基于文本分析的在线评论对产品性能提升作用探析
2021-04-23郭晓姝吴孟珊
郭晓姝,吴孟珊
(东北财经大学 管理科学与工程学院,辽宁 大连 116025)
0 引言
在大数据的浪潮下,经济形势正在不断更迭调整,数字化、信息化成为了明显趋势,在社会环境驱动力与国家机关互联网普及政策的双重影响下,电子商务成为互联网经济中的重要领域,是互联网中最大的市场。网络购物市场的快速发展,带来了极大的经济效益,同时用户生成内容(UGC)作为线上购物的衍生品数量也随之大幅增加,用户生成内容是一种大众表达观点和想法的方式,用户通过互联网和社交媒体以非营利目的参与到网络活动中,用户生成内容在网络购物市场的具体表现为用户商品评论。这些评论信息无论是对消费者还是商家来说都具有特殊的价值。
对于消费者来说,这是一种意见反馈途径,是一种实现参与互联网生活的主要方式。同时也是一种信息收获方式,可以通过了解商品质量、商品服务售后情况进行综合性考察,影响最终的购买决策。对于商家来说,商家与用户之间的互动不仅可以帮助用户进行选择,增加了用户黏性,更是一种重要的信息反馈来源,商家可以通过收集并分析在线用户评论内容对自身产品进行改进与更新,加强内部控制,增加竞争力。本文利用文本分析的方法,研究用户生成内容对产品性能提升的作用,从而验证用户生成内容的质量。
1 研究方法与数据处理
1.1 研究方法
文本分析是一种大数据时代下的新兴技术,是数字化社会的产物。指的是对文本内容进行检索挖掘并提取主要的信息,通过技术手段将文中的特征词抽取并进行量化后来表达文本内容,特征提取是其主要内容,这种技术常应用于经济领域的研究。“词袋法”是文本分析领域中较为常用的方法,其主要原理是对将不同情感倾向的词语进行分类,形成不同的词语列表,现存较为知名的文本分析系统有PEG(Project Essay Grader)系统、UEA(Intelligent Essay Assessor)系统等。在整个实验过程中,进行了数据爬取、评论预处理、模型准备、模型构建等多个步骤,使用文本分析的方法对某电子社区用户生成内容质量进行判断。
1.2 数据处理
1.2.1 数据源选择
本次实验所选取的数据均来自于某电产品子社区,因其创新研发理念较为先进,故有较高的研究价值。社区中评论的电子产品是一家近年来兴起成长速度较快、发展势头迅猛的互联网公司生产的,“创新”是该企业文化的重要组成部分,其三大创新点在于生态链、参与感和自研发收集操作系统,其中的“参与感”指向的就是用户参与研发和营销过程。该公司是国内较早开始注意用户生成内容的企业,对电子社区这样一个用户参与研发平台的发展和运营注入了极大的精力,注重内容和流量,快速形成自己的圈子和文化,收集用户反馈充分利用了社交媒体及互联网,避免了传统研发模式中的许多问题,将用户视作研发导向者,减少了企业内部人员的决策占比。因此,该电子社区中的数据能够为本次实验提供有效的数据支持,具有较高的分析价值。本次实验用选取该电子社区“圈子”中参与成员较多且性能较相似的手机A 和手机A pro 两款手机的评论进行文本分析。
1.2.2 数据获取与预处理
通过爬虫软件PyCharm 2019.3.3 爬取5 000 条该电子社区“圈子”中手机A 和手机A pro 这两款手机的评论数据,清洗评论数据中重复的数据,减小实验干扰,最后获得2 306 条手机A 相关评论,2 381 条手机A pro 的评论。
2 基于文本分析的用户生成内容建模
2.1 Snownlp 正负语料划分
