基于深度学习的医疗图像分割综述
2021-04-22孔令军王茜雯包云超李华康
孔令军,王茜雯,包云超,李华康
(1.金陵科技学院,江苏 南京 211169;2.南京邮电大学,江苏 南京 210003;3.西交利物浦大学,江苏 苏州 215123)
0 引言
作为机器学习的子领域,深度学习由于其高效的计算和处理高维非线性数据的能力已经被广泛应用于图像处理领域[1]。截至今日,深度学习已经在计算机视觉领域(Computer Vision,CV)做出了巨大的贡献,CV的发展同时促进了医学图像分析的进步。通过运用神经网络,计算机设备可以高效地处理大量图片信息,以辅助专科医生进行诊断,从而可以缓解放射科医生的压力,减少误诊漏诊概率,提高诊断效率,在医疗领域具有良好的发展前景[2]。
深度学习有别于其他编程算法的主要特点是通过神经网络对输入数据进行特征提取,而不需要过多的人为参与。传统的机器学习系统通常要通过专业人员对输入数据进行人工特征提取,将原始的输入数据转化为系统能够识别的形式,而深度学习减弱了对人工提取特征的要求,原始数据在通过神经网络之后,可以自主学习到有用的信息,使得系统可以得到最优的输出。
目前,医学影像处理深受国内外的重视。作为医疗影像处理过程中一个重点的研究方向,图像分割可以有效分割出影像中的异常组织和结构,是进行合理评估以及给予病患恰当治疗方案的条件,逐渐在医学界发挥着越来越大的作用。图像分割可以提取出影像图像中的特定组织或结构,给医生提供特殊组织的定量信息。图像经过分割,可以应用于各种场合,例如定位病变组织、实现精准注射以及组织结构清晰化呈现等。
在医生做诊断时,只需要对医学影像中的部分组织或结构进行分析,这部分图像被称为感兴趣区域(Region of Interest,ROI),这些ROI通常对应于不同的器官、病理或者是其他的某些生物学结构。医疗图像分割的目的即为分割出影像图片中的ROI,除去无用信息。到目前为止,国内外已经提出了很多医学图像分割方法,分割方法经历了从传统的图像分割法到基于深度学习的医疗图像分割法的演变。
1 传统图像分割方法
1.1 阈值分割法
阈值分割法是传统图像分割方法中最基本的图像分割法,因其计算复杂度小,易于实现,且分割结果直观而成为图像分割方法中最为广泛应用的分割法,图像二值化分割公式如式(1)所示。阈值分割法中,如何选择最佳阈值是该技术的核心所在。最广泛使用也最具有代表性的阈值选择法是1979年提出的OTSU方法[3],它是针对灰度图像分割而提出的方法,通过最大类间方差自动计算阈值。
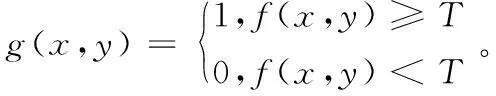
(1)
2008年,Moltz等人[4]通过阈值法对CT图像中的肝脏肿瘤部分进行分割,其方法为:通过分析给定区域内的灰度值,描绘出灰度值分布图,根据该分布图采用自适应阈值法[5]对图像进行粗略的分割,随后通过形态学对分割结果进行进一步的处理。阈值分割法没有很好地利用好像素的空间信息,使得分割结果容易受到图片内噪点的影响,因此只适用于目标的类内方差较小的图像处理,比如指纹。
