基于信息解释能力的小企业信用评级体系构建研究
2021-05-10陈洪海
陈洪海,王 慧,隋 新
(南京财经大学金融学院,江苏南京210023)
1 引 言
作为数量最多的企业群体,小企业已发展成为激活市场竞争、促进经济增长、创造就业机会的关键力量.小企业的经营发展与技术创新产生了强烈的外部融资需求,其贷款需求甚至分别高出大型和中型企业17.2%和8.2%[1].但较之大型企业,小企业却普遍存在着规模偏小、抗风险能力弱、信用积累时间短、有效抵押少、财务管理不甚规范、公司治理水平偏低、违约成本相对较小等信用风险特征.这与商业银行对企业贷款客户的授信工作的日趋严格和规范极不相称.而银企间的信息不对称等问题,进一步促使商业银行不愿意贷款给小企业,在很大程度上导致小企业贷款依然贵、依然难.随着商业银行间市场竞争的日趋激烈,目前商业银行也日益希望有效地开发小企业信贷市场,但为了控制信贷风险,商业银行通常会对申请贷款的企业客户进行信用评级,并基于企业客户的信用评级结果做出信贷决策,以决定贷款与否、期限与利率.因此,科学合理地对小企业进行信用评级至关重要.而企业信用评级指标体系是企业信用评级的基础,是以衡量企业信用风险为主要目的,利用定性或定量指标筛选方法,从大量备选指标中选择出的一组能有效地反映企业综合信用风险的评价指标.显然,如果信用评级指标体系不合理,则小企业信用评级结果的合理性便无法得到保障.因此,如何构建一套科学合理的小企业信用评级指标体系,为小企业信用评级工作提供科学基础,进而帮助商业银行控制信贷风险和解决小企业融资难问题,正成为一项亟待解决的难题.
在理论界,学者们十分重视结构化模型[2]、风险量化[3]及支持向量机[4]等评级方法的研究和讨论,但亦日益重视信用评级指标选取的相关研究[5].国内外传统的信用评级指标体系主要是围绕“5C”、“5P”及“LAPP”等信用评价体系构建的.目前,企业信用评级指标体系相关研究按照来源可分为三类.一是由穆迪、标准普尔、菲奇以及大公国际等评级机构提出的评级体系[6−9].二是由中国银行等商业银行建立的贷款企业评级体系[1].三是学术文献中的信用评价指标体系.如Min等[10]以资本存量周转率等11 个指标预测了企业的破产风险.吴青等[11]认为评价小企业信用的指标应包括行业与宏观经济状况、企业主个人及企业信用等三类.Psillaki 等[12]认为利润率、偿债能力等指标可有效判别企业的信用风险.Chiang等[13]认为债务比率等22 个指标能有效识别高科技企业的违约风险.Petr等[14]则对比了美国与欧洲在信用评级指标选取上的普遍性差异.Chen等[15]给出了息税前收入/总资产等12 个判别企业破产比较显著的指标.上述信用评价指标的选取皆基于专家经验,导致评价指标的选取过于主观,其客观一致性无法保障.
鉴于主观遴选信用评价指标的弊端,筛选信用评价指标的定量方法日趋流行起来.如范柏乃等[16]通过隶属度分析等方法建立了包含资产负债率等15 个指标的中小企业信用评价指标体系.赵志冲[17]等、迟国泰[18]等分别基于释然比检验、F–检验,剔除了对企业违约状态(违约与否)影响不显著的指标,并皆通过剔除任意两个相关程度高的评级指标中相对不重要的一个指标来降低指标集的信息重叠程度.此类指标筛选方法仅仅考虑或完全不考虑评级指标对违约状态的影响.违约状态是企业客户违约风险最基本、最直接的反映,因此信用评价指标理应具有显著识别企业违约状态的能力.但违约状态仅能粗略刻画企业的信用风险,难以满足评级实践对精细划分企业信用风险的客观需要.以穆迪、标普及惠誉等三大国际知名的信用评级机构为例,其对企业信用等级的划分最少的也有9个之多,而并非仅仅分为违约与否两个等级而已.
