基于深度学习的半监督图像标注系统设计与实现
2021-05-10胡明玉杨晨雪曹景军柴秀娟
胡明玉 夏 雪 杨晨雪 曹景军 柴秀娟*
(1.中国农业科学院 农业信息研究所,北京 100081; 2.农业农村部农业大数据重点实验室,北京 100081)
随着计算机视觉的发展,深度学习技术在图像分类[1-6]、目标检测[7-12]和图像分割[13-18]等研究中得到了广泛应用,农业领域中的应用包括作物及其器官分类、病虫害识别、果实识别和计数、植物识别、土壤覆盖分类、杂草识别、行为识别和分类、植物养分含量估计、植物叶片或种子表型分析等方面[19]。但由于深度学习方法需要大量的数据样本,在相关研究中普遍存在训练样本标注费时费力的问题。针对训练样本标注任务,已开发出多款图像标注工具。目前在目标检测研究中可使用的图像标注工具可分为客户端和WEB端2种。客户端标注工具包括Labelme、LabelImg、YOLO_mark、Sloth、RectLabel等,WEB端标注工具包括CVAT、VOTT、LabelBox、VIA、Boobs、Vatic等。现有的图像标注工具各具特点。从支持的标注图形的几何形状来看,除矩形外,Labelme、Sloth、RectLabel还支持采用点、线段、多边形对图像进行标注;从支持的标注信息存储文件导出格式来看,除Yolo_mark仅支持文本格式(专为YOLO系列的模型训练准备数据)外,其他标注工具均支持至少2种数据导出格式,例如COCO JSON格式、VOC[20]XML格式等;从支持标注的图像形式看,Labelme、Sloth、CVAT、VOTT、VIA不仅支持图片标注,还支持视频标注;Vatic是专为视频标注任务研发的标注工具。另外,部分标注工具实现了半自动图像标注功能,例如,Vatic采用了基于OpenCV的目标追踪算法,使得标注人员在标注视频图像时只需标注适量单帧图像即可实现对视频中所有单帧图像进行标注;RectLabel利用其内置的Core ML模型实现了对图像的自动标注。虽然使用已有标注工具可以完成大部分常规的图像标注任务,但一些图像中会存在检测目标数量大且密集的情况,如食用菌图像和小麦图像等,若使用无自动标注功能的常规标注工具对图像中的目标逐一进行纯手工标注,一方面工作量较大,另一方面也很难保证多人参与时图像标注的准确性、一致性和完整性。另外,现有图像标注工具的半自动标注功能存在适用的物体类别有限以及自动标注效果较差的问题。本研究针对深度学习研究中训练样本标注工作费时费力的问题,以食用菌为研究对象,拟采用将深度学习目标检测模型与迭代图像标注工作有效结合的方法,开发基于深度学习的半监督图像标注系统,采用“检测模型训练—目标自动检测—人工标注修正—检测模型更新”的迭代操作,以期实现半监督方式的图像标注,不断优化系统的自动检测性能,从而提高图像标注效率,降低图像标注的人工成本投入。
1 材料与方法
1.1 数据及设备
