基于IFOA-LSSVM算法的机载LiDAR森林生物量估测
2021-04-27于慧伶孙绳宇朱伊枫李羽昕李新立
于慧伶,孙绳宇,朱伊枫,李羽昕,李新立
(东北林业大学a.信息与计算机工程学院;b.机电工程学院,哈尔滨 150040)
0 引言
森林生物量是森林生态系统林分特征信息的重要体现,与森林生物多样性、蓄积量和碳储量等属性有着很强的相关性[1]。每木检尺的单木森林调查是量化森林特征的主要途径,通过测量单木胸径和树高并将其作为自变量建立相应的异速方程获得森林地上生物量,虽然这种野外测量方法准确,但耗时费力[2]。遥感作为有效的技术手段,解决了大区域林分特征定量估算问题,减少了人力与时间耗费,在较高精度下保证获得数据的空间完整性和时间一致性。激光雷达(Light Detection and Ranging,LiDAR)是一种新兴的遥感技术手段,是通过测算传感器到达目标物之间的时间进行距离换算的一种主动遥感技术,凭借其获取植被垂直结构信息的优势成功应用于林业领域[3]。
近年来,一些学者将非参数化机器学习算法应用于森林生物量遥感估算研究中[4-6]。其中,支持向量机(Support Vector Machine,SVM)能够极大地降低计算复杂性、加快求解速度,对于解决复杂的回归问题具有较好的预测性能[7]。董金金[8]应用实测地上生物量和Landsat-8遥感数据,对泰山景区的森林地上生物量进行估测,表明粒子群优化算法(Particle Swarm Optimization,PSO),优化SVM的估测性能最好。
果蝇优化算法(Fruit Fly Optimization Algorithm,FOA)是一个较新的群智能优化算法,其灵感来自真实果蝇的嗅觉与视觉觅食行为[9-10]。FOA以强大的全局寻优能力,较小的计算量等优点逐渐体现在各领域中。选取全局搜索能力强、计算效率高的FOA优化最小二乘支持向量机(Least Squares Support Vector Machine,LSSVM)的惩罚因子和核函数参数,以提升模型精度和计算效率,并将优化模型应用于森林地上生物量估测,以提高估测模型的速度、稳定性,提升机载LiDAR数据估测森林地上生物量的精度[11-13]。
1 数据获取与处理
1.1 机载LiDAR数据获取与处理
LiDAR数据是2016年由某森林和森林、土地、自然资源运营和农村发展部的海达瓜依区办公室共同获得。利用人工交互的方式进行数据处理,借助点云处理软件Terrasolid,通过搜索局部高程异常点去除LiDAR数据的噪点,采用不规则三角网(Triangulated Irregular Network,TIN)滤波算法对离散点云数据进行滤波分类,由数字表面模型(Digital Surface Model,DSM)与数字高程模型(Digital Elevation Model,DEM)栅格差值运算,得到研究区域高程归一化后的冠层高度模型(Canopy Height Model,CHM),通过坐标对每块样地进行裁切提取了84个样地位置的归一化点云数据[14-16]。
1.2 地面数据获取及处理
2015年某完成植被资源清查项目(Vegetation Resource Inventory,VRI),覆盖海达瓜依的全部范围,约106ha,其中有35块永久监测样地(YSM),3块变化监测样地(CMI)和46块VRI样地。在了解实际样地级林分参数的基础上,将VRI、YSM和CMI 3种样地类型的共计84块样地数据经异常值去除以及林种分类等分析,采用其中62块样地作为构建地上生物量模型的地面数据。考虑到样地数量的有限性,将样地林型分为3种:崖柏型(C型24块),铁杉型(H型24块)和云杉型(S型14块)。汇总得到3个研究区域样地级(plot-level)林分参数包括胸高断面积Basal area(m2/ha),树高Tree height /m(胸高断面积加权高)和蓄积量Volume(m3/ha)。样地级林分参数统计表见表1。

