文本智能计算研究的主题挖掘与演化分析*
2021-04-29胡吉明田沛霖
胡吉明 田沛霖
(1.武汉大学信息管理学院 武汉 430072;2.武汉大学信息检索与知识挖掘研究所 武汉 430072)
0 引 言
文本智能计算是依托于人工智能、自然语言处理等大数据管理和分析技术,所形成的体系化的智能计算解决方案[1],是文本处理领域的全新计算模式,囊括了信息分析、自然语言处理、深度学习等领域的大量技术创新,能够揭示大规模非结构化文本数据的语义内涵,从而为决策提供智力支持。传统情报学文本计算方法已无法满足大数据时代下不断提升的文本处理需求,以及智能计算方法的不断发展,促使文本智能计算成为当前文本处理研究的重要方向与热点课题。
1958年Luhn将词频统计与句子显著性因子计算的方法应用于自动摘要生成[2],开创了文本智能计算研究的先河。1991年Dubois研究了基于模糊集的近似推理语义方法[3],进一步推动了文本智能计算研究的发展,自此之后研究规模开始发展壮大。近年来国际学者从多种细分领域对其进行研究,取得了丰富的成果,并广泛涉及社会诸领域,为舆情分析、情感计算、迁移学习、金融市场等领域提供了技术支持[4-7]。
在对文本智能计算及其子领域研究进展与发展态势的研究中,一方面,部分学者采用内容分析等定性分析方法,指出当前面向技术路径识别的文本挖掘方法主要有语义增强、文本聚类等,未来会加强面向多源数据的多元关系融合研究[8];基于图神经网络的方法在文本特征提取中将会愈发受追捧[9];基于神经网络的分布表示方法是未来文本相似度计算领域最为重要的研究方向[10]。另一方面,少数学者采用共词网络分析等定量分析方法,对领域文献进行发文量、关键词、合著关系等指标的统计,从而识别领域的研究热点、现状及未来方向[11]。
上述研究对文本智能计算及其子领域的研究现状、主题分布及发展趋势进行了揭示,但所涉及的多为部分子领域,缺乏对文本智能计算整体研究结构及关联关系的描述;同时缺少定量分析,特别是基于计量学基础的演化脉络梳理与发展趋势分析。基于上述情况,本文在前人研究的基础上,对文本智能计算研究的相关文献进行关键词抽取,通过计算词共现关系,以识别文本智能计算研究的主题分布,并揭示整体研究结构与子领域研究结构的特征与差异;在对词共现网络和演化脉络进行可视化分析的同时,基于多元指标计算,对其研究的发展态势进行预测,从而全面系统地揭示文本智能计算研究的主题结构与演化态势,为国家、科研院所与学者把握研究动态提供智力支持。
