,实现对船舶轨迹的时空聚类。最后进行实验验证,通过与经典DBSCAN算法进行效能对比,结果证实本文算法的有效性。不足之处在于随着船舶轨迹数据规模的扩大,算法的耗时会急剧增长,因此如何对该算法进行优化,有效降低算法的聚类开销,是后期的研究方向。
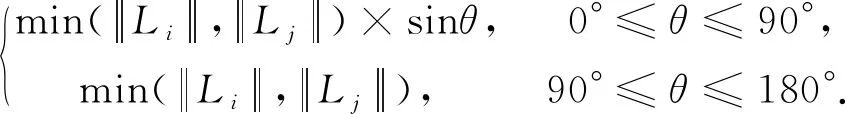



3 实验验证
3.1 实验环境
3.2 实验流程与结果




3.3 实验分析

4 结束语
