基于集成学习模型的城市轨道交通车载数据分析与列车停车误差预测
2021-04-27张兴凯张立鹏王晓玲
张兴凯 张立鹏 陈 钰 李 欣 王晓玲
(1.郑州地铁集团有限公司运营分公司,450046,郑州;2.卡斯柯信号有限公司,200071,上海;3.华东师范大学软件工程学院,200070,上海 ∥ 第一作者,高级工程师)
城市轨道交通数据分析有利于更好地提升服务效果,提高管理效率。在票价变更实施之前,可通过数据分析来评估票价变化可能带来的影响[1-2];通过数据分析为城市轨道交通出行者提供最有效的出行计划[3-4];数据分析还应用在停站跳站方案设计[5]、公共交通网络设计[6]、路线性能评估[7]和公共交通结构图设计[8]等工作中。目前,对车载数据分析的研究尚属空白。
1 车载数据分析模型的建立
1. 1 车载数据
城市轨道交通车载数据是列车在运行过程中通过各传感器采集到的、标记列车各项指标的数据集合,是一种典型的大数据,数据量庞大、特征多、数据类型丰富。车载数据可反映车轮是否发生打滑、车门状态、车辆负载及坡度等列车当前的状态。列车停车误差为列车实际停车位置和期望位置之间的差值,其实际表现为列车停稳后车门与对应屏蔽门之间距离。该误差是车载数据的最后一个标签。若列车停车误差较大,轻则影响乘客乘车体验,重则使乘客无法轻松地进入客室,此时列车需要通过重新起动及制动来调整停车位置。
本文进行车载数据分析的主要目标是找到影响列车停车误差的相关因素,并通过学习模型根据车载数据进行停车误差预测。将除列车停车误差之外的所有列车状态值作为自变量X(向量),将停车误差作为因变量y,则可将停车误差预测问题转化为一组自变量对因变量的影响。又因y为连续变量,若假设共有m个自变量,则可将该停车误差问题表示为回归问题。LR(逻辑回归)、SVR(支持向量回归)等众多基础的机器学习算法都可解决回归问题,并且在解决简单的回归问题或某些特定领域的问题中取得很好的效果。然而,经试验发现,在面对特征维度较高、特征较为复杂的车载数据时,单个算法很难取得令人满意的结果。
1.2 集成学习模型思路
集成学习算法为通过组合多种学习算法,进而得到比单一算法预测性能更好的算法。其潜在的思想是:即使集成学习算法中的某个学习算法得出了错误的预测,其他学习算法也可以通过最终结果的集成来纠正错误。集成学习的策略主要有Bagging、Boosting及Stacking等3种。Bagging策略主要基于重复采样思想,在采样一定次数之后计算统计量的置信区间,其主要代表算法模型为随机森林(Random Forest)。Boosting策略主要基于减小监督学习中的偏差思想,经过训练得到一系列弱学习器,并将其组合为1个强学习器。Stacking策略主要是训练1个模型用于组合其他模型:先训练多个不同的模型,再把各训练模型的输出为输入来训练1个新模型,以得到最终的输出。Stacking策略在理论上可表示上述两种集成学习策略,且其设计方法更灵活,可根据实际场景设计合适的集成模型。
基于Stacking策略的集成学习算法集各基础算法的优点于一身,且最终能给出一个用于实行的完整算法,并因此受到了学术界和业界的普遍关注。按实行阶段,基于Stacking策略的集成学习算法可分为基础模型算法评估阶段和基础模型算法集成阶段。基础模型评估阶段通常要衡量基础模型的准确度。在基础模型集成阶段,对于分类问题,通常采取基础模型投票表决的方式,以票数最多的类别为样本数据的最终类别;对于回归问题,多采用基础模型加权平均法计算,从而得到样本数据的标签值。
在基础模型的评估中,除了基础模型的准确度之外,基础模型之间的差异性也应作为基础模型的评估标准。如果2个基础模型的相似度非常高,甚至完全一样,那么这两个基础模型的集成结果不会高于其中任意一个基础模型的结果。因此,基础模型之间的差异性越大,越能从差异的个体基础模型之间寻找到可以优化提升的地方。
在基础模型集成过程中,仅仅依靠简单的加权平均并不能让准确度高的基础模型发挥较大的作用。有必要设计相关的模型集成算法,使得精确度较高的基础模型可获得较高的权重,对最终的集成结果贡献更大。
2 基于Stacking策略的集成学习模型
2.1 基础模型算法评估阶段
2.1.1 基础模型算法的评估内容
基础模型算法的评估内容主要包括准确度评估和差异度评估。列车停车误差y是一个连续型变量,也就是一个回归问题。回归问题的模型准确度主要是基于均方误差EMS进行衡量的。其计算式为:
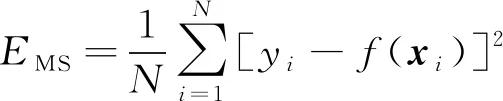
1)
式中:
N——包含列车停车误差的车载数据记录数量;
yi——车载数据记录中的第i条真实停车误差值,i=1,2,…,N;
f(xi)——基础模型根据第i条车载数据预测的停车误差值。
式(1)反映了预测值与真实值之间的误差。EMS的值越小,表示模型的准确度越高。
差异度评估主要采用ICC(组内相关系数)作为衡量指标。ICC是衡量和评价观察者间信度和复测信度的信度系数指标。将2个基础模型视作2位观察者,则在同一批包含N条车载数据的数据集上,ICC的值r为:
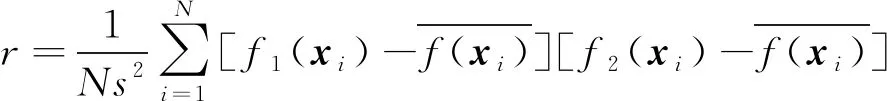
2)
式中:
f1(xi)——观察者1对第i条车载数据的停车误差的预测;
f2(xi)——观察者2对第i条车载数据的停车误差的预测;
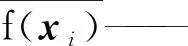