1 主题网络提取与分析方法
共同出现在同一文献中的一对关键词被视为具有共现关系,共现强度等于包含这对关键词的文献数量[12]。共现强度越大,两个词之间的内涵关联性越强,在主题上的一致性越好,对大规模学科关键词共现的关联网络计算[13]则能够反映研究主题的结构和演变规律[14-17]。共现分析已成为学科研究现状描述及发展趋势预测的重要定量分析方法[18]。由此,本文以文本智能计算研究文献的关键词为数据处理与分析依据,在关键词共现网络分析的基础上进行主题结构揭示、演化脉络梳理与发展态势分析,并进行可视化展示。
1.1文献数据收集与处理为获取学科最前沿、最全面的研究动态,本文从国际视角展开研究,以WOS核心合集(含SCIE、SSCI、A&HCI、CPCI数据库)为数据源,以“text AND intelligen* AND (comput* OR calculat*)”为检索词在主题字段进行检索,检索时间范围为2000年1月1日至2020年12月31日。检索结果经人工筛选,去除与主题不相关的文献,共得到1 483篇文献,下载其题录数据作为词频统计与词共现分析的基础数据集。文本智能计算研究的历年发文及关键词数量(多次出现的关键词不重复计)统计情况如图1所示,可以发现其研究过程经历了相当长的平稳期,自2011年起,文献数量呈显著增长趋势,2015年和2019年的增长情况最为突出;关键词数量总体呈增长趋势,说明文本智能计算的研究内涵在逐步扩大。
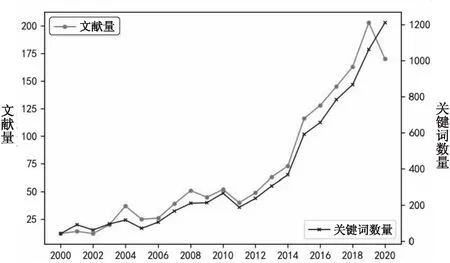
图1 2000-2020年文本智能计算研究的发文及关键词数量演化图
