基于模糊逻辑推理系统的簇首选择算法
2021-05-10朱国晖
朱国晖,杨 瑛
(西安邮电大学 通信与信息工程学院,陕西 西安 710121)
车联网[1]是以车辆作为网络中的节点进行无线通信的网络。尤其是在路边单元(Road Side Unit,RSU)无法接入的情况下,车辆与车辆之间的直接通信将成为网络中数据传输的一种重要方式。在不考虑车辆节点与RSU进行数据传输的情况下,网络中将无中心节点,所有节点地位平等,共同承担路由与数据传输的功能,此时网络结构是平面式的。在平面式网络结构中,源节点(Source Node,SN)与目的节点(Destination Node,DN)之间存在多条路径,节点可以选择不同的路径进行数据的传输,以减少网络拥塞情况的发生。为了更好地提升车联网的数据传输性能和网络的可靠性,研究人员提出了采用分簇算法改善网络性能[2-4]。
分簇算法的基本原理是将网络中的节点根据一些规则集而聚合成为一个簇,并在簇内选择一个节点成为该簇的簇首(Cluster Head,CH),以便簇内和不同簇间或网络的其余部分进行数据传输[5]。将作为网络节点的车辆划分为簇,有助于限制信道之间的竞争,通过网络资源在空间上的复用进一步提升网络的性能[6-8]。
由于车辆节点的快速移动性以及在节点数量较多的情况下,较大的路由开销以及网络拓扑的快速变化将会使得节点之间的簇结构变得不稳定,网络的可扩展性变差。针对该问题,采用适当的分簇算法对网络进行分层,使处于不同层的节点肩负起不同的职责,有效对网络进行扩展,并且在网络节点数量较多的情况下,减少信息冗余。因此,有效降低因选择簇首和在高动态性和快速变化的网络拓扑中维护所有簇成员过程中所带来的额外网络开销[9]是分簇算法中的关键问题。
早期提出的分簇算法有最小标识优先算法和最大连接度优先算法,其均以单个因素作为簇首选择的标准,性能较差。随后,文献[10-11]对这两个基本算法进行了改进,更加符合不同的场景需求,但固定选择一些因素作为其簇首选择的衡量标准,在一定程度上影响了节点成为备选簇首的概率。目前,已有的关于节点分簇的算法,如文献[12]提出的簇首选择算法没有考虑车辆节点在网络中所处位置信息的变化对簇结构的影响。基于三角模糊数的簇首选择算法[13]通过预测车辆节点的加速度完成对簇结构的划分,考虑的因素较为单一。文献[14]从降低基站负载的角度提出了一种分布式聚类算法和基于进化博弈论的簇首选举算法,未考虑车辆节点的运动特性。基于移动性的稳定聚类方法[15]利用车辆节点的速度、方向以及链路质量等度量用于簇首选择,但并未考虑到节点在网络中的邻居环境对簇结构稳定性的影响。文献[16]考虑了节点的信息,但节点无运动属性。
考虑到车辆节点所处的网络环境,及在实际情况中节点的运动特性,拟提出一种基于模糊逻辑推理系统的簇首选择算法。利用模糊逻辑推理系统,定义语言规则,综合考虑车辆节点在网络中的相对速度、相对邻居节点数与相对中心度,确定每一个节点成为簇首的优先级,从而选择较为适合的节点成为簇首并形成簇结构。
1 基于模糊逻辑的分簇算法
1.1 层次网络模型
车辆节点与路边基础设施构成的车联网应用场景如图 1所示。在网络中,车辆作为节点,没有功能上的不同。
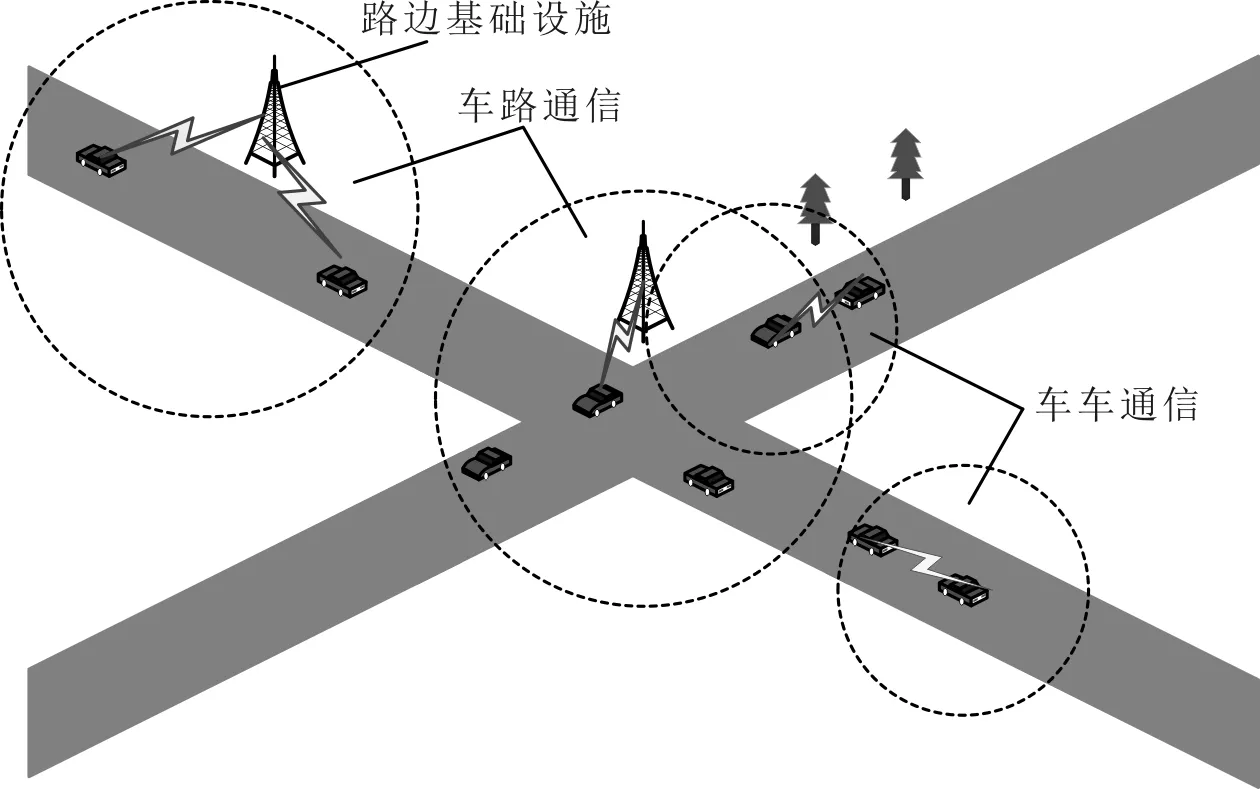
图1 车联网应用场景
为了提高网络的可扩展性,需要对网络进行分层处理,将原本处于同一平面的节点进行层次的划分,选出能够承担不同作用的节点。网络分层示意图如图 2所示。

