基于改进的C4.5算法的代码异味检测方法
2021-04-22吴海涛高建华
王 帆,吴海涛,高建华
(上海师范大学 信息与机电工程学院,上海 200234)
0 引 言
在软件生命周期阶段,代码异味导致软件质量逐渐衰退,降低软件理解性和维护性[1]。代码异味检测已经成为发现软件源码或设计问题的方法,过去几十年中,大量研究者研究出不同的代码异味检测技术。Baydaa等[2]在基于相似性度量基础上提出两种新的度量检测Refused Bequest代码异味。Palomba等[3]提出一种“HIST”检测技术,通过挖掘系统版本变更历史来检测代码异味,解决单个版本容易丢失重要信息的缺点。近些年来,越来越多的研究者使用机器学习方法检测代码异味。Wang等[4]使用代码变更信息来提升代码异味数据集中的标签质量,得到更可靠的训练集,提高代码异味检测准确率。Amorim等[5]将C5.0算法和遗传算法相结合进行代码异味检测。Fontana等[6]使用16种机器学习算法对4种代码异味进行检测,其目的是评估哪种机器学习算法在检测代码异味上准确率更高。
为了提高代码异味检测精确度并使开发人员便于理解代码异味检测过程,提高开发人员识别代码异味的信心,本文使用机器学习中的C4.5算法对其进行检测。在属性选择阶段,本文提出使用ReliefF算法计算条件属性和目标属性相关性,使用互信息计算条件属性间的冗余度,选择出相关性大而冗余度小的条件属性集,通过划分子集并依据机器学习算法求得F值最大的条件属性子集,减少生成决策树的计算开销。同时提出在C4.5算法中加入对称不确定性(SU),选择信息增益率高且与条件属性间相关度低的条件属性作为分裂属性,建立新的算法模型。对比实验结果得出,该模型在检测代码异味的精确度和召回率方面均有所提高。
1 背 景
1.1 代码异味
代码异味是软件结构中的一种设计缺陷,阻碍代码理解,影响软件质量和维护。代码异味在软件版本中生存周期长[7],研究者给出22种代码异味的定义,并列出特定的重构方法来分别移除每种代码异味。但是研究者只是在单一平面上给出22种代码异味的定义,并没有进一步对其进行分类。文献[8]根据每种代码异味的特点将Fow-ler定义的代码异味分为7种类别,以便更好理解代码异味,并认识到代码异味之间的关系,表1列出代码异味的分类类别。
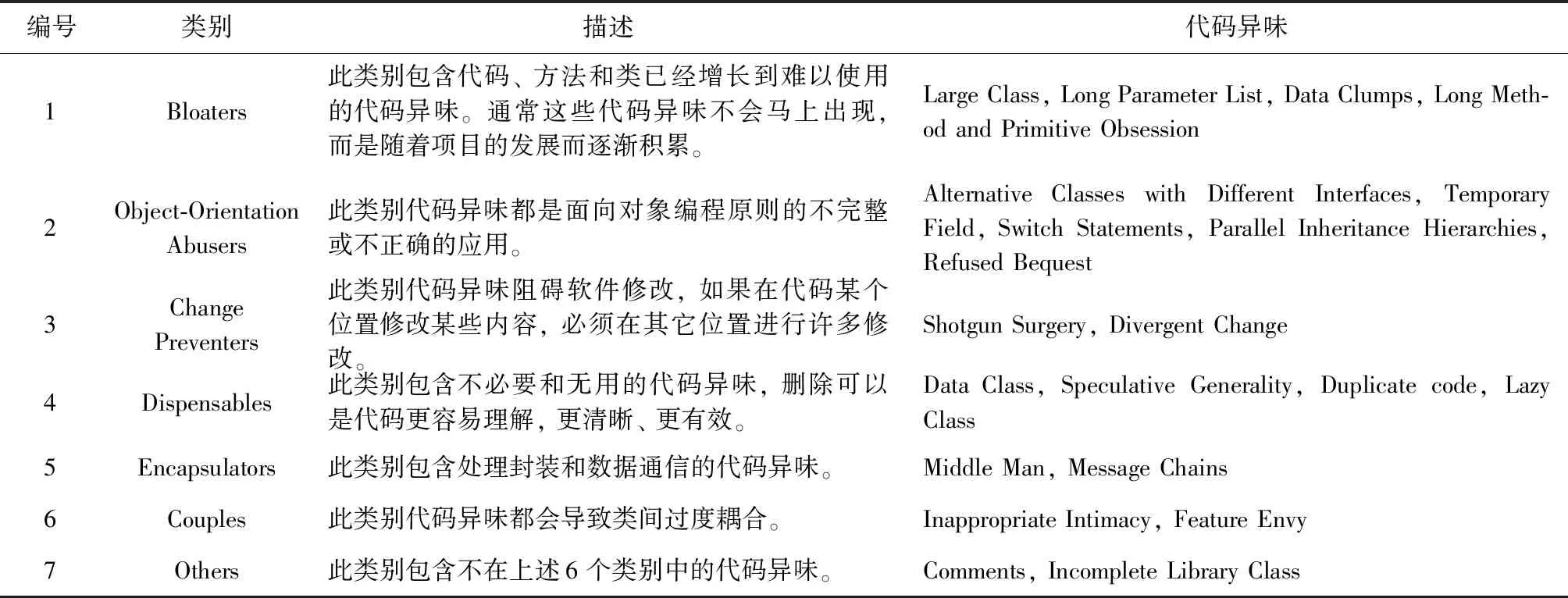
表1 代码异味分类
1.2 C4.5算法
C4.5算法是决策树算法中的一种算法,可以用于解决分类和回归问题,本文用于对代码异味进行分类。
假设D是一组带有目标属性的数据集,|D|为数据集的样本总数。本文涉及二分类,即目标属性C有两个不同的取值{P,N},|P|, |N|分别为D中目标属性值为P,N的样本总数,这里|P|+|N|=|D|。对D中的样本分类所需的信息熵为
(1)
假定选择条件属性A划分数据集D中样本,若A有m种不同的取值{a1,a2,…,ai,…,am},则属性A按照m种取值将D划分为m个子集{D1,D2,…,Di,…,Dm}, |Di|为D中属性A取值为ai的子集Di的样本总数。属性A划分数据集D的信息熵为
(2)
通过条件属性A划分后的样本集的信息增益为
InfoGain(D,A)=info(D)-infoA(D)
(3)
条件属性A对数据集D的分裂信息为
(4)
条件属性A对数据集D的信息增益率为
(5)
C4.5算法选择信息增益率大的条件属性,即能够最大减少目标属性不确定程度的属性,作为当前节点的分裂属性。
2 代码异味检测方法
本文研究一种基于改进的C4.5算法的代码异味检测技术,提出增加条件属性间的相关度,更新信息增益率的方法,并在属性选择过程中,提出将ReliefF算法和互信息结合,选择出最优条件属性集。图1总结了本文代码异味检测技术的主要过程。