本文使用文献题录信息统计分析工具SATI[19]对文献进行关键词抽取与词频统计,根据频次占比情况,结合普赖斯指数[20]、G指数[21],从关键词中筛选出词频大于等于5的关键词作为代表文本智能计算研究的重点内容,以支撑后续的共词网络分析。考虑到关键词存在不规范、不统一等问题且具有上下位关系,本文首先进行同义词合并(如Natural Language Processing和NLP等),删除主题词(Text、Intelligent Computing)、概念宽泛的词(如Processing、Speech等);其次将词频小于5的关键词合并至其高频上位词中(如将Special education、Medical education、Elementary education合并至Education等),最终确定127个关键词作为文本智能计算研究的主流关键词,使用SATI构建其共现矩阵并导入Ucinet[22]中,生成关键词共现网络文件以供后续分析。
此外,采用Citespace[23]对文献进行突发关键词检测,并根据各年份主题的重合关系,实现研究主题随时间演进的演化过程可视化,分析主题延续、突现、融合、分化等发展过程,从而把握文本智能计算研究的主题随年代的变化情况[24]。
1.2主题关联数据提取与关联网络分析方法本文以文本智能计算研究文献为分析单位,进行关键词共现相关数据计算与关联网络构建,对关键词共现网络进行格式化处理。网络中,节点代表关键词,其大小代表关键词词频;边代表连接的两节点存在共现关系,其粗细代表共现次数。对上述127个关键词形成的共词网络进行最大连通子图提取,以表示文本智能计算研究的主流。具体分析方法如下:
首先对共词网络的整体和局部特征进行计算与分析。包括共词网络的密度、各中心势、各中心度和聚集系数等指标。其中网络密度表征了关键词间关联程度与领域发展程度[25],密度越大则词间关联越强,学科越成熟;中心势和中心度揭示了网络的集中程度、网络中信息通达程度与词间依赖程度[26];聚类系数表明了学科领域研究的聚集程度[27]。
其次对共词网络的社区进行划分。采用多级Louvain算法[28]划分共词网络社区,使社区内部节点联系紧密,不同社区间节点联系疏松,从而产生区别鲜明的主题社区。主题社区内部节点紧密联系的特征表征了这些关键词在研究方向上的同质性,从而可将各主题社区视作文本智能计算研究的各子领域。