本研究中所采用的食用菌图像来自浙江省桐乡市联翔食用菌有限公司的双孢菇培养工厂。工厂为封闭式结构,双孢菇置于厂内层叠的铁架容器中,每层有10 个容器,共有5 层。每个容器长度约为1.5 m,宽度约1.4 m,高度约0.37 m。图像采集时间为2018年10月。采集方式为,将每个容器大致均匀分为16 块,人工采用IPHONE 8 PLUS手机在与容器底部平行方向且距食用菌约0.3 m处依次按行、列顺序移动拍摄图像。此次共采集分辨率为4 032像素×3 024像素的食用菌图像1 158 幅。
本试验采用4块型号为Tesla P100-SXM2-16GB的显卡对数据进行并行处理。
1.2 基于深度学习的半监督图像标注方法
目标检测模型是半监督图像标注的核心和基础。目前用于目标检测的深度学习模型分为两阶段目标检测模型和单阶段目标检测模型。两阶段目标检测模型中具有代表性的是R-CNN及其衍生的系列模型,如Faster R-CNN[21],采用对锚框进行回归与分类生成候选框、对候选框进行回归和分类2个步骤实现目标检测。单阶段目标检测模型中具有代表性的是YOLO和SSD,直接对采用密集采样方式设置的锚框进行回归与分类实现目标检测。经过分别采用YOLOv3、SSD、Faster R-CNN对食用菌图像进行检测的试验结果对比(将在3.2中介绍)可知,基于Resnet50的Faster R-CNN模型的检测效果最好,因此本研究选择此模型作为食用菌目标检测的深度学习模型。Faster R-CNN模型可分为特征提取、候选框生成(Region proposal network,RPN)以及位置回归和分类预测(RoIHead[21]/Faster R-CNN)3个部分,模型的整体工作流程见图1。
在特征提取部分,将食用菌图像输入到特征提取模块中,对图像的红(R)、绿(G)、蓝(B)3个通道进行一系列的卷积、池化、全连接等操作后生成特征图。
在候选框生成部分,将提取的特征图输入到RPN模块来生成候选框。首先针对特征图上的每一个点生成12种不同尺寸和长宽比的锚框,并计算每一个锚框属于前景的概率以及对应的位置参数,然后选取概率较大的m个锚框,利用位置参数修正锚框的位置得到候选框,最后经过非极大值抑制操作保留概率较大的n个候选框输入到下一个模块中。

图1 Faster R-CNN整体工作流程Fig.1 Overall process of Faster R-CNN
在位置回归和分类预测部分,RPN模块提供的n个候选框被输入到RoIHead(Fast R-CNN)模块,对每个候选框的位置参数进行调整来生成预测框,并得到分类结果。
本研究采用“检测模型训练—目标自动检测—人工标注修正—检测模型更新”的迭代操作,实现了半监督方式的图像标注。具体可分为6个步骤。
步骤1:将部分人工标注的食用菌图像和对应的标注信息存储文件作为输入,训练得到食用菌目标检测模型,此时模型的食用菌检测能力较低;
