基于深度学习的小样本声目标识别方法
2021-05-07王鹏程王彦博孔庆珊
王鹏程,崔 敏,李 剑,王彦博,赵 欣,孔庆珊
(1.中北大学 信息探测与处理山西省重点实验室,太原 030051;2.北方科技信息研究所,北京 100089; 3.山东省军区数据信息室,济南 250099)
0 引言
声目标分类是实现声源识别的主要方法[1],指的是将声信号数据与目标标签相关联,从而实现声信号到声源类别的识别。
声音信号识别的经典方法有高斯混合模型(GMMs, gaussian mixture model)[2],支持向量机(SVM, support vector machines)[3],隐马尔可夫模型(HMM, hidden Markov model)[4]等经典机器学习方法,由于采用手工设计特征并识别的方法,通常能取得非常准确的效果。但这些方法无法自动提取特征,在识别新信号时往往表现较差,仍然需要重新做算法开发,存在适用范围小、泛化能力差的问题。
深度学习近年来蓬勃发展,凭借其在计算机视觉[5]、自然语言[6]、生物信息学[7]等领域的独特优势,成为众多学者的研究热点[8-9],在文字[10],图像[11]和声音[7]等数据的解析方面有很大的应用价值,能够学习样本数据的内在规律和表示层次,解决了很多复杂的模式识别难题。
将其应用于声目标分类识别也取得了很好的效果。或是使用卷积神经网络技术(CNN, convolutional neural networks)直接从声谱图数据中识别特征[12],或是通过无监督学习技术根据数据间特征的相似性进行分组(聚类算法)[13],又或者将多种CNN网络融合后进行多时间分辨率分析和多级特征提取[14],这些声目标分类方法不需要人工提取特征,且识别精度可观。然而,由于模型参数量巨大,容易过拟合,这使得在处理低复杂度样本时会很困难。然而,在具体的声源识别应用中,往往缺乏大规模的训练数据,无法满足模型高样本复杂度的要求。
基于上述问题,本文提出了一种基于深度学习的小样本声目标识别方法,基于残差网络(ResNet, residual network)设计了声目标分类模型(MDF-ResNet, handmade design features ResNet)。模型采用了对数梅尔声谱图特征和手工设计特征分别对声音数据进行特征预提取,扩充模型可用特征量;通过ResNet网络结构对两种预提取特征进行深度提取和分类处理,提高特征利用率,最终实现声目标的准确分类。
1 小样本声目标识别方法
为完成小样本条件下的声信号准确分类,结合声信号处理中前端和后端的方法,从信号采集到信号识别做了一系列工作。首先,通过高灵敏度全指向性声传感器组成麦克风阵列,收集到不同声源发出的声信号,数据预处理之后,对声信号数据进行手工设计特征和Log-mel spectrogram提取,得到(人工特征数×帧数×通道数)形式的手工设计分类特征和(frequency,timesteps,channel)形式的Log-mel spectrogram特征。其次,基于ResNet网络构建适用于声信号数据的深度学习训练网络。以手工设计分类特征和声谱图为输入,声源类型为标签输出,建立声信号特征到声源类型的端到端深度学习模型MDF-ResNet。最后,对网络模型进行训练,通过实验测试模型性能。
