基于颜色聚类的光学伪装效果评估背景选取方法
2021-05-06余松林陈玉华何鹄王吉军李岩
余松林, 陈玉华, 何鹄, 王吉军, 李岩
(1.军事科学院 国防工程研究院, 北京 100850; 2.32184部队, 北京 100093)
0 引言
在基于静态光学图像的伪装效果评估中,度量伪装目标与四周背景之间的相似性是一项重要内容[1],其中背景区域的选取对评估结果影响较大。目前常用的方法是选择目标区域的9倍范围[2](或称8邻域)作为评估的背景区域[3-5](见图1),通过计算、对比目标和背景区域的特征参数得到评估结果。但是,当目标处于反差较大的两种背景交界区域附近时,直接采用8邻域选取方法,将会导致评估结果出现较大偏差。以图2为例,选取的背景区域中,不仅包含了目标所处的植被区,而且包括了反差较大的道路,由于目标隐蔽于植被区域中,相应伪装措施模拟的是植被特征,而道路区域图像的灰度、色度和纹理等特征均与植被有显著差别,在计算时将该区域纳入计算范围,势必导致评价结果出现较大误差。
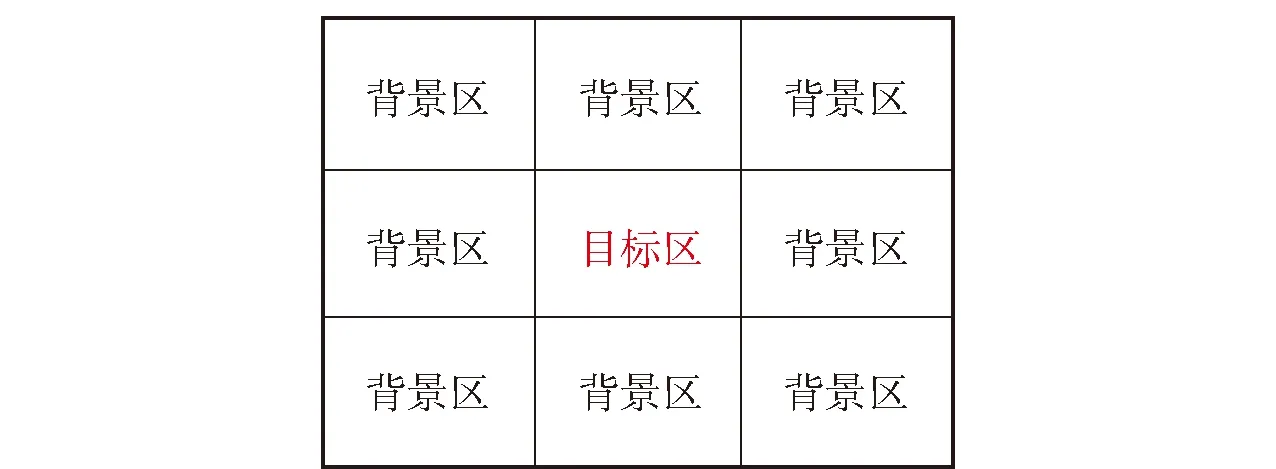
图1 背景选取方法(8邻域)Fig.1 Background selection method(8-neighborhood)
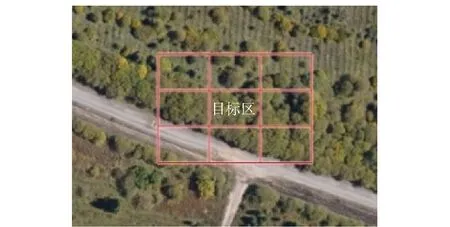
图2 交界区域附近的目标Fig.2 Target region near the background border
针对上述问题,目前常用的解决方法是人工剔除反差较大的部分背景邻域,或选用8邻域中1个或多个不包含大反差背景的邻域区计算,但这样处理需要人工介入且主观性强,无法满足自动化伪装评价的需要。由于颜色是可见光图像最显著的特征之一[6],本文提出一种基于颜色聚类的背景选取方法,实验结果表明,该方法可以有效去除无关的背景区域,提高伪装效果评价的客观性和准确性。
1 总体思路与计算流程
对基于光学图像的伪装效果评估而言,目标的伪装效果取决于目标区和背景区在图像特征上的差别,当这种差别达到一定程度时,目标就可以从背景区中被分离出来[7]。而目标与周边近邻区域的特征差别,是决定目标伪装效果的关键。因此,本文以目标近邻区域特征为样本,通过颜色聚类法选取背景中与近邻区域包含相同聚类颜色的区域,作为伪装效果评价计算时的背景区域,在实现背景区域自动选择的同时,还可提高其合理性和客观性。