步骤2:载入部分待标注食用菌图像,利用系统中嵌入的食用菌目标检测模型对图像中的食用菌目标进行检测,得到系统自动标注的结果;
步骤3:对不准确的标注结果(包括漏标、错标和标注框歪偏等错误)进行人工修正,得到精确的标注结果(图像中所有食用菌均有标注且标注框贴合食用菌边缘,没有不包含食用菌的标注框);
步骤4:将修正后的精确标注信息存储文件和对应的食用菌图像作为输入,重新训练食用菌目标检测模型,得到精度更高的检测模型,此时图像中更多的食用菌目标可被自动标注出来;
步骤5:重复步骤2 至步骤4,迭代更新模型,直至目标检测模型的检测效果达到理想精度,即平均准确率(Average precision,AP)>85%;
步骤6:将最终训练获得的达到理想精度的目标检测模型嵌入图像标注系统,完成剩余食用菌图像的标注工作,此时图像中90%以上的食用菌目标可被准确的标注出来。
2 半监督图像标注系统的实现
2.1 系统工作流程
本系统分为半监督标注模块和人工标注模块。半监督标注模块实现系统自动标注+人工修正的功能,人工标注模块实现纯手工标注的功能。系统工作流程见图2。在进行食用菌图像标注时,首先选择图片存储路径,完成食用菌图片的载入。若标注方式为半监督标注,系统会先自动检测出图像中的食用菌,同时生成标注信息存储文件,随后人工对自动生成的标注结果进行修正,人工修正方式分为3种:对于漏标的情况,直接手动添加标注框;对于错标的情况,直接手动删除标注框;对于标注框歪偏的情况,首先手动删除原来的边框,然后手动添加新的边框。若标注方式为人工标注,则不执行系统自动检测功能,人工直接对食用菌图像进行纯手工标注。在修正或标注完当前图像后,系统将自动保存标注结果,同时可跳转至上一张或下一张图片开始后续标注任务。

图2 半监督图像标注系统总体运行流程Fig.2 Overall operation process of the semi-supervisedimage labeling system
2.2 系统操作界面
本研究采用Python 3.6编程,通过Tkinter模块调用Python的标准Tk 图形用户界面(Graphical user interface,GUI)工具包来实现系统的图形化操作界面。本系统的操作界面分为上中下3层:上层设置有图像路径选择功能区、鼠标焦点坐标信息显示区和当前图像名称信息显示区;操作界面中层设有图像显示区域、局部放大区和标注信息列表区,操作界面下层设有图像计数信息显示区、图像切换跳转功能区和自动标注选择功能区。本研究所设计的半监督图像标注系统操作界面见图3。
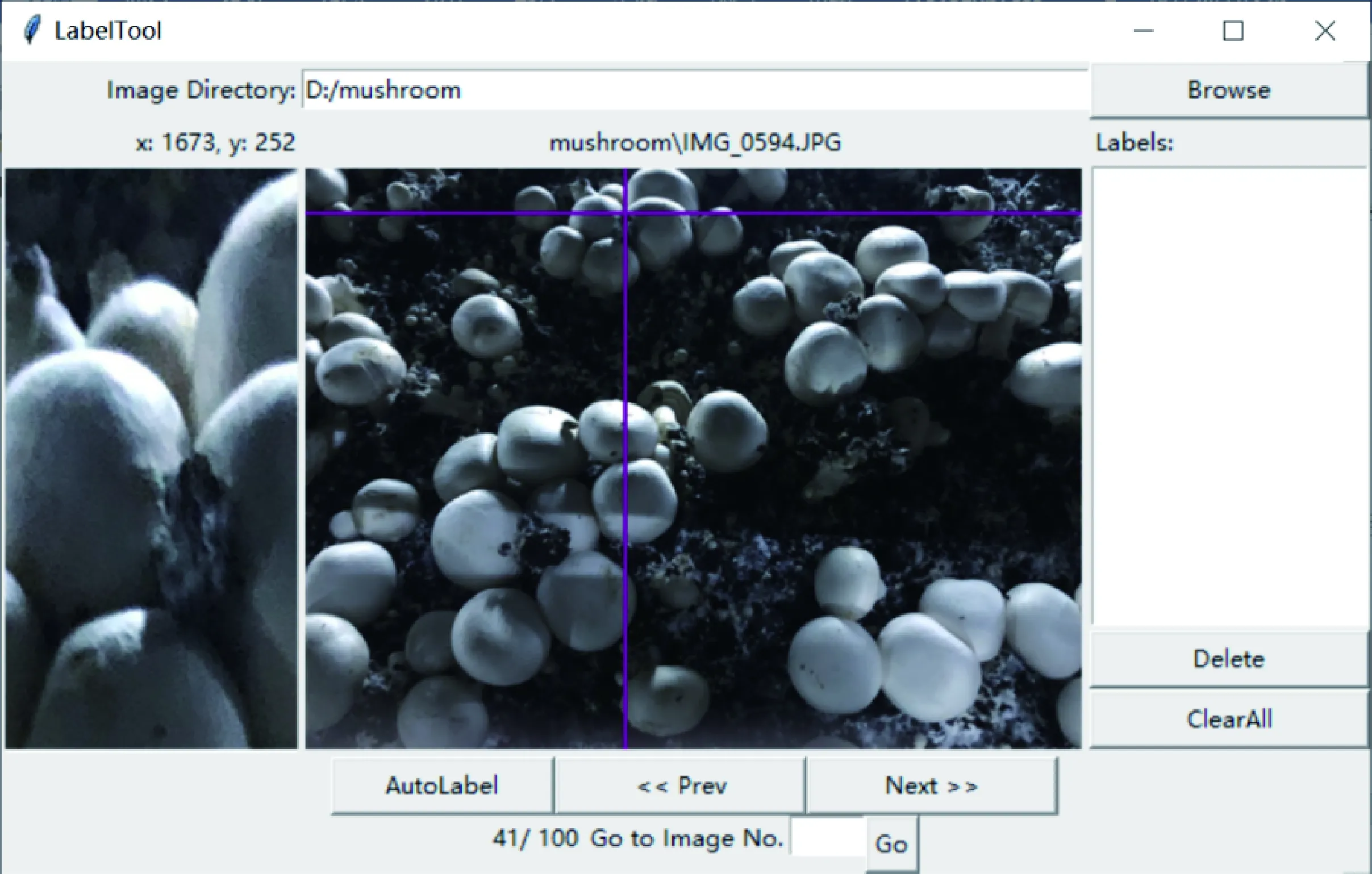
图3 半监督图像标注系统操作界面Fig.3 Operation interface of the semi-supervised image labeling system
2.3 半监督图像标注模块设计