最后对结果进行可视化。使用Gephi[29]对整体网络及各主题社区进行可视化,以直观展示文本智能计算研究的主题关联特征,辨析各主题社区研究地位;结合各主题社区的密度与平均中心度,可将社区映射至战略图[30],以此对各子领域的发展态势进行预测分析。
2 文本智能计算研究的主题关联结构与演化发展态势
2.1主题分布本文从所采集的文献数据中共提取出3 952个唯一的关键词,总频次为6 876。进行频次累计比例计算后发现,频次Top100的关键词频次总和占总频次的31.4%,覆盖了当前文本智能计算研究的绝大部分,具有统计学上的代表性。这表明文本智能计算研究的词频分布不均衡,总体呈现幂律分布,即少数关键词占据绝大多数词频,说明研究的倾向性明显[31],主要集中于少数主题,如图2所示。
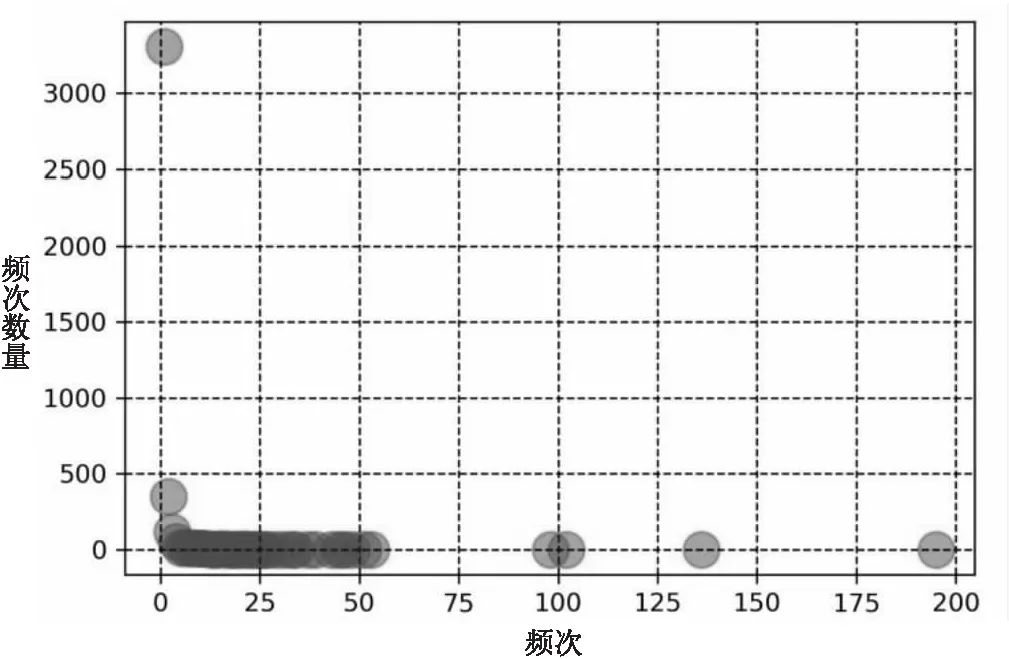
图2 文本智能计算研究的词频幂律分布
表1列出了词频排序前50的关键词,是2000-2020年文本智能计算研究的重要主题,内涵广泛且重点突出,如人工智能、自然语言处理、机器学习、文本挖掘、信息检索、本体论、教育等。

表1 文本智能计算研究的主题分布(前50)
根据图3所示的突发词检测结果,2000年起文本智能计算研究的新兴主题不断涌现,尤其是2014、2016和2018年,是三次技术的爆发期。2014年的新兴研究重点主题为智能导学系统、计算智能等;2016年的新兴研究重点主题为主题模型、智能字符识别等;2018年的新兴研究重点主题为知识发现、遗传算法和深度学习,且这三个主题一直延续至2020年,很可能会在接下来的几年中保持一定的热度。

图3 2000-2020年研究的突发词及其强度
2.2主题关联网络分析计算发现,本文选取的127个关键词组成的共词网络为最大连通子图,代表了文本智能计算研究的热点。计算其网络指标并识别社区关联结构,可以展示出研究的主题方向,并对其发展态势作出预测。