算法流程如图3所示,首先对目标区域进行一定像素的扩展获取近邻区,然后对目标8邻域图像进行颜色聚类,统计近邻区包含的聚类颜色数量,并在8邻域中淘汰掉近邻区中不包含的颜色区域,对剩下的部分进行孔隙填充和区域分割等形态学处理,即可得到最终选择的背景区,最后根据选取区域在8邻域图像中的面积占比,判断该算法是否有效。

图3 算法流程图Fig.3 Algorithm flowchart
2 典型算例与主要算法原理
2.1 典型算例
根据第1节的算法流程,以图2为例,在其中靠近道路的位置选取一定面积的区域作为目标区,设置颜色聚类中心数量K=6、淘汰阈值T=0.05、填充半径r=D/20(D为目标直径,是指目标区外接矩形的长边像素值),关键步骤的计算结果如图4所示。
2.2 提取目标近邻区
在评价单个目标伪装效果时,伪装目标与背景融合的程度,主要取决于目标区域与目标周边近邻区域的特征相似程度。基于这一考虑,将目标近邻一定范围的区域提取出来,作为下一步计算其他部位是否纳入背景区域的基准,如图5所示。具体实现方法是采用方形结构元素对目标区域图像蒙版进行膨胀[8-9],结构元素的边长根据目标大小确定,本文采用的近邻扩展宽度像素值p为目标直径D的1/10.

图4 典型算例关键步骤结果图Fig.4 Results of key steps of typical case
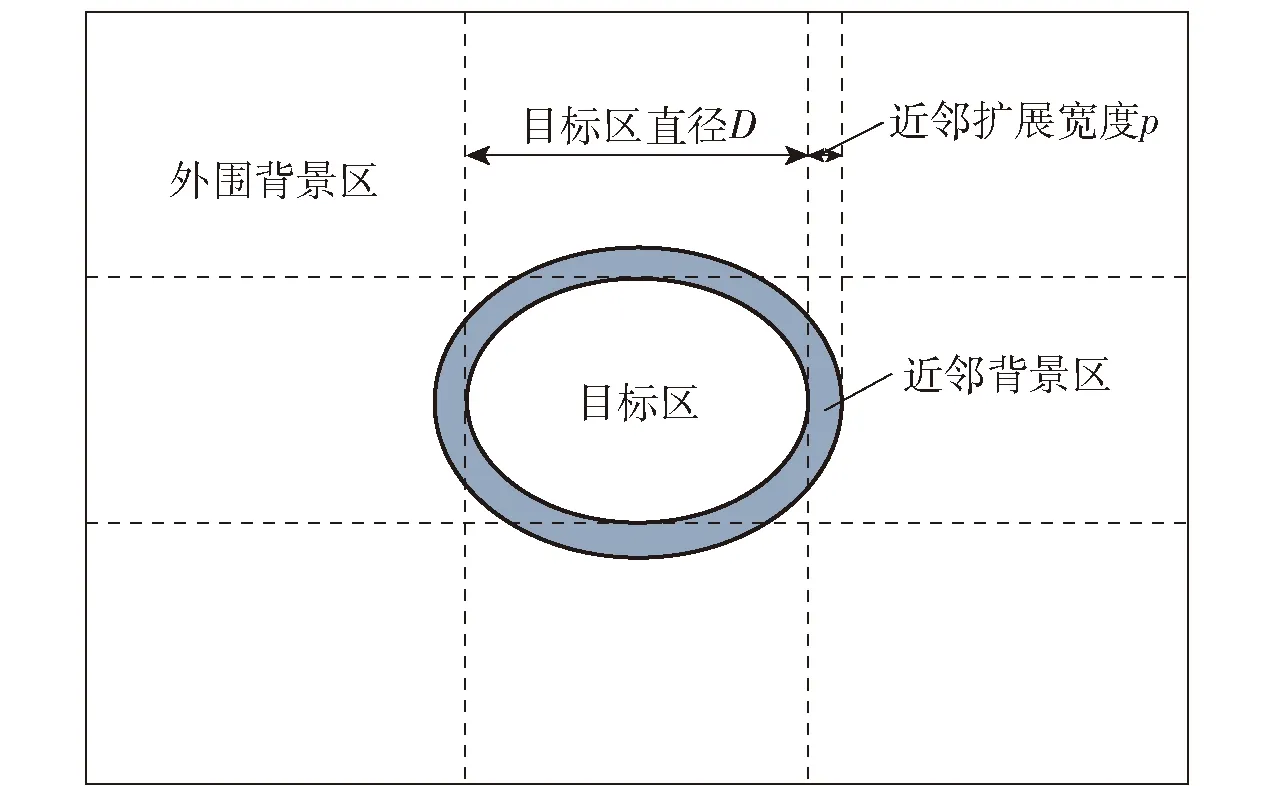
图5 目标近邻背景区示意图Fig.5 Schematic diagram of adjacent region
2.3 目标8邻域图像颜色聚类
考虑到本文的目的是将综合特征反差较大的大片背景区域从目标8邻域范围内排除,为便于识别反差较大区域,利用可见光图像中颜色特征识别度较高的特点,采用K均值聚类方法,对目标及其8邻域图像进行颜色聚类。
