深度复合模型下的土壤重金属含量预测
2021-04-22曹文琪
曹文琪,张 聪
(武汉轻工大学 数学与计算机学院,湖北 武汉 430023)
0 引 言
我国目前的土壤重金属污染情况十分严峻[1],对未知区域的土壤重金属含量进行预测是土壤重金属污染治理过程中重要的一环。随着人们对神经网络的研究逐渐深入,径向基神经网络(RBFNN)在数据预测方面的应用越来越多,它相较于常见的BP神经网络具有更好的泛化能力,同时其本身具有收敛速度较快、全局逼近能力强等特点[2]。但由于RBFNN隐含层基函数的中心与宽度向量难以确定,以及其输出层参数的初始化方式通常为随机生成且使用梯度下降法进行训练,往往导致网络的性能不稳定,训练结果易陷入局部极小值[3,4]。将遗传算法与RBFNN进行结合后可以有效避免由变量的初始随机化生成导致的性能不稳定问题,但易陷入局部极小值及遗传算法本身存在的易过早收敛等问题仍未得到较好的解决[5]。本文提出一种深度复合模型(DCM),该模型将加入了基于双曲正切函数变换的概率调整和容忍准则的遗传算法与RBFNN结合以获得更好的初始输出层参数,同时构造随梯度正负值变化的学习率调整公式并引入到均方根反向传播算法(RMSProp)中,用于对RBFNN中的参数进行训练,以此克服遗传算法与RBFNN的传统缺陷,使模型在进行土壤重金属含量预测时具有较高的稳定性与准确性。
1 遗传径向基神经网络(GA-RBFNN)
GA-RBFNN是将遗传算法与径向基神经网络结合起来的一种网络[6,7],该网络首先以径向基神经网络中的参数作为遗传算法中种群的个体,然后使用遗传算法对种群中个体进行迭代寻优,寻优过程结束后将种群中适应度最好的个体赋值给RBFNN作为其参数的初始值然后进行训练,通过此方式避免由传统参数初始化的随机性带来的网络性能不稳定的问题,使得参数初始值更符合网络需求以达到较好的训练结果。
1.1 遗传算法(GA)
GA是一种借鉴生物进化理论,仿照生物的多代遗传过程的随机搜索算法,它以目标问题的不同解作为不同的个体生成种群,然后对种群进行选择、交配、变异操作来寻求最优个体以实现对目标问题的求解[8],其主要算法步骤如下:①编码生成种群个体,编码方式一般为实数编码或二进制编码;②计算种群个体适应度值;③选择操作,选出种群中适应度较高的个体,一般使用轮盘赌方法进行选择;④交叉操作,根据交叉概率对经过选择后的种群个体进行个体间基因片段的交换,交叉概率一般为固定值;⑤变异操作,根据变异概率对经过选择后的种群个体进行基因片段的改变,变异概率一般为固定值;⑥重复步骤③到步骤⑤,当达到最大迭代次数或满足停止条件后停止迭代,然后输出种群中的最优个体。