图2 网络分层示意图
图2中的底层表示平面网络的底层结构,节点之间不做区分,相互之间根据需求进行数据的传输。中间层代表对节点进行了初步划分,在传输数据时,不再是从SN到DN进行一跳或多跳的直接传输,而是从SN将数据先传输至自己所在簇的簇首节点,再由簇首节点将数据传输至DN所在簇的簇首,最终到达DN。最顶层表示在不同区域选出最适合成为簇首的节点。
1.2 基于模糊逻辑的簇首选择算法
在分簇路由算法中,簇首的产生是簇形成的基础。为了形成一个较稳定的簇结构,尽力降低单位时间内簇的拆散与重组的次数,分别从节点的运动角度、位置角度和邻居环境角度出发,考虑节点的相对速度(rel-V)、相对中心度(rel-C)和相对邻居节点(rel-N)数等3个因素,通过模糊推理与解模糊化过程,得到每一个节点成为簇首的优先级,最终选择出最适合成为簇首的节点。
1.2.1 模糊逻辑推理系统
簇首的选择原则是基于模糊逻辑。常见的模糊推理系统可分为纯模糊逻辑系统、Sugeno型与Mamadani型等3种。其中,纯模糊逻辑系统是其他类型模糊逻辑系统的核心部分,其提供了一种将语言信息量化的方法,并且是在一般模糊逻辑的原则下利用这类语言信息的一般化模型。纯模糊逻辑系统可以看作为一个映射关系,输入模糊集A通过模糊逻辑系统中的模糊规则库与模糊推理得到输出模糊集B,如图 3所示。一般化模糊逻辑系统如图 4所示。