此外,鉴于评级体系是信用评级工作的基础,检验其合理性自然十分重要,但目前此方面的研究成果却甚为少见.Shi等[19]认为信用评级指标体系各指标的总方差占筛选前全部指标总方差的比例越大,评级指标体系的信息贡献越大,但却忽略了不同指标原始数据在单位及量纲上的差异.而石宝峰[20]则在利用多重决定系数检验信用评价指标体系合理性时没有考虑多元线性回归模型解释变量的差异,也未考虑两组指标间共线性程度的差异,亦有待完善.
综上,现有评级指标筛选的相关研究尚有两个关键问题亟待解决.一是在筛选评级指标过程中,如何有效地兼顾指标对违约状态的识别与精细划分企业客户信用风险这两种能力,以保证评级指标皆具有显著的信用风险识别能力;二是如何有效地检验评级指标体系的合理性,为后续评级工作提供保障.为此,本文提出一种系统的小企业信用评级指标筛选方法.首先,通过F–检验剔除对违约状态识别能力弱的评级指标,保证被保留的指标均具有一定的违约风险识别能力.其次,提出一种基于信息解释度的指标筛选方法,从信息解释能力的角度解决现有主成分指标筛选方法[21,22]仅依据单个负载系数筛选指标不合理[23]的问题,并据此提出信用信息解释度的概念及剔除综合信用风险识别能力弱的指标.从而,通过这两次指标筛选,保证被保留的评级指标既具有一定的违约风险识别能力,又具有精细刻画小企业客户综合信用风险的能力,解决难点一.再次,根据信用评级指标体系对违约状态的识别准确率越高、越稳定,信用评级指标体系越合理的思路,检验小企业信用评级指标体系的合理性,丰富现有评级指标体系的合理性检验方法,解决难点二.最后,根据中国一家商业银行的小企业信贷历史数据进行了实证研究,建立了包含“总负债经营活动净现金流比率”等22个指标的小企业信用评级指标体系.研究发现,本文建立的小企业信用评级指标体系识别信贷违约风险的准确率比现有主成分指标筛选方法构建的评级指标体系高,而且稳定.
2 信用评级指标的筛选
2.1 小企业信用评级指标的海选
为了全面反映小企业信用风险特征,避免主观遗漏重要的信用评级指标,有必要对影响小企业信用风险的因素进行海选.为此,本文给出了小企业信用评级指标海选的六项原则.一是信用评级指标的海选应充分反映信用风险这个核心概念,这是信用评级指标海选的最基本要求.二是广泛借鉴已经经历了一定信用评级实践检验的、国际上影响广泛的五C要素、五P要素和中国通常采用的五性要素.三是海选的评级指标中应包含能够有效反映小企业成长性的指标.四是小企业常存在财务管理不规范的情况,因此应增加非财务指标的比例.五是应增加反映小企业经营决策者信用状态的指标,以在一定程度上间接反映小企业的还款意愿.六是指标数据应可观测,以满足现代评级实践的操作及定量分析需要.