半监督标注模块采用系统自动标注和人工修正结合的方式完成食用菌图像标注任务。半监督图像标注模块包括4方面的功能:
1)模型自动载入与调用功能。模块可将训练完成的食用菌目标检测模型嵌入,当半监督图像标注功能被激活时,模块可实时调用模型对食用菌图像进行处理。
2)食用菌自动检测功能。模块可对输入的食用菌图像自动进行目标检测,获取图像中食用菌的位置坐标信息。
3)标注结果可视化功能。模块可根据系统自动检测得到的食用菌标注信息在图像上可视化显示出矩形框,即可呈现自动标注的效果。
4)标注结果修改功能。模块可提供利用操作界面对系统自动标注结果进行人工修正的功能,并将修改过的食用菌标注信息重新保存至相应的标注信息存储文件中。
系统自动标注和人工修正后的食用菌图像标注结果见图4,可见,系统自动标注时会出现漏标和标注不准确的情况(图4(a)),需要人工修正来完善标注结果(图4(b))。
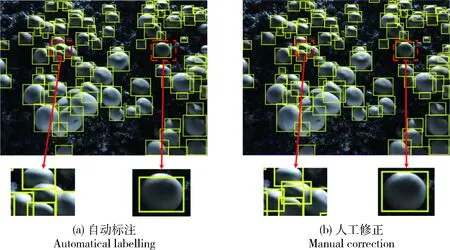
图4 半监督图像标注系统自动标注及人工修正标注效果Fig.4 Auto-labeling results of the semi-supervised labelling system and manual correction results
2.4 人工图像标注模块设计
人工图像标注模块用来实现纯手工标注,作为半监督图像标注方式的补充。人工图像标注模块包括4方面的功能:
1)标注信息手动删除功能。模块提供了2种标注信息删除方法:一种方法是鼠标移至标注框左上角时,点击鼠标右键实现删除功能,另一种方法是在标注信息列表区选中待删标注条目,利用专门的删除功能按钮实现标注信息的删除。
2)手动标注图像功能。模块允许以滑动鼠标的方式来框选图像中的食用菌目标,并记录其位置坐标信息。人工进行手动标注时,首先点击鼠标左键并滑动,当标注框贴合目标边界时再次点击鼠标左键完成一次标注。
3)手动标注信息存储功能。手动标注完成后,模块会记录食用菌标注框左上角的x、y坐标和右下角的x、y坐标,并以“minx-miny-maxx- maxy”的形式显示到标注信息列表区,同时将标注信息写入指定的存储文件中。
4)图像局部区域自动放大功能。模块借助图像切割函数截取以鼠标焦点为中心的50像素×50像素范围内的图像内容,并利用图像缩放函数放大截取的图像区域,实现图像局部区域的自动放大。
3 试验结果与分析
3.1 模型性能评价指标
本研究试验中检测模型的性能评价指标为平均准确率(Average precision,AP)。在计算AP的过程中,交并比(Intersection over Union,IoU)是一个很重要的参数。IoU的计算方法为:
(1)
式中:A为人工标注框的面积;B为模型检测出的目标边框的面积。
模型的平均准确率AP根据准确率(p)、召回率(r)计算得出。准确率和召回率的计算方法为:
(2)
(3)