1.2 径向基神经网络(RBFNN)
RBFNN是一种具有较强映射功能的三层前向网络[9,10],其隐含层通过径向基函数对输入数据进行非线性映射,然后将隐含层的输出数据通过线性计算传递至输出层进行输出,该网络已被验证是具有最优映射的前向网络。径向基神经网络的结构如图1所示。

图1 RBFNN结构
RBFNN对数据的训练过程主要分为两个部分,一个部分是无监督学习,即使用K-means算法对输入网络的数据进行聚类,通过此方式生成隐含层径向基函数的中心点与宽度向量,且径向基函数一般选择高斯函数,宽度向量的计算公式如下
其中,cmax为中心点之间的最大距离,h为节点数。
之后输入数据分别经过隐含层、输出层进行相关计算,输入样本xi在隐含层的第j个节点的输出由以下公式计算得出
其中,cj与σj分别为隐含层第j个节点的中心点与宽度向量。
输入样本xi在输出层的第m个节点的输出由以下公式计算得出
ym=φ(φ(xi,j)*ωm)
其中,ωm为该节点的权值,φ为激活函数。
另一个部分是监督学习,即通过误差函数计算出每个参数的梯度值,然后使用传统梯度下降法如随即梯度下降法(SGD)对权值进行不断修正的过程,具体的更新公式如下
其中,E为误差函数,μ为学习率。
除上述方法外,还可直接随机生成隐含层的中心点与宽度向量,之后按照监督学习过程的梯度修正公式对其进行更新。
2 深度复合模型(DCM)
2.1 基于自我学习的遗传算法(ALGA)
2.1.1 种群个体生成
传统GA中,种群个体由实数编码生成之后,通常以一维向量形式对个体进行保存并以此种方式进行遗传操作,由于一维向量形式的个体在操作过程中基因片段的被选择性较高,因此容易导致进化过程中重要基因片段的改变,另外由于数值的生成在一定范围内,导致搜索范围过小,也难以寻得全局最优值[11]。
针对上述问题,在进行个体生成过程中进行以下改进:
首先对个体的保存形式进行改进,将个体的保存形式与所求目标的形式相匹配,有效降低重要基因片段的被选择性。例如将本算法用于生成RBFNN的权值、阈值时,它们在RBFNN中的形式为实数数组,形状分别为8*1与1*1,因此遗传算法种群个体应为实数数组形式,且是由形状分别为8*1和1*1的两个小数组并列组合的大数组,相关遗传操作将以小数组为基本单位进行。通过此方式以避免进化过程中重要基因片段的丢失,同时简化计算过程。
另外初始化生成种群个体时,在每个种群个体的周围生成一定数量的小种群,然后计算出小种群中适应度值最高的个体,并将此个体作为种群的新个体,所有小种群中适应度值最高的个体组合而成的种群将替代初始化生成的种群并进行之后的遗传操作。上述操作可以避免种群个体之间的分布过于密集,同时尽可能多地在可行域内进行搜索,增加个体的多样性。
2.1.2 自适应概率调整
在种群的交叉与变异过程中,交叉概率与变异概率一般设为固定值,并由此固定值决定选择的个体是否进行交叉与变异操作,但此方式未对个体本身的适应度值大小进行充分考虑,若个体本身适应度值较高而进行了交叉与变异操作时,容易导致操作后的个体适应度值反而较操作前有所降低[12]。针对这一情况,本方法提出一种自适应概率调整方式来决定交叉与变异概率的大小,具体点调整公式如下
其中,f为当前个体的适应度值,fmax与fmin分别为当前种群个体中的最大适应度值与最小适应度值,pm为一固定值,范围处在0.5到1之间。在上述公式中,φ(x)为双曲正切(tanh)函数,当x取值在0到1之间时,φ(x)为值域约在0到0.76之间的单调递增函数,能够保持较好的平滑性。
由于此算法的目标是搜索范围内适应度值最高的个体,因此在对自适应概率进行确定时,个体适应度值的比较目标为当前种群个体中最大适应度值的一半,在此称其为一般适应度值。当个体适应度值低于一般适应度值时,交叉与变异概率将取一个较大值,通过更多的交叉与变异机会来提高个体的适应度值,而当个体适应度值高于一般适应度值时,交叉与变异概率随着适应度值的增大而不断减小,当个体适应度为种群中最高适应度值时,个体不进行交叉与变异操作,以此来避免进化前后个体适应度值有所降低的情况发生。
2.1.3 容忍准则
由于遗传算法在迭代过程中,目标是保证适应度较优的个体基因被遗传至下一代,因此容易朝着单一的极值点方向进化,从而陷入局部最优状态。为避免陷入局部最优,本方法在种群个体进化后增加新旧个体的适应度比较环节中,提出容忍准则来判定个体是否接受此次进化过程,该准则中以概率p作为是否接受进化过程的标准,具体的计算公式如下