K均值聚类方法[10-13]是图像处理领域应用最广泛最成熟的聚类分析算法之一,具有快速、直观、易于实现等优点。其基本思想是从含有大量数据对象的数据集中随机选择K个数据对象作为初始聚类中心,计算每个数据对象与K个聚类中心的距离,将所有数据对象划分到与它距离最近的聚类中心代表的类中,根据新生成的各类数据对象的均值更新K个聚类中心。若相邻迭代次数内聚类中心值的变化超过规定的阈值,则根据新的聚类中心对所有数据对象进行重新划分;若相邻迭代次数内聚类中心值的变化小于规定的阈值,则算法收敛,输出聚类结果。
颜色聚类的计算结果如图4(d)所示。聚类中心数量K是影响背景区域选取效果的重要因素,后文将讨论不同K值对背景选取效果的影响规律。
2.4 淘汰近邻区含量较少的颜色区域
以近邻区中聚类颜色的含量为依据,对整个背景区域进行筛选与淘汰。具体步骤如下:
1)统计目标近邻区中聚类中心颜色的数量以及每种颜色的占比。为排除孤立像素点颜色突变对总体结果造成影响,本文设置了淘汰阈值T,分别计算近邻区中每种颜色所占的比例,将占比低于淘汰阈值T的聚类颜色,也视作近邻区中不包含的颜色。后文计算中设置淘汰阈值T=0.05.
2)在目标8邻域图像中,去除近邻区中不包含的颜色区域,得到聚类淘汰后的图像蒙版。计算结果如图4(e)所示。
2.5 形态学处理
对聚类淘汰后的图像蒙版进行形态学图像处理,得到最终选取的背景区。具体分以下两个步骤:
1)孔隙填充。聚类淘汰后的图像蒙版可能存在许多斑点和孔隙,反映的是背景中存在的斑驳颜色区域,对于较小面积的孔隙,不应视作需要排除的部分。因此,采用半径为r的圆形结构元素对图像进行闭运算[8-9]以填充孔隙,r的大小取决于希望得到背景区域的精细化程度。计算结果如图4(f)所示。
2)连通区域选择。孔隙填充后的蒙版图像中,可能含有多个连通区域,需要将包含目标的区域选取出来。为此,统计连通区域数量,并根据目标近邻区所处的位置判断需要选取的连通区域,在其中减去目标区域,即可得到最终选取的背景区,如图4(g)和图4(h)所示。
2.6 有效性验证
计算最终选取的背景区域面积在整个8邻域图像除目标区以外的面积中的占比R,如果R小于某一阈值L,则可认为目标、背景区域边界线和外围背景区域符合图6所示的孤岛状分布,此种情况下可将目标、近邻区及与近邻区相似的背景区整体视为新的目标,从而导致算法失效,应适当增大近邻区扩展像素并再次计算。后文计算中设置有效性阈值L=0.5.

