联合相位谱补偿优化的幅度谱掩蔽语音增强
2021-04-22张存远马建芬张朝霞
张存远,马建芬+,张朝霞
(1.太原理工大学 信息与计算机学院,山西 晋中 030600;2.太原理工大学 物理与光电工程学院,山西 晋中 030600)
0 引 言
语音增强的目的是将目标语音与噪声干扰区分开。为解决传统单声道语音增强算法存在残留噪声的问题,多名研究者提出了基于监督性学习的语音掩蔽增强[1-5],常见的DNN掩蔽估计目标有:理想二值掩蔽(IBM)[6]、理想比例掩蔽(IRM)[7]等,这些传统的掩蔽算法仅增强语音的幅度谱而不考虑语音的相位信息。虽然这些方法能够显著抑制噪声[8],但是近年研究发现[9],当仅增强相位谱并且保持噪声幅度不变时,可以有效地提升语音质量。为此,Williamson等提出了复数域理想掩蔽算法(cIRM)[10],但该方法没有做到直接对相位估计,仅能转换到复杂的直角坐标系中计算短时傅里叶变换后(STFT)的实部和虚部,同样的相敏掩蔽(PSM)[11]可以简单概括为cIRM的实部,这些方法不能直接处理非结构化特性的相位谱,且计算复杂影响其效率。近年,Zhang等指出相位谱补偿方法(PSC)可以有效地修正相位谱信息[12],能够大幅度提高语音质量。但其参数固定无法适应非平稳噪声的能量变化,且未能结合监督性学习。
因此,在本文中我们提出了一种基于多目标深度神经网络的相位谱补偿和语音掩蔽联合估计的语音增强算法,通过优化传统相位谱补偿函数,使其更适合作为训练目标,同时达到直接估计相位的目的。为了能够提升相位谱补偿适应噪声能量的波动,在其系数中添加SNR特性。具体的,本文将改进的相位谱补偿和幅度谱掩蔽共同作为训练目标,进行联合训练,所训练的网络同时包含相位谱和幅度谱信息,将得到的网络进行语音增强。通过实验对比,进一步探讨本文方法的性能。
1 基于相位谱增强的训练目标重建
语音增强的目标是在给定含噪语音信号的情况下,估计出干净语音信号。假设x(n) 表示为干净语音信号,z(n) 表示为噪声信号,且x(n) 和z(n) 相互独立,则含噪语音信号表示为y(n), 有
y(n)=z(n)+x(n)
(1)
对于干净语音、噪声信号和含噪语音,其相应频谱的时频单元表示为X(k,l)、Z(k,l) 和Y(k,l)。 其中X(k,l) 表示干净语音信号的第k帧位于频带l的频谱分量。将其表示在极坐标上,可以分解为幅度谱和相位谱
X(k,l)=|X(k,l)|ejθx(k,l)
(2)
式(2)表明,x(n) 经过STFT之后得到该信号的短时幅度谱 |X(k,l)|, 和该信号的短时相位谱θx(k,l)。 本文主要致力于极坐标上幅度和相位联合的语音增强,在极坐标上能够直接表示其幅度和相位的关系,其中幅度谱具有清晰的结构,在语音增强中的应用十分受欢迎,而相位谱却十分杂乱,但却十分重要不可忽视。
1.1 相位谱补偿函数的提出
虽然相位信息可以提高语音的感知质量,但由于相位卷绕[13],相位谱呈现为高度非结构化特征,我们很难通过现有的方法直接对相位进行估计。现有方法通常将极坐标域转换到由实部与虚部构成的直角坐标域上计算,无法直接对相位谱修正且造成了系统的冗余。Paliwal提出了相位谱补偿算法(PSC)可以通过噪声的特性对含噪语音的相位进行修正,相位谱补偿函数可以表示为