图1 代码异味检测过程
2.1 RMIO属性选择算法
属性选择是数据挖掘数据预处理中的重要和常用技术之一[9],在有限的样本数据中,冗余的、不相关的条件属性只会使分类器计算开销大并且分类性能差。本文每种代码异味有61种软件度量即条件属性,并不是每种条件属性对于检测代码异味都是相关的,通过属性选择可以删除冗余的无关的条件属性,提高分类器效率。
ReliefF算法由Kononenko在Kira等的研究成果基础上提出,用于解决多类问题[10],是一种属性权重算法。ReliefF算法的主要思想是从训练集中随机选择一个样本S,依次从与S相同类别和不同类别的训练集中选择M个最近邻样本,然后根据权重公式计算条件属性的权重值并更新排名。上述过程不断重复,直到每个条件属性与目标属性的权重都被计算,最终得到按照权重降序的条件属性排名。权重越大,代表该条件属性对分类作用越大,即该条件属性和目标属性相关度越大,反之,表示该条件属性对分类作用越小。通过设定阈值选择相关度大的条件属性子集,剔除无效、不相关的条件属性。
虽然ReliefF算法可以对属性进行选择,但是不能解决属性冗余的缺点,即得到的属性子集中仍然存在冗余项。可以通过互信息(mutual information)[11]计算条件属性间的冗余度,也表示两个条件属性间的依赖程度。互信息的计算公式为
(6)
其中,P(x,y)是X和Y的联合概率分布函数,而P(x)和P(y)分别是X和Y的边缘概率分布函数。互信息度量的是两个条件属性间,一个条件属性对另一个不确定减少的程度,依赖性越强,I(X;Y)的值越大。
通过ReliefF算法计算条件属性和目标属性间的相关度,使用互信息计算条件属性间的冗余度,选择出与目标属性相关度大而与其它条件属性冗余度小的条件属性,所以把该算法称为RMIO属性选择算法,伪代码如算法1所示。
算法1:RMIO属性选择算法
输入:数据集D,包含条件属性集X
输出:最优条件属性集S
(1)For X中的每个条件属性xi
(2)使用ReliefF算法计算xi和目标属性C之间的相关性W(xi,C)
(3)End For
(4)选择相关度最大的条件属性x=argmaxW(xi,C),其中xi∈X
(5)S=S∩x
(6)Fori=1 To |X|-|S| Do
(7)从X-S中选择相关性最大冗余度最小的条件属性