2.2 剔除对违约与否影响不显著的指标
2.2.1 定性指标打分及指标数据标准化
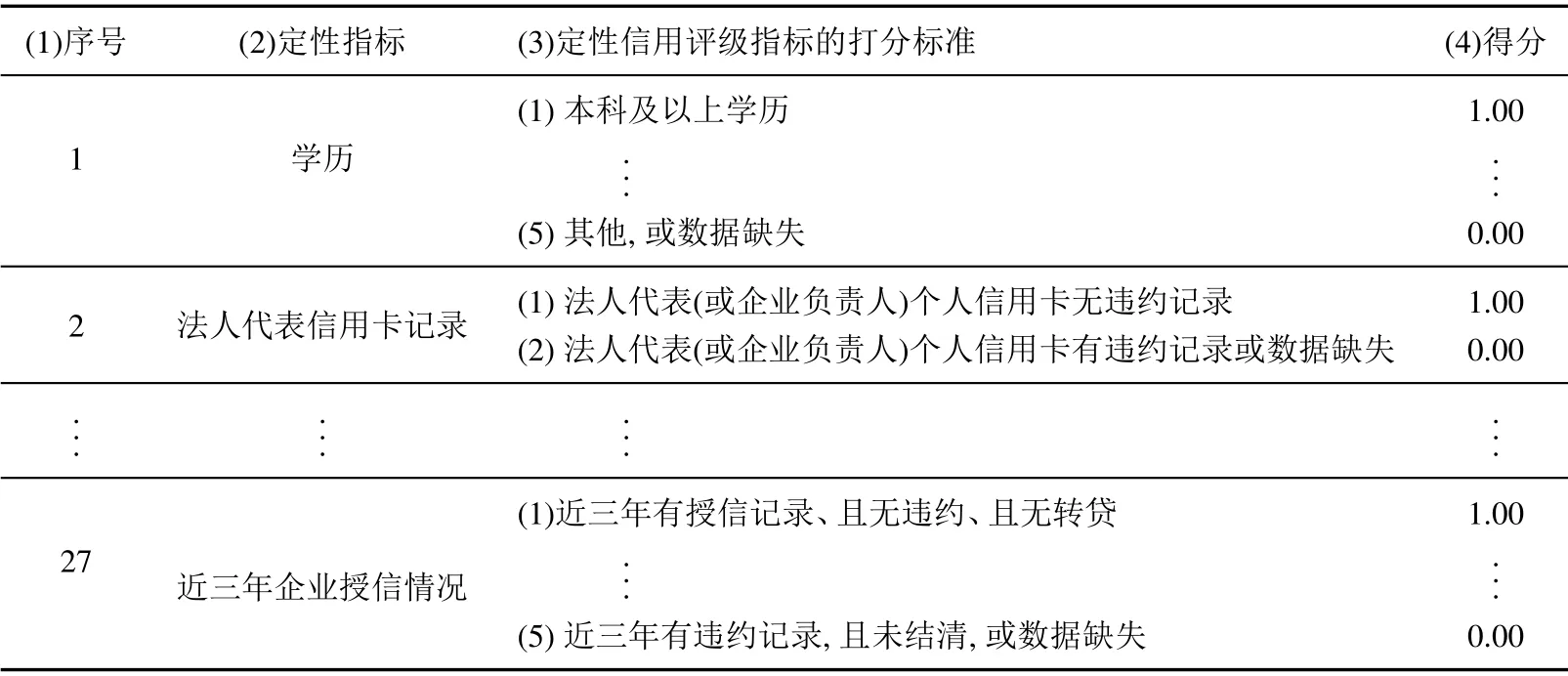
1)定性指标的打分.定性指标在定量分析中不能直接以其数据大小精确地加以衡量,因此有必要对海选的定性指标打分,打分后的定性指标数据可以标准化,从而满足后续定量分析的需要.下文将结合实证分析中具体的定性指标来说明其打分标准.
2)信用评级指标的一致化.将全部信用评级指标分为正向型指标(数值越大越好,如“利润增长率”)、负向型指标(数值越小越好,如“未偿还贷款总额占净资产比例”)及区间型指标(数值在某一个特定区间内较好,如“居民消费价格指数”)三类,并根据信用评级指标的类型分别对其数据进行一致化处理,以消除指标类型的不一致.一致化后信用评级指标的数据类型均转换为正向型指标,从而一致化后的信用评级指标的数值越大,小企业的信用水平就越高.这为后续不同小企业间信用综合得分的大小比较提供了基础.这三类指标一致化处理的具体公式读者可参阅现有文献[24]获取,不赘述.
2.2.2 剔除违约状态识别能力弱的指标
本文通过定量分析方法将依次剔除违约状态识别能力弱、综合信用风险识别能力弱及信息重叠程度高的指标,其原因可主要归结为:1)剔除违约状态识别能力弱指标的原因.违约与否是商业银行信贷决策时关注的焦点.为此,本文利用数据挖掘中被广泛使用的F–检验法,确定并剔除对违约状态影响不显著的评级指标,保证被保留的评级指标均对客户违约风险具有一定的识别能力.2)进一步剔除综合信用风险识别能力弱的信用评级指标的原因.F 检验法仅能剔除少量对违约状态影响极不显著的信用评级指标,无法满足大量海选信用评级指标亟待筛选的客观需要.同时,对违约状态影响显著与否虽十分重要,但却也仅能粗略刻画评级指标识别企业信用风险的能力,无法满足精细刻画企业客户综合信用风险的客观需要.而下文基于指标的信用信息解释度剔除综合信用风险识别能力弱的评级指标却刚好可以弥补这一不足.3)最终再剔除信息重叠指标的原因.首先,评级指标间信息重叠水平高会导致信用评价结果扭曲,因此有必要剔除信息重叠水平高的指标;其次,剔除违约状态识别能力弱及综合信用风险识别能力弱的指标均属于剔除对评价结果影响不显著的指标,因此根据指标筛选的显著再相关标准[25]应在先剔除这两类指标后再剔除信息重叠水平高的指标.本节介绍的是基于F–检验剔除违约状态识别能力弱的评级指标的方法,具体如下.