式中:TP表示食用菌检测模型已检测出并且是正确的框的个数;FP表示模型已检测出但是错误的框的个数;FN表示模型没有检测出来但是正确的框的个数。TP与FN之和即为人工标注框的个数。
对于模型检测出的每一个框,遍历同一幅食用菌图像中人工标注框,分别计算IoU值,取其中的最大IoU值。当最大IoU值>0.5时,记该检测结果为正确的;当最大IoU值<0.5时,记该检测结果为错误的。由此计算出模型检测每一幅图像的准确率和召回率并绘制准确率-召回率曲线,计算该曲线与坐标轴所围成的区域面积定义为模型的检测AP,它定量地描述了模型在测试集上的检测性能。
在实际计算过程中,为了简便,通常只抽样选取几个特定点的数据,如召回率为0,0.1,…,1.0所对应的准确率,绘制准确率-召回率曲线并近似计算曲线与坐标轴的面积得到模型的检测AP:
式中:P(r)表示召回率为r所对应的准确率。
3.2 模型训练及测试
为了确定最适合食用菌图像检测任务的网络模型,本研究选取了SSD、YOLOv3、Faster R-CNN分别进行试验,训练集图像数均为140 幅(4 032像素×3 024像素),并按照不同网络模型的输入图像尺寸要求将原图裁剪为若干幅小图,不同模型在测试集上的检测AP见表1。可见,以Resnet50作为特征提取网络的Faster R-CNN模型在测试集上具有最高检测AP,为85.3%。因此,本研究选取基于Resnet50的Faster R-CNN模型作为食用菌目标检测模型,后续试验均采用此模型来展开。本研究重点在于探讨一种基于深度学习的半监督图像标注系统的设计方法,因此本仅选取了7种模型进行试验,在实际应用中也可采用其他模型。

表1 不同模型对食用菌图像检测的平均准确率Table 1 Average precisions of different model detections on edible mushroom images
对于半监督图像标注系统,检测模型的训练十分关键,模型的检测性能将直接影响到图像标注效率,下面将结合基于Resnet50的Faster R-CNN 模型介绍模型的训练过程。综合考虑试验所用计算机设备显存容量、图像中食用菌尺寸以及模型训练时输入数据的批尺寸(Batch_size)3种因素,在模型训练前的数据预处理阶段对原图像采取2种处理方式:第一种方式是将每幅原图图像裁剪为140幅尺寸为512像素×512像素的小图,由于对原图进行裁剪时将部分食用菌分为两半会造成食用菌特征信息的丢失,因此在裁剪原图时采用了重叠裁剪的方式,即在原图上相邻的两幅小图有一半是重叠的;第二种方式是将原图缩小为800像素×600像素的图像。2种方式下均需要对食用菌图像的标注信息进行相应的坐标转换。
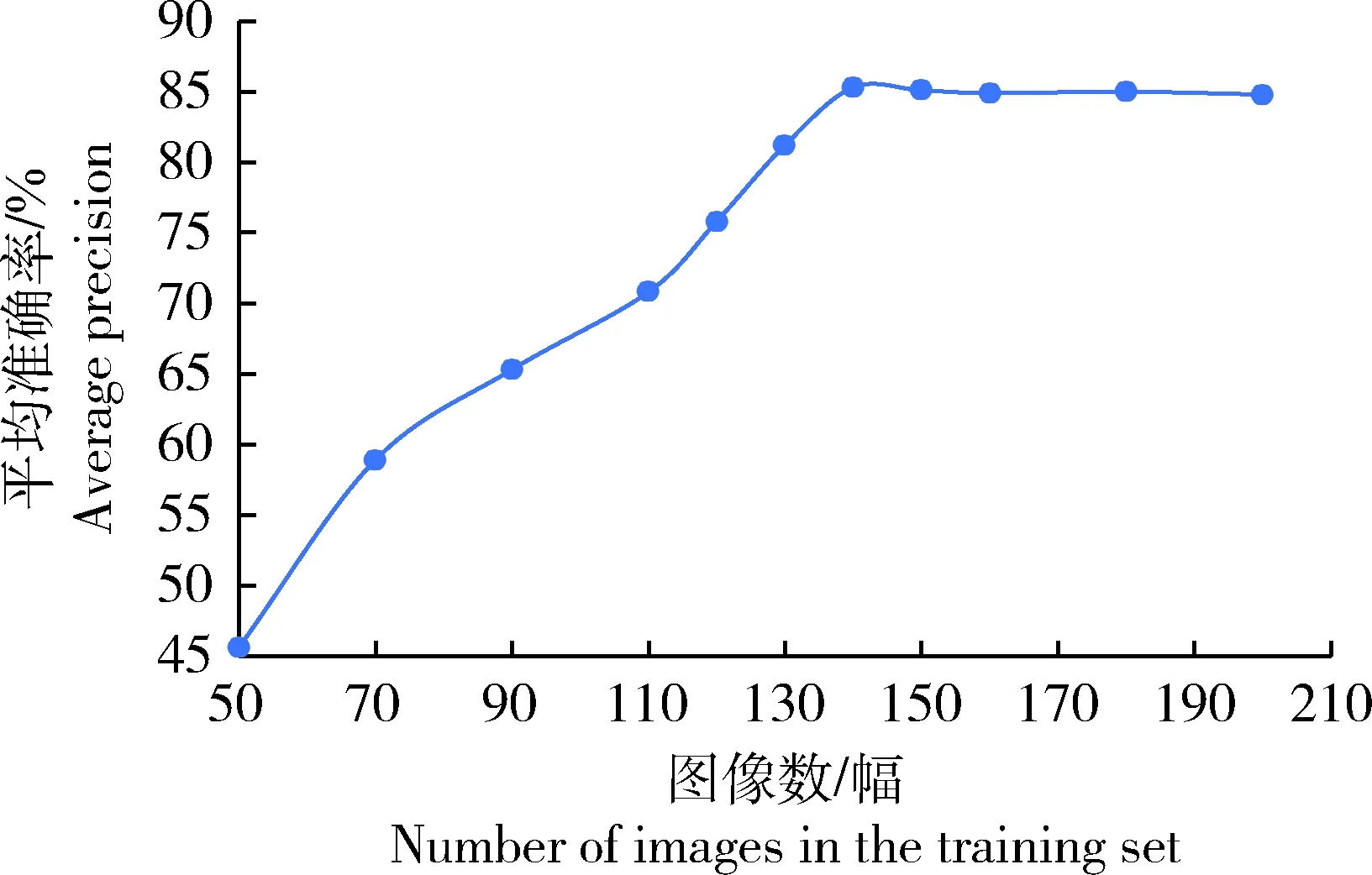