(3)
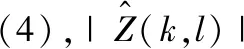
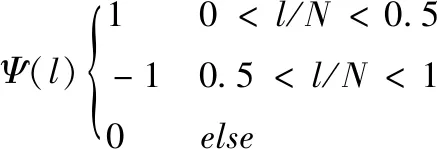
(4)
1.2 改进的相位谱补偿函数
为克服相位谱非结构化特性和传统PSC在修正相位的问题,本文提出将信噪比(SNR)作为影响相位谱补偿的因素之一[14],我们知道语音信噪比能够影响干净语音和含噪语音的相位差。本文对该方法进行改进,将补偿因子结合SNR构建新的相位谱补偿因子,则相位谱补偿函数的表达式为式(5)所示。其中c为固定值设置为2.7
(5)
由式(5)可以看出如果当前单元为语音单元,则SNR值增加,补偿因子减小,则相位谱补偿函数对含噪语音的影响降低,且满足上述提到的SNR较大相位的可靠度高。
为此本文分别将提出的新的补偿因子和传统补偿因子结合含噪语音的幅度谱进行语音增强,如图1所示,图1(a)为传统的PSC,图1(b)为改进的PSC,可见改进的PSC保留了更多的语音细节,语音较噪声能量更加突出,更适合作为网络的训练目标,同时抑制噪声的能力也比传统强。将其二者进行客观评价,改进的PSC得到了比传统PSC更高的评分。

图1 不同补偿因子的比较
1.3 训练目标的提出
以上本文提出了基于SNR改进的相位谱补偿因子,为了方便网络的估计,将式(5)中相位补偿函数Λ(k,l) 写作式(6)
Λ(k,l)=Ψ(l)×Q(k,l)
(6)
在网络训练的时候,我们将此参数Q(k,l) 设置为训练标签,为了呼应网络输出层sigmoid函数取值在0和1之间,需要将Q(k,l) 进行归一化记为ΩZ。 在Q(k,l) 中包含了噪声信号的能量和干净语音的能量,该参数容易获得且计算简单,将Q设定为网络的训练目标,简化了训练难度。将训练好的参数结合频带数恢复Ψ(l), 即可计算出相位谱补偿。在相位谱补偿函数中Ψ(l) 主要作用是产生一个反对称函数,如式(4),用于对相位的修正,在语音合成中可以起到抵消噪声的因素。Λ的作用如式(7)所示
YΛ(k,l)=Y(k,l)+Λ(k,l)
(7)
式中:YΛ为补偿后的频谱,通过对补偿后的频谱进行相位的提取,得到式(8)为补偿后的相位谱∠YΛ, 其中arg(·) 表示提取相位的复数幅角函数,通过该函数的反变换即能得到修正后的相位谱
∠YΛ(k,l)=arg(YΛ(k,l))
(8)
新建的PSC是网络训练中训练目标之一,通过网络的训练计算出最优的补偿参数的值。为验证该方法结合DNN重构相位的有效性,将联合幅度谱掩蔽进行语音增强。
2 基于DNN的相位谱和幅度谱联合估计
2.1 相位谱补偿联合幅度谱估计
为了能够弥补传统幅度谱掩蔽在增强阶段相位合成的问题,本文提出了基于DNN的相位谱补偿联合幅度谱估计的语音增强算法。将相位谱补偿以及幅度谱掩蔽作为网络的训练目标,以提升语音质量和语音可懂度。联合估计的实验框架如图2所示。它包括两个部分:训练部分和增强部分。本文将在训练部分介绍:特征提取、训练目标的构建以及代价函数的定义。在增强部分介绍:语音的合成及测试。

