基于改进YOLOv3的工业安监目标检测算法
2021-05-07赵春晖
赵春晖, 李 瑞, 宿 南
(哈尔滨工程大学 信息与通信工程学院, 黑龙江 哈尔滨 150001)
近年来,随着监控摄像头的普及,公共安全越来越被重视[1].此外,计算机视觉蓬勃发展,智能监控应运而生,智能监控是利用计算机视觉技术对视频信号进行处理、分析和理解.而在智能监控中,一个重要的研究方向是目标检测,目标检测是在图像中定位并分类出感兴趣的目标.而基于工业安监领域的目标检测,由于相机的俯仰角,会使成像存在近大远小的特点,产生小目标.而在通用目标检测模型中,特征提取网络都存在下采样的过程,小目标在下采样之后,特征图非常小,导致检测器检测效果不好.另外,在很多情况下,数据集中的小目标样本少,导致神经网络在学习的过程中被大目标主导,使得目标检测算法检测小目标的能力较差.上述原因导致现有的算法很难满足实际需要,因此设计一个有较高鲁棒性的目标检测算法很有必要.
目标检测可以分为传统算法和深度学习算法[2].随着R-CNN等深度学习方法的出现,深度学习方法在特征提取层面优于传统方法的手动特征,开启了基于深度学习目标检测算法的热潮.基于深度学习的目标检测算法大致分为2类.
1) 双阶段方法.主要思路是先通过启发式方法或者CNN网络产生一系列稀疏的候选框,然后对这些候选框进行分类和回归.这类方法的优点是准确度高,但往往速度较慢.
2) 单阶段方法.主要思路是均匀地在图片的不同位置上密集抽样,然后利用CNN提取特征后直接分类和回归,整个过程只需一步,因此速度较快.
在双阶段算法中,Girshick等[3]于2014年提出R-CNN(region conventional neural network),Ren等[4]在2017年提出Faster R-CNN,分别利用卷积神经网络和RPN提高了目标检测的性能.2014年He等[5]提出了SPP-Net,解决了神经网络要求固定输入尺寸的问题.2016年Dai等[6]提出了R-FCN,利用position sensitive score map把目标的定位信息融合进ROI pooling,保证了分类所需要的平移不变性.Cai等[7]提出了Cascade R-CNN,该方法通过级联不同IOU阈值(界定正负样本)的输出,使不同IOU值检测与其相对应的IOU值的目标.在单阶段算法中,Redmon等[8]在2016年提出了YOLOv1(you only look once:unified,real-time object detection),创造性地提出了单阶段目标检测算法,将分类和回归在一个步骤中完成,极大地提高了目标检测速度.Liu等[9]在2016年提出了SSD算法(singleshot multibox detector),相对于YOLOv1,其通过多尺度特征图,利用卷积进行检测和设置先验框提高了准确度.Redmon等[10]在2018年提出了YOLOv3,其借鉴了残差网络的结构,形成了更深的网络层次及多尺度预测,提升了检测多类平均精度和小目标检测效果;Tan等[11]在2019提出了一种加权的双向特征金字塔结构BiFPN,用于快速特征融合,之后提出了新的联合放缩方式,将检测网络的4部分进行了统一处理,以EfficientNet作为backbone,生成了高效快速,适用于不同计算条件的检测网络,但该方法较难训练.
由于智能监控的目标检测算法需要处理实时视频数据,需要较高的推理速度,而双阶段算法在速度上明显差于单阶段算法,因此选用单阶段算法.而在经典的单阶段算法中,SSD和RetinaNet[12]在总体性能上已经落后于YOLOv3,YOLOv4和YOLOv5相较于YOLOv3并没有实质的改进,而是各种tricks的组合,并且各种组合对不同的数据集的表现不一致,而对YOLOv3的改进可以很好的兼容到后续YOLOv4、YOLOv5.EfficientNet由于参数多、训练难度大,对GPU的要求非常高,因此本实验选取YOLOv3作为基础算法,对其进行研究和改进.