其中,fnew为新个体适应度,fold为旧个体适应度,T为迭代后适应度下降连续出现的次数,T的初始值为0。当出现迭代前后适应度值连续降低的情况,则使用以下公式对T进行更新
T=T+1
p随T值变化的曲线如图2所示。
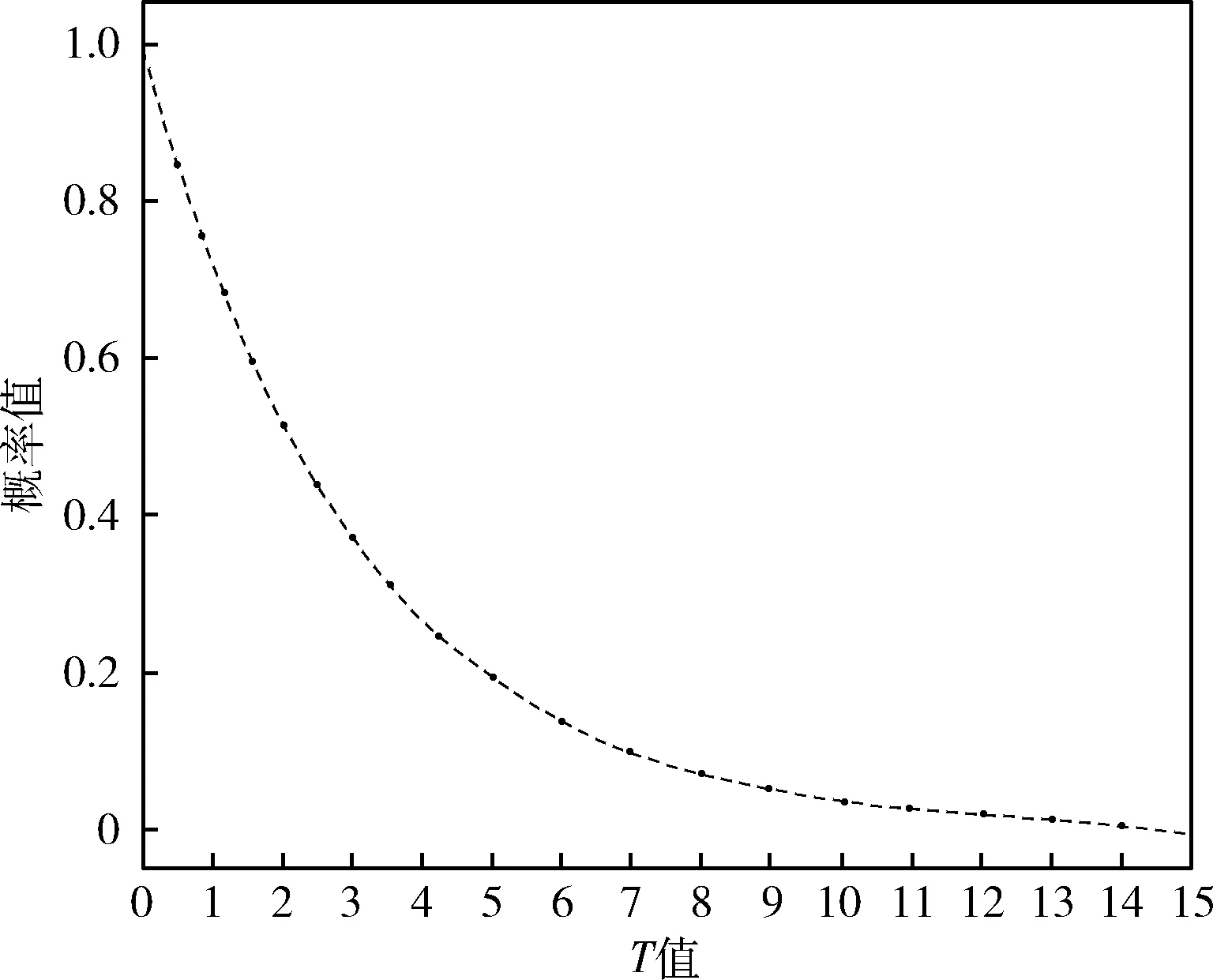
图2 概率p变化曲线
当连续几次迭代下适应度值均出现降低或不变的情况时,T值将不断增加,在连续次数较少时,并不能代表已经陷入了局部最优,因此此时仍有较大概率接受进化结果,而随着连续次数的增多,陷入局部最优的可能性也随之增大,因此接受进化的可能性也随之降低直至为0。当个体未接受进化时,个体将恢复到上一次的状态重新进行遗传算法的相关操作,直至迭代前后适应度值增加的情况出现,此时个体将直接接受进化之后的状态,T值也将再次初始化为0。
2.2 基于自适应监督学习的径向基神经网络(SRBFNN)
2.2.1 变量修正方式调整
在传统RBFNN中,隐藏层的中心点与宽度向量由K-means聚类生成,通常生成后不再通过监督学习进行调整,但由于聚类的过程具有一定的随机性,因此生成的中心点不一定为最优值[13],考虑到这一情况,在RBFNN的监督学习过程中加入对中心点与宽度向量的调整,调整方式与权值、阈值相同。
而在遗传算法中,由于初始生成值具有一定的随机性,若使用其对中心点与宽度向量进行生成,则会增加算法的计算复杂度,容易导致训练结果的误差增大。
因此将在本方法中对所有变量的修正方式调整如下:在RBFNN的无监督学习过程中,使用K-means算法生成RBFNN隐含层的中心点与宽度向量,使用遗传算法生成RBFNN输出层的权值和阈值,而在之后的监督学习过程中,对隐藏层的中心点、宽度向量、输出层的权值、阈值4种变量同时进行更新。
2.2.2 自适应均方根反向传播算法(SRMSProp)
在传统RBFNN的监督学习过程中,通常采用梯度下降中的随机梯度下降法(SGD)来对变量进行更新,即以学习率乘以梯度值作为更新值,这一方法容易导致梯度值陷入局部极小值,在目前的优化算法中均方根反向传播算法(RMSProp)可以有效加快算法收敛速度,避免陷入局部极值,但该算法并未考虑到迭代过程中梯度值发生正负变化这一情况,通常使用固定的学习率作为学习步长[14],容易导致每次迭代优化结果的波动性较大,收敛速度较慢。