2.2.1 整体网络分析 整体网络指标如表2所示,整体共词网络的中心势较高,具体表现为:较高的点度中心势表明文本智能计算研究的向心力较大,形成了部分核心主题且其对整体研究的把控与影响能力较强;较高的接近中心势表明网络中各关键词间路径较短,信息通达度较好,核心主题对边缘主题可以产生直接影响;中介中心势较低,表明网络中多数关键词可以直接关联,而不需中介关键词作为共现的“桥梁”。结合较高的聚类系数,表明文本智能计算研究主题具有明显的内聚性与差异性,子领域内部一致性较强而各子领域间区别鲜明。此外,网络密度较低,说明学科正处于发展过程中,尚未完全成熟。

表2 整体关联网络指标
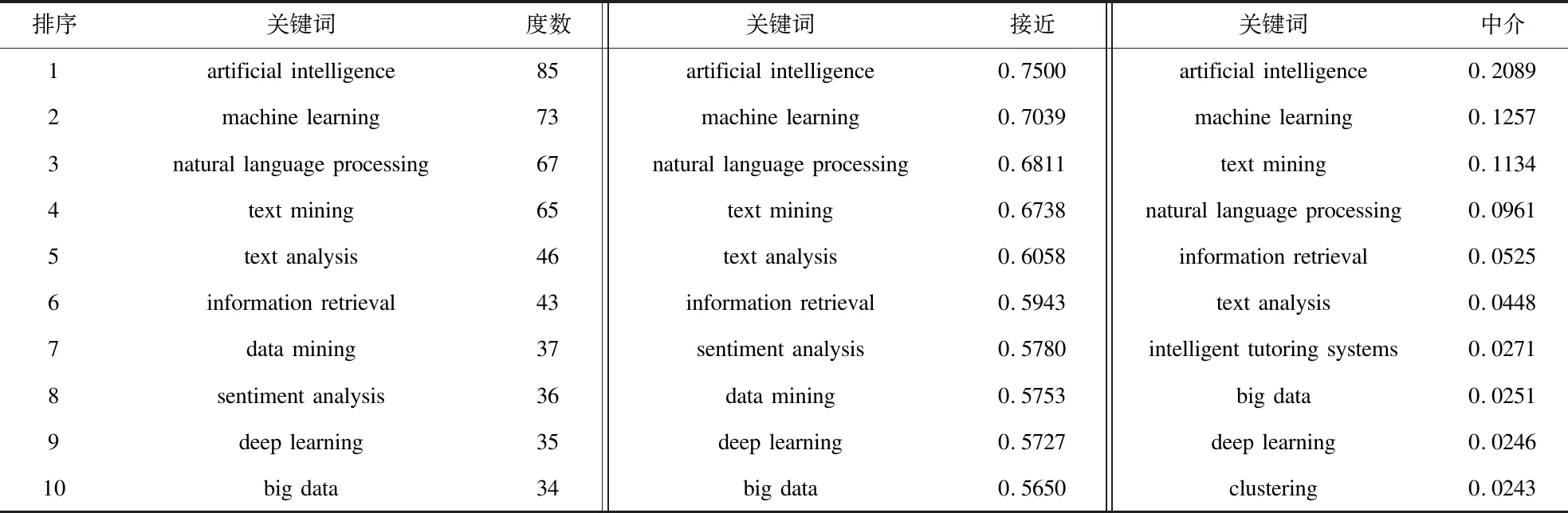
表3 关键词各中心度排序(前10位)
网络中各关键词的中心度排序如表3所示。人工智能、机器学习、自然语言处理、文本挖掘、文本分析、信息检索、数据挖掘、情感分析、深度学习、大数据主题的点度中心度和接近中心度都排在前10位,说明这些关键词代表的研究方向是文本智能计算研究的核心主题,研究集群的建立主要以这些方向为依据。此外,与中介中心势类似,各关键词的中介中心度普遍处于较低水平,说明当前的各研究主题间存在较紧密的关联。
2.2.2 主题社区分析 根据关键词间的关联关系及其强度,可将当前文本智能计算的研究划分为5个主题社区,具体研究内容如表4所示。各主题研究规模各异,分层现象鲜明。其中规模较大的社区有:C3-信息检索,包含本体论、算法、信息抽取、语义网、知识库等主题;C4-文本挖掘,包括教育、智能导学系统、社会媒体、计量学、虚拟现实等主题;规模一般的社区有:C1-人工智能,包含自然语言处理、深度学习、会话代理、认知计算、医学信息学等主题;C5-文本分析,包含多媒体、主题建模、验证码、知识图谱、图像分割等主题;规模较小的主题有C2-数据挖掘,包含情感识别、情感分析、情感计算、商务智能、交互等。各社区的研究主题各异,但都是文本智能计算范畴内的研究方向,可以代表当前国际研究的主流。
为探究各主题社区间的交叉协同影响情况,将主题社区间的关联关系可视化,如图4所示。C1-人工智能与其他四个主题社区间关联均非常紧密,表明信息检索、文本分析、文本挖掘与数据挖掘的研究离不开人工智能技术的支持,人工智能在文本智能计算领域的运用已成共识。