1.2 区域生长法
区域生长法是利用图像灰度值的相似性,将相似像素或者相似子区域集合起来形成更大区域。区域生长法中较为著名的是分水岭算法[6]。分水岭算法由Vincent于1991年提出,该方法模拟地质学中的地貌,将图像中像素点的灰度值模拟为海拔高度,像素灰度值中的局部极小值模拟为谷底,局部极大值模拟为顶峰,谷底之间的边界即为分水岭。
区域分割法实现简单,可以保证分割后的图像在空间上的连续性,适用于分割连续的均匀小目标。其缺点是需要人为参与来选择每个区域合适的种子点,且该算法对噪声敏感,不适用于大区域的分割,可能导致过分割或者欠分割。
1.3 图割法
图割法是一种基于图论的图像分割方法,通过建立一种概率无向图模型来实现图像分割。这种概率无向图模型又被称马尔可夫随机场。在传统图像分割法中,图割法因其具有很好的鲁棒性而被广泛应用在医学图像分割中。图割法中比较有代表性的方法是graphcut法[7],基本思路为建立一张加权图,通过尽可能移除较小权重的边,使得最终被划分出的各个子图不相连。
图割方法鲁棒性高,分割较为复杂的图像也能得到很好的效果,但其具有较高的时间复杂度和空间复杂度,通常与其他传统分割方法搭配使用。
2 基于深度学习的医疗图像分割算法
传统的图像分割方法都需要分析待分割图像前景与背景之间的差异,从而人为地从图像的灰度、对比度及纹理等信息中的设计特征来进行分割,且分割过程会丢失掉图像的语义信息,而深度学习技术解决了传统图像分割方法的局限性。基于深度学习的医疗图像分割法主要有基于全卷积网络(Fully Convolutional Networks,FCN)的图像分割方法、基于U-Net网络的图像分割方法以及基于U-Net++网络的图像分割等方法。
2.1 图像分割算法
2.1.1 FCN
早期的深度学习图像分割算法主要通过滑动窗口法进行目标的分割,滑动窗口法会产生大量的冗余候选区域,计算量大且很多计算是重复的计算,效率低下,且图像块的大小会直接影响分割的精度,具有一定的局限性。2015年Long等人[8]提出了FCN,由此,FCN代替了传统的滑动窗口法,被广泛应用到图像分割领域。
FCN主要思想是搭建一个只包含卷积操作的网络,输入任意尺寸的图像,经过有效推理和学习可以得到相同尺寸的输出。FCN的网络结构是一种编码—解码的网络结构模式,将经典卷积神经网络(Convolutional Neural Networks,CNN)中的全连接层替换为卷积层,从而使整个网络主要由卷积层和池化层组成,因此称为FCN。另外,网络中设计了跳跃连接将深层网络的全局信息和浅层网络的局部信息连接起来,相互补偿,如图1所示。网络结构中,编码器部分主要作用是提取图像中的高维特征,图像经过卷积层和池化层后空间维度降低,而解码器部分则对该输出特征图进行上采样,将该特征图恢复到与输入图像相同的尺寸,同时将提取到的高维特征映射到最终特征图的每个像素,从而可以实现像素级别的图像分割。