本文提出的自适应均方根反向传播算法(SRMSProp)考虑到迭代过程中梯度发生正负值变化时,已经跳过了梯度值为0的点,因此在下一次调整过程中,不仅需要对学习方向进行调整,同时学习步长也应有所降低,而当前后两次迭代梯度的正负值未发生变化时,说明距离极值点较远,因此学习步长需要有所增长。
具体的算法步骤如下,以第t次迭代中权值w的更新为例:
(1)对w进行临时更新,并计算更新后的梯度gt,更新公式为
w′=wt+α*vt-1
其中,α为动量系数,vt-1为上一次迭代更新值,初始值为0。
(2)计算累计梯度平方r,计算公式如下
rt=ρ*rt-1+(1-ρ)*gt
(3)计算学习率,公式如下
其中,st为累积梯度值,初值为0,μ0为固定值,即若迭代前后梯度正负值发生变化,则学习率减小,反之则学习率增大,另外随着迭代次数的增大,st不断增大,则学习率的变化不断减小。
(4)对w进行更新,公式如下
wt+1=wt+vt
2.3 深度复合模型的建立
在上述方法的基础上,建立深度复合模型,建模步骤如下:①初始化小种群,生成小种群最优;②小种群赋值大种群,计算适应度;③选择、交叉、变异操作;④使用容忍准则判断是否接受更新;⑤重复过程③和④,满足停止迭代条件或达到最大迭代次数时输出最优个体;⑥最优个体赋值RBFNN的权值、阈值;⑦K-means聚类生成RBFNN的中心点与宽度向量;⑧前向计算;⑨使用SRMSProp算法进行监督学习;⑩重复过程⑨和⑩,满足停止迭代条件或达到最大迭代次数时训练结束。
具体的流程如图3所示。

图3 DCM流程
3 实验与分析
3.1 实验数据
实验数据选用武汉市6个新城区的农田土壤重金属含量数据,该数据由武汉市农业科学院严格依照《土壤环境监测技术规范》,根据作物分布、土壤类型等信息定点采样获得。整理后选用500组数据作为训练数据,20组数据作为测试数据,其中经度、纬度、海拔、作物类型4项指标作为网络的输入值,重金属As含量作为目标值。
对数据进行归一化处理的公式如下
PN=(P-Pmin)/(Pmax-Pmin)
其中,P为原始数据,Pmax与Pmin分别为原始数据中的最大值与最小值。
3.2 实验一及结果分析