C4-文本挖掘、C2-数据挖掘和C3-信息检索三个主题社区间关联也较为紧密,表明文本挖掘与数据挖掘具有较大的同质性,且二者在信息检索领域的应用广泛[32]。此外,C5-文本分析除了与C1-人工智能有较紧密的关联外,与其他三个社区关联疏松,此社区虽然所含主题较少,但其研究建立在文本挖掘与人工智能之上[33],具有较大的发展潜力。

表4 文本智能计算研究的主题社区
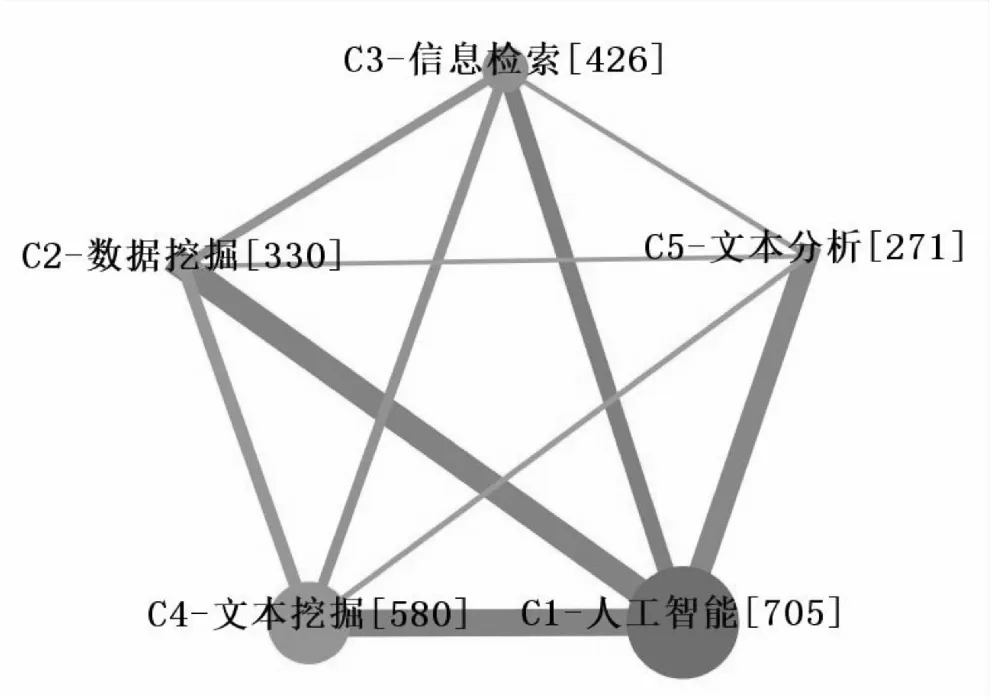
图4 文本智能计算研究的主题社区关联图
通过表5和图5对各主题社区的可视化与指标计算发现,C1-人工智能和C2-数据挖掘两主题社区平均度数中心度与密度最大,且二者关联最为紧密,说明其处于文本智能计算研究的核心地位,且发展较为成熟,已形成了系统化的研究结构;C5-文本分析虽然规模一般,但内部主题关联较为紧密,其研究有形成体系化的趋势;C3-信息检索和C4-文本挖掘两社区虽然规模最大,但内部主题间关联程度松散,平均度数中心度也较低,表明其研究结构尚不明显,发展水平有待提高。

表5 各主题社区网络指标
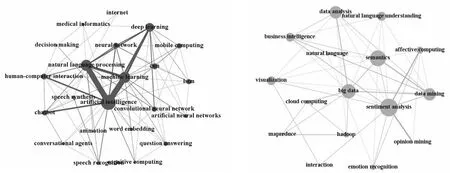
C1-人工智能 C2-数据挖掘

C3-信息检索 C4-文本挖掘
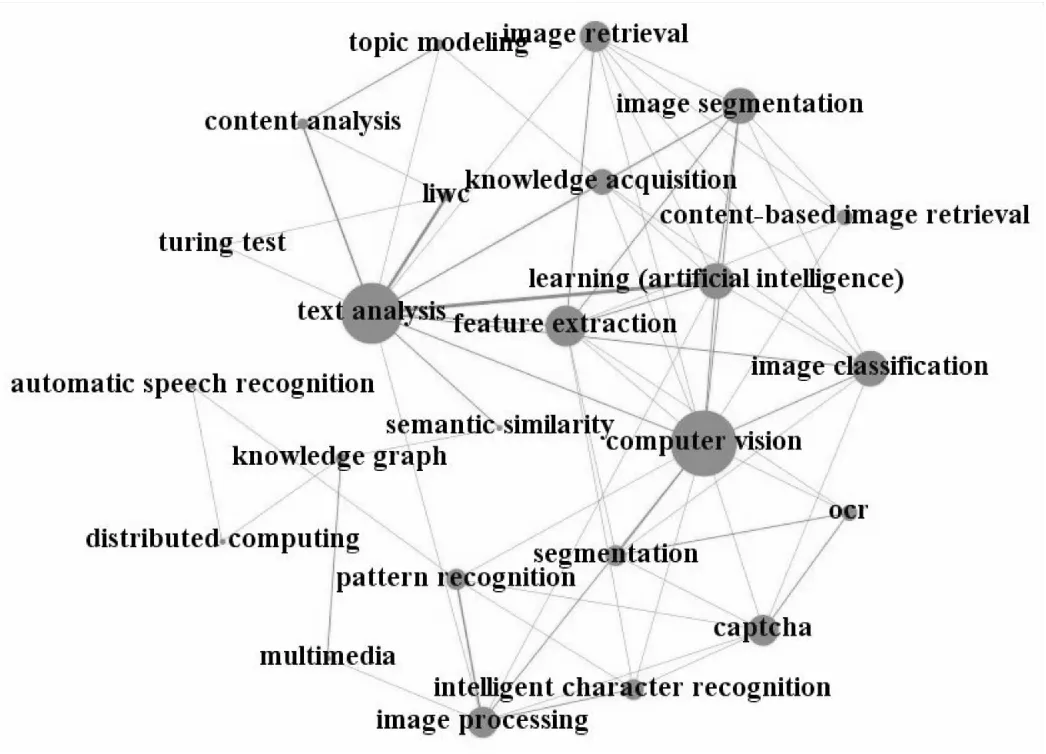
C5-文本分析
2.3主题演化与发展态势分析为探究文本智能计算研究主题随时间演化的情况,本文将文献数据以两年为单位进行切片,将主题演化脉络进行可视化展示,并依据战略图分析各主题社区的发展态势。
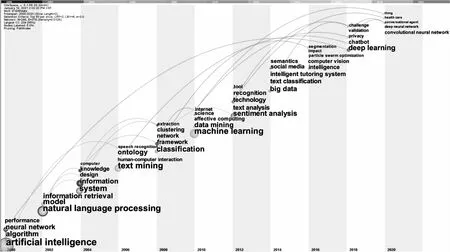
图6 2000-2020年文本智能计算研究的主题演化情况
2.3.1 主题演化分析 首先,在2002-2013年间研究主题的持续性较好,有许多持续演化的脉络出现。2014-2018年则涌现出较多新兴的主题,这与图3中突发词检测的结果相印证。因此可以认为2014年之后文本智能计算的研究进入了新时代,社会媒体、智能导学系统、粒子群优化、计算机视觉、语义学等新兴主题不断出现。