表1 样地林分参数统计表
针对研究区域中的62块样地,采用森林植被蓄积量-生物量的转化方法进行地上生物量计算,并以此作为样地森林生物量地面调查数据。
2 改进的果蝇算法优化LSSVM
果蝇利用嗅觉闻到食物味道,而食物味道浓度与每个果蝇相对食物的距离呈负相关。飞近食物位置之后,利用敏锐的视觉找到同伴聚集和食物的位置,再靠近目标。通过数次迭代探索,直至在搜索空间中找到食物对应的位置为止。在此通过反向学习的群体初始化操作以及三维搜索与自适应更新步长策略,提高算法寻优能力与收敛精度。对果蝇优化算法改进如下:
将FOA的搜索空间由二维平面扩展到三维空间(X_axis,Y_axis,Z_axis),果蝇种群与原点的距离为:
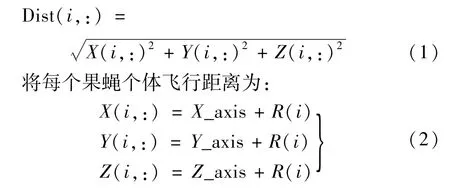
式中:i为迭代次数;R(i)为第i次搜索步长。
在果蝇算法寻优的过程中,果蝇群体总会向当前迭代中具有最佳浓度(bestSmell)的果蝇个体靠拢聚集。如果,此果蝇个体并不具有全局的最优位置,那么每次选定的最优个体很容易带来局部寻优的缺陷。引入分散化寻优机制更新果蝇群体的位置,基于反向学习策略启发增加对每次迭代中具有最差浓度(worstSmell)果蝇个体的学习,意味着在决定下一次迭代群体初始位置时,应综合考虑当前迭代中最佳果蝇个体与最差果蝇个体的位置

式中,bestSmell和bestindex分别为当前迭代中浓度最佳果蝇个体的味道浓度和序号。
将下一次迭代群体初始位置设定为最差果蝇个体关于当前群体位置的中心对称坐标与最优果蝇个体位置的中点

将该坐标作为下次迭代果蝇群体位置,实现基于反向学习的群体位置初始化。
利用自适应更新步长策略,步长取值为果蝇个体的飞行方向距离由当前迭代的最佳味道浓度值与上次迭代的最佳味道浓度值的比值决定,k(i)为权重因子。
当i>1时,果蝇的搜索步长定义如下:
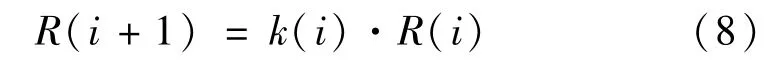
权重因子的取值由上一次的果蝇最佳味道浓度与当前迭代的果蝇最佳味道浓度决定:
当Smell′(i)< Smell′(i-1)时,有

当目前迭代的最佳味道浓度值优于上一次迭代的最佳味道浓度时,k(i)<1。
当Smell′(i)≥Smell′(i-1)时,有
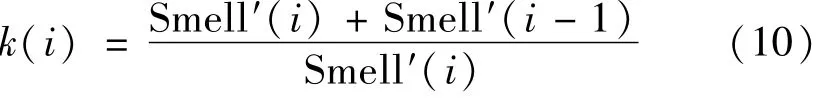
即上一次迭代的最佳味道浓度值优于目前迭代的最佳味道浓度,权重因子k(i)>1。为提高果蝇优化算法的全局搜索能力,应该通过增加下一次迭代搜索步长来扩大寻优范围,提高全局搜索能力。由式(10)可知,当Smell′(i-1)与Smell′(i)的差值较小时,意味着当前搜索范围内此次迭代寻优的最佳味道浓度值劣于上一次迭代的最佳味道浓度,当前搜索范围的寻优效果一般,应使搜索步长R(i+1)以较快速度增加来更新搜索区域继续寻找搜索空间最优解;反之,当Smell′(i-1)与Smell′(i)的差值较大时,意味着果蝇群体已经通过快速增大的步长到达更新的搜索范围,由于当代寻优结果仍差强人意,应该让搜索步长R(i+1)增加较慢,来继续扩大寻优范围。
LSSVM模型中的可调节参数(惩罚因子γ和核函数参数σ)的选取对模型的学习性能有很大的影响,采用改进的IFOA对LSSVM的两个参数进行优化。
设置算法最大迭代次数(maxgen),种群规模(sizepop),随机初始化果蝇群体的初始位置(X_axis,Y_axis,Z_axis),初始化果蝇个体的搜索步长R(1)=3。将改进果蝇算法应用到优化最小二乘支持向量机两个参数(σ,γ)的具体算法流程图如下:
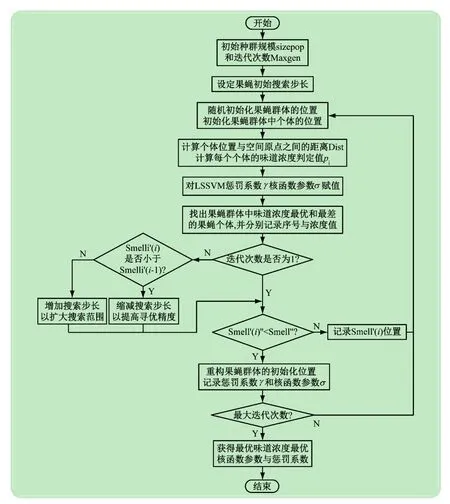
图1 IFOA-LSSVM算法流程图
3 实验与结果分析
3.1 模型特征变量的提取
对于不同的机载激光扫描(Airborne Laser Scanning,ALS)系统的构造和飞行高度,在大多数情况下植被冠层的第1回波更趋于稳定,采用第1回波来提取森林参数。为排除灌木等低矮植被点的干扰,对高程归一化后的激光雷达数据进行变量提取时,只提取高于2 m的植被点。选取以下LiDAR特征因子作为备选变量:最大高度(max)、最小高度(min)、平均高度(avg)、高度标准差(std)、高度偏斜度(ske)、高度峰度(kur)、高度绝对标准差(qav);点云百分位高度变量:p10、p20、p30、p40、p50、p60、p70、p80、p90、p95、p99;冠层返回点密度变量:b10、b20、b30、b40、b50、b60、b70、b80、b90、b95、b99;返回点数变量:c00、c01、c02、c03、c04、c05;返回点密度变量:d00、d01、d02、d03、d04、d05和冠层覆盖度变量(cov)共41个变量。
以百分位高度p50,冠层覆盖度变量cov为例,图2为点云处理软件TerraSolid中提取相关LiDAR变量三维示意图。