r值越大,则表明组内观察者之间的相似度越高。因此,可用1-r来衡量组内各个模型之间的不相似性。在保证模型精确度的前提下,为了尽量使得组内的基础模型不相似,1-r的值越高越好。
2.1.2 基础模型的筛选
基于基础模型的精确度和差异性,筛选了K个基础模型,再之后集成为最终模型。集成模型的质量为:
(1-α)[1-rC(R1,R2,…,RK)]
3)
式中:
α——超参数,用来衡量模型在准确度和差异性之间的选择度,取值范围为[0,1]。通常来说,α应该设置为一个较大的数,毕竟集成模型最终的目的是提高模型的准确度。
Rj——表示第j个模型,j=1,2,…,K;
rC(R1,R2,…,RK)——各基础模型之间的相似度;则1-rC(R1,R2,…,RK)反映各基础模型之间的不相似性。
为确定K值,在车载数据分析预测的场景中,假设筛选出的每个基础模型都只有1个输出(即对停车误差的预测),则每个基础模型都可以形式化为函数f:Rm→R,其中m表示车载数据的特征维数。例如:在1条列车停车车载记录中,包含了m维特征,用于表征车轮是否打滑、车门状态、车辆旁路信息及车辆负载等列车当前状态;每条车载数据都包含m维特征及1个标签数据y(停车误差)。表1为车载数据具体格式示例。