在传统RBFNN中,除K-means生成中心点与宽度向量外,还可随机生成中心点与宽度向量后再对其进行调整,为了比较两种方法的优劣性并判断变量修正方式中对隐含层与输出层的全部变量进行更新是否能取得更好的优化效果,将随机生成中心点与宽度向量并对全部变量进行更新的RBFNN(简称RBFNN1),由K-means生成中心点与宽度向量,但仅更新输出层的权值、阈值的RBFNN(简称RBFNN2)以及由K-means生成中心点与宽度向量并且对全部变量进行更新的RBFNN(简称RBFNN3)进行对比实验。
实验中训练方法采用SGD方法,学习率设置为0.01,激活函数选用tanh函数,隐含层节点数设置为8,迭代500次后,3种变量修正方式下的网络损失值的变化情况如图4所示。

图4 损失值比较
如图4所示,代表RBFNN1与RBFNN3的曲线在前期就快速降到一个较低水平,说明它们的损失值在迭代次数少于50次时能够快速收敛到一个较低值,而代表RBFNN2的线的前期变化较另外两个更为平缓一些,但在迭代70次左右之后,损失值的大小基本不变,由此可见这3种方法的梯度值都能快速下降。将RBFNN1的损失值变化情况与RBFNN3相比,RBFNN1在最初几次迭代时较RBFNN3表现更好,但此情况的发生可能是因为RBFNN1中初始化的参数值较好,它的出现具有不稳定性,而在迭代约10次之后,RBFNN3的收敛速度与收敛精度较RBFNN1表现更好,说明RBFNN3的实际性能优于RBFNN1。比较迭代后期3种不同的方法下损失值的变化情况可以发现,代表RBFNN3的曲线最早到达较低点,其位置明显低于另外两条曲线,直至迭代500次时,RBFNN3的损失值依旧低于另外两种方法。因此可以得出结论,采用由K-means生成中心点与宽度向量并且对全部变量进行更新这一变量修正方式对RBFNN进行训练,训练结果更优。
3.3 实验二及结果分析
为验证深度复合模型(DCM)的有效性,将其分别与遗传径向基神经网络(GA-RBFNN)、径向基神经网络(RBFNN)、BP神经网络(BPNN)、多元线性回归(MLR)4种方法建立的模型进行土壤重金属As含量的预测对比实验。
实验二的参数设置中,除实验一出现的参数外,将大种群数设为60,小种群数设为10,最大自适应交叉概率设为0.7,最大自适应变异概率设为0.07,衰减速率设为0.9,动量系数设为0.1。不同模型的As含量预测值与真实值对比图分别如下。