检验统计量为[26]

其中Nj是信用违约状态Y=j(j=0或1)的样本数量,Y=0表示“非违约”,Y=1 表示“违约”;是违约状态Y=j的所有样本中,信用评级指标X的样本均值;是信用评级指标X的总体均值;J为信用违约状态不同取值的个数,显然这里J= 2;s2j是信用评级指标X对应于违约状态为Y=j的样本构成的样本方差;N为全部企业信贷样本的数量.
F–检验的原假设H0:指标X与违约与否这个指标Y完全不相关.备择假设为H1:指标X与违约与否这个指标Y相关.显著性水平α下F–分布的临界值为Fα(J −1,N −J),若F < Fα,则接受原假设H0,认为信用评级指标X对违约影响不显著,剔除信用评级指标X;否则,则拒绝原假设H0,认为信用评级指标X对违约影响比较显著,保留该信用评级指标X.这里取显著性水平α=0.01.
2.3 剔除综合信用风险识别能力弱的指标
1)剔除综合信用风险识别能力弱的评级指标原理
不难理解,在信用风险综合评价中各信用评级指标彼此影响、相互作用,构成一个综合了大量企业客户综合信用风险信息的复杂系统.因此,理应剔除解释综合信用风险信息能力弱的信用评级指标.为此,本文在现有主成分指标筛选方法基础上,提出了一种基于信用信息解释度的评级指标筛选方法.根据现有主成分指标降维方法在原始信用评级指标集信用违约信息损失很小的条件下,将一组数量众多的信用评级指标降维为少数几个互不相关的主成分.一个指标Xi蕴含的信用信息是通过该指标与各个主成分间的负载系数(相关系数)cij表示的,而现有主成分指标筛选方法却仅依据单个负载系数的绝对值确定一个指标解释原始指标集信息的能力并据此筛选指标其做法并不合理[23].本文测度并剔除解释综合信用风险信息能力弱的评级指标的思路如下:
首先,通过加权负载系数的绝对值ωj×|cij|,反映信用评级指标Xi通过主成分fj解释原始信用评级指标集信用风险信息的能力.一个特定的负载系数cij仅仅表示指标Xi解释主成分fj所蕴含的信用风险信息的能力.而据主成分理论可知,一个主成分fj所蕴含的信用风险信息占原始信用评级指标集信用风险信息的比例为方差贡献率ωj.因此,必须用主成分fj解释原始信用评级指标集信用风险信息的比例ωj,对负载系数的绝对值|cij|打个折扣,这个打了折扣后的加权负载系数ωj ×|cij|才能反映指标Xi通过主成分fj解释原始指标集信用风险信息的能力.之后,通过负载系数绝对值的加权平均∑ωj ×|cij|,反映信用评级指标Xi解释原始指标集综合信用风险信息的能力,称为该评级指标的信用信息解释度(一般性的指标筛选问题中可称之为信息解释度).显然,一个评级指标的信用信息解释度越高,该指标蕴含的信用风险信息越多,越能够精细地刻画借款企业客户的信用风险,该评级指标越应予以保留.这便是本文测度评级指标解释综合信用风险信息的能力,以及剔除解释综合信用风险信息能力弱指标的基本思路.