(8)S=S∩x
(9)End For
(10)将S中条件属性划分成n份,S1…Sn
(11)Fori=1 TonDo
(12)利用C4.5算法选出F值最大的条件属性集
S=argmax(C4.5(Si))
(13)End For
(14)Return S
2.2 SU_C4.5算法
数据集合中的条件属性并非都对模型的分类包含相同的期望信息,有些条件属性对分类起到一定的正作用,有些则相反。例如对Long Method代码异味进行分类,条件属性“LOC”(代码量)包含更多的期望信息,对其分类有更多作用,而条件属性“DIT”(类的继承深度)只包含少量期望信息。同样,利用C4.5算法构造决策树时,在数据集合中先选择一个条件属性作为分裂属性,剩下的条件属性集中,有的条件属性对分裂属性影响较大,有的则相反。例如天气的两个条件属性温度和季节,季节的变化会影响温度的高低,这两个条件属性将有一定的影响,具有一定的关联关系。
本文认为任意两个属性都有一定的关联关系,并且定义这种关联关系为相关度。C4.5算法在构造决策树时,只考虑条件属性与目标属性的相关度,忽略条件属性间的相关度。改进的C4.5算法通过计算对称不确定性来确定两个条件属性间的相关度。
对称不确定性(SU)[12]常用来判断条件属性与目标属性、条件属性间的相关度。SU的公式可参考第1章的式(1)~式(3),条件属性X和条件属性Y的相关度公式如下
(7)
SU(X,Y)取值范围为[0,1],当SU(X,Y)=0时,表示X与Y为两个相互独立的条件属性,当SU(X,Y)=1时,表示X与Y为两个完全相关的条件属性。则条件属性A与其它所有条件属性的平均相关度公式为
(8)
式(8)中E为不包含条件属性A的属性子集,|E|为集合E的属性总数。
C4.5算法构造决策树选择分裂属性时需要考虑该条件属性与目标属性有最大相关度,同时在该条件属性与其它条件属性间需要有最小相关度,即该条件属性与其它条件属性有最小的平均相关度。改进后的算法公式如式(9)所示
(9)
如果条件属性A与其它条件属性的相关度越小,平均相关度就越小,信息增益率就越大。本文将对称不确定性(SU)加入C4.5算法中,更新信息增益率的计算,所以把该改进算法称为SU_C4.5算法,伪代码如算法2所示。
算法2:SU_C4.5算法
输入:数据集D(有n个属性,其中n-1个是条件属性,第n个是目标属性)
输出:一棵决策树
(1)创建根节点N
(2)If 所有样本都属于同一类别C,then
(3)Return N为叶子结点,标记为类C
(4)For D中的每个条件属性A
(5) 计算条件属性间的相关度和信息增益率
(6)End for
(7)选择使GainRatio(D,A)(信息增益率)最大的条件属性作为分裂属性
(8)将数据集D按照选择的分裂属性进行划分
(9)对于分裂后的每部分数据集,循环执行以上算法过程
2.3 算法复杂度分析
在传统的C4.5算法中,计算信息增益率的时间复杂度是O(m*n),其中m是属性的个数,n是样本的个数[13]。在SU_C4.5算法中,计算信息增益率之前,需要先计算条件属性间的相关度,需要扫描为整个区间去计算每个条件属性间的相关度,其时间复杂度为O(m*n)。所以在使用SU_C4.5算法计算信息增益率最坏情况下的时间复杂度仍然为O(m*n)。
3 实 验
为了验证本文提出的SU_C4.5算法的有效性,在4个开源软件Eclipse 3.3.1,Mylyn 3.1.1,ArgoUML 0.26和Rhino 1.6上进行了实证性研究。本实验主要关注以下3个问题:
Q1: C4.5算法在属性选择后的数据集上的分类准确率是否有提高?
Q2: SU_C4.5算法相对于传统C4.5算法的分类准确率是否有提高?
Q3: SU_C4.5算法相对于其它机器学习算法的分类准确率是否有提高?
3.1 实验数据集
实验中使用的数据集来自于Lucas Amorim等[6]的论文中的数据集,数据集D={(Ni,Ai,Ci)|i=1,2,3,…,n}, Ni表示代码类实体的ID,Ai表示代码实体的属性(本文指度量,如LOC、WMC等),Ci表示该实体是否是代码异味。数据集D来自4个java开源软件Eclipse 3.3.1、Mylyn 3.1.1、ArgoUML 0.26 和Rhino 1.6,总共有7952个样本,61个条件属性,9种代码异味。本文实验采用十折交叉验证来测试C4.5算法的准确性。
本文选择9种代码异味,Antisingleton、Blob、Class Data Should Be Private、Complex Class、Large Class、Long Method、Long Parameter List、Message Chains和 Swiss Army Knife。对于这9种代码异味,在文献[14]中有详细的定义。
(1)Antisingleton(AS):该类的对象只有一个实例,承担很多责任,在一定程度上违背“单一职责原则”。
(2)Blob(Bb):系统中类承担很多的责任,有很多属性、操作,并且依赖数据类。
(3)Class Data Should Be Private(CP):暴露字段的类,违反封装原则。
(4)Complex Class(CC):类中至少包含一个大而复杂的方法,可以用圈复杂度和代码行数度量。
(5)Large Class(LC):类中至少包含一个大的方法。
(6)Long Method(LM):类中有过长方法。
(7)Long Parameter List(LPL):类中至少包含一个方法,该方法相对系统中每个方法的平均参数数量的长参数列表。
(8)Message Chains(MC):一个使用长链方法调用来实现(至少)其功能之一的类。
(9)Swiss Army Knife(SK):类中某方法可以分为多种方法的分离集,从而提供许多不同的不相关的功能。
3.2 模型评价指标
本文使用信息检索中最基本指标召回率和精确度来评估模型的好坏,其中召回率和精确度的计算方法如下
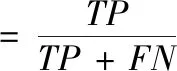
(10)