2 声信号特征预提取方法
2.1 对数梅尔声谱图特征
声音数据是一种多通道的波形数据,转化为张量数据时体现为(timesteps,features)的二维时间序列信息, 如图1,但这只考虑到了声音的时域信息,未对其频域信息进行分析,因此需要对声音数据进行时频域分析,将数据转化为声谱图形式,得到包含声音时频域信息的声谱图,如图2,将其当做图像来处理,就可以在声谱图上训练深度卷积神经网络,利用卷积网络的特征提取能力对声信号进行特征提取。
图1 声音波形图
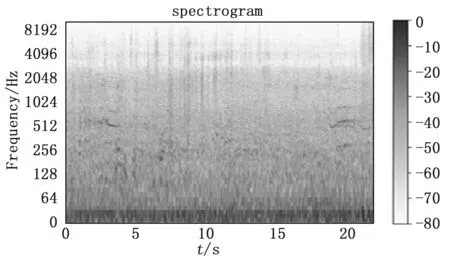
图2 对数梅尔声谱图
在声信号处理领域分析音频,往往从中提取一种称为梅尔倒谱系数(MFCC,Mel frequency cepstrum coefficient)的特征参数作为预提取特征[4],但在MFCC提取过程中会损失大量声音细节,深度学习兴起后,深度神经网络强大的特征提取能力使得我们只需要将信息更加丰富的对数梅尔声谱[15](如图2)信息直接送入神经网络进行训练,让神经网络提取更加鲁棒的特征。
从声信号数据中提取得到Log-mel声谱图的过程如图3所示。
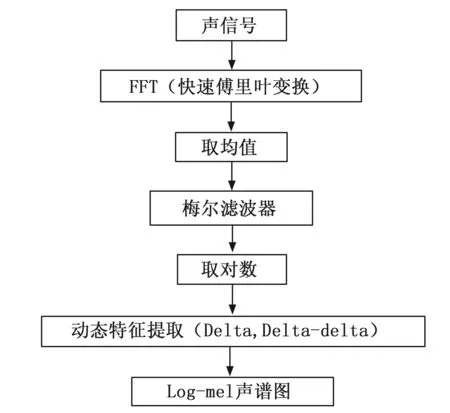
图3 对数梅尔声谱特征提取
2.2 手工设计特征
手工设计特征基于特征工程方法[16],即预先经过人工设计并从音频信号中提取的特征。手工设计特征偏重于对声音信号的整体认识如声高、音调以及沉默率,通过手工工设计特征从数据中得到有意义的数据特征,高质量的特征有助于提高模型整体的性能和准确性。特征在很大程度上与基本问题相关联,需要设计与场景、问题和领域相关的特征。
用音频分析开源软件Essentia的特征提取器Freesound对声音数据抽取手工特征,Essentia提供了用于TensorFlow深度学习模型的接口,便于嵌入深度学习中使用。首先对音频文件作分帧处理,将10 s的声音信号分为500帧,每一帧信号40 ms,相邻帧间有20 ms重叠。
然后进行Freesound特征提取:对于单通道内每一帧信号用Freesound特征提取(参数设置为默认值)抽取400个特征如表1所示。每个声音样本可得到(手工特征数×帧数×通道数)形式的Freesound手工设计声源分类特征。
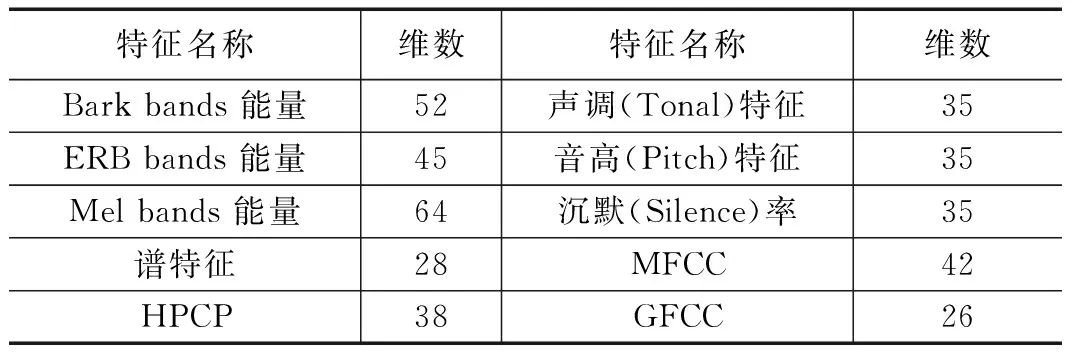
表1 Freesound特征提取器提取到的特征
3 声目标分类模型MDF-ResNet
3.1 卷积神经网络
卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一。卷积神经网络具有表征学习能力,能够按其阶层结构对输入信息进行平移不变分类。
由于孔子所处时代的影响,孔子提出的礼更加注重实践价值和可操作性。首先来说,礼是人伦关系的规定。孔子所制之礼以现实生活的内容为基,把周礼神秘的内容转为世俗性的,人伦性质的关系。周礼的主要内容都是关于祭祀的。“国之大事,在祀与戎。祀有执脂,戎有受服,神之大节也。”[4](《左传》成公十三年)之所以周人注重祭祀,并不仅仅是因为祭祀本身是一件神圣的事件,更为重要的是通过祭祀神圣连接主宰事物的神以说明统治的合法性。
卷积是一种线性运算。卷积网络是使用卷积运算代替矩阵乘法运算的神经网络。例如,它被定义为:
其中是输入nin矩阵的个数或者是张量的最后一个维度。Xk表示第k个输入矩阵。Wk表示卷积核的第k个子卷积核矩阵。S(i,j)对应位置的值是输出矩阵的元素对应于卷积内核W。对于卷积后的输出,通常用经过激活函数——整流线性单元Relu将输出张量中小于0的元素值整形为0值。通过卷积神经网络的不断堆叠,网络越来越深,不仅可以实现卷积网络强大的表征能力,而且随着网络深度增加,过拟合的问题也得到了改善。
3.2 ResNet分类网络
一般来说,通过不断堆叠网络层来加深、加宽神经网络,深度学习会有更强的表达能力,模型性能也会提高。但实验发现一味地增加网络层数并不能带来分类性能的进一步提高,而且参数量的不断增加会导致在小样本条件下,网络收敛变得更慢,分类准确率也变得更差。因此,本文采用了ResNet网络:
H(x)=F(x)+x
(1)
将求解x到H(x)的问题转化为求解两者之间差值F(x)的问题,这样网络内的信号可以直接通过捷径连接到更深的层,这样在网络末端仍保留大量有效特征,数据内的特征信号得到充分挖掘和利用,能够在深度增加的情况下维持强劲的准确率增长,这使得ResNet分类网络成为了当前应用最为广泛的CNN特征提取网络。
3.3 预训练网络
想要将深度学习应用于小样本数据集,一种常用且非常高效的方法是使用预训练网络。预训练网络(pretrained network)是已在大型数据集上训练好的模型,如果这个原始数据集足够大且足够通用,那么预训练网络学到的特征空间层次结构可以有效地作为声学分析的通用模型,因此这些特征可用于各种不同的声信号分类问题,即使这些新问题涉及的类别和原始任务完全不同。
DCASE声音场景与事件检测分类挑战赛中,任务A声学场景分类的数据集是一个可供声学分析的大型数据集,ResNet网络在该任务上取得了很好的效果,我们采用在该分类任务上训练好的ResNet网络来处理我们采集到的声数据。
采用了网络微调fine-tuning的方法使用预训练网络,仅保留网络的卷积部分用来做特征提取,将预训练网络的分类器部分丢掉,增加需要训练的新分类器。某个卷积层特征提取的通用性(以及可复用性)取决于该层在模型中的深度,模型中越深的层能够提取到越抽象的概念。由于新数据集与模型训练的原始数据集有着较大差异,所以只使用模型前一部分层来做特征提取,而更深的层则与新加的特征分类器一起训练。