Snownlp 是Python 中的一个第三方类库,用于中文文本情感分析。在过去,英文文本处理属大多数,故现存的大量自然语言处理库都是面向英文的,为了增强处理中文文本的能力,Python 开发了这样一个类库。在现实使用中,多用于对评论内容的情感分析。首先使用Sentiments 方法对已经去重后的文本内容进行正负语料划分,并分别保存,由于想同时保留建议类评论和吐槽类评论,将划分时的情感系数设定在0.8。划分结果为,手机A 正向评论数为416,负向评论数为1890,负向评论占比为82.0%;手机A pro 正向评论数为436,负向评论数为1945,负向评论数占比为82.0%,并将两款手机的负向评论重新保存成txt 文档。

表1 手机正负向评论选例
可以观察到两款手机评论的负向评论数远超于正向评论数,但这并不意味着这两款手机“差”,结合电子社区的性质来看,不同于电子商城单纯地购买评论,也不存在消费者习惯性好评的情况,其评论内容大多是用户对手机的改进建议、雷点吐槽以及提问,负向评论数多属正常现象,并且这些负向评论代表了用户期望,也更加具有研究价值,本实验以负向评论语料为研究对象。
2.2 去停用词及文本分词
2.2.1 停用词去除
为了提高搜索效率,将语料库中没有实际意义的字和词进行过滤,如连接词、语气词和副词等在文本分析中并没有实际的意义,没有分析价值,比如“者”“也”“之”“乎”等虚词,再如评论中的“品牌”“手机”等实验中特别出现的名词。本文使用哈工大停用词表为材料进行操作,去除停用词的步骤较为简单:①使用Python 读取停用词表(哈工大版);②遍历两款手机的负向语料库,将停用词表中的词语与之进行匹配,若存在相同词语,则替换为空字符。
2.2.2 中文文本分词
在本次试验中,用到的电子社区产品评论属于非结构化的中文文本内容,为了进行进一步的分析,需要将文本进行分解,主要包括将文本分割成句子、将句子分解成词语两部分。首先将文本切分成句子,在Python 第三方库中比如nltk.tokenize 和正则分词器RegexpTokenizer 等都可以实现对文本的划分。接下来将句子分割成一个个单独的词语,句子是许多词语的集合,在Python 中较为常见的两种分词系统是Pynlpir 和Jieba,本文采用Jieba 分词算法,其工作原理是基于统计词典的,在这个分词系统中可以对分词词典进行自定义以及增减等操作,并可以对已有词典进行动态的修改与维护。在Jieba 分词对分离出来的这两款手机的负向评论语料库进行分词处理。
经过以上操作后对词频进行统计,分别打印出两款手机负面评论中出现频率最高的18 个词汇,如表2 所示手机A pro高频讨论词汇和表3 所示的手机A 高频讨论词汇。

表2 手机A pro 高频讨论词汇

表3 手机A 高频讨论词汇
对比表2 和表3 中两款手机的高频讨论词汇可知,用户相同的关注点在于“显示”“系统”“更新”“屏幕”“声音”“稳定版”和“模式”方面。
2.3 模型构建
本次实验采用无监督的贝叶斯模型LDA(Latent Dirichlet Allocation)主题模型,无须人工区分测试集和训练集。将去除停用词、做过中文文本分词的两篇负向语料导入模型中进行建模分析,可以得到表4 和表5 所示结果。
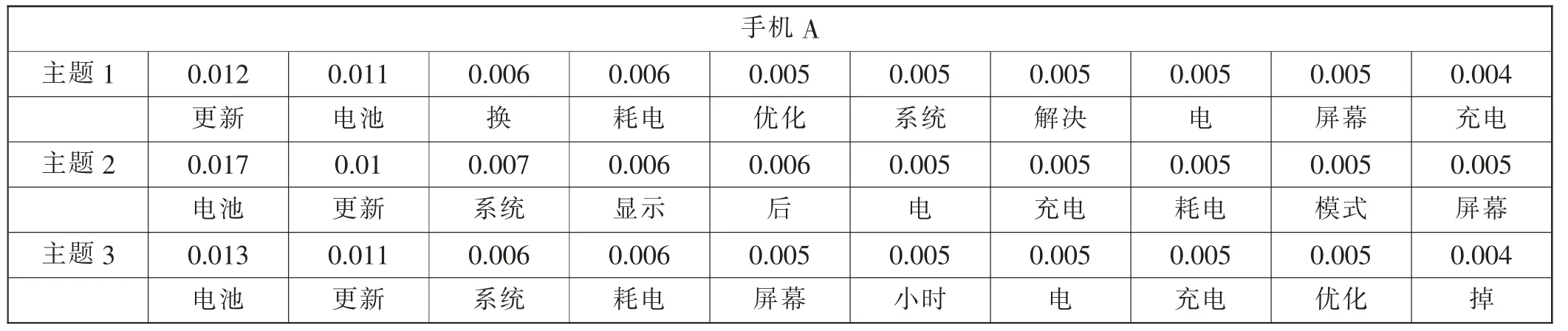
表4 手机A 模型分析结果

表5 手机A pro 模型分析结果
在本次试验中,笔者分别将两篇负向语料文档划分成三个主题,经过LDA 主题分析后,输出每个主题下生成的10 个最有可能出现的词语及其概率,即可以表示文本内容的特征词语,取每篇语料中概率相对较大的主题进行对比,展示如下。
手机A:0.017*“电池”+0.010*“更新”+0.007*“系统”+0.006*“显示”+0.006*“后”+0.005*“电”+0.005*“充电”+0.005*“耗电”+0.005*“模式”+0.005*“屏幕”