首先将图5与图6进行对比观察,可以看出图6中实线代表的真实值与虚线代表的预测值的走势较图5更为接近,且图6中实线的走势与虚线基本一致,部分线出现了重合,说明使用BPNN模型进行预测的结果比MLR模型更好。然后对比图7与图6可以看出,图7中实线与虚线重合的预测点较图6有所增加,说明RBFNN模型预测效果较BPNN模型有所提高,但部分预测值与真实值之间仍存在较大差距,预测效果依旧有待提高。
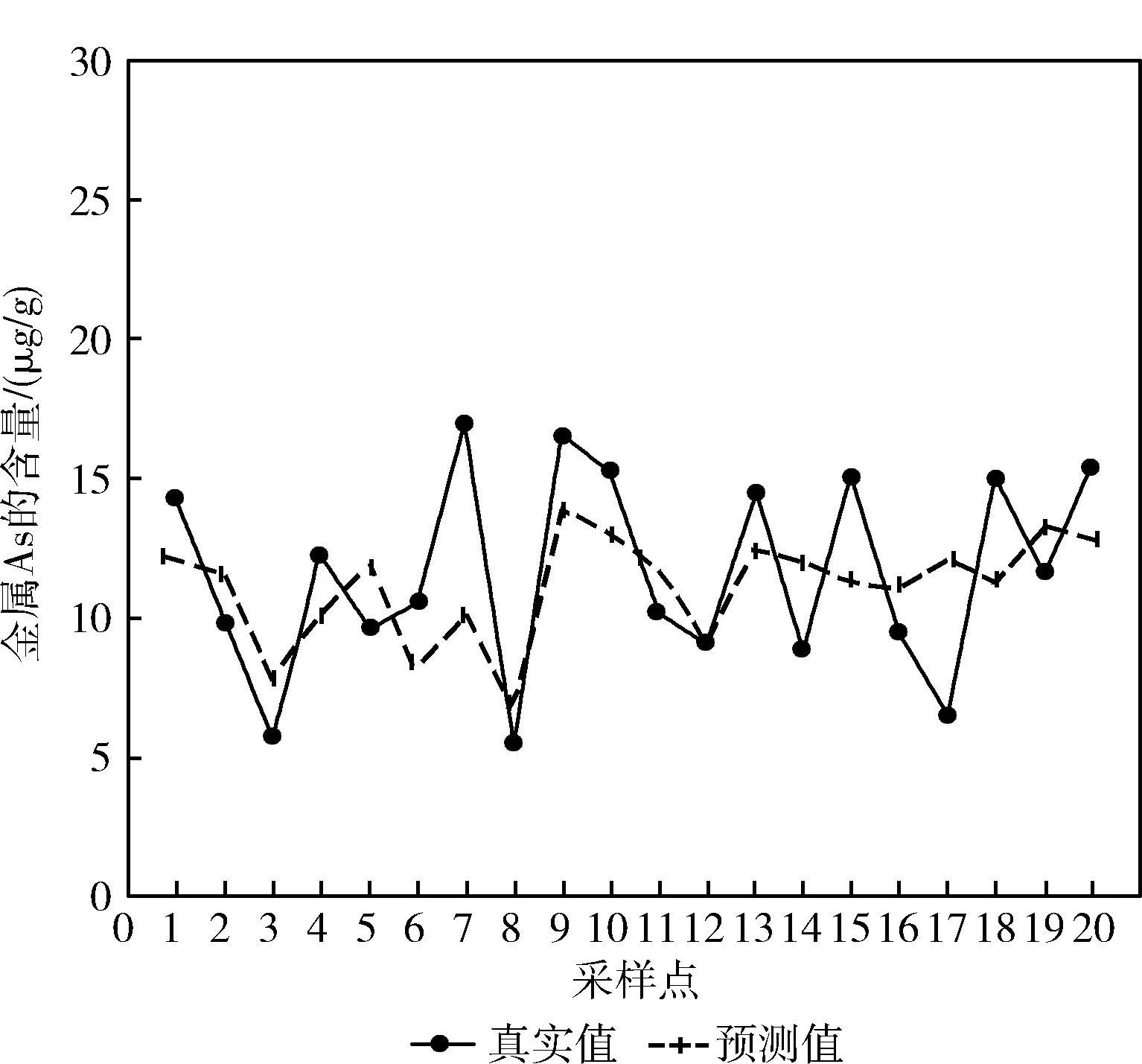
图5 MLR模型As含量预测对比

图6 BPNN模型As含量预测对比

图7 RBFNN模型As含量预测对比
将图8与图7进行对比观察,整体上两张图中代表预测值的虚线与代表真实值的实线之间差距的区别不够明显,只有少数几个点的差距更小,说明在使用GA-RBFNN进行预测时,预测点的预测值与真实值之间的差值要略小于RBFNN,而将图9与图8、图7相比时,可以看到图9中实线与虚线之间的重合度明显提高,并且大部分预测点的预测值与真实值基本重合,说明图9代表的DCM预测模型较另外几种对比实验模型的预测值更为接近真实值。

图8 GA-RBFNN模型As含量预测对比
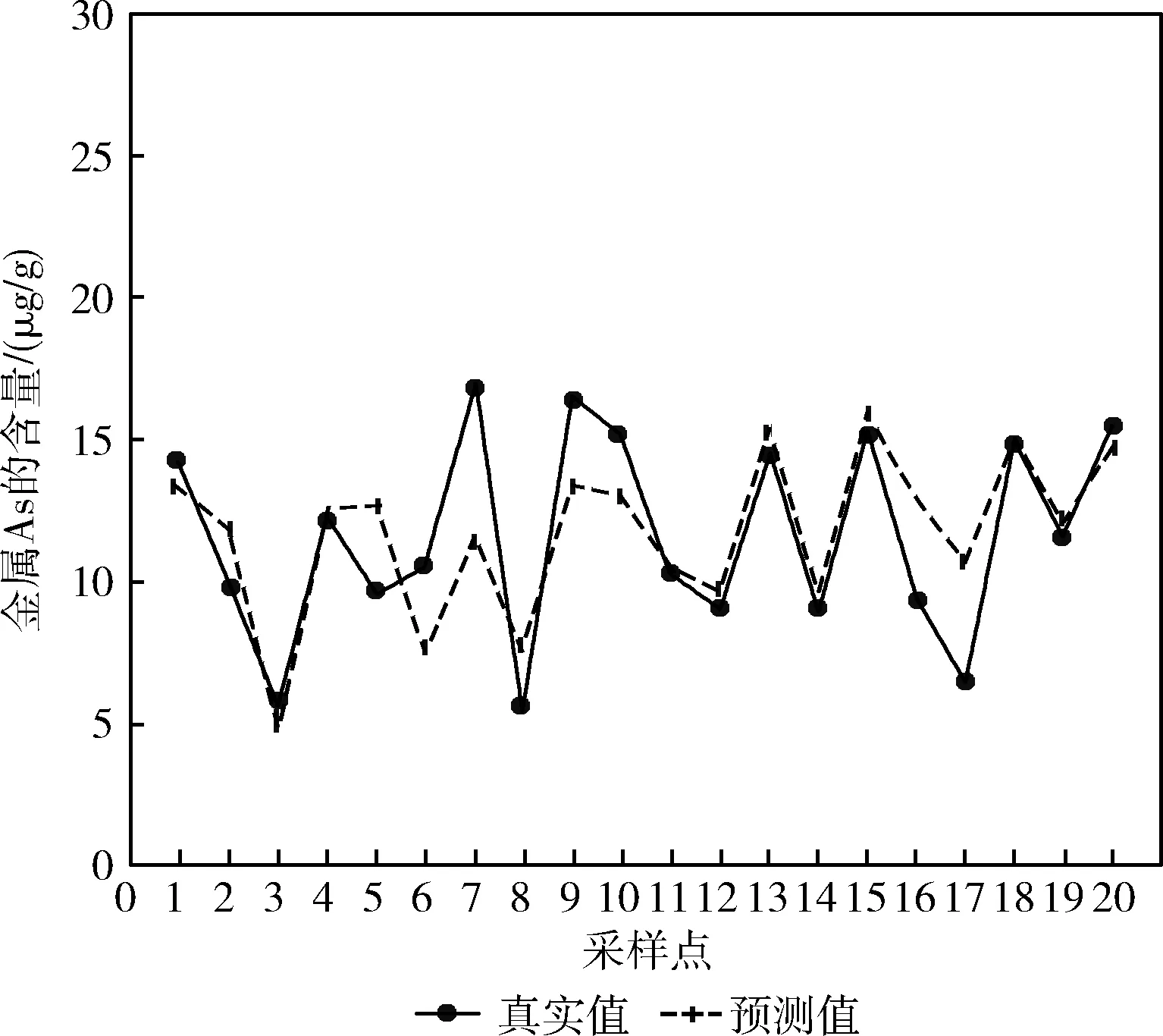
图9 DCM模型As含量预测对比
为了更加清楚地了解5种模型的预测结果中预测值与真实值之间的差距,将分别计算出使用5种预测模型进行预测时,每个预测点的预测值与真实值之间的差值,然后求出该差值与对应采样点真实值的比值大小,最后统计在不同的比值区间内5种预测模型的20组预测点分布的数量并绘制直方图。绘制完成的直方图如图10所示。

图10 不同模型中预测点的差值分布
如图10所示,MLR、BPNN、RBFNN这3种模型中预测差值与真实值比值小于20%的点约占预测点总数量的一半,MLR与BPNN中预测差值与真实值比值小于20%的点的数量相同,RBFNN中该区间的点的数量与这两种模型相比有所增加,但增加数量较少,结合图5、图6和图7可以说明,使用这3种预测模型进行预测时,它们预测值与真实值之间的差距较为接近,它们的预测效果为RBFNN优于BPNN,BPNN优于MLR。