2)剔除综合信用风险识别能力弱评级指标的步骤
步骤1计算信用评级指标Xi的信用信息解释度

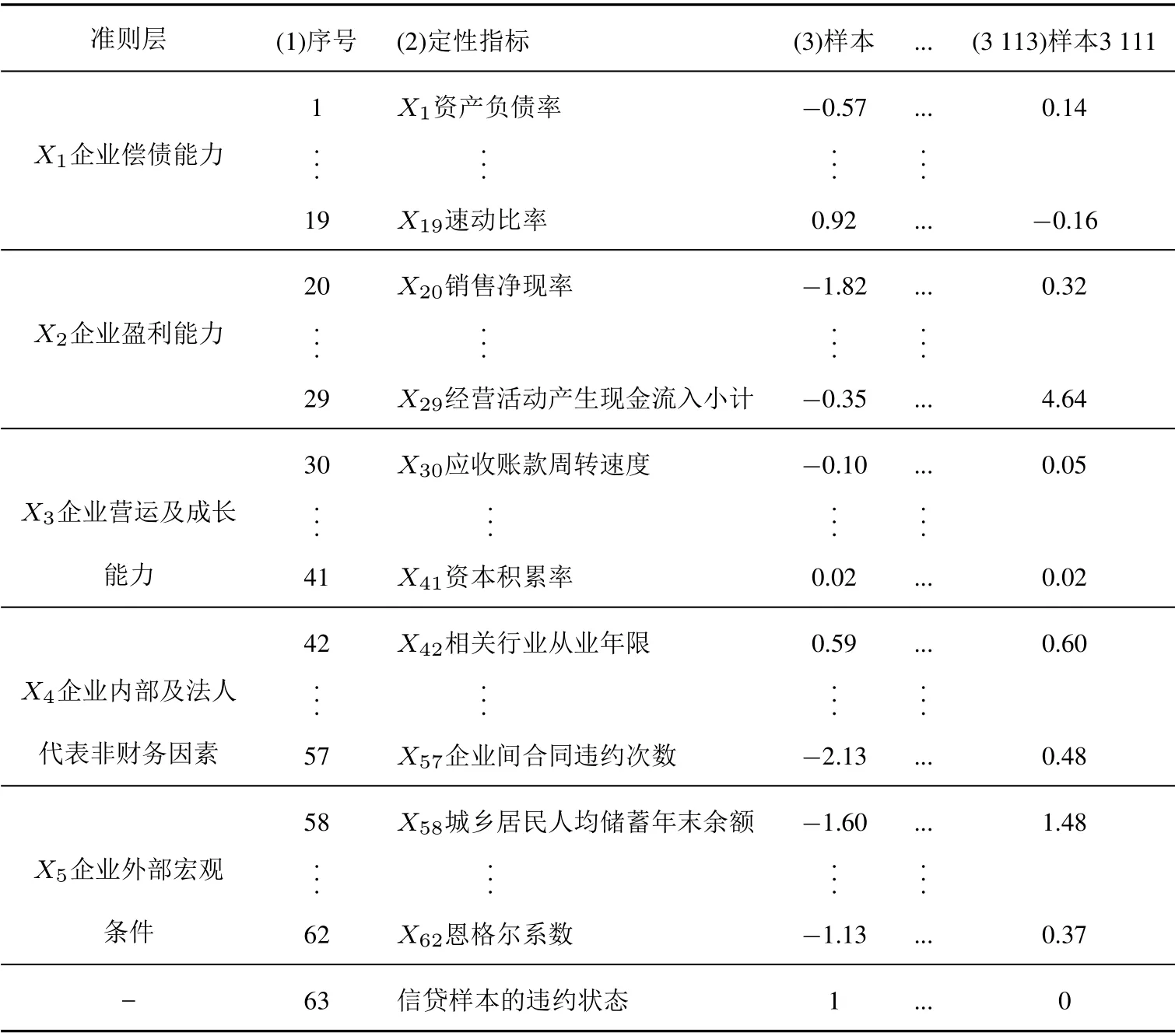
其中ωj是主成分fj解释原始信用评级指标集信息总变异的比例,反映主成分fj解释原始信用评级指标集信用风险信息的比例,且ω1ω2···ωm; 前p个主成分的方差贡献率之和(累计方差贡献率Ωp)表示这p个主成分解释原始评级指标集全部信用信息的比例,若Ωp80%[27],则保留方差贡献率相对较大的前p( 信用信息解释度Ii的经济含义:它表示信用评级指标Xi解释原始信用评级指标集综合信用风险信息的水平,反映信用评级指标Xi在原始信用评级指标集中的相对重要性. 步骤2计算信用评级指标的累计信用信息解释率Rv,即前v个信用信息解释度Ii最大的信用评级指标占全部m个原始信用评级指标信用信息解释度的比例 其中Imi是全部m个原始信用评级指标中第i大的信用信息解释度. 步骤3剔除信用信息解释度小的信用评级指标.若累计信用信息解释率Rv满足 则保留信用信息解释度Ii相对较大的前v个信用评级指标,剔除其余信用信息解释度小的信用评级指标.R0为决策者确定的阈值. 在主成分分析理论中,若信息量大的几个主成分占全部主成分信息的比例达到70% ∼90%[24],就保留这几个主成分.借此思想,为了剔除相对不重要的信用评级指标不妨取累计违约信息解释率的阈值R0为70%.显然,阈值R0越小,保留的信用评级指标就会越少,但指标集包含的信用风险信息就相对地越不全面;反之,阈值R0越大,保留的信用评级指标就会越多,自然指标集包含的信用信息就会越全面,但同时指标集内部的信息重叠现象也会越严重,越容易扭曲信用风险综合评价的结果.而且,一个质量较高的评级模型客观上也要求指标数量不宜太多[28].因此,决策者可根据决策需要适度调整阈值R0的大小. 步骤4剔除信息重叠程度高的信用评级指标.在剔除了解释信用违约风险信息能力较弱的指标后,如果剩余的任意两个评级指标Xi与Xj间的Person 相关系数rij的绝对值大于某个临界点r0,则剔除信用评级指标Xi与Xj中信用信息解释度相对较小的信用评级指标,以避免重叠信息扭曲企业客户信用综合评价结果.这里,将指标筛选的临界点r0取为0.9[21]. 与现有主成分指标筛选方法的主要差别.现有主成分指标筛选方法[21]仅仅依据单个负载系数确定一个指标解释原始指标集综合信息的水平.而据式(2)可知,本文方法在确定一个指标的信息解释度时,既考虑了一个指标的信息蕴含于多个负载系数之中的事实,又考虑了各负载系数所在的主成分对原始指标集综合信息的解释能力(方差贡献率)的差异. 1)检验思路 鉴于费歇尔判别法应用广泛且具有较高的准确度和可靠性[29],本文利用费歇尔判别法确定小企业信用评级指标体系对违约与否判别的准确率.进而,根据该准确率越高、越稳定,评级指标体系识别企业违约风险的能力就越大,评级指标体系越合理的思路,检验信用评级指标体系的合理性. 2)检验方法 假设小企业信用评级指标体系内各信用评级指标分别为Z1,Z2,...,Zp,违约样本的数量为n1,非违约样本的数量为n2.在此基础上,利用费歇尔判别法检验小企业信用评级指标体系合理性的步骤简述如下. 步骤1确定样本Ai=(zi1,zi2,...,zip)所属违约状态总体的标准.