手机A pro:0.015*“充电”+0.010*“10”+0.009*“更新”+0.008*“系统”+0.006*“买”+0.006*“解决”+0.006*“后”+0.005*“显示”+0.005*“知道”+0.005*“王者”
对两款手机的特征词语进行比对后可以明显观察到,用LDA 主题模型分析所得的手机A 和手机A pro 的用户生成内容相似性较大,在手机A 负向用户评论中出现频率为0.010 的“系统”“更新”同样以0.009 的频率出现在手机A pro 的负向评论中;手机A 中出现频率为0.007 的“系统”,“系统”也以0.008的频率出现在手机A pro 中;手机A 中出现频率为0.006 的“显示”也以0.005 的频率出现在手机A pro 中;手机A 中出现频率为0.005 的“充电”在手机A pro 中的出现率甚至有提高,频率达到了0.015。除此之外,“充电”“电池”和“耗电”三个词可统一看作是用户对电池系统的建议或吐槽,在两款手机负向评论中出现频率也都相对较高。特征词语的相似度较高,说明两篇负向语料文档的相似度也较高,可以推理出手机A 和手机A pro存在着相似亟待解决的问题。虽然用户在使用手机A 过程中出现的问题并未有效地在手机A pro 中得到完全解决,但是也有部分性能有所提高,分析其原因,笔者认为该公司对用户评论的采纳度不够,或用户需求没有得到实质性的满足,总体用户生成内容有效性不高。电子产品的新一代的更新并不是所有性能都会改进,一般会在某一方面着重改进,这种改进是逐步细微的。
3 研究结果分析
本文以某电子社区为例,研究了用户生成内容对产品性能的影响,发现企业虽然重视社区中顾客对产品的评论,但是对用户评论的采纳度还并不足,综合各方面因素分析原因如下。
3.1 人工阅读用户评论效率低下
电子社区中,有用户间的交流,也有产品、技术和客服与用户的交互,目标是及时听取和吸收用户的意见。这一行为使得该公司在用户群体中收获了较好的口碑,在线沟通的方式体现了对用户的尊重,也存在人工阅读效率相对较低的问题,该电子社区有大量的用户基础,数十万的活跃用户每天都会产生大量的用户评论,而相关团队人员构成有限,若只让他们对成千上万条用户评论进行人工阅读显然是低效率的,仅凭借人工浏览的方式,会使得公司不能够准确地了解到用户们最为关注的产品特征,难以有效地进行收集反馈,从内容中识别用户需求,进而来对产品进行改进。
3.2 研发目标与用户需求未能统一
除了用户期望,研发工作也要符合公司对自身企业发展的规划。电子产品的新一代的更新并不是所有性能都会改进,一般会在某一方面着重改进,这种改进是逐步细微的。如今社会的进步使得5G 手机成为了近来的热点之一,不断吸引着消费者的注意。随着5G 网络的逐渐普及和5G 商用牌照的发放,各大手机厂商纷纷进行跟随潮流进行研发并推出自家的5G 手机,手机A pro 最大的卖点宣传也是定位在性价比较高的5G手机,在研究和开发5G 匹配功能的同时,可能难以对用户需求进行全面的满足。
4 结语
在互联网新时代下,自媒体的发展,用户生成内容海量增加,鲜明的褒贬性以及用户对产品的主观态度都在这些内容中得到体现。面对这些海量的用户生成内容,各组织机构都应给予足够的重视,致力在最短的时间内取得更加全面的用户反馈信息,并采取一定的改进措施。对大量评论数据进行分析后,总结出企业现阶段对用户生成内容应用还不够充分,可能存在人工阅读用户评论效率低下、研发目标与用户需求未能统一等问题,提出可使用文本分析手段进行总体研究、研发工作从局部到整体逐步满足客户需求等合理建议。本文存在着一些局限性,实验中使用的模型还较为单一,没有进行多种模型结合的创新性方法等;研究对象较少,由于其他款式的手机关注度较低,评论量较少,无法作为有效的参考数据,故只选取了两款手机进行比对,无法做出连续的比较。今后将增加数据量,进一步研究用户生成内容对产品性能提升的作用机制。