其次,整个演化过程中出现了自然语言处理、信息检索两个持续性较强的演化脉络,且其存在较多的主题融合与分化现象。自然语言处理演化脉络主要涉及知识、网络框架、深度学习、医疗保健、隐私等主题;信息检索演化脉络主要涉及知识、网络框架、情感分析、会话代理等主题,二者在2004年和2010年都出现过融合现象,体现了信息检索与自然语言处理的交叉协同关系。此外,2014年后出现的许多脉络也具有持续演化的趋势,如2014年出现的“大数据”主题演化脉络和2018年出现的“聊天机器人”主题演化脉络,都演化至2020年,有很大可能在接下来一段时间中持续演化。
最后,在整个研究过程中,也出现了许多孤立主题和未能持续演化下去的主题,如2006年出现的“人机交互”主题演化至2016年便发生断裂。2000年出现的“人工智能”主题脉络在2018年演化至“深度学习”时也发生了断裂,可能的原因是深度学习研究分化为了多个规模较小的子领域,研究关注热点受到分散[34]。
2.3.2 发展态势分析 根据图7展示的主题战略图的结果,文本智能计算研究各主题社区均位于第一或第三象限,发展态势对比鲜明。C1-人工智能和C2-数据挖掘两社区位于第一象限,是当前研究的核心主题,且发展潜力巨大,不仅受到研究者的广泛关注,其研究体系也已比较完善。其中,C2-数据挖掘主题社区的密度最大,说明其内部各子主题的发展已经相对完备,交叉现象明显,如基于数据分析和商务智能的意见挖掘等研究方向在近年来发展势头较好[35];C1-人工智能主题社区的平均度数中心度最大,说明社区内的各主题受关注程度最高。
C3-信息检索、C4-文本挖掘和C5-文本分析三社区位于第三象限,处于学科领域的边缘位置。结合领域发展的实际情况,信息检索与文本挖掘主题社区中的许多研究方向已经较为成熟,如朴素贝叶斯、SVM、众包、推荐系统等,不再是当前需要突破的核心,且伴随着新兴技术的发展,其受到的关注度也在逐年下降;文本分析主题社区中的许多研究方向都是新兴的技术领域,如验证码识别、知识图谱、计算机视觉、LIWC等,与许多学科有广阔的交叉应用前景,同时还有许多有价值的方面未被充分挖掘,虽然目前处于边缘位置,但在未来有很大的提升空间,很可能成为未来研究中的引擎类主题。