在的条件下,若y(zi1,zi2,...,zip)> y0,则判定样本Ai属于非违约总体G2;若y(zi1,zi2,...,zip)< y0,则判定样本Ai属于违约总体G1. 步骤2小企业信用评级指标体系合理性检验.若小企业信用评级指标体系识别信贷样本所属信用违约状态的准确率Rp达到90%以上,则认为该小企业信用评级指标体系识别企业违约风险的能力强,即 其中nrp是全部n个信贷样本中被全部p个信用评级指标正确识别是否违约的样本数量.显然,样本所属违约状态识别准确率Rp越大,越说明小企业信用评级指标体系整体识别信用违约风险的能力越大,小企业信用评级指标体系越显合理.同时,分别基于30%、70%及100%的小企业信贷样本确定小企业评级指标体系对违约状态识别的准确率,以检验违约状态识别准确率的稳定性. 1)数据来源及评级指标海选 本文基于《中小企业划型标准规定》,从中国某商业银行信贷系统中提取了3 111个小企业信贷样本,依据本文提出的6 项信用评级指标海选原则海选评级指标.比如,在信用评级海选指标的选择上我们考虑到小企业通常具有成长性比较高、经营决策易受少数决策者左右等特点,引入了诸如“营业收入增长率”及“法人代表信用卡记录”等指标.最终,构建了包含X1企业偿债能力、X2企业盈利能力、X3企业营运及成长能力、X4企业内部及法人代表的非财务因素以及X5企业外部宏观条件共计5 个准则层、85个指标的小企业信用评级海选指标体系. 2)定性信用评级指标的打分 在定量分析中定性指标无法直接通过其数据大小精确地加以衡量,因此有必要对“学历”等27个定性指标进行打分,以满足指标数据标准化及后续定量分析的需要.为了尽可能地保证定性指标打分的合理性,本研究广泛借鉴、分析了国内外关于信用评级定性指标打分的理论研究成果,并与项目合作银行负责小企业信贷业务的69位各级业务骨干对定性指标的打分标准进行了多轮次、反复的合理性论证,最终确定了本文所涉及的27个定性指标的具体打分标准,具体打分标准列于表1. 表1 定性的信用评级指标打分标准Table 1 Scoring standard of qualitative credit rating indices 3)信用评级指标的一致化 为了保证不同信用评级指标类型一致性,将85个海选的评级指标划分为正向、负向及区间型三种类型的指标,并根据一致化处理公式分别进行评级指标数据的一致化处理.一致化后的指标均为正向型. 3.2.1 基于违约状态识别能力的信用评级指标筛选 本节将利用F–检验剔除对小企业违约状态影响不显著的评级指标,保证保留下来的评级指标皆对违约风险具有一定的识别能力.以85个海选的评级指标中“净资产收益率”的筛选为例,将该指标与小企业样本违约状态数据(违约记为1,未违约记为0)一并代入式(1),得到指标“净资产收益率”的F–检验值F= 5.962.同时,设显著性水平为α= 0.01,由于F–分布的临界值为F0.01(2−1,3 111−2) = 6.643,因此接受原假设“H0:指标“净资产收益率”与违约状态指标Y 完全不相关”,剔除“净资产收益率”这个评级指标.类似地,共累计剔除对小企业违约状态影响不显著的评级指标23个,即暂时保留了62个评级指标,其Z标准化[24]数据列于表2第1行∼第62 行第3列∼第3 113 列.3 111个小企业信贷样本对应的违约状态列于表2最后一行第3列∼第3 113列. 