图3 纯模糊逻辑系统
Mamadani型模糊推理算法采用if/then规则定义输入与输出之间的模糊关系,如ifxisAandyisBthenzisC。其中,x和y为输入语言变量,A和B为推理前件的模糊集合,z为输出语言变量,C为模糊规则的后件。将已定义的模糊规则作用于输入语言变量,通过模糊推理将输出合并成模糊集合,采用相应的解模糊化方法,最终得到精确的输出。较为常用的解模糊化方法有质心法、面积重心法和极大平均法等。
Sugeno模型将解模糊化与模糊推理相结合,输出量为精确量。其中,精确输入量模糊化和模糊逻辑运算过程与Mamadani型相同,但输出隶属度函数的形式与Mamdani型存在差异。举例说明,一阶Sugeno型模糊规则的形式为ifxisAandyisBthenz=px+qy+r。其中:x和y为输入语言变量;A和B为推理前件的模糊集合;z为输出语言变量;p、q和r为常数。由于高阶数的Sugeno模型增加了复杂性,性能的改善效果并不是很好,故很少使用。
1.2.2 模糊逻辑输入变量
将车辆作为网络中的节点,节点的相对速度、相对中心度和相对邻居节点数等3个变量的表示如下。
1)节点的相对速度。从运动角度考虑,假设某区域内共有n个节点,节点i的速度为vi,则相对速度为
对vr,i结果进行正规化,使其值映射到[0,1]区间之内,并用Vr,i表示正规化后的节点的相对速度,即
2)节点的相对中心度。从节点所处的位置角度进行考虑,相对中心度表示为
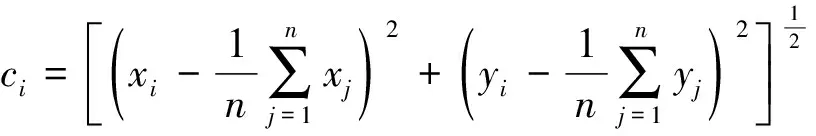
式中,xi与yi分别表示节点i的x轴坐标与y轴坐标。正规化后的节点的相对中心度表示为
3)节点的相对邻居节点数。从邻居环境角度进行考虑,将某节点的邻居节点bi定义为在该节点通信范围内的所有节点,则网络中节点的相对邻居节点数表示为
1.2.3 变量的模糊化与模糊规则
为节点的相对速度、相对中心度和相对邻居节点数等3个输入参数选择语言变量,并为其匹配隶属度函数。语言变量分为不同的等级,节点的相对速度={very low,low,middle,high},节点的相对邻居节点数={low,middle,high},节点的相对中心度={very few,few,many,very many}。隶属度函数选择三角形函数与梯形函数,3个输入参数的隶属度函数如图5所示。

图5 输入参数的隶属度函数
根据if/then语言规则,定义了48条模糊规则,如表1所示。

表1 模糊规则库

续表1 模糊规则库
系统输出为节点成为簇首的概率,规定为{very low,low,little low,middle,little high,high,very high}7个等级,对节点进行成为簇首优先级的划分,如图 6所示。

图6 输出隶属度函数
同一个输入参数可对应两个不同的隶属度函数,得到不同的模糊值,即一个输入可同时适用于多个模糊规则。利用Min-Max决策方法将所有规则组合出的模糊结果集合并,在该方法中,将输入值中的最小值作为每条规则的输出值,在组合不同规则的结果时,将同规则下最大的数值作为该规则的最终值。
例如,假设某节点的相对运动速度rel-V为0.25,对应的模糊语言变量的隶属度为{very low:0.75,low:0.25,middle:0,high:0 }。相对邻居节点数rel-N的值为0.3,对应的模糊语言变量的隶属度为{very few:0.5,few:0.5,many:0,very many:0}。相对中心度rel-C的值为0.5,对应的模糊语言变量的隶属度为{low:0,middle:1,high:0}。在表1中进行查找,其分别对应“规则17”“规则18”“规则21”“规则22”,则该节点的相对运动速度为{very low}的隶属度为0.5,相对邻居节点数{very few}的隶属度为0.5以及相对中心度{middle}的隶属度为1。对应“规则17、18、21、22”并考虑Min-Max决策方法,可得到该节点成为簇首的优先级集合为{very low:0.5,low:0.5,little low:0.25},其他对应规则整理如图 7所示。