(11)
这里TP(true positive)指正确检测出的代码异味数,FP(false positive)指将非代码异味检测为代码异味的数量,FN(false negative)指将代码异味检测为非代码异味的数量。由于精确度和召回率是两个值,无法根据两个值来比较模型的好坏,需要F值来综合精确度和召回率,计算方法如下

(12)
3.3 实验设计
实验环境如下:操作系统是windows 10,处理器是inter(R) Core(TM)i5-8250U @1.6 GHz,内存是8 GB,实验是在Weka3.8和eclipse中完成,开发语言是java。
实验一:本文每种代码异味数据集的样本总数和条件属性总数见表2。使用RMIO算法对9种代码异味数据集进行属性选择。RMIO算法最后一步之前会给出按照值大小的一份条件属性排序,此处的值代表条件属性的相关度及冗余度,值最大即相关度最大且冗余度最小的条件属性排在首位,值最小即相关度最低且冗余度最低的排在末尾。每种代码异味数据集的条件属性都有61种,为了得到更优的条件属性子集,本文首先将61种条件属性按照排序结果分成6份,第1份包含前10个条件属性,第2份包含前20个条件属性,依次类推,第5份包含前50个属性,第6份包含所有属性。使用C4.5算法在不同数量的条件属性的代码异味数据集上进行分类,F值最大的条件属性集再依次左右±1,2,3个条件属性,再使用C4.5算法在不同的数据集上进行分类,此时F值最大的条件属性集为最优条件属性集。