为了提高YOLOv3对小目标的检测精度及多尺度目标的鲁棒性,首先利用数据增强对部分数据进行填充并放缩,形成小目标样本;接着将backbone提取的特征接多尺度池化层,捕捉到多个尺度的目标信息.在整个网络中,采用更加平滑的Mish[13]激活函数,而对于某些对算法处理速度要求不高的场景,采用多尺度测试进一步提高检测算法的检测精度.
1 YOLOv3改进算法
1.1 YOLOv3原理简介
YOLO系列算法的输入是整张图像,利用整张图像的上下文信息直接从像素获得可能的类别以及回归边界框,是一种端到端的算法,没有生成候选区域的中间步骤,因此能够快速的将目标与背景区域区分.YOLOv2[14]的骨干网络是Darknet-19,YOLOv3则参考了残差网络的结构,在骨干网络中引入了残差块,因此能够降低训练深层网络的难度,并且其骨干网络的深度也扩展到Darknet-53.Darknet-53含有53个卷积层,每个卷积层包含卷积运算、批归一化处理和Leaky ReLU[15]激活函数,Darknet-53输出3个尺度的特征图,大小分别是input-size/32、input-size/16、input-size/8,3个尺度的特征输入到检测网络的感受野依次减小,最小的输出特征图的大小为输入的1/32,感受野较大适合检测大目标.同理,其他尺度2个适合检测中目标和小目标.
1.2 改进的YOLOv3系列目标检测算法
针对实际监控数据的多尺度和小目标问题,从检测网络的4部分着手,对YOLOv3的输入、骨干网络和detection neck进行了研究及优化.如图1所示,改进分为2个方向:①利用目标可变占比的数据增强算法数,从数据层面改善算法精度;②改变了YOLOv3的算法结构:在neck部分采用了多尺度池化层,从特征融合层面提高YOLOv3算法的检测精度.

图1 改进的算法结构Fig.1 Improved algorithm structure
1.2.1 目标可变占比的数据增强算法
选取的YOLO算法包含水平翻转、随机裁剪、随机平移数据增强算法.这些数据增强的方法都没有涉及到对数据尺度方面的增强,而研究的2个数据集小目标都比较多,针对这2个数据集中小目标比较多的特点及原始存在的数据增强对小目标并没有较好的改善作用,在训练阶段应用目标可变占比数据增强算法(variable target percentage algorithm,VTP)改善算法对小目标的精度.其算法的表达式如式(1)、(2)所示.
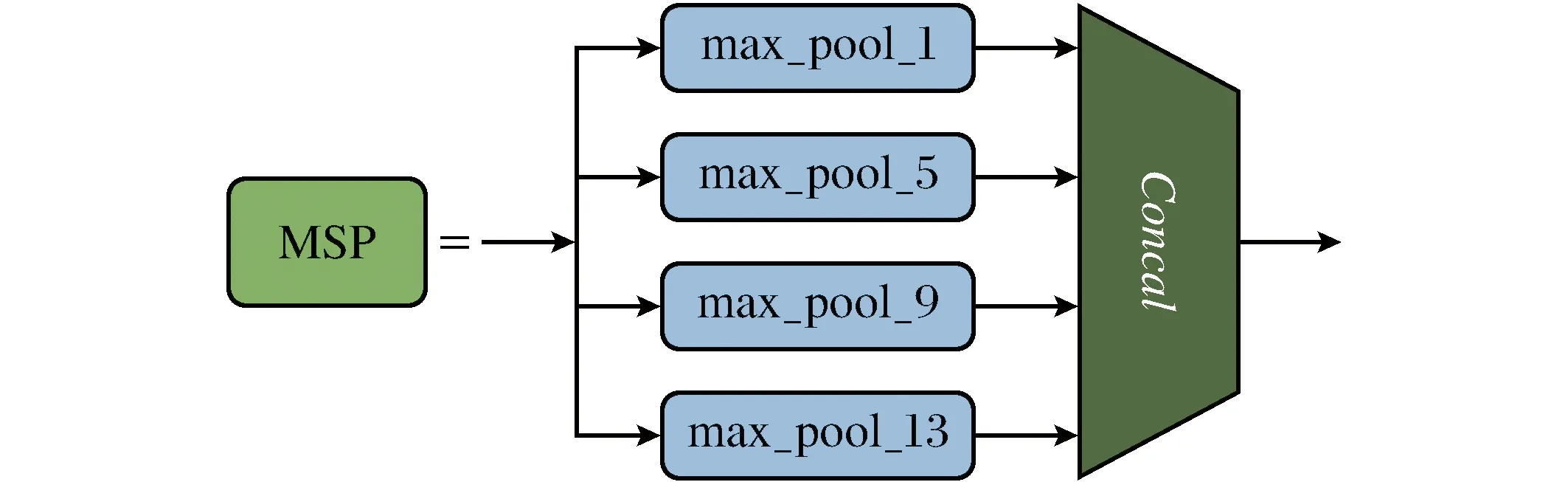
式中:Fimgin(x,y)|w=t′ (a) 原图(b) VTP后图像 图3 多尺度池化层Fig.3 Multi-scale pooling layer 1.2.2 多尺度特征池化层 池化操作在神经网络不可或缺,它能够在尽可能保留图片主要信息的情况下降低图片或是特征的尺寸,能减少计算量及特征的数量,使得网络更加专注于主要特征,增大卷积核的感受野,增强神经网络的拟合能力. 多尺度池化层(multi-scale pooling layer,MSP)将特征通过不同的最大池化(输出与输入尺寸相同)后进行拼接,能够捕捉不同尺度下的特征,提高了算法对不同尺度目标的敏感度,进而提高算法的鲁棒性.