GA-RBFNN与DCM中预测差值与真实值比值小于20%的点较另外3个模型均有所增加,说明这两种模型的预测效果优于前面3种模型,而观察DCM的点的分布可以看出,该模型中预测差值与真实值比值小于10%的点占总数量的一半,小于20%的点的数量占总数量的75%,明显高于其它几组模型,结合前面的预测对比图可以看出,DCM模型的预测值与真实值之间的差距较另外4种模型更低,预测效果更好。
除上述将预测值与真实值进行对比以及统计样本点的预测差值与真实值的比值的分布外,还使用平均绝对误差(MAE)、均方误差(MSE)、平均绝对百分比误差(MAPE)3项指标对5种模型的预测效果进行评估,这3项误差指标的计算公式分别如下

如表1所示,5种模型的20组数据的预测结果误差对比中,5种模型的3项误差指标值依次递减,其中MLR、BPNN、RBFNN这3种模型的平均绝对误差与均方误差均在2与6以上,GA-RBFNN模型与DCM模型的平均绝对误差与均方误差均分别2与6以下,但GA-RBFNN的误差指标值与RBFNN较为接近,而DCM模型的3项误差指标与前4种模型的误差指标相比,下降幅度最为明显,3项误差指标较MLR的降低值分别约为0.8、3.7、7%,表明5种预测模型中,DCM的预测结果误差最低。

表1 预测结果误差对比
综合以上图表分析可以得出结论,在MLR、BPNN、RBFNN这3种模型中,使用RBFNN模型进行土壤重金属含量预测时,预测准确性最高,在使用遗传算法对RBFNN进行优化后,GA-RBFNN的预测效果较RBFNN有较小提升,而与其它4种预测模型相比,使用本文提出的DCM模型进行土壤重金属含量预测时预测效果最好。
4 结束语
本文提出一种深度复合模型(DCM)用于土壤重金属含量预测,该模型采用基于自我学习的遗传算法(ALGA)来生成RBFNN输出层的参数,然后使用自适应均方根反向传播优化算法(SRMSProp)对RBFNN的所有参数进行优化修正,通过这两种算法来加快RBFNN的收敛速度,获得更高的预测精度。将本模型与MLR、BPNN、RBFNN、GA-RBFNN模型进行预测对比实验,本模型的预测值与真实值更为接近,预测效果更好,可以为土壤重金属含量预测提供一种新的方法。对本方法进行更多理论学习,将其应用到更多实际问题上,是接下来需要进一步考虑的问题。