3.4 声目标分类模型
基于ResNet网络设计了MDF-ResNet模型,结构如图4所示。
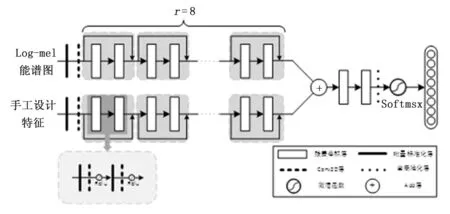
图4 神经网络模型示意图
MDF-ResNet模型包含36个卷积层,Log-mel能谱图特征与手工设计特征的两个分支上各有17个卷积层。这些卷积层的前后层分别是批量标准化层和采用了relu激活函数的激活层;其中,将批量标准化层scale和center参数设为False,起到了正则化的作用,防止模型过拟合,relu激活层对卷积层输出的结果进行非线性变化,修正网络中的线性输出。
两种特征分支结束后,通过Add层的add操作将两个分支的输出数据结合,结合后的特征经过一个分类器来对特征进行最后的分类。分类器由Conv2D层、批量标准化层、全局池化层和激活层组成,这里Conv2D层使用了1×1的卷积核大小,第二个Conv2D层的卷积核个数设置为声目标分类数量,再经过全局池化层展开成一维向量数据后,由采用了Softmax函数的激活层对每个通道的贡献进行加权,实现声目标的分类。
4 实验验证和结果分析
本实验所采用的硬件平台处理器为Intel (R) Core (TM) i7-7700@2.80 GHz,显卡为NVIDIA Tesla V100,使用了并行计算架构CUDA对深度学习处理流程进行加速。
4.1 数据准备
为了验证所提出的模型,本文中建立了一个声学信号硬件采集系统[17]来采集多个声源信号。采集系统由16位分辨率16输入数字采集设备SPECTRUM DN2.592-16、16个驻极体电容话筒Micw i436组成的球形阵列和定向扬声器组成,采集参数由笔记本电脑控制程序进行调整。我们采用48 kHz采样率采集了8个不同声源的声信号数据,每个声源包含1 000个样本,共8 000个样本数据集。每个样本持续10秒。
4.2 数据预处理
利用librosa包中的log-mel方法对声音数据作特征预提取,并使用二阶差分对预提取特征进行处理增加声信号动态信息。最终,经过预处理后得到数据集为(8 000,128,461,6)。使用2.2中方法对声音数据提取手工设计特征,得到数据大小为(8 000,500,400,2)。对8 000个样本对应的分类标签转换成one-hot编码的形式。数据集的训练集和测试集的划分比例为7∶3。
4.3 实验验证
在训练中,批处理量为32,损失函数使用交叉熵损失函数categorical_crossentropy,优化器使用随机梯度下降优化器SGD,epoch次数设为500次,使用学习率重置方法,在3、8、18、38、128和256次迭代后将学习率重置为最大值0.1,然后按照余弦函数方式衰减到0.000 01,这种方法可以提高分类的准确性。