表1 车载数据示例(部分)
表1中,每一列都表示每一条车载数据在该特征上的取值,所有特征都可以看做是模型的输入值X。X是包含N行m维车载数据的向量,表示为X∈Rm。假设车载数据服从p(X)分布,且这N条数据都是从p(X)分布中采样出来的,则列车真实的停车误差可表示为y(X)。假设第j个基础模型对X的预测结果表示为fj(X),则K个基础模型集成后的模型f(X)可表示为:
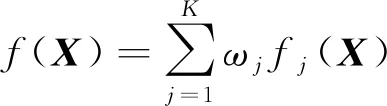
4)
式中:
ωj——第j个基础模型的权重。
那么第j个基学习器及集成模型在当前X上的误差可以分别表示为:
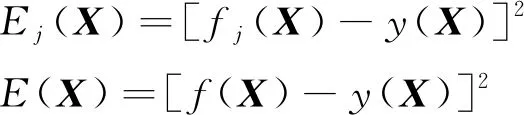
5)
那么第j个基学习器及集成后的集成模型在数据分布p(X)上的误差可以分别表示为:
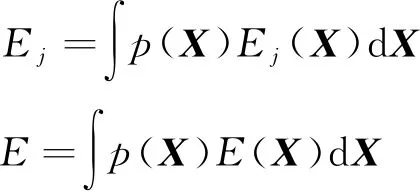
6)
那么第j个基学习器及第l个(l=1,2,…,K)基学习器在数据分布p(X)上的相关性可以表示为:
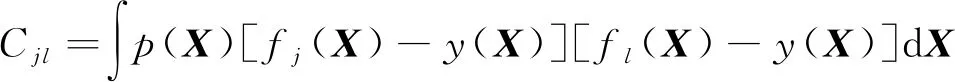
7)
可以很容易看出来Cjl=Clj,且Cjj=Ej。可以从式(4)及式(5)中得到:
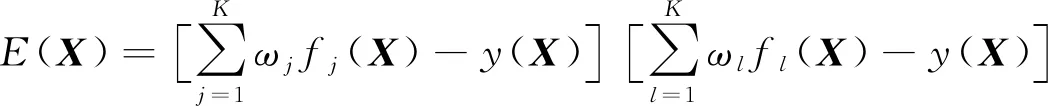
8)
由式(6)~(8)可得:
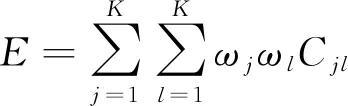
9)
如果假设所有基础模型在集成阶段都有相同的重要性,即所有基础模型的权重都一样,则式(9)可表示为:

10)
如假设第k个基础模型被从候选基础模型中剔除,用数学符号表示取k的补集,则式(10)可以表示为:

11)
由式(10)及式(11)明显可见,E比E大。由此可得,基础模型筛选基本条件为:
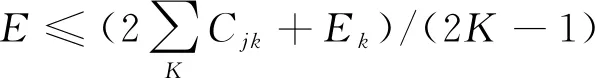
12)
如果满足式(12),则意味着对最终集成的模型而言,包含第k个基础模型比没有包含第k个基础模型效果差。此时,应将第k个基础模型剔除出候选集。综合考虑式(10)及式(12),可以得到如下约束:

13)
基于式(13)可对于每个基础模型做出判断,将不符合的基础模型直接剔除出候选集。
2.2 基础模型算法集成阶段
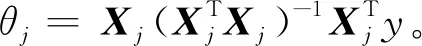

14)
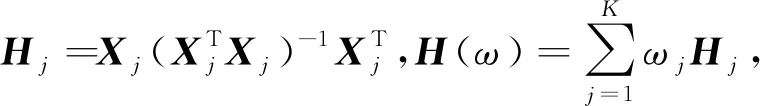
本文使用留一法来确定基础模型的权重。对一个基础模型而言,留一法通过对包含N条数据的整个数据集进行N次训练和预测来确定权重:第1次,使用2~N条数据对基础模型进行训练,并使用第1条数据作为测试集;第2次,使用除了第2条数据之外的所有数据进行模型训练,并使用第2条数据作为测试集;如此继续,直至第N次,使用除了第N条数据之外的所有数据进行模型训练,并使用第N条数据作为测试集。


15)
留一法交叉验证的标准是使用残差平方和来计算的:
Vcr(ω)=(y-η)-1(y-η)=
对目标函数求解,当Vcr(ω)取最小值时,ω的取值为最优解。即最终每个基础模型的权重为:

16)
式中:
QN——整个权重的搜索空间,可表示为QN={ω∈[0,1]K,0≤ωk≤1}。
经过基础模型评估阶段及基础模型集成阶段,可成功选出K个基础模型,进而基于模型集成策略完成模型的集成工作,完成集成模型的创建。
3 集成模型算法的评估
为了验证基于Stacking策略的集成学习模型算法的效果,本文以郑州地铁5号线为例进行验证。从郑州地铁5号线的车载数据中解析出约10 000条列车停车数据相关记录,其每条数据都包含180维特征及列车停车误差标签。在研究开始前,对车载数据的特征进行处理,清理出一些静态特征数据,并对相关度极高的特征数据进行删减合并等,最终保留了75维特征。本研究在试验中用到的基础模型都来自于sklearn包(Scikit-Learn机器学习开源工具包)。
本文从Sklearn包中挑选出20个最常使用的基础模型作为候选模型库。这20个基础模型根据郑州地铁5号线车载数据得到的停车误差预测值(如表2所示),分别按均方误差EMS和模型拟合度(Adjusted R-squared)来进行衡量。模型拟合度是一个比例式,比例区间为[0,1],越接近1,表示模型拟合度越高。由表2可以看出,模型之间优劣性是很明显的。总的来说,Decision TreeRegressor模型等基于决策树的模型表现都优于其他模型。这可能是因为地铁车载数据中存在较多离散的特征,非常适合采用决策树做节点的分裂。