图2 基于相位谱补偿的深度学习语音增强算法
2.2 相位谱幅度谱掩蔽的多目标DNN
本文的训练目标分为相位谱和幅度谱,上章介绍了以PSC为训练目标的相位谱修正,在本节中我们将介绍以幅度谱掩蔽为训练目标的幅度谱修正。
归一化的PSC具有和幅度谱掩蔽相似的形式,我们发现将幅度谱和相位谱同时作为网络训练的目标,测试语音就能根据训练好的网络得出目标相位和幅度。由于传统的深度神经网络(DNN)不能很好同时估计双分类问题,本文将采用多目标神经网络,如图3所示。多目标DNN输出层分为两个子层,一个用于估计干净语音的幅度谱,另一个用于估计对应的相位谱补偿。输出层中的这种Y形网络结构通常用于联合估计相关目标,并且在这种情况下,它有助于确保从相同的输入特征联合估计幅度谱和相位谱补偿的值。
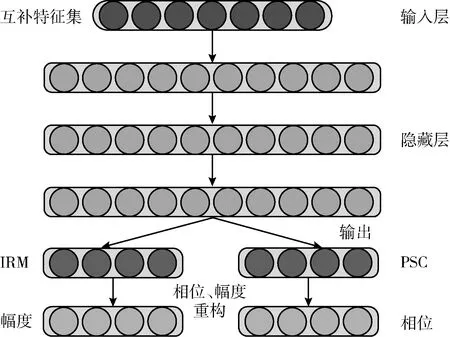
图3 网络结构
常见的幅度谱掩蔽目标有理想二值掩蔽(IBM)以及理想比例掩蔽(IRM),在本文中我们将使用IRM估计幅度部分
(9)
假设X(k,l) 和Z(k,l) 不相关的情况下,X(k,l)2和Z(k,l)2分别表示T-F单元内的语音能量和噪声能量,β为IRM中可调参数,通常情况下设置为0.5。IRM的取值范围为[0,1]上的实数。
综上,本文将MIRM设置为幅度谱掩蔽的训练目标,ΩZ作为相位谱补偿的训练目标。IRM以及归一化后的ΩZ的输出范围都在[0,1],同时满足了网络输出层sigmoid函数的输出,这样能最大化网络的监督性学习的作用。
2.3 DNN训练
2.3.1 网络配置
本文实验的神经网络有3个隐藏层,每个隐藏层具有相同数量的单元为1024个。隐藏层的激活函数为ReLU(整流线型单元),两个输出层单元设置为sigmoid函数,使用带动量的自适应梯度下降用于优化。本文采用80次 epoch 训练网络,前5次的动量(moment)设置为0.5,其余的epoch设置为0.9。
2.3.2 特征提取
本文用于DNN训练的特征选用互补特征集[15],互补特征集已被证明能够代表语音短时特性且适用于网络的训练。互补特征集包括:幅度调制频谱图(AMS)、感知线性预测(RASTA-PLP)、梅尔频率倒谱系数(MFCC)、伽马通频率(GF)。输入的特征提取后还要进行归一化的处理,其操作是为了方便DNN的参数调节。其次,为联系语音的上下文,我们将输入的单个语音帧作为中心,拓展到其左右两帧,也就是说将输入的窗口长度设置为2W+1,其中W为半个窗长。
2.3.3 代价函数
对于该多目标的神经网络,我们将它的代价函数定义为
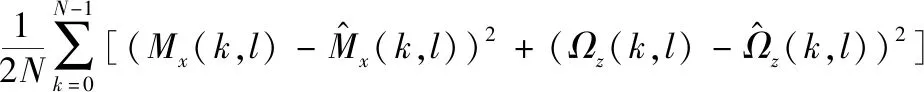
(10)
2.4 测试阶段的语音合成
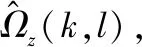
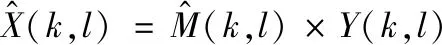
(11)
(12)
通过网络估计得到的增强幅度谱和增强相位谱,可以计算出干净语音的频谱,记为
(13)
最后通过逆傅里叶变化(ISTFT)便能得到时域上的增强语音,达到最终去噪的目的。在下章节中会仿真我们提出的方法,同时通过客观评价标准验证我们实验的性能。