图7 Min-Max决策方法示意图
以Min-Max决策方法给出所有模糊的结果,利用重心法进行解模糊化运算,形成最后的精确输出值为
(1)
式中:x表示隶属度函数的横轴;f(x)表示隶属度函数集。计算不同隶属函数对应的簇首概率,通过式(1)最终得到该节点能够称为簇首的可能的概率值。
2 模型仿真与性能分析
利用Matlab仿真软件对基于模糊逻辑推理系统的簇首选择算法的性能进行仿真,在不同的车辆行驶速度与车辆密度场景下,计算簇首生存时间,并与文献[12]算法和文献[13]算法进行对比。
2.1 簇头选择算法模型
簇头选择算法的仿真结果如图8所示。其中,图8(a)表示从节点相对速度和相对邻居节点数这两个角度考虑节点成为簇首的优先级的关系。随着节点相对速度和相对邻居节点数隶属度值的增加,节点成为簇首的概率也随之增加。图8(b)表示从节点相对运动速度和相对中心度这两个角度考虑节点成为簇首优先级的关系。

图8 簇头选择算法模型仿真结果
2.2 性能分析
为了测试算法的有效性,分别对比所提算法、文献[12]算法和文献[13]算法等3种算法在不同车辆密度与车辆行驶速度的情况下,对簇稳定性的影响。设定每次仿真时间为500 s,共仿真20次,取平均值作为最终的仿真数据。不同车辆密度即交通流密度对簇结构稳定性影响的仿真结果如图9所示。

图9 车辆密度对簇稳定性的影响
由图9可以看出,随着车辆密度的增大,使得车辆之间的间距变小,促进了簇结构的稳定性,因此3种算法均表现出簇首的平均生存时间在逐渐延长。相对而言,所提算法对于维持簇首的平均生存时间更为有效,这是因为在选择簇首时,对模糊规则库的划分更加详细,从车辆的实际运动场景出发考虑,所选择出的节点在运动角度更加适合成为簇首。
仿真过程中的车辆行驶速度服从正态分布,车速范围为30~120 km/h。不同的车辆行驶速度对簇结构稳定性影响的仿真结果如图10所示。

图10 车辆行驶速度对簇稳定性的影响
由图10可以看出,随着车辆行驶速度的增加,簇首平均生存时间随之减少,这是因为随着车速范围的增加,车辆速度的分布会逐步分散,网络拓扑变化加剧。相比之下,所提算法较其他两种算法,能够提升簇首平均生存时间,其原因在于选择簇首时对实际场景中的车辆行驶速度进行了详细的划分,因此从运动角度方面来讲,这样选择出来的节点更适合成为簇首。
通过簇结构的拆分重组的流动性定义簇结构的稳定性。一个簇的结构越稳定,越不容易被拆分重组,簇整体维持的时间也就越长。3种算法的簇稳定性对比如图11所示。可以看出,在车辆不同流动率情况的比较下,所提算法具有更好的稳定性,这是因为该算法在进行簇首选择时更加着重的考虑了车辆节点所处的环境,考虑了邻居节点数量与节点所处的地理位置。

图11 簇稳定性的对比
3 结语
基于模糊逻辑推理系统的簇首选择算法将各节点相互平等的平面网络进行逻辑上的层次划分,提高了网络的扩展性,并在层次网络中将节点分为簇首节点与非簇首节点,减少了网络中由于节点未分工所带来的的信息冗余所导致资浪费的情况。簇首节点的选择分别从运动角度、位置角度和环境角度等3个方面综合考虑,利用模糊逻辑推理系统,选择参数最接近网络平均值的节点成为簇首。仿真结果表明,所提算法较其他两种算法,进一步提升了簇首的平均生存时间,增加了簇结构的稳定性。