表2 基础模型的评估结果
表3为多回归器集成学习模型与各基础模型的预测结果对比。由表3可以看出,多回归器集成学习模型的预测准确度有了极大的提高。
表4为基于Stacking策略的集成学习算法模型与其他集成模型的预测结果对比。由表4可以看出,基于Stacking策略的集成学习算法模型的效率最优。
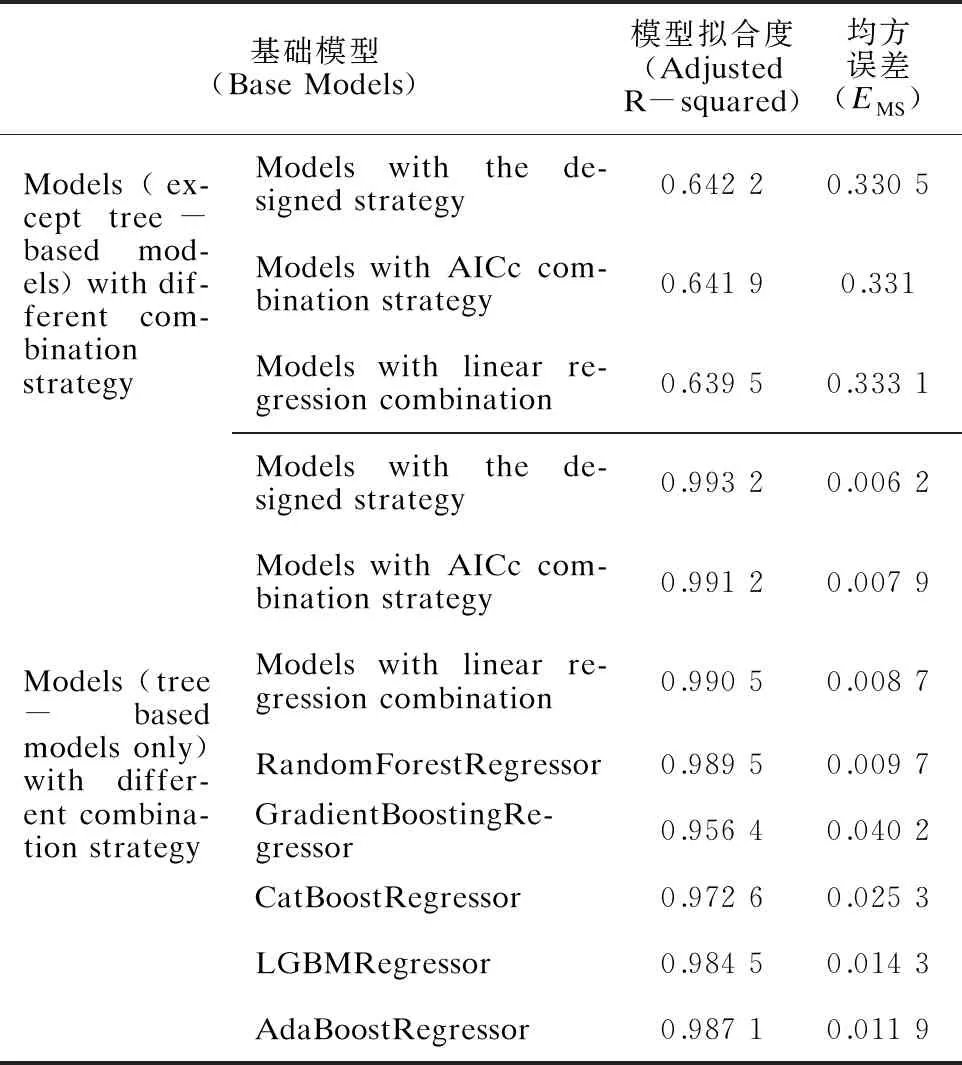
表4 基于Stacking策略的集成学习算法模型与其他集成模型的预测结果对比
表5展示的是部分预测和实际数据的对比结果。由表5可以看出,模型预测数据与真实数据非常接近,具备非常好的精度。