图2 提取百分位高度p50与冠层覆盖度变量cov三维示意图
3.2 模型特征变量的优化
为更好地拟合地上生物量与LiDAR特征变量的关系,提高模型的估测精度,分析每个LiDAR变量与样地生物量的Pearson相关系数和显著性水平;考虑特征变量间的共线性来选取与生物量相关性较高(p≤0.05)且独立性好的特征变量;利用主成分分析法对选取的特征变量进行降维,去除冗余变量防止过拟合。
分别计算崖柏型(C型)、铁杉型(H型)、云杉型(S型)和不分类(即不区分样地林种N型)4种类型的Pearson相关系数,分析结果如图3所示。
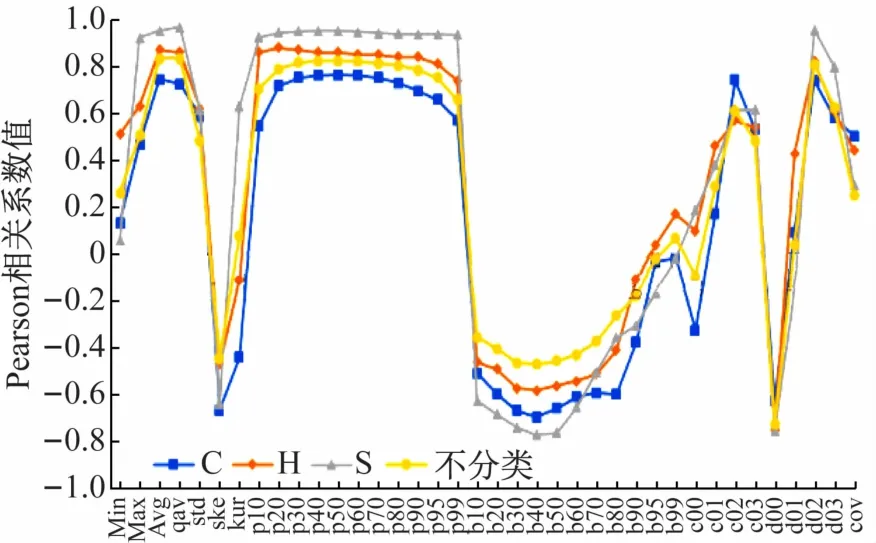
图3 不同林种类型点云特征变量与地上生物量的Pearson相关系数分析
由Pearson相关系数分析结果可知,平均高度(avg)、点云高度绝对标准差(qav)、百分位高度(p10~p99)及返回点云密度(d00,d02,d03)与生物量之间的相关性较高;各林型与不区分林种类型时,各LiDAR变量与相应样地地上生物量之间的相关性大小大体趋于相同,为得到区别于不同林种的LiDAR特征变量还需要进行相关性的显著性检验。
3.3 基于IFOA-LSSVM的生物量估测模型
实验采用改进的FOA分别对LSSVM的参数(σ,γ)寻优,将各林型的点云特征变量经主成分分析后的主成分得分和森林地面生物量实测值作为估测模型作为实验数据,2/3的数据用来训练,1/3的数据作为测试。采用留一法交叉验证对训练数据集进行交叉验证。
通过FOA算法对(σ,γ)两个参数进行寻优,寻优目标为使浓度判定函数Smell(i)达到最小。果蝇种群规模为20,迭代次数为100,初始步长设置为3,σ的寻优范围为[0,100],γ 的寻优范围为[0,200]。以未分类型样地的迭代寻优过程为例,迭代20步RMSE收敛,收敛最终值RMSE=0.012 5;经IFOA寻优计算后的未分类型森林地面生物量估测模型中:σ=2.393 0,γ =27.889 9。
图4为FOA-LSSVM模型与IFOA-LSSVM模型的训练收敛图,可以看出IFOA-LSSVM模型的收敛速度更快且曲线梯度更高,图5为2种模型对测试集数据集的生物量估测结果与真实值的对比,可以看出IFOA-LSSVM模型的估测值更加接近真实值,达到了更好的估测准确率。
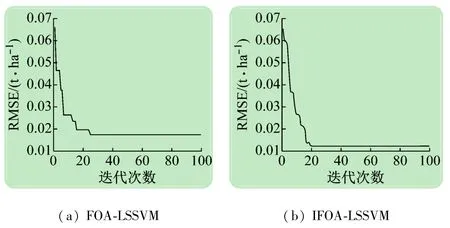
图4 FOA-LSSVM与IFOA-LSSVM训练收敛过程对比