表2 F–检验后的小企业信用评级海选指标Table 2 Primary election of credit rating indices for small enterprises after F–test 3.2.2 基于综合信用风险识别能力的信用评级指标筛选 本节将剔除剩余62个指标中综合信用风险识别能力弱的指标,具体步骤如下. 步骤1方法适用性检验.本文信用信息解释度是基于现有主成分降维法的部分参数确定的,因此同主成分降维法一样需要先利用巴特利特球度检验和KMO检验进行适用性检验.本文的巴特利特球度检验统计量的概率P值为0.000,小于设定的显著性水平0.05,而且KMO=0.892达到了0.5以上[31],因此方法适用性检验通过.巴特利特球度检验和KMO检验结果可由统计软件IBM SPSS21方便得到. 步骤2计算信用评级指标的信用信息解释度.根据文献[27]可以获得前18个主成分的方差贡献率向量(ω1,ω2,...,ω18)=(24.252%,13.264%,...,1.254%)(因累计方差贡献率Ω18=81.146%>80%,故保留前18个主成分).同时,亦不难得到负载系数矩阵C= (cij)62×18,取绝对值后列于表3第3列∼第20 列.再将表3第3列∼第20列的数据、(ω1,ω2,...,ω18)的数据代入式(2),得到待筛选的62个信用评级指标各自的信用信息解释度Ii(i=1,2,...,62),将其与表3第2 列各指标依次对应地列于表3第21列. 步骤3计算累计信用信息解释率.将表3第21列各指标的信用信息解释度代入式(3),得到信用信息解释度较大的前v个信用评级指标的累计信用信息解释率Rv,v=1,2,...,62,列于表3第22列. 步骤4剔除信用信息解释度小的评级指标.据表3第22列第1行∼第32行可知累计信用信息解释率满足:R31= 69.781%< R0= 70%< R32= 71.258%.因此,暂时保留表3第21列中信用信息解释度最大的32个信用评级指标,并依信用信息解释度由大至小的顺序,将指标筛选结果列于表3第23列. 表3 基于信用信息解释度的指标筛选Table 3 Indices screening based on default information interpretation degree 步骤5基于信息重叠的评级指标筛选.以暂时保留的32个指标中“X24成本费用净利率”与“X9净利润现金含量”为例,两者Person相关系数的绝对值达到了0.918,大于临界点0.9.指标X24的信用信息解释度为0.193 125,大于指标X9的信用信息解释度0.125 024.因此,剔除信用信息解释度较小的指标X9.类似地,最终累计剔除了10个信息重叠程度高的指标,剩余的22个评级指标共同构成了小企业信用评级指标体系,列于表4第2列. 表4 与现有方法的对比Table 4 Comparison with the existing method 3.3.1 违约风险识别的准确率及稳定性检验 为了检验小企业信用评级指标体系的合理性,本节将从违约风险识别的准确率、稳定性两个角度系统检验小企业信用评级指标体系的合理性. 步骤1确定全部信贷样本违约状态识别的准确率.根据文献[30]可以得到费歇尔判别函数y=−0.224Z1+0.253Z2+0.209Z3+···−0.341Z22,费歇尔判别的临界值y0=−0.000 12.