为了对比验证MDF-ResNet模型的性能,使用了Densenet121,ResNet101和Inception v4这3种深度学习网络结构在log-mel声谱图上同样训练了500次迭代。
4.4 结果分析
图5、6中所示是MDF-ResNet,Densenet121,ResNet101和Inception v4对应的训练准确性和损失。表2详细列出了每个模型的性能,表中显示了模型在测试集上的分类表现。可以看出,MDF-ResNet首先达到收敛,可以将其损失降低到非常低,且最终达到的识别精度是最高的。
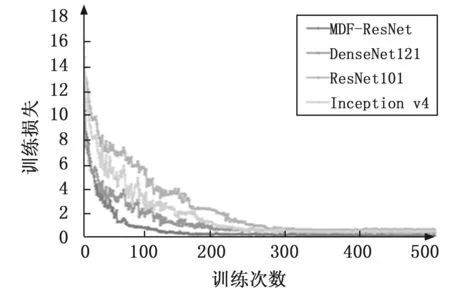
图5 训练损失值曲线图
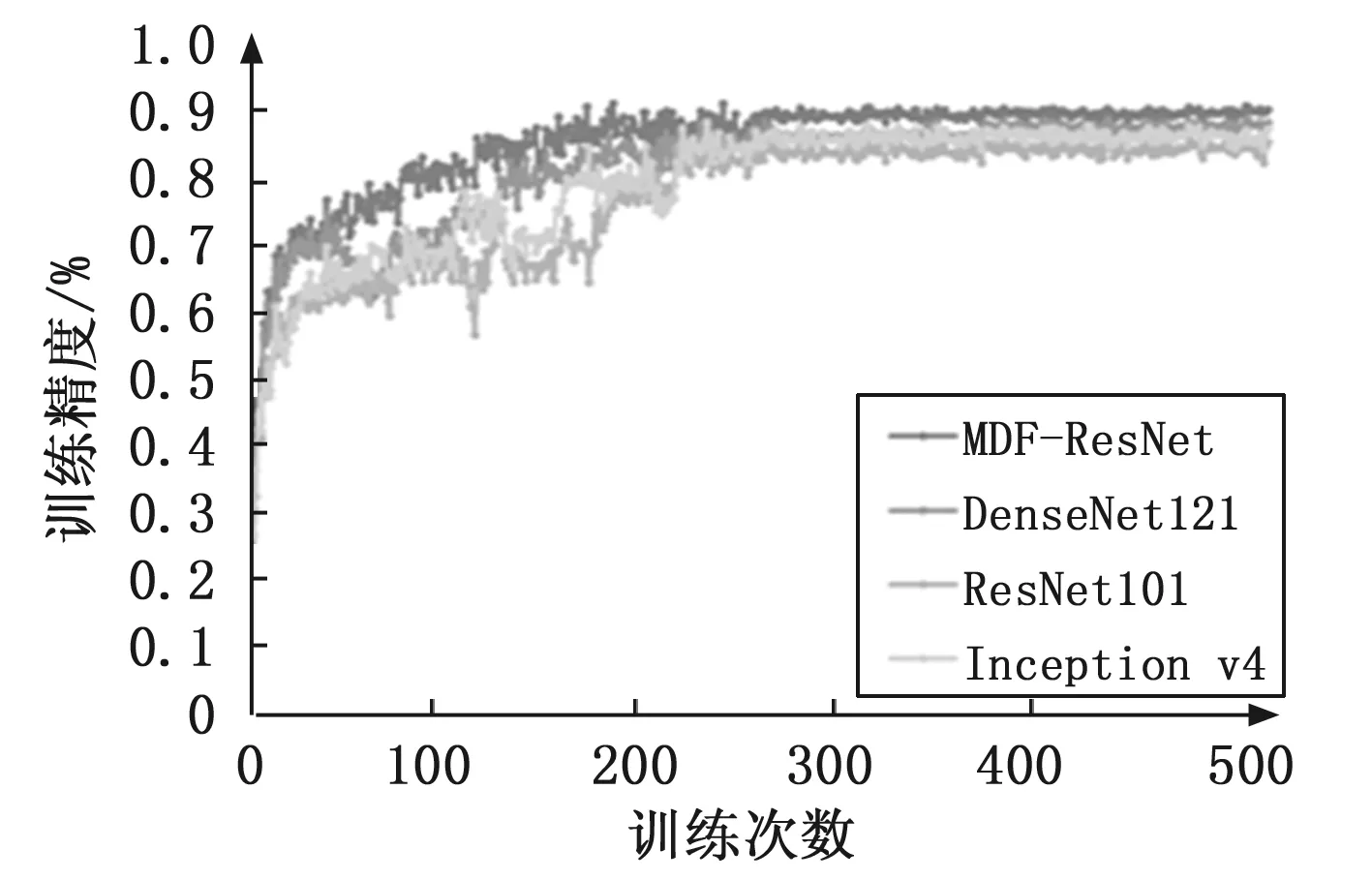
图6 训练精准度曲线图
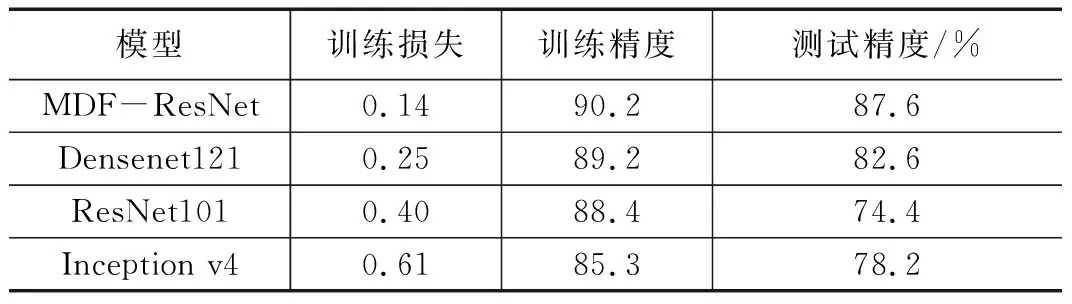
表2 各模型的训练情况和测试精度
最后,MDF-ResNet在测试集上的识别准确性为87.6%,如图7所示,横轴为网络预测结果,纵轴为真实标签,在各分类上的精度从81.82%~92.93%之间。这表明MDF-ResNet可以完成有效而准确的声信号分类和识别。

图7 训练损失值曲线图
为了研究不同训练数据量下的模型性能,本文从8 000个样本数据集中创建了1 000、1 500,…,4 500、5 000,…,7 500和8 000个训练样本的数据子集。在不同样本量上以同样的训练方式所训练的不同模型的精度如图8所示。
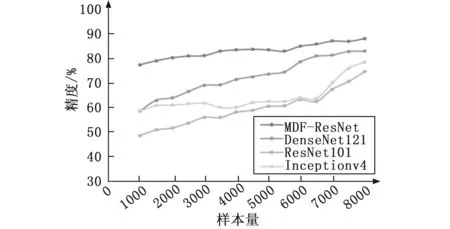
图8 不同数量训练样本上训练不同模型的对比实验
图8的结果表明,与其他几种模型相比,MDF-ResNet在每个数据子集中表现更好,并且在较小的样本数据子集中(例如1 000、2 000、3 000、4 000个样本)表现出更好的识别能力。手工设计特征的加入,使得该模型只需少量训练样本即可实现较高的识别精度。
5 结束语
本文针对声源目标分类中小样本训练时分类模型性能不佳的问题,提出了一种基于深度学习的小样本声目标识别方法——MDF-ResNet模型。该模型在log-mel声谱图特征提取之外,增加了手工设计特征作为模型的特征补充,提高了小样本数据的样本复杂性。该模型在搭建的声信号采集系统获取到的8种声源数据集上进行了实验验证,即使在少量训练样本上,MDF-ResNet仍然能够实现良好的识别精度。在处理声信号分类中样本复杂性低的问题时,MDF-ResNet在准确性上有显著的提高。在声源探测领域具有一定的工程应用价值。
该分类模型能够灵活胜任基于大型和小型数据库的训练任务。目前的模型结合了人工设计特征,可在样本复杂性低的情况下训练,降低了对样本量的要求。作为未来的工作,该算法还可推广到其它应用领域,如医学图像识别、人脸识别与人脸伪装、人脸匹配与视频、人脸速写与照片匹配等。