图6 孤岛状分布位置关系示意图Fig.6 Island distribution of target and background
3 实验设计与结果分析
为验证本文方法对背景选取效果的改进作用和适用范围,并研究相关参数对背景选取结果的影响,设计以下4组实验。实验中目标区域的选取方法是用鼠标逐点描绘,故对轮廓细节的选取可能存在一定误差,但各组对同一个目标计算不同参数时,所使用的目标区域是相同的。
3.1 背景选取方法改进效果对比
亮度对比是伪装评价中常用的指标之一,将可见光图像灰度值近似为亮度值,在一幅典型图像中选取目标区域,分别按照本文方法与一般8邻域方法选取背景,采用(1)式计算目标区域与背景区域的平均灰度对比[14],比较两种方法得到结果的差别。
(1)
式中:Kg为平均灰度对比;Gt、Gb分别为目标区域和背景区域的平均灰度值。
以图4中的背景与目标图像为例,在计算目标区域的平均灰度Gt、采用本文方法选取的背景区平均灰度Gbs、一般8邻域方法选取的背景区平均灰度Gbn基础上,分别按照(1)式计算灰度对比Kgs与Kgn,计算结果如表1所示。

表1 2种背景选取方法灰度对比计算结果Tab.1 Gray contrast calculations of two backgroundselection methods
从表1中可以看出,两种背景选取方法计算的平均灰度值相差较大,由于本文方法剔除了与目标近邻背景相差较大的道路区域,计算出的平均灰度对比Kgs更能反映目标与周围背景区域的平均灰度差别。
3.2 目标位置的适用性验证
在实际应用中,目标位置与背景区域边界线的距离关系并不固定,为验证本文算法在各种情况下的适用性,将目标轮廓线与背景区域边界线的关系分为远离、临近、重合、交叉和孤岛5种情况进行计算,各种情况位置描述如图7和表2所示。图7中,d为目标轮廓线与背景区域边界线的最小距离(二者不相交时),如边界线从目标区域内部穿过,则d<0.

图7 目标与背景区域边界线位置关系示意图Fig.7 Schematic diagram of location relation between target and background boundary line
选用一张具备不同典型背景区域的图片,在其中按照一定规则选取目标区域的位置,使目标轮廓线与背景区域边界线分别满足上述5种位置关系,计算得到各种条件下的背景区域选取结果如表3所示。