此外,该模块能够扩大神经网络的感受野,使网络学习到更好的特征.本文的多尺度特征池化模块中,有如图3所示的4个不同大小的池化结构,能捕捉不同尺度的有效特征,使提取的特征的鲁棒性更好.该模块函数表达式如式(3)所示. 式中:FMSP_in为多尺度池化层的输入特征;max_pool_1、max_pool_5、max_pool_9、max_pool_13分别为1×1、5×5、9×9、13×13最大池化:concat表示对特征张量进行拼接,FMSP_out为多尺度池化层输出的融合特征. 实验在安全帽佩戴和口罩佩戴2个数据集上进行,包括工地、工厂、培训教室等工业安监场景.在安全帽佩戴数据集中包含训练集5 677张、测试集1 894张,部分数据如图4所示.在口罩佩戴数据集中包含训练集6 468张、测试集2 772张,部分数据如图5所示. 图4 安全帽佩戴数据集样图Fig.4 Sample images of helmet wearing data-set 图5 口罩佩戴数据集样图Fig.5 Sample images of mask wearing data-set 从图4、图5可以看出,这2个数据集尺度多样化,目标大小差异较大,算法需要提高对不同大小目标检测的鲁棒性. 2.1.1 操作平台配置 操作系统为Ubuntu16.04,处理器为Inter(R)Core(TM) i5-6500,主频3.2GHz,内存32GB,GPU为1080Ti. 2.1.2 实验参数 激活函数将Leaky ReLu 替换为Mish激活函数. 训练参数:batch=2;input_size=[320, 416, 512, 608, 704, 800,896,992];Lr_st=e-4;Lr_end=e-6;warm_ep=2;total_ep=80.测试参数:bacth=2;input_size=544;置信度阈值0.3;IOU阈值0.45. 当迭代次数x小于设置回暖次数(warmup_ep)时,学习率Lr与迭代次数x成正比,当两者相等时,学习率达到最大值Lr_st,之后学习率随着迭代次数的增加不断减小,且变化较快. 表1和表2是基础算法和改进算法在安全帽数据集和口罩数据集上的结果,表中:单类平均精度是目标检测单类的综合评价指标,是准确率和召回率与坐标轴围成的面积;多类平均精度是不同类别平均精度的平均值. 表1 安全帽佩戴检测最佳实验结果Table 1 Optimal experimental results of helmet detection 表2 口罩佩戴检测最佳实验结果Table 2 Optimal experimental results of mask detection 表1为安全帽佩戴检测的基础实验结果和最佳实验结果,改进算法在多类目标上的检测平均精度都有提高,在佩戴安全帽人员上,平均精度提高2.60%,在未佩戴安全帽人员上,平均精度提高0.48%,多类平均精度提高1.54%,且改进算法与原算法在测试时间上相当. 表2为口罩佩戴检测基础实验结果和最佳实验结果,改进算法在佩戴口罩人员上平均精度提高0.34%,在未佩戴口罩人员上平均精度提高4.22%,多类平均精度提高2.28%,改进算法和基础算法耗时相当. 