基于YOLO v3和传感器融合的机器人定位建图系统
2021-04-23陈文峰张学习蔡述庭熊晓明
陈文峰 张学习 蔡述庭 熊晓明
技术应用
基于YOLO v3和传感器融合的机器人定位建图系统
陈文峰 张学习 蔡述庭 熊晓明
(广东工业大学自动化学院,广东 广州 510006)
场景中的动态物体影响移动机器人定位算法的精度,使机器人无法建立蕴含场景信息的高精度地图,降低定位建图系统在复杂场景中的鲁棒性。针对目前主流动态SLAM技术受限于系统需求和硬件性能,无法兼顾移动机器人定位精度和系统实时性的问题,提出一种基于YOLO v3和传感器融合的机器人定位建图系统。首先,建立融合编码器和视觉传感器的机器人运动模型,求解移动机器人位姿;然后,利用深度学习技术剔除复杂场景中的动态物体,并针对YOLO v3目标检测网络特点,采用多视图几何方法进行性能优化;最后,经测试,本系统相比DS_SLAM具有更优的轨迹精度,耗时更短。
传感器融合;目标检测;动态物体;定位;多视图几何
0 引言
同步定位和地图构建(Simultanous Localization and Mapping, SLAM)是一种利用传感器获取移动机器人在环境中的运动信息和构建未知场景地图的技术[1],广泛应用于机器人、未知领域(行星、空中、陆地、海洋等)探索、高风险地区搜索救援任务、虚拟现实和自动驾驶等领域[2]。
近年来,视觉SLAM(vSLAM)系统由于传感器成本低廉、性能不俗,受到研究人员的广泛关注。经典的vSLAM系统在理想室内静态场景内,已经相当成熟。目前,动态场景下vSLAM系统的定位和建图问题已成为国内外研究的热点。采用多传感器融合替换单一传感器,常见的是融合IMU传感器的SLAM系统,如港科大团队发布的VINS-Mono[3]和最新的ORB_SLAM3[4]都采用这种方案;融合深度学习方法的SLAM系统可解决动态物体对机器人建图的干扰,如ClusterSLAM[5]利用K-means算法对像素点分簇,计算不同簇的运动模型,恢复物体运动;DS_SLAM采用语义分割方法分离图像的前景和背景,利用帧间几何一致性判断前景是否为动态物体;KinectFusion[6]和Static Fusion[7]通过聚类对图像像素点分簇,为每一簇构造独立的运动模型,然后进行三维重建,并将三维重建的投影与采集图像进行比对和优化。
本文在已有研究成果的基础上,采用深度相机和编码器采集数据,通过非线性优化的方式融合传感器数据;利用YOLO v3网络分离关键帧中的动态物体,通过帧间几何一致性判别是否为动态物体;利用多视图几何重投影方法,减少目标检测次数,提高目标检测线程的性能。
1 移动机器人运动模型分析
1.1 编码器模型分析


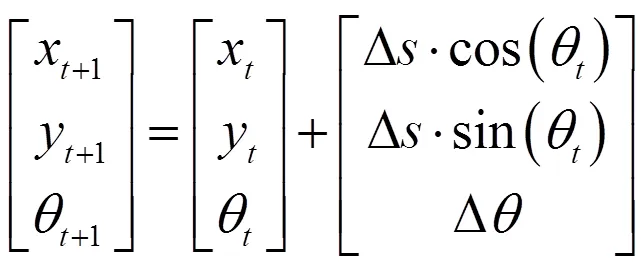
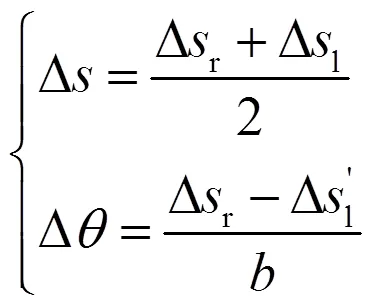