从表3中可以看出,当位置关系为远离时,目标8邻域图像中不包含大反差背景,选取范围为除目标区以外的整个8邻域,R=1;当位置关系为临近时,由于近邻区域不包含边界,对8邻域中差异较大的背景区域进行了剔除;当位置关系为重合时,目标处于林地区域,其近邻区包含一部分草地,在选取背景时未能将草地排除,降低了最终选取背景的准确性,但仍能够将公路及对侧的区域排除;当位置关系为交叉时,近邻区中包含了多类背景(公路、路边的草地和树林),在进行聚类淘汰时,无法淘汰任何一类背景,因此最终选取的背景区域仍是除目标外的整个8邻域,R=1;当位置关系为孤岛时R=0.35,认为与近邻背景相似的区域在8邻域中面积占比较小,即使目标与近邻区域融合较好,也可能因为近邻区域与外围背景显著的特征差异,导致将整个近邻区域视为新的目标而影响伪装效果。

表2 目标位置关系及特征Tab.2 Location relations between target and background boundary line
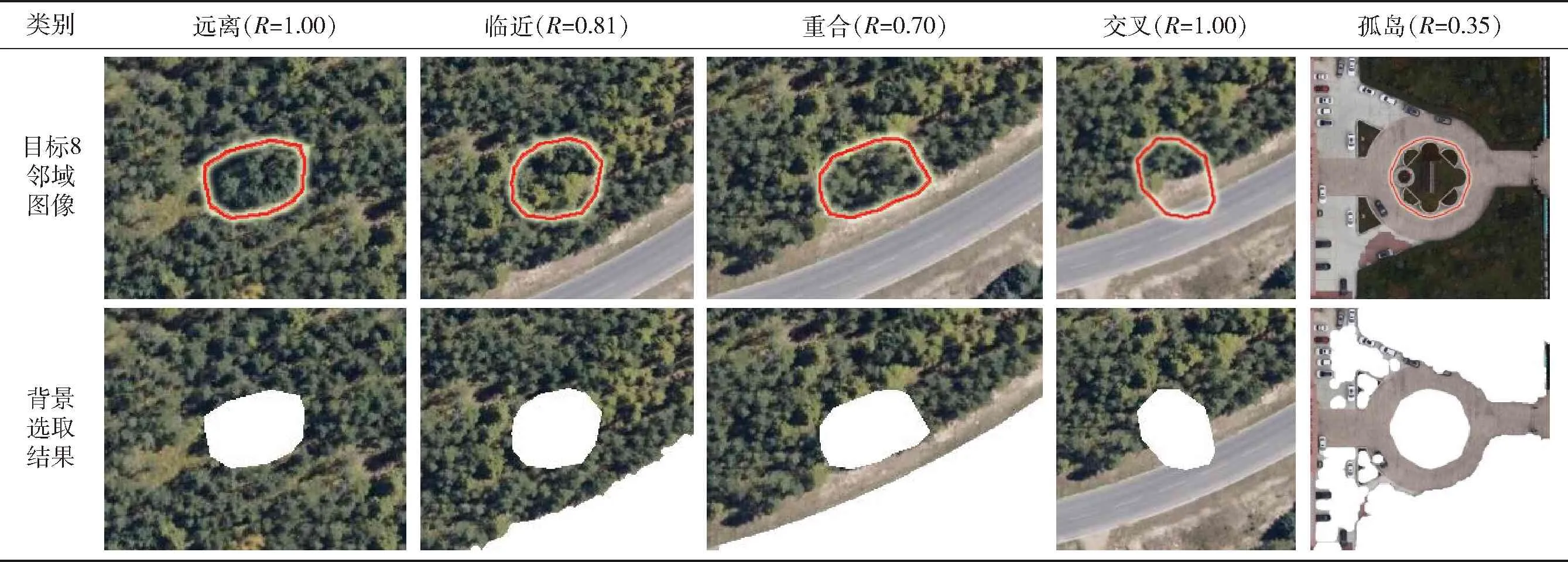
表3 目标与背景区域边界线不同位置关系(红线为目标轮廓)
由此可见,目标与背景区域边界形成不同位置关系时,均能较好地改进背景选取效果,只有在重合状态下未达到预期效果,但仍有一定的改进作用。考虑到实际情况下目标轮廓与背景区域边界线重合的几率较低,可以认为本文方法对不同目标位置的适用性较强。
根据上述实验结果,可将本文方法进一步推广到地面伪装效果检测,当目标8邻域图像中包含天空背景时,只要目标轮廓与天空背景区的距离大于近邻扩展宽度,即可有效排除天空背景。
3.3 颜色聚类中心数量对背景选取效果的影响
选择颜色类型和分布相差较大的2张图片(城镇区和植被区),在其他参数保持不变的情况下(p=D/10,T=0.05,r=D/20),分别设置聚类中心数量K为4、6、8、12、16,计算得到5种情况下的背景区域选取结果(见图8和图9),并绘制R值随K值变化的曲线(见图10)。

图8 不同颜色聚类中心数量的背景选取结果(城镇)Fig.8 Background selection with different number of cluster centers(urban area)

图9 不同颜色聚类中心数量的背景选取结果(林地)Fig.9 Background selection with different number of cluster centers(vegetation area)
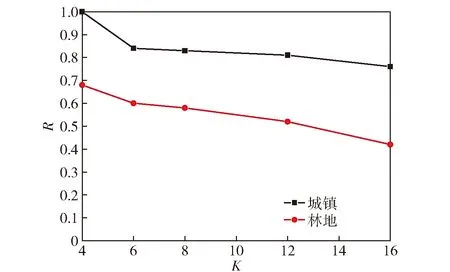
图10 R随K值变化Fig.10 R vs. K