图6 、图7分别为佩戴安全帽和口罩部分检测结果示意图(见封3),在佩戴安全帽数据中,蓝色方框代表佩戴安全帽,黄色方框代表未佩戴安全帽;在口罩数据集中,蓝色方框代表未佩戴口罩,黄色方框代表佩戴口罩. 本文实验是在单尺度测试下进行,从图6和图7都能看出,对于原始算法中一些漏检的小目标,改进算法能够准确的回归并分类,提高了对小目标的检测能力. (a) YOLOv3基础算法结果(b) YOLOv3+MSP+VTP算法结果 (a) YOLOv3基础算法结果(b) YOLOv3+MSP+VTP算法结果 表3、表4分别为安全帽佩戴检测消融实验结果和口罩佩戴检测消融实验结果,包括基础实验结果、单一改进方法实验结果、组合改进方法实验结果,其中MST是多尺度测试,采用单类平均精度、多类平均精度和时间消耗评价指标. 表3 安全帽佩戴检测消融实验Table 3 Ablation experiment of helmet detection 表4 口罩佩戴检测消融实验Table 4 Ablation experiment of mask detection 2.3.1 安全帽数据集 从表3可以看出,单个改进方法均能够在一定程度上提高多类平均精度(MST方法提高4.72%, MSP方法提高1.53%, VTP方法提高1.90%).在组合改进方法中,VTP+MSP方法提高1.54%,检测速度基本不变;VTP+MST方法提高4.83%,但检测速度大幅度降低,可见多尺度测试在牺牲速度的前提下极大地提高了检测的精度. 2.3.2 口罩佩戴数据集 从表4可以看出,单个改进方法均能够在一定程度上提高多类平均精度(MST方法提高3.94%, MSP方法提高2.43%, VTP方法提高1.96%).在组合改进方法中,VTP+MST方法多类平均精度提高2.28%,检测速度基本不变;VTP+MST方法多类平均精度提高4.62%,但检测速度大幅度降低,可见,采用多尺度测试在牺牲速度的前提下极大地提高了检测的精度. 从表3、表4结果和图6图7可以看出,改进方法在2个数据集中多类平均精度均有所提高.VTP方法能够从数据层面解决训练样本小目标较少的问题,使得神经网络不被数据量较大的大目标主导.MSP在特征层面能够保留更具表征目标信息的特征.而多尺度测试则通过不同尺寸的输入以牺牲速度的代价下提高精度.从VTP+MSP方法的实验的结果可以发现,对于安全帽数据集,VTP+MSP方法优于MSP方法而劣于VTP方法,在口罩数据集上,该结果相反,该结果是数据集本身的特点决定的,安全帽数据集相对于口罩数据集,所含有的小目标样本较少,因此,通过VTP数据增强能够获得更好的效果,而口罩数据集本身小目标样本较多,对于特征的操作则更有效.从该实验可以看出VTP+MSP方法更具鲁棒性. 本文针对在工业安监中出现的小目标问题,在YOLOv3上进行了改进,并通过实验验证了改进方法的有效性.在单尺度测试下,MSP+VTP方法能够提高算法对小目标的检测精度,并在不同数据集下具有较好的鲁棒性.在多尺度测试下,VTP+MST方法能够在较大程度上提高检测精度,但从表3、表4可以看出,采用MST的时间消耗为原来的2倍以上.而如何提高工业安监中遮挡目标检测的精度是下一个要研究的问题.

2 实验、结果及分析
2.1 实验


2.2 结果






2.3 分析
3 结 论