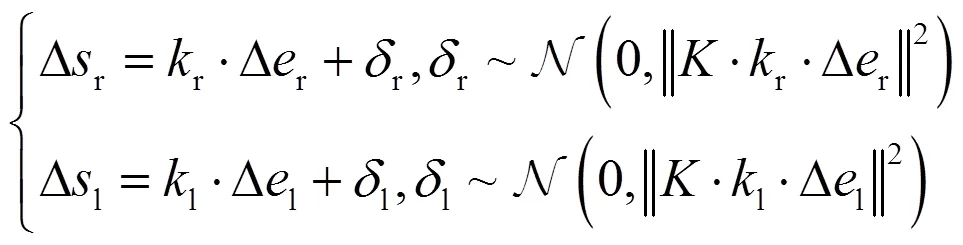
2)圆弧模型,当机器人左右轮差速运动时,轨迹是是圆弧。假设机器人从点到点的轨迹是圆弧,圆心在圆弧的中垂线上,可得出和+1时刻位姿关系为
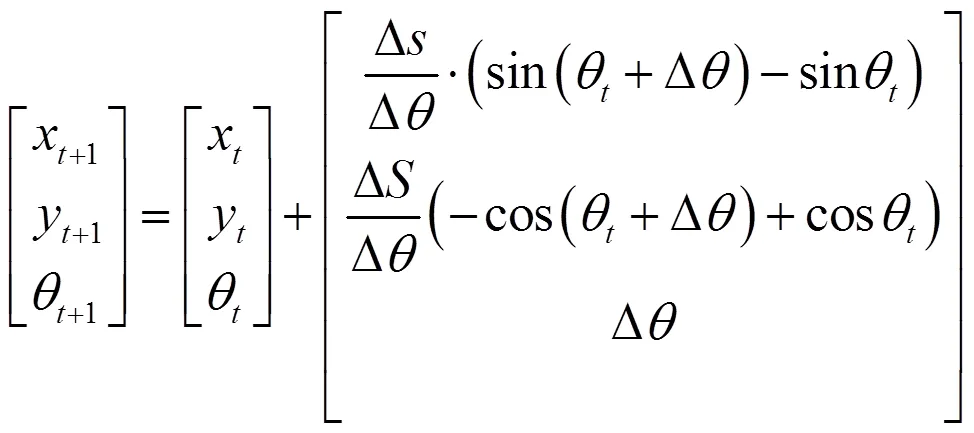
3)割线模型,圆弧模型计算较为复杂,实际中使用最多的是割线模型。假设机器人沿圆弧的割线方向移动,得到和+1时刻位姿关系为
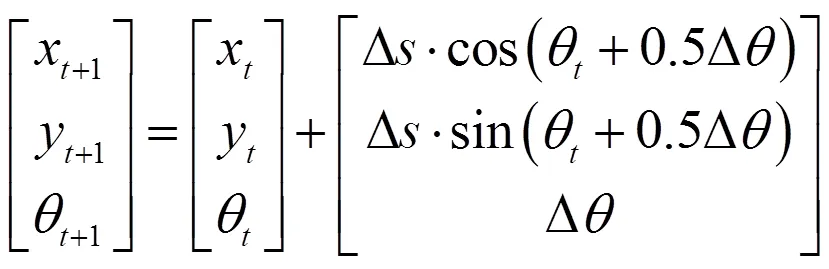
1.2 编码器和视觉传感器融合
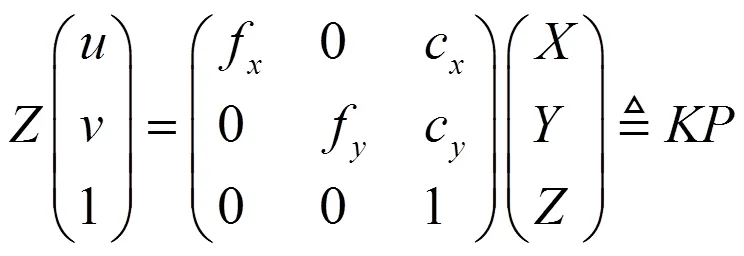
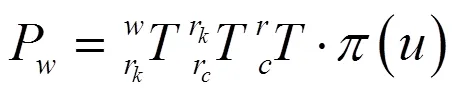


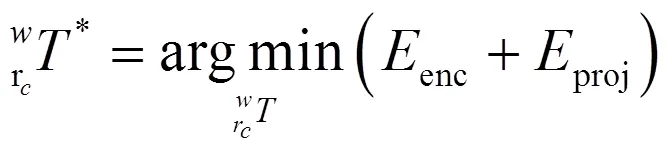
其中编码器误差为

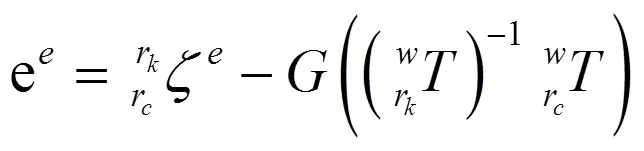
编码器误差协方差矩阵可由编码器噪声模型得到。
2 目标检测网络与SLAM系统融合
2.1 深度学习与SLAM系统融合
本文采用目标检测方法,兼顾实时性和识别精度;采用YOLO v3目标检测网络,在开源COCO数据集进行训练。COCO数据集是一个大型的、具有丰富场景的目标检测和语义分割数据集,可提供80个类别的分类标签。在传统SLAM系统框架中增加目标检测线程,YOLO v3网络可处理图片20张/s。Kinect深度相机帧率为20~30,如果对每一帧图像都进行目标网络检测,目标检测线程会成为系统性能瓶颈,因此,本文采取多视图几何法优化目标网络检测。
2.2 多视图几何法优化目标网络检测
动态像素主要通过2方面影响特征点法SLAM系统的轨迹精度:1)物体运动造成的特征点误匹配影响求解位姿精度;2)大量动态特征点成功特征匹配,影响随机抽样一致性估算的位姿值。
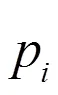
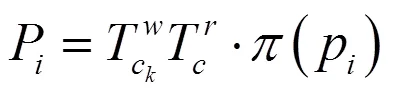
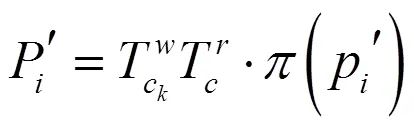
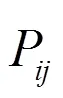
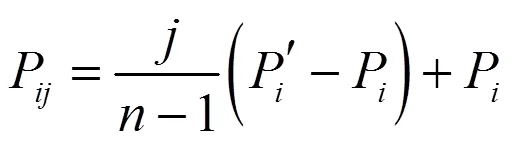
将其重投影到每一个普通帧上,用投影四边形框替代普通帧进行目标检测,减少系统进行目标检测的开销,使系统满足实时性要求。

2.3 利用几何一致性判别动态物体
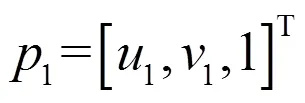
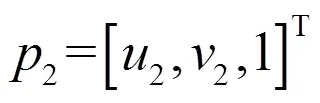
理想情况下,投影点和基础矩阵满足对极约束:

3 实验结果与分析
实验利用Turtlebot3机器人,配置为Intel E3 CPU,P2000 GPU和32 GB内存。本文SLAM系统搭建在ROS平台,分为Tracking,Local Mapping,Loop Closing,Detecting线程。在DRE_SLAM团队开源数据集上进行测试。数据集分为ST,LD和HD 3类,分别代表环境中物体运动为静止、少量物体运动和大量物体运动。数据集提供RGBD相机和编码器数据,并提供groundtruth值可对比系统运行结果和实际运动值的误差。
本系统和DS_SLAM在HD,LD和ST 3个数据集下相机位姿误差的均方根、均值和中值的对比表如表1所示。
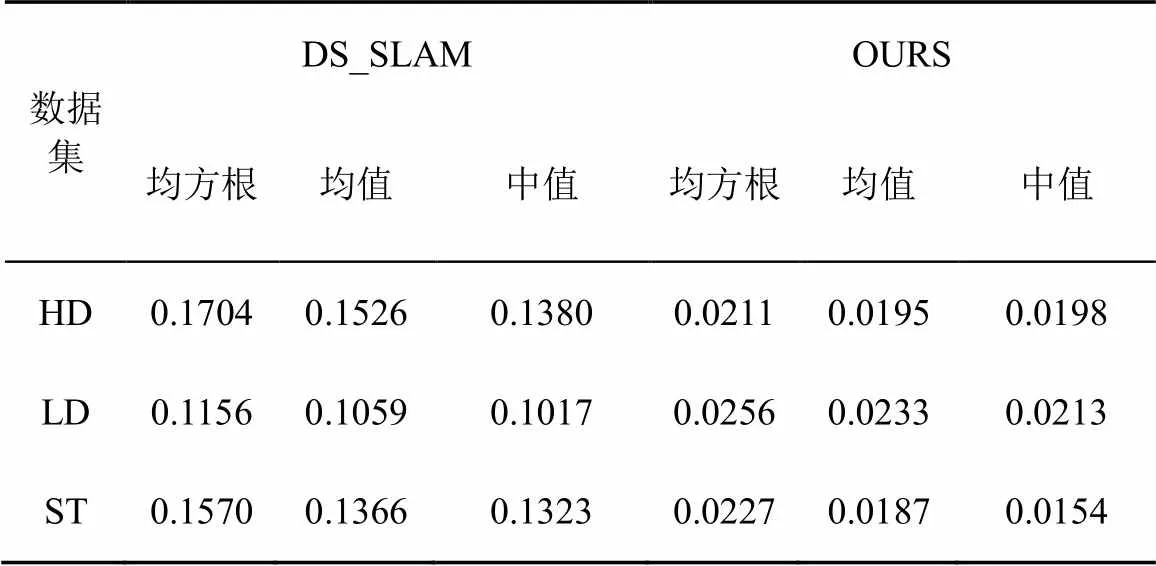
表1 本系统与DS_SLAM轨迹误差对比
由表1可看出:本系统在3个数据集下都具有更优的轨迹精度。
本系统运行3个数据集平均每个线程耗费的时间如表2所示。
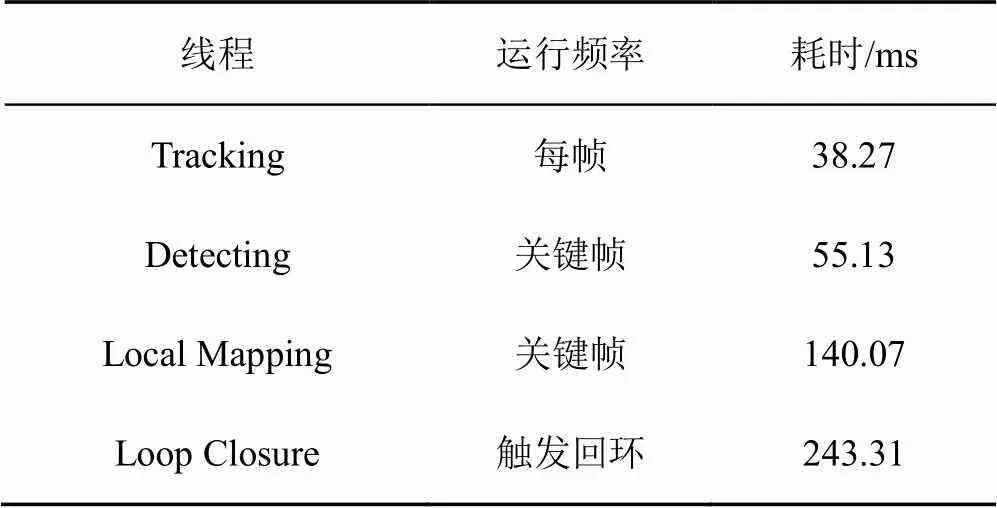
表2 本系统各线程耗时
由表2可知:目标检测线程在新关键帧产生时工作,仅耗时55 ms,确保了系统实时性。普通帧个数是关键帧的20倍左右,没有经过多视图几何优化的目标检测性能将降低近20倍,同时目标检测网络的效果可以覆盖到每一个普通帧,在关键帧频率较高情况下,有较好效果。普通帧目标检测效果图如图2所示。

图2 普通帧目标检测效果图
由图2可看出:普通帧中的动态物体基本可被识别,运动幅度较大的物体出现识别不全的情况。
4 结论
本文对动态场景下移动机器人定位问题进行讨论,利用多传感器融合解决了移动机器人在动态场景鲁棒性降低的问题,给出编码器和相机运动模型,分析2种传感器模型误差的来源,并利用非线性优化最小化误差的方式实现了传感器融合。本文的SLAM系统融合深度学习中目标检测网络,进一步排除动态物体对帧间匹配和三维建图的干扰;同时利用多视图几何法,将目标检测的效果从关键帧投影到普通帧中,缩减了目标检测线程的开销。目前系统还存在缺陷,之后的研究工作将从2方面进行优化:1)解决编码器传感器在打滑情况下,数据出现失真的问题;2)将关键帧目标检测效果重投影到普通帧后,提高目标检测的精度。
[1] CADENA C, CARLONE L , CARRILLO H, et al. Past, present, and future of simultaneous localization and mapping: toward the robust-perception age[J]. IEEE Transactions on Robotics, 2016,32(6):1309-1332.