从图8~图10中可以看出,当聚类中心数量增大时,近邻区中不包含的聚类中心颜色越来越多,选取结果中呈现的空白区域也逐渐增加,选取区域占比R逐渐降低。在城镇区域图像中,颜色种类相对较多,且相互之间的差别较明显,近邻区的颜色比较杂,适当地增大K值可以提高选取区域的准确性。而植被区域图像中,除道路和建筑物外,植被区域颜色差别较小,层次分布不明显,K值增大将导致植被区域也被不同程度地剔除,降低背景选取的准确性。由于本文算法的目的是剔除与近邻区差异较大的背景,K值不宜过大,一般取4~6即可,在实际应用中,应结合背景区域颜色分布层次灵活选取。
此外,在局部区域还出现了随K值增大、选取结果出现反转的情况,如图9(d)和图9(e)中左侧部分,这是因为K均值聚类方法选取的聚类中心颜色存在一定随机性导致的,但是对整体结果的影响不大。
3.4 孔隙填充半径r对选取结果的影响
为较好地展示孔隙填充半径r的作用效果,选取一张包含不同尺寸的颜色区域图像,在其他参数保持不变的情况下(p=D/10,T=0.05,K=6),分别设置闭运算孔隙填充半径为D/40、D/30、D/20、D/10、D/6和D/4,计算得到背景区域选取结果如图11所示。
其中,图11(a)为目标与8邻域背景图,图11(b)为采用本文算法进行聚类淘汰后的结果,图11(c)~图11(h)为r取不同值时的计算结果。从图11中可以看出,r取值越小,选取的区域边界与图11(b)越接近,但对小尺度孔隙填充效果较差;r取值越大,对小尺度孔隙填充的效果越好,但是区域边界准确度较差,甚至会出现差异较大的背景区被选取的情况。从本文涉及的多个算例来看,当r=D/20时获得的结果相对较好。

图11 不同半径的结构元素闭运算结果Fig.11 Results of closed operation of structural elements with different radii
4 结论
本文根据单个目标光学伪装效果评估原理,提出基于颜色聚类的背景区域选取方法,并开展了实验分析。得到以下主要结论:
1)采用基于颜色聚类的方法,选取8邻域内与目标近邻区域特征相似的区域,作为目标伪装效果评估的背景,可以有效去除无关的背景区域,提高伪装效果评估的客观性。
2)将目标与背景区域边界的位置关系分为远离、临近、重合、交叉和孤岛5种,通过典型图片验证各种位置情况下的背景选取效果,证明本文方法对不同目标位置的适用性较强。
3)颜色聚类中心数量K对背景选取结果影响较大,一般取4~6为宜,实际应用中,应结合背景区域颜色分布层次的数量灵活选取。
4)闭运算结构元素半径r影响背景图像的孔隙填充效果,一般情况下,当r取值为目标直径D的1/20时,可获得比较理想的填充效果。
本文提出的背景选择方法模型中,部分参数需要根据背景类型选择不同取值,才能达到较好效果。下一步在具备一定数据积累后,可根据不同尺度目标,研究自适应邻域选取方法[15]并构建模型,针对不同背景类型进行大量数据样本训练,以进一步优选参数、减少人工干预。