3 实验部分
在本章中将会介绍所使用的实验配置以及评价标准。我们会将本文提出的模型和几种当今流行的基于DNN的幅度谱掩蔽算法在同条件下进行比较,增强结果将通过两种客观评价方法对增强语音进行评价,并对其结果进行分析。
3.1 实验配置
我们所使用的数据集来自TIMIT语料库,该语料库中每位发言者有10条干净的语音。我们选取了该语料库中119位男性发言者进行训练以及40位男性发言者进行测试。每位发言者包含10条干净语音,所以分别有1190条和400条干净语音。我们从NOISEX-92数据库中选择了babble、factory2、buccaneer1噪声,所挑选的噪声分别表示为人群嘈杂的声音、汽车生产车间的噪声、驾驶室内部噪声。将所选噪声分为两部分,为保证测试语音噪声段在训练阶段不可见,前半部分用于训练集的合成,后半部分用于测试集的合成。将干净语音和对应噪声段的5个随机切分相结合构建含噪语音,信噪比分别为-5 dB、0 dB、5 dB。最终的训练集包含17 850条含噪语音(119个发言人×10条语句×3个噪声×5个随机切分),测试集包含1200条含噪语音(40个发言人×10条语句×3个噪声),并将900条含噪语音设置为交叉验证集(30个发言人×10条语句×3个噪声)。
3.2 实验细节
实验中所有的语音集的采样率为16 kHz,然后对信号进行分帧、加汉明窗,其中帧长为40 ms,帧移为20 ms,再对一帧计算STFT,就可以将时域信号转换为信号的频谱。
提取频谱中相位与幅度信息,将IBM、IRM、cIRM以及本文提出的IRM_PSC作为神经网络的训练目标,在训练的过程中,都使用带动量的梯度下降法优化网络,将以上4种方法进行同条件下去噪比较,并用客观评价方法(能够验证其语音质量和语音可懂度的算法)对其评价。
3.3 评价方法
本文使用两种客观评价算法评价语音的质量和语音的可懂度,即为语音质量的感知评估(PESQ)得分、短时目标可懂度(STOI)得分。通过计算增强语音和其对应的干净语音进行比较得到PESQ得分,所产生的分数在[-0.5,4.5],得分越高代表语音的质量越好。STOI得分由增强语音和干净语音之间的短时时间包络的相关性计算得到,所产生的分数在[0,1],同样得分高表示语音的可懂度越好。PESQ和STOI已被证明和人类语音的质量和语音可懂度高度相关,二者被广泛用于语音评价中。
3.4 评价结果
我们使用Mixture表示含噪语音,使用IBM、IRM分别表示两种掩蔽算法通过DNN训练得到的增强语音的方法,cIRM表示为复数域理想比例掩蔽算法,将本文提出的方法表示为IRM_PSC。以上方法将在factory2(fac)、babble(bab)、buccaneer1(buc)的含噪语音下进行去噪比较。且作为对比项的3种方法均为现阶段较有代表性的基于DNN训练的方法。