[2] FUENTES-PACHECO J, RUIZ-ASCENCIO J, RENDÓN-MANCHA J M. Visual simultaneous localization and mapping: a survey[J]. Artifcial Intelligence Review, 2015,43(1):55-81.
[3] Tong Q, Li P, Shen S. VINS-mono: a robust and versatile monocular visual-inertial state estimator[J]. IEEE Transactions on Robotics, 2017(99):1-17.
[4] Campos C , Elvira R , JJG Rodríguez, et al. ORB-SLAM3: an accurate open-source library for visual, visual-inertial and multi-map SLAM[J]. Under review,2020.
[5] HUANG J, YANG S , ZHAO Z , et al. ClusterSLAM: a SLAM backend for simultaneous rigid body clustering and motion estimation[C]// ICCV 2019, 2019.
[6] Newcombe Richard A, Shahram Izadi, Otmar Hilliges, et al. KinectFusion: real-time dense surface mapping and tracking[C]. IEEE International Symposium on Mixed & Augmented Reality IEEE, Basel, Switzerland, 2011.
[7] SCONA R, JAIMEZ M, PETILLOT Y R, et al. StaticFusion: background reconstruction for dense RGB-D SLAM in dynamic environments[C]. 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 2018: 3849-3856.
Location and Mapping System Based on YOLO v3 and Sensor Fusion
Chen Wenfeng Zhang Xuexi Cai Shuting Xiong Xiaoming
(School of Automation, Guangdong University Of Technology, Guangzhou 510006, China)
The existing thermal wave detection technology for structural adhesive damage of glass curtain wall has some problems, such as large amount of thermal image sequence data, less effective information, low resolution and large noise. The thermal image sequence of glass curtain wall is completed by using data reconstruction of single column position, image reconstruction based on wavelet transform, image enhancement based on Wiener filter and thermal wave location based on damage area recognition rule Column processing and damage area identification. The experimental results show that: the wavelet transform technology using adaptive threshold coefficient can effectively reduce the noise components in the high-frequency components of the thermal image and retain the characteristics of the thermal image; Wiener filter uses 3 × 3 template to further smooth the image to ensure most of the important information in the thermal image; the recognition rate of the damage area is 93.7%.
sensor fusion; object detection; dynamic object; location; multi view geometry
TP830.1
A
1674-2605(2021)02-0007-06
10.3969/j.issn.1674-2605.2021.02.007
陈文峰,男,1996年生,硕士研究生,主要研究方向:移动机器人定位和建图,机器视觉。
张学习(通信作者),男,副教授,硕士生导师,主要研究方向:控制理论与控制工程,智能机器人及信息处理技术。E-mail:zxxnet@gdut.edu.cn