表2 代码异味数据集样本总数和条件属性总数
实验二:分别使用SU_C4.5算法和传统C4.5算法在RMIO属性选择后的9种代码异味数据集上进行实验。通过十折交叉验证法计算代码异味分类准确率,最后比较两个算法的精确度、召回率及F值。
实验三:分别使用SU_C4.5算法和JRip算法及朴素贝叶斯算法在RMIO属性选择后的9种代码异味数据集上进行实验。通过十折交叉验证法计算代码异味分类准确率,最后比较SU_C4.5算法和JRip算法及朴素贝叶斯算法的精确度、召回率及F值。
3.4 实验结果与分析
通过上述3组实验的设计,得到3组实验结果,根据实验结果,逐一回答前文提到的Q1-Q3问题。
Q1:对9种代码异味数据集使用RMIO算法进行属性选择,使用C4.5算法做为基准分类算法,得到最优的条件属性子集,并与选择之前的条件属性集进行比较,得到的结果见表3。其中“Δ”表示使用RMIO算法得到的条件属性子集和未进行选择的条件属性集构造的模型比较,“+”表示使用RMIO算法进行属性选择后构造的模型结果更好,“-”表示不进行属性选择的条件属性集构造的模型结果更好。从表3中可以看出Message Chains数据集中的条件属性总数减到10,Blob和CDSBP数据集的条件属性总数减得少些,减到30。从表3能够看出,C4.5算法在使用RIMO算法进行属性选择的数据集上构造的模型的分类准确率有明显提高,其中分类精确度最高提高5.9%,召回率提高3.7%,F值提高4.1%。通过图2能够直观看出,C4.5算法在RIMO属性选择后的数据集上的分类F值有所提高,结果表明在预处理阶段对数据集进行RMIO属性选择能够提高分类器性能。

表3 RMIO算法与未属性选择的比较结果

图2 属性选择前后F值对比
Q2:根据表4的实验结果,可以看出SU_C4.5算法和传统C4.5算法相比,代码异味分类准确率有明显提升,其中分类精确度最高提高4.9%,召回率最高提高6.8%,F值最高提高4.7%,虽然Message Chains异味的召回率和F值有所下降,但是平均各指标的值都有所提高。从图4可以看出传统C4.5算法检测代码异味时,Blob的F值近似50%,而其它代码异味的F值都在68.5%以上,其中Long Parameter List的F值为97.4%。这是因为代码异味没有统一正式的定义,用来作为条件属性的度量值也不一样,使用现有的度量值并不适合用来检测Blob异味。表4和图3结果表明,SU_C4.5算法在构造决策树时,将条件属性间的相关度考虑进来,能够有效提高分类准确率。

表4 SU_C4.5算法与C4.5算法的比较结果

图3 C4.5算法改进前后F值对比
Q3:根据表5和表6的实验结果,可以看出SU_C4.5算法同JRip算法和朴素贝叶斯算法相比,代码异味分类准确率均有所提高。同JRip算法相比,SU_C4.5算法分类精确度最高7.7%,召回率最高提高16.6%,F值最高提高11%;同朴素贝叶斯算法相比,SU_C4.5算法分类精确度最高62.5%,召回率最高提高63.1%,F值最高提高58.8%。产生差异的原因在Fontana等[6]论文中指出,在代码异味检测中,C4.5算法和随机森林算法分类准确率最高,其次是JRip算法,而朴素贝叶斯算法相比于前面几种算法分类准确率要低。

表5 SU_C4.5算法与JRip算法的比较结果

表6 SU_C4.5算法与朴素贝叶斯算法的比较结果
4 结束语
本文针对传统C4.5算法未考虑条件属性间相关度提出一种改进方法,将对称不确定性(SU)加入C4.5算法中,选择信息增益率高且与条件属性间相关度低的条件属性作为分裂属性。并且在数据预处理阶段,使用ReliefF算法和互信息对条件属性进行选择,得到最优条件属性子集。本文在9种代码异味数据集上进行实验,实验结果表明,SU_C4.5算法以及RMIO属性选择算法有更好的精确度、召回率以及F值。本文介绍了9种代码异味的检测,后续也会对更多类型的代码异味进行检测。