图5 原图裁剪为若干小图,模型检测平均 准确率与训练集图像数的关系Fig.5 Relationship between average precision of themodel detection and the image number of thetraining set when cropping the original imageinto several small images
在将原图裁剪为若干小图的图像处理方式下,选择50幅原图像,裁剪为7 000幅小图训练食用菌目标检测模型,并结合半监督图像标注的方法不断更新模型,直到训练出达到理想精度的目标检测模型。当训练集图像数由50幅增至200幅时,模型在测试集上的检测AP呈现先升后降的趋势(图5)。当训练集图像数达到140 幅时,模型在测试集上的检测AP达到峰值,为85.3%。当训练集图像数(裁剪前)分别为50、90和140 幅时,模型在测试集上的检测效果以及人工修正后的效果示例见图6。
在将原图裁剪为若干小图的图像处理方式下,训练集图像数在裁剪前为140幅时模型训练过程中的参数调优过程分为4个步骤。
步骤1:为确定最佳学习率(Learning rate, lr),将批尺寸(Batch_size)设为24,迭代次数设为 15 000 次,将lr分为4种:0.000 1、0.000 5、0.001 0和0.005 0,在每次训练中使用1种lr进行训练。不同lr模型训练的损失函数值见图7。可见,当lr为0.005 0时,损失函数收敛速度最快且收敛后的值最小,因此确定0.005 0为本研究中模型训练的最佳lr。
步骤2:为确定最佳Batch_size值,训练时设置lr为最佳值0.005 0。当迭代6 000次左右时,损失函数已收敛,无需再迭代15 000次,因此将迭代次数设为6 000次(图7)。由于计算机设备显存容量的限制,将Batch_size值分为4、8、16、24这4种,在每次训练中使用1种Batch_size值进行训练。不同Batch_size模型对测试集上的检测结果见表2。可见,当Batch_size为24时,模型的检测效果最好。
步骤3:为确定最佳迭代次数,训练时设置lr为最佳值0.005 0,设置Batch_size为最佳值24。模型对测试集的检测AP与迭代次数的关系见图8。可见,当迭代次数达到6 200次时,AP达到最高值85.3%。
在将原图缩小的图像处理方式下,选择80 幅食用菌图像训练食用菌目标检测模型,并结合半监督图像标注方法不断更新模型,直到训练出达到理想精度的目标检测模型。当训练集图像数由80 幅逐渐增至400 幅时模型在测试集上的检测AP见图9。可见,在训练集图像数达到230 幅时,模型在测试集上的检测效果最好,此时准确率为98.1%,召回率为88.5%,AP为88.3%。当训练集图像数分别为80、140和230 幅时模型在测试集上的检测效果以及人工修正后的效果示例见图10。