从而,根据上文样本所属违约状态总体的判别标准可以判定全部3 111个小企业样本所属的违约总体,列于表5第5列. 进而,通过对比表5第5列∼第6列可以确定全部信贷样本所属违约状态是否得到正确识别,表5第7列以“√”表示样本所属违约状态得到了正确识别,以“×”表示样本所属违约状态识别错误.在此基础上,表5第7 列容易得到全部3 111个信贷样本(100%的信贷样本)被识别的准确率R22为96.9%.显然,本文建立的小企业信用评级指标体系具有较高的信用风险识别能力. 表5 违约状态的判别Table 5 Identification of default status 步骤2识别违约状态准确率的稳定性分析.本文随机选取了全部3 111个信贷样本的30%的信贷样本、70%的信贷样本,分别计算了以信用评级指标体系识别样本所属信用违约状态的准确率,分别为95.1%及97.2%.不难发现,本文建立的小企业信用评级指标体系准确识别企业客户违约风险的能力不但很大,而且很稳定.就此而言,本文建立的小企业信用评级指标体系是合理的.此外,在将式(4)中阈值R0分别调整为80%和90%的前提下,所获得的两套新的评级指标体系识别违约状态的准确率亦均达到了90%以上,分别达到了95.7%和90.4%,这说明本文建立的指标筛选模型较为鲁棒. 3.3.2 与现有指标筛选方法的对比 本文工作的重点在于信用评级指标的系统筛选,而文中的信息解释度方法是基于现有主成分指标筛选方法改进提出的.因此,可将上文模型中“2.3 节”中的信息解释度方法替换为现有主成分指标筛选方法,而其余指标筛选步骤保持不变,并将筛选后得到的列于表4第3列的信用评级指标体系与列于表4第2 列的本文方法构建的小企业信用评级指标体系识别违约风险的准确率进行对比,以进一步说明本文指标筛选方法的有效性.现有主成分指标筛选方法的运用过程可参阅现有文献[21,22]详尽了解,不赘述.根据表4最后一行可知,本文方法比现有主成分指标筛选方法构建的小企业信用评级指标体系识别全部企业客户样本违约状态的准确率高了近20%.因此,就违约风险识别能力而言本文方法构建的小企业信用评级指标体系相对更优.这一结果,也不难从现有方法构建的小企业信用评级指标体系中包含了较多不甚符合信贷评级实践情况的评级指标中找到部分原因,如“X58城乡居民人均储蓄年末余额/(元/人)”、“X60居民消费价格指数(以上一年为100)”及“X61城市居民人均可支配收入/元”等. 本文以建立商业银行小企业客户信用评级指标体系为目的,提出了集信用评级指标海选,剔除违约状态及综合信用风险识别能力弱的评级指标,检验信用评级指标体系合理性等一套系统的小企业信用评级指标体系构建方法.同时,基于中国一家商业银行的小企业信贷业务的历史数据进行了实证研究,构建了小企业信用评级指标体系.研究表明,本文建立的小企业信用评级指标体系识别信用风险的准确率不但高,而且稳定.此外,除信用评级指标海选外,本文的评级指标定量筛选及评级体系合理性检验等方法亦可应用于其余类型企业的信用评级指标体系的构建.

2.4 信用评级指标体系的合理性检验

3 小企业信用评级指标体系构建
3.1 小企业信用评级海选指标体系的建立
3.2 信用评级指标的筛选


3.3 小企业信用评级指标体系的合理性检验

4 结束语