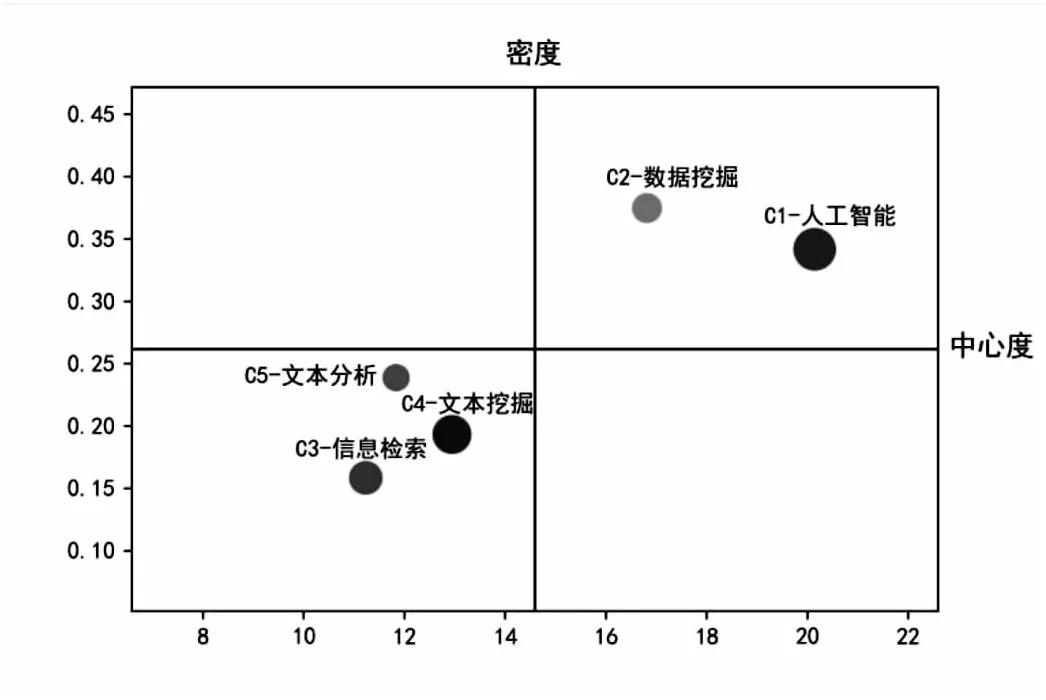
图7 文本智能计算研究发展态势战略图
3 研究结论与反思
文章基于文献关键词,利用复杂网络分析方法和可视化工具,以文献关键词为分析依据,对文本智能计算研究的主题分布、关联结构、演化脉络和发展态势进行了分析与揭示,以更直观清晰地揭示文本智能计算研究的当前主题关联结构与未来发展规律。
3.1研究结论2000-2020年间文本智能计算研究涉猎主题广泛,研究方向明显,形成了特征和区别鲜明的主题社区,各主题社区均表现出了独特的方向特征与发展态势。
在学科结构上,整个文本智能计算领域结构稳定,发展全面,各主题社区在互相交叉渗透的同时也保持了自身研究体系的稳定。研究大致可分为如下5个主题社区:人工智能、数据挖掘、信息检索、文本挖掘、文本分析。其中,人工智能在文本智能计算领域的运用已成共识;数据挖掘、信息检索、文本挖掘领域的发展已经较为成熟;文本分析领域具有较大的发展潜力。
在研究的当前热点与未来方向上,人工智能、数据挖掘两个主题社区是目前文本智能计算领域研究的主流方向,具有良好的发展前景;信息检索、文本挖掘和文本分析领域受关注程度较弱,在研究中较为孤立,原因是信息检索与文本挖掘主题社区中许多研究方向已经较为成熟,不再是当前需要突破的核心,因此领域受到的关注度也逐年下降;文本分析主题社区中的许多研究方向都是新技术和新应用的高发区间,研究正处于萌芽阶段,主题间关联正在建立之中,价值未被充分挖掘,在未来很可能成为研究中的引擎类主题,发展前景广阔。
3.2研究反思本文直观清晰地揭示了2000-2020年期间文本智能计算研究的主题关联结构、研究方向、演化脉络和发展态势,总结并拓展了前人在文本智能计算领域的研究成果,并为后续的研究指明了可能的方向。
此外,本文的研究是基于文献中的关键词及其之间的共现关系开展的计量学定量分析,有一定的研究缺陷:在今后的研究中应当考虑文献多方面的特征,如标题、摘要、基金及参考文献等,以更加深入丰富地揭示领域研究的内涵;还可以考虑开展文本智能计算研究领域的国家、机构、作者的合作关系研究,从而多元化地描述文本智能计算研究的主题结构与发展演化态势。
