基于Tri-Training的驾驶风格分类算法
2021-04-24董昊旻张维轩王文彬何云廷康子怡
董昊旻 张维轩 王文彬 何云廷 康子怡
(1.中国第一汽车股份有限公司研发总院,长春 130013;2.中国第一汽车股份有限公司智能网联开发院,长春 130013;3.汽车振动噪声与安全控制综合技术国家重点实验室,长春 130013;4.吉林大学,长春 130012)
主题词:驾驶风格识别 半监督学习 三协同训练
1 前言
随着车载通信终端(T-Box)逐渐普及,车载数据更易于获取,同时,大数据技术的逐步应用为通过车载数据进行驾驶风格分析提供了便利。驾驶风格主要指驾驶员的驾驶习惯,多通过驾驶时的行为特征进行定义。准确识别驾驶员的驾驶风格可以有效地为车载功能的改进、供应商向服务商的转型,以及保险、理赔等业务提供强有力的支撑[1]。
驾驶员的驾驶风格在各领域得到了大量应用,如针对不同驾驶风格设计混合动力汽车能量管理策略[2-3]、车辆换道预警方法[4]和智能车辆自主驾驶决策方法等[5]。近年来,很多学者针对驾驶风格分类进行了研究。黄丽蓉等[6]提出一种基于深度置信网络(Deep Belief Network,DBN)的驾驶行为风格识别模型。李立治等[7]通过主成分分析(Principal Component Analysis,PCA)实现了评价指标的降维,并基于神经网络建立驾驶风格识别模型。刘通等[8]建立基于K-Means 聚类结果的高斯混合模型,得出将驾驶员分为3类时聚类效果最佳的结论。李经纬等[9]采集了不同驾驶员所驾驶的商用车和乘用车的行驶数据,提出了基于K-Means聚类的驾驶风格识别方法。李明俊等[10]建立了多分类半监督学习算法驾驶风格识别模型,有效利用大量未标记数据参与训练,提高了模型对驾驶风格的识别能力。
然而,以上研究并没有针对不同的工况进行驾驶风格分类。同时,现有研究的数据多来源于问卷调查或者仿真环境下的驾驶试验,并不能代表真实道路中驾驶员的驾驶风格。本文基于半监督学习三协同训练(Tri-Training)算法[11-12]对驾驶员驾驶风格进行分类。首先,对驾驶员实际驾驶产生的真实长时序数据进行数据清洗、工况识别、特征提取、专家系统标记。然后,使用Tri-Training 算法进行训练,建立驾驶风格识别模型。最后,通过设置不同的训练、测试集比例,与传统机器学习模型进行对比,以考察模型的有效性。
2 数据采集与处理
2.1 数据采集
2.1.1 硬件装置
基于本文对信号的要求,在车辆正前方、正后方分别安装毫米波雷达,并在车辆正前方安装前视图像单元,如图1、图2所示。通过多通道CANoe设备采集试验车辆动力CAN信号、正前方雷达传感器信号、正后方雷达传感器信号及前视图像单元信号[1]。

图1 毫米波雷达

图2 前视图像单元
2.1.2 数据采集
为了避免参与试验的驾驶员驾驶风格偏向某一方面导致试验数据分布不均,在进行试验前通过《驾驶员驾驶风格调查问卷》进行初选后,选取了80位年龄覆盖25~55岁的驾驶员参加试验。试验时,每位驾驶员需要在规定路线内,分别在50 km/h和80 km/h的2种常用车速下进行2 h 的自然驾驶。在驾驶过程中,由随车的2名专家对特定工况进行记录,并综合整体驾驶试验过程,对驾驶员的驾驶风格进行主观评价。部分典型工况信息和驾驶风格主观评价结果如表1所示。

表1 典型工况与驾驶风格主观评价结果
2.1.3 数据处理
由于车辆底盘CAN 信号噪声数据较多,为了进一步提高训练数据的可靠程度,需要对各原始信号及其数据进行滤波处理,去除传输过程中产生的错误数据。以侧向工况为例,识别过程需要横摆角速度和纵向车速信号,横摆角速度信号来自电子稳定系统(Electronic Stability Program,ESP)的加速度传感器,是传感器原始信号,信号中含有高频噪声,同时存在一定的零点漂移,需进行滤波和去零漂预处理,滤波采用巴特沃斯低通滤波器,通带截止频率1.5 Hz,并对信号最大值进行限制,去除异常跳变值。
同时,在自然驾驶过程中,存在大量的驾驶员正常行驶数据,这些数据往往并不能体现驾驶员真正的驾驶风格,所以需进行筛选,删除匀速行驶的数据、正常切换油门踏板与制动踏板的数据等。
2.2 特征处理
有效且充分的特征指标是驾驶风格识别的基础。现有研究表明,车辆状态参数和驾驶员操作参数能够从多维度有效表征驾驶行为状态及特征。本文结合纵向行驶和侧向行驶的特点,选择表征车辆姿态和运动状态的参数、驾驶员操作信号作为特征,包括油门踏板开度及其变化率、转向盘转角、转向盘转速、车速、纵向加速度、纵向加加速度、侧向加速度、横摆角速度、横摆角加速度共计10个特征。
由于提取的部分特征之间含有强相关性,为了避免过多相似特征使模型过于复杂,采用皮尔逊相关系数计算各工况下特征之间的关联关系,删除部分冗余特征。
以制动工况为例,所选取特征的皮尔逊相关系数如表2所示。