表1~表3列出了在3种信噪比条件下,含噪语音以及4种不同的训练目标训练后得到的增强语音的平均结果。从表中可以看出IRM_PSC的PESQ和STOI得分较IRM和IBM均有不同幅度的提升,再一次验证了相位增强可以进一步提高语音质量和语音可懂度。同时在-5 dB和5 dB工厂噪声的条件和0 dB的所有条件下STOI得分IRM_PSC较cIRM有所提升,验证本文直接重构相位谱的方法能够有效提高语音可懂度。但-5 dB和5 dB在babble条件下较cIRM略有下降,这是因为在人噪(bab)条件下与语音信号相位结构类似,区分度不高,所以无法达到工厂(fac)和驾驶舱噪声(buc)的水平。
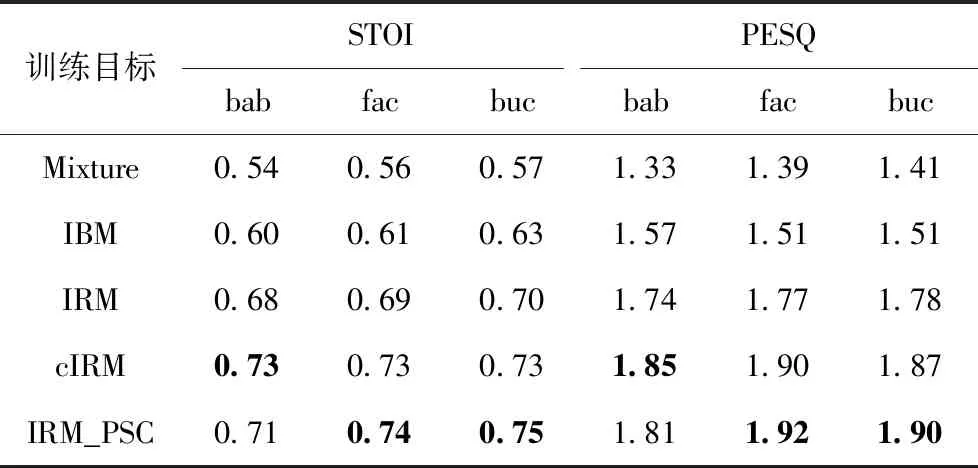
表1 信噪比-5 dB噪声条件下各训练目标性能

表2 信噪比0 dB噪声条件下各训练目标性能

表3 信噪比5 dB噪声条件下各训练目标性能
根据表1~表3计算各方法PESQ均值,如图4所示。本文方法取得最高PESQ得分2.27,较IBM和IRM提高0.27和0.10,较cIRM也有小幅度的提升,平均提升约0.03,验证本文方法能够有效地提升语音质量,且对比cIRM方法,直接修正相位谱能更好提升语音质量。

图4 各方法PESQ均值
结合表1可知,低信噪比下SNR为-5 dB时,在不同的含噪环境中IRM_PSC较IBM和IRM,PESQ值分别平均提高了0.35和0.12,STOI值分别平均提高了0.12和0.04,均有较明显的提升。验证本文方法在低信噪比环境下同样适用。
3.5 语谱图分析
进一步分析语谱图,如图5所示。从图5(b)可以看出含噪语音的语音信息被遮盖,图5(c)~图5(e)中IRM、cIRM和IRM_PSC为处理过语音的语谱图,三者都可以进一步抑制残留噪声,但可以看出cIRM和IRM_PSC保留更多的语音信息,因此语音可懂度进一步提高。图5(c)语音信息被噪声遮盖,语音分段模糊,因此难以提升语音质量和可懂度。图5(d)虽然语音分段和基频信息保留完整,但如图5(d)中黑圈所示,后部语音无声段噪声残留较多影响语音质量和可懂度。观察图5(e)底部深黑色线条,基频明确,低频信号处理清晰,且通过本文方法处理的语音间断较IRM更加明确,该方法通过改进SNR特性在无声段的处理效果明显,优于IRM和cIRM方法,如图5(a)和图5(e)中黑圈所示。因此语音可懂度和质量得以进一步提升,但在高频处存在噪声残余。通过主观试听IRM_PSC方法增强效果明显,能够滤除大多噪声,保留清晰的语音信号。

图5 语音语谱图
4 结束语
本文提出了一种基于DNN的相位感知语音增强方法。该方法引入了相位谱补偿为DNN训练的新目标。它是传统相位谱补偿的改进,使得传统的相位谱补偿能够随着噪声语音的能量变化而变化,且更适合DNN的训练和估计。在DNN的训练阶段我们采用了多目标训练的神经网络,网络同时训练了语音相位谱补偿以及幅度谱掩蔽,目的是能够从相同输入特征下联合估计这两个参数。且据我们所知,本方法也是第一次将相位谱补偿联合幅度谱通过监督性学习进行训练的方法。与此同时,训练相位谱补偿具有一般性,可与任何幅度谱估计方法进行联合训练,和IRM联合后,实验结果表明,我们提出的方法在语音质量和语音可懂度方面均优于传统不含相位的语音增强算法,且相位谱补偿计算简化了间接转换求相位的方法,保留了更多的语音细节。今后可以尝试优化网络,提升多目标训练的效率。