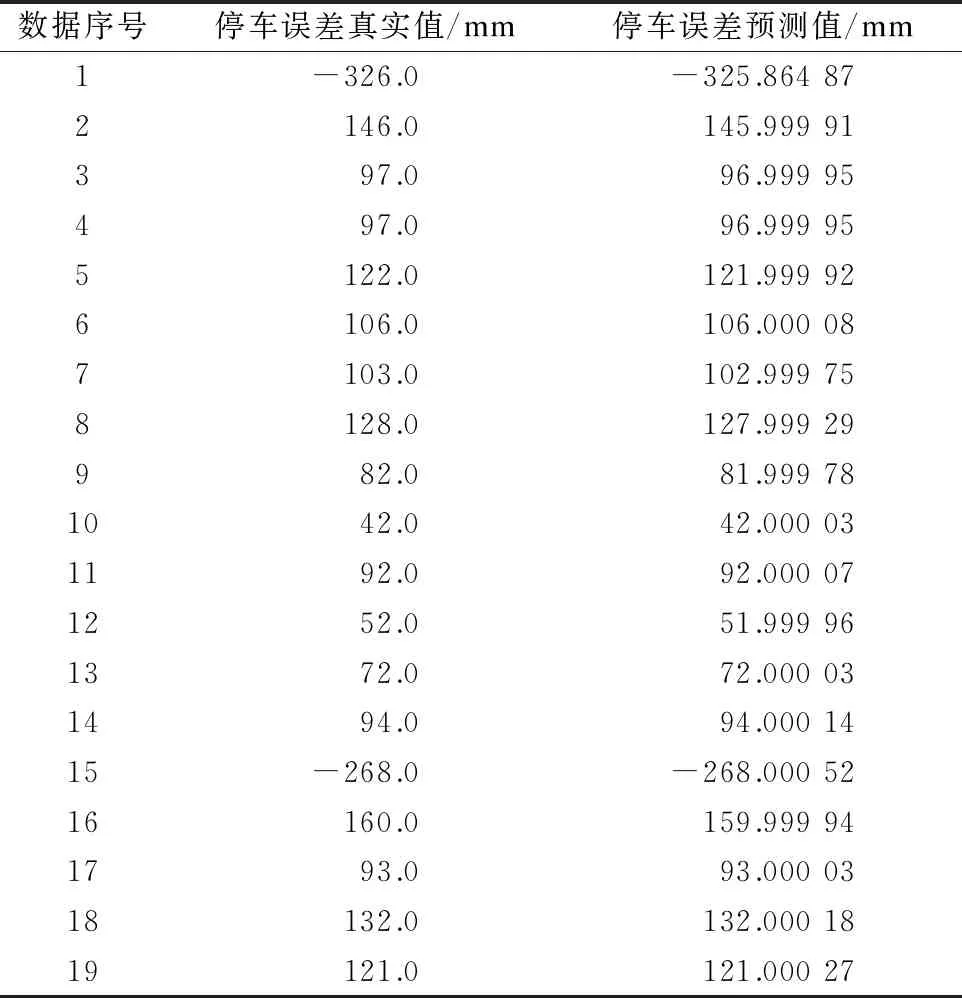
表5 郑州地铁5号线停车误差的真实值与预测值对比
4 结语
本文提出了一种基于Stacking策略的集成学习模型算法。通过基础模型算法评估阶段和基础模型算法集成阶段,成功选出K个基础模型,并基于模型集成策略完成了模型的集成工作,最终得到了基于Stacking策略的集成预测模型。基于实际案例,使用该集成模型对列车停车误差进行预测,并对预测结果进行验证。验证结果显示,基于Stacking策略的集成学习算法模型的训练效率高、预测精度高,与其他传统模型相比具有较强优势。