图5 FOA-LSSVM与IFOA-LSSVM估测结果与真实值对比图(未分类)
3.4 生物量估测模型的性能对比及分析
为了验证IFOA-LSSVM模型的泛化能力和寻优精度,利用所建模型与测试数据集对崖柏型(C型)、铁杉型(H型)、云杉型(S型)和不分类(N型)4种类型的样地的森林地面生物量进行估测,并将该模型的估测结果与FOA-LSSVM、GS-LSSVM、PSO-LSSVM 的估测结果进行比较。采用均方根误差(RMSE),平方相关系数(R2),作为评价指标,对比如表2所示。

表2 不同优化算法的LSSVM模型寻优参数和性能对比
对于未分类林型的森林地面生物量模型,IFOALSSVM模型估测生物量的均方根误差值(RMSE)由FOA-LSSVM 的86.708 9 t/ha 下降到67.219 5 t/ha,误差降低了28.99%。另外IFOA-LSSVM模型估测未分类林型生物量的值与实测值的相关系数(R2)由80.51%提升到89.44%,可见IFOA-LSSVM 模型的估测误差更小拟合程度更好。对崖柏型、铁杉型、云杉型,IFOA-LSSVM模型估测生物量的RMSE值分别由79.129 5、77.164 2、60.397 7 t/ha 下降到55.278 7、63.696 7、36.081 3 t/ha,误差依次降低了30.14%、17.45%、40.26%;而且估测值与实测值的相关系数R2由93.99%、88.68%、84.06% 提升到96.68%、93.71%、91.28%。可见IFOA-LSSVM 模型对已分类的3种林型的生物量估测误差和拟合程度均优于GSLSSVM、PSO-LSSVM、FOA-LSSVM。综上可以得出IFOA-LSSVM估测模型的泛化能力更强、收敛速度更快、寻优精度更高。
4 结语
本文以地面样地获取的林分特征为自变量,选用森林植被蓄积量-生物量转化方法计算各林型样地地上生物量。针对FOA容易陷入局部最优的问题,提出了一种改进的FOA,将群体搜索范围由二维扩展到三维,并引入了基于反向学习的群体位置初始化操作,结合自适应更新步长的方法,提高了算法寻优精度与速度。采用改进的果蝇算法优化最小二乘支持向量机的惩罚因子和核函数参数,构建了基于IFOA-LSSVM的森林生物量估测模型,实验表明在实验条件相同的情况下,IFOA-LSSVM估测模型具有泛化能力强、收敛速度快、寻优精度高的特点,适合于对研究区域各林型样地森林地上生物量的估测。