图6 原图裁剪为若干小图,训练集图像数(m)不同时模型检测果及人工修正标注效果Fig.6 Detection results of the model trained with the training set of different image numbersand manual correction when cropping the original image into several small images
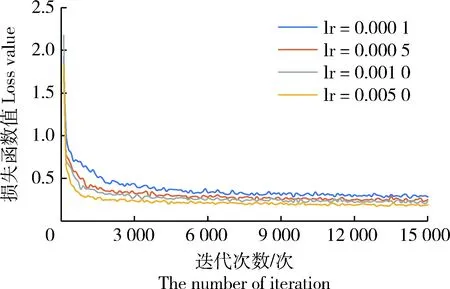
图7 不同学习率(lr)模型训练的损失函数值Fig.7 Loss values of the model trainedunder different learning rates
此外,试验还从食用菌采摘的实际应用的角度衡量检测模型的性能,由于在食用菌的自动采摘过程中,机器只需采摘体积较大的成熟蘑菇,因此只需测量模型对大于某一尺寸的食用菌的检测精度。在将原图缩小的图像处理方式下,利用230 幅图像训练的模型对测试集中不同大小食用菌的检测结果见表3。可见,检测模型对尺寸较大的食用菌检测精度更高,说明图像中食用菌的尺寸会对模型的检测精度造成一定影响。

表2 不同Batch_size模型对测试集的检测结果Table 2 Detection results on the test set when Batch_size is different

图8 模型对测试集检测的平均准确率与迭代次数的关系Fig.8 The relationship between the average precisionof the model detection on the test set with thenumber of iteration

图9 原图缩小模型检测平均准确率与训练集图像数的关系Fig.9 Relationship between the average precision of themodel detection with the image number of thetraining set when reducing the original images

图10 原图缩小训练集图像数(n)不同时模型检测效果和人工修正标注效果Fig.10 Detection results of the model trained with the training set of different imagenumbers (n) and manual correction when reducing the original images
由试验结果可知,与SSD和YOLOv3相比,基于Resnet50的Faster R-CNN模型对食用菌的检测效果最好。试验中采用基于深度学习的半监督图像标注方法,利用迭代操作得到达到理想精度的食用菌目标检测模型。在将原图裁剪为若干小图的图像处理方式下,当训练集图像数为140幅,lr为0.005 0,Batch_size为24,迭代次数为6 200 时,模型检测平均准确率AP达到最高,为85.3%。采用将原图缩小的图像处理方式时,对比将原图裁剪为若干小图的图像处理方式,模型在测试集上的检测AP峰值更高,这可能是因为将大图裁剪为小图后,增加了训练集中不完整食用菌图像的数量,影响了模型对食用菌特征信息的学习。