表2 制动工况下部分特征间相关性
2.3 工况识别
本文的工况获取方式分为2种,一种是由随车行驶的专家在出现代表性特定工况时进行记录,但由于数据总量较大,因此大部分情况由另一种获取方式获得工况,即基于驾驶员操作信号、车辆状态信号、高级驾驶辅助系统环境传感器信号,通过后期的数据处理方式对驾驶员的行驶工况进行识别。
本文以换道工况为例,介绍工况识别方式。换道工况属于单移线工况,是车辆由一个车道行驶至相邻车道的过程。换道工况属于转向操作工况的一种,相对于比较容易判别的转弯、掉头工况,特点是转向盘转角变化较小,横摆角速度变化较小,车辆侧向位移为1个车道宽度(4 m左右),换道完成后车辆沿初始方向继续行驶。
判断转向过程是否属于换道工况,需要参考转向持续时长是否大于时间阈值、侧向位移的绝对值是否在标准范围内、转向开始航向角与结束航向角变化量的绝对值是否小于航向角阈值,以及转向过程航向角变化序列与标准模板之间的误差是否小于0.075°。换道工况标准模板如图3所示。
3 算法原理
传统监督学习通过对大量带标记的训练数据进行学习以建立模型,通过模型预测未标记数据。此时的标记指数据所对应的真实标签,如分类任务中的类别、回归任务中的实际输出值。但随着大数据时代的来临,带标记数据少、未标记数据多的情况逐渐增多[13]。

图3 换道工况标准模板
本文中,如果采用监督学习的方法进行驾驶员驾驶风格分类,则分类器需要大量带标签的驾驶风格数据进行训练,存在由专家标记所产生的时间成本、经济成本等问题。如果只使用少量带标记数据进行学习,那么所训练出的分类器不仅分类能力较差,同时也忽略了同样具有大量信息的未标记数据,对数据资源造成了极大的浪费。
半监督学习(Semi-Supervised Learning)[14]尝试通过使用学习器自动对大量未标记数据进行利用,辅以少量有标记数据进行学习。半监督学习方法通过寻找标记实例中的内部结构信息给予未标记实例其可能所属的类别,之后再利用不断扩大的训练集学习获得能力更强的分类器。半监督学习中,大量未标记实例所隐含的内部信息是至关重要的。因此,在仅有部分带有标签的驾驶员驾驶数据和大量未标记数据的条件下,分类器使用半监督学习进行驾驶风格分类是目前较为合理的一种方法[15]。具体学习过程如图4所示。

图4 半监督学习算法过程
4 驾驶员风格识别模型
通过数据采集及处理得到各工况数据后,将每个工况的数据分别输入驾驶员风格识别模型中可得到每种工况下的驾驶风格识别结果,然后进行决策融合,即可得到驾驶员的总体驾驶风格标签。
4.1 基于Tri-Training的驾驶员驾驶风格识别模型
Tri-Training 算法的主要思想是在带标记训练集中进行随机采样,生成3 个有差异的训练集,通过上述训练集对3个基分类器进行训练。之后,利用其中2个分类器对训练集中的数据进行分类,如果存在2个分类器对某个未标记样本分类一致,那么该样本会被作为伪标记样本加入到第3 个分类器的训练集[16]。通过扩充训练集完成对每个基分类器的调优,每个基分类器的扩充训练集均由其他2 个基分类器进行多次重复迭代的伪标记形成。最终,3个分类器通过投票的方式输出分类结果[17]。
算法具体流程如下:
a.首先通过自助法(Bootstrap)方式在同工况下带标签的数据集D中构建3 个具有差异性的训练集S1、S2和S3,通过上述训练集分别对基分类器m1、m2和m3进行训练。
b.使用分类器m1、m2和m3中的2个在未标记样本集U中进行预测,给予分类一致的样本伪标记,并将其加入到第3个分类器的扩充训练集Li(i=1,2,3)中。
c.判断分类器m1、m2和m3及其对应扩充训练集L1、L2和L3是否发生改变。若改变,则重复进行步骤b,直至分类器m1、m2和m3均不再发生任何改变。
d.训练完成后,分类器m1、m2和m3通过投票机制集成为一个分类器得出分类结果。
4.2 试验设置
4.2.1 评价指标
本文使用正确率(Accuracy)、精准率(Precision)和召回率(Recall)作为评价指标:

式中,Ra为正确率;Rp为精准率;Rr为召回率;Tp为被模型预测为正的正样本数量;Fp为被模型预测为正的负样本数量;Fn为被模型预测为负的正样本数量;Tn为被模型预测为负的负样本数量。
4.2.2 试验结果
将驾驶员真实驾驶产生的长时序数据进行数据清洗、工况识别、特征提取,并通过专家进行标记后收集到约2000 条数据样本,随机选取部分数据作为训练集。训练集比例以20%的步长逐步递增至80%,将剩余样本作为测试集。在各工况下,将模型预测的驾驶风格分类结果与专家系统给出的标签进行对比,以准确率作为评价指标。Tri-Training 模型选取随机森林(Random Forest)作为基分类器,并通过与监督学习Random Forest算法和半监督学习自训练(Self-Training)[18]算法进行对比,如表3所示。

表3 各工况驾驶风格识别准确率 %
由表3 可知:当带标签数据占总数据量的80%时,传统的机器学习模型Random Forest模型比Tri-Training和Self-Training 识别准确率均更高;但随着带标签数据比例逐渐下降至60%和40%时,半监督学习方法开始逐渐显现优势;带标签数据比例为20%时,加速工况下的Tri-Training 方法表现十分突出,在制动和并线工况下,Tri-Training 方法较传统的Random Forest 方法和Self-Training 方法也有一定优势。可见Tri-Training 模型可以有效利用未标记样本来提高驾驶风格分类的准确率。
4.3 决策融合方法
将训练数据比例为80%时的试验结果进行融合,与专家系统为驾驶员所标记的结果进行对比,结果如表4、表5所示。
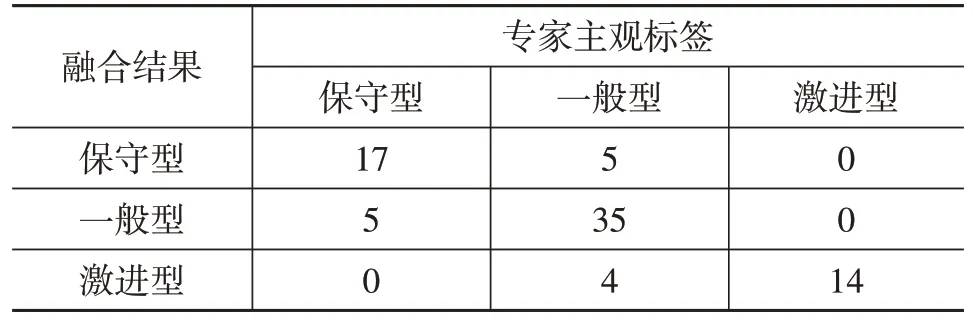
表4 各工况下结果决策融合后驾驶风格识别结果 名
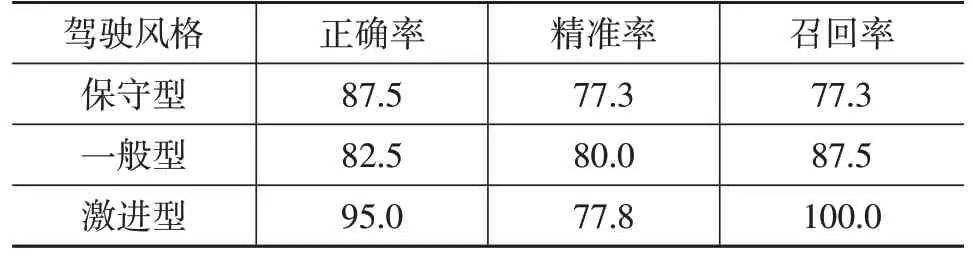
表5 各驾驶风格类型的查准率与查全率 %
根据融合结果可以看出,保守型和激进型之间一般不会出现误分类的情况,但是存在将保守型和激进型错分为一般型的情况。在22名保守型驾驶员中,有5名驾驶员被误分为一般型,这种情况可能是总数据量较少,而一般型数据占比较高导致的,由于数据的不均衡,导致分类器存在一定的偏倚性。在44 名一般型驾驶员中,有5 名被误分类为保守型,4 名被误分类为激进型。其主要原因有:首先,一般型驾驶员和保守型驾驶员界定不明显,后续工作中可能需要进一步明确二者的边界;其次,部分激进型驾驶员在整个驾驶过程中也存在正常的驾驶行为,所以存在一些噪声数据,导致部分一般型驾驶员被误分为激进型。
从评价指标上看,激进型的召回率达到了100%,同时也有着很高的正确率。一般型的数据在正确率、精准率、召回率方面都有较好的结果。但是激进型和保守型的精准率都稍低,均在77%左右,这说明模型学习这2类驾驶风格的能力较弱,也可能是由于样本不均衡导致一般型驾驶员占比过高,降低了整个试验的准确率。
5 结束语
本文提出了一种基于Tri-Training方法的驾驶风格分类方法。从时序数据中筛选出部分特征数据,通过数据清洗、工况识别、特征处理、专家系统标记得到小部分带标签数据,然后通过Tri-Training 模型进行半监督学习。试验结果表明,该模型有效利用了未标记样本,提高了在带标记数据较少时的驾驶员风格分类准确率,并通过进行各工况下的决策融合实现了较好的分类效果。
后续研究将进一步扩大数据集的样本量,挖掘新的驾驶员风格数据,对模型进行优化,在进一步提高准确率的同时,降低算法运行所占用的内存及消耗的时间成本。