表3 原图缩小训练集图像数为230 幅时模型对不同大小食用菌的检测结果Table 3 Detected results of the model trained with 230 images on edible mushrooms of different sizes when reducing the original images %
3.3 系统标注效率分析
试验中采用基于深度学习的半监督图像标注系统对食用菌图像进行标注,并对半监督图像标注速度进行评测,考虑到对图像标注工作熟练程度不同的人标注速度不同,采用将3个实验员的标注速度取平均值的方法对半监督图像标注速度进行了测试。在将原图裁剪为若干小图的图像处理方式下,系统嵌入由图像数不同的训练集训练所得的检测模型时的半监督图像标注速度见图11。可见,采用纯手工标注(训练集图像数为0)时,标注速度约为600 s/幅;采用半监督图像标注方法时,随着训练集图像数的增加,模型不断优化,人工修正一幅图像的平均耗时逐渐缩短,在训练集图像数为230 幅时,标注速度达到最大值:15 s/幅,单幅图像的标注耗时仅为纯人工标注耗时的2.5%。由此可见,采用半监督图像标注系统能够显著提高食用菌图像标注效率。
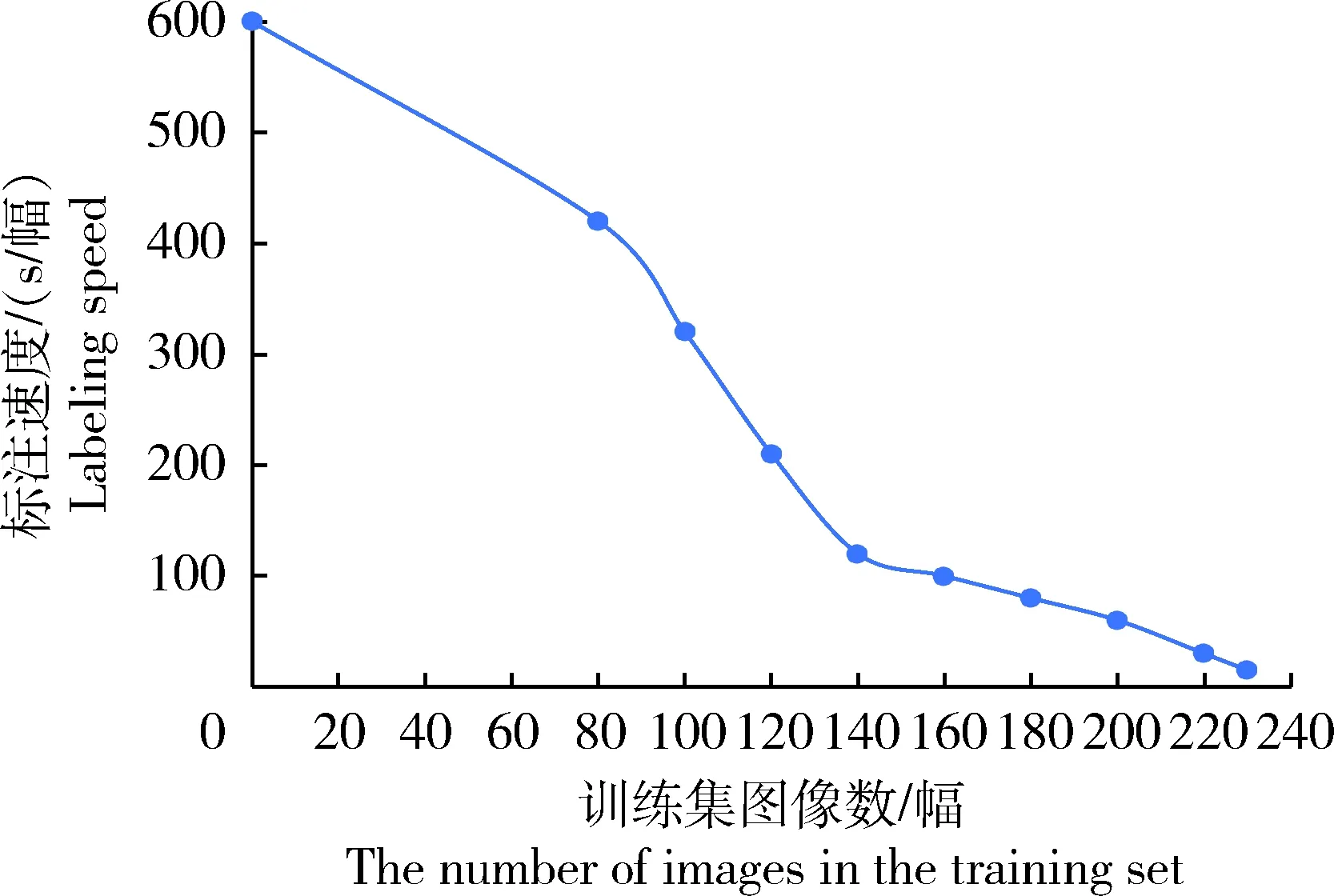
图11 系统半监督图像标注速度与训练集图像数的关系Fig.11 Relationship between the semi-supervisedimage labeling speed of the system and theimage number of the training set
4 结 论
本研究提出了一种基于深度学习的半监督图像标注方法,将深度学习目标检测模型与迭代图像标注工作有效结合,采用“检测模型训练—目标自动检测—人工标注修正—检测模型更新”的迭代操作,实现了半监督方式的食用菌图像标注。构建的基于深度学习的半监督图像标注系统提供了半监督图像标注功能和人工图像标注功能,显著降低了食用菌图像标注工作的繁琐程度,极大减少了人工标注的工作量。试验结果表明,对训练集图像采用将原图缩小的图像处理方式,即将原图缩小至800像素×600像素时,系统内嵌模型的检测性能达到最优,检测准确率为98.1%,召回率88.5%,平均准确率88.3%。利用系统进行半监督图像标注的速度由原来纯手工标注的600 s/幅提升至15 s/幅,标注效率显著提升。研究结果为深度学习研究中的训练样本标注工作提供了高效的标注方法和工具,有助于提高图像标注效率,减少人力成本投入。