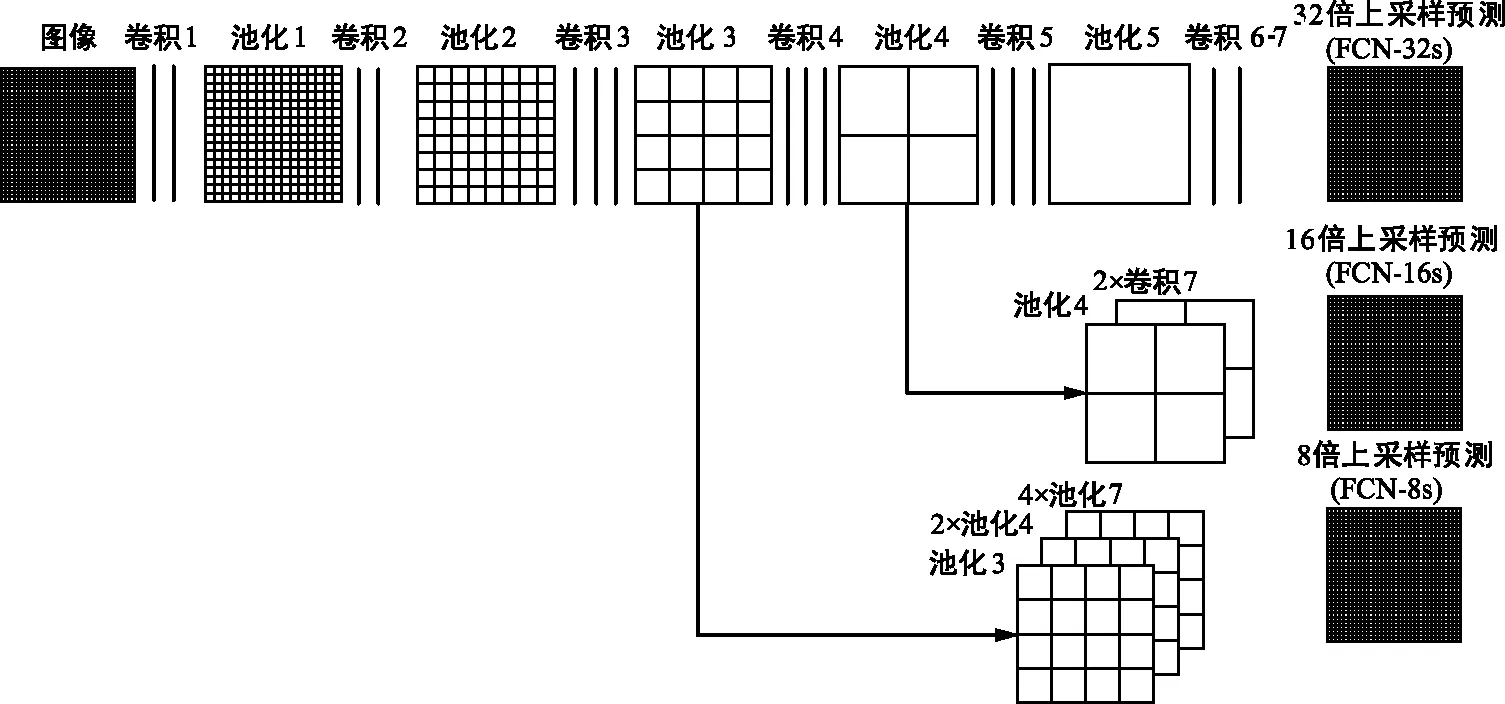
图1 FCN结构Fig.1 Architecture of FCN
相对于经典的CNN网络,FCN的优点是对输入网络的图像尺寸没有限制,但其缺点也是不可忽视的,FCN采用的逐像素进行分类忽视了各个像素之间的联系,没有考虑全局上下文信息,且上采样部分是进行了一次上采样操作,直接将特征图进行8倍、16倍、32倍扩大会忽视图像中的细节信息,使结果较为模糊。
2.1.2 U-Net
除了FCN,医学图像分割领域中另一个经典网络为Ronneberger 等人[9]提出的 U-Net 网络,也是医学图像分割任务中应用最为广泛的网络。U-Net网络是在FCN基础上做了改进的版本,其网络结构与FCN的结构相似,没有全连接层,由卷积层和池化层构成,同样是分为编码器阶段和解码器阶段。U-Net结构如图2所示,网络结构主要包括下采样部分、上采样部分以及跳跃连接部分,上采样和下采样部分对称,网络整体形成U型结构。下采样部分主要作用为提取图像中的简单特征,而上采样部分经过了更多的卷积层,感受野更大,提取到的特征是更为抽象的特征,跳跃连接融合了下采样结构中的底层信息与上采样结构中的高层信息,以此来提高分割精度。

图2 U-Net结构Fig.2 Architecture of U-Net
2.1.3 U-Net++
Zhou等人[10]提出的U-Net++是在U-Net基础上针对原始结构中的跳跃连接部分做了进一步的改进。其结构如图3所示,X定义为卷积操作。原始U-Net结构中的跳跃连接用的是直接串联方式,而U-Net++的跳跃连接改用密集连接方式。采用密集连接方式,网络得以在训练过程中自动学习不同深度特征的重要性,从而可以根据需要选择合适的下采样层数,在保证网络性能的条件下减少了网络参数。传统U-Net结构上采样部分只叠加了同层下采样部分的特征图,这两层的语义信息相差较大,不利于网络的优化。而U-Net++采用密集连接,网络可以将来自不同层的特征进行特征叠加,减小了下采样阶段特征和上采样阶段特征之间的语义差异,更利于网络的优化。更多的特征信息也有效地避免了原始图像中的小目标和大目标边缘等信息随网络层数增加而丢失的现象。
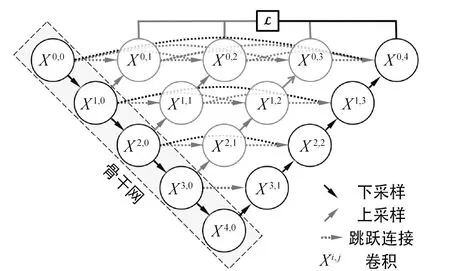
图3 U-Net++结构Fig.3 Architecture of U-Net++
U-Net++的另一个特点为网络共享了同一个下采样部分,使得训练过程只需要训练一次下采样网络,不同深度的特征由对应的下采样层以对称方式还原。除了在跳跃连接上做改进之外,U-Net++还增加了深监督,将网络结构各层的输出也连接到最终输出。
2.1.4 SegNet
SegNet[11]的编码网络和VGG-16的卷积层部分相同,同样不含全连接层,主要作用是进行特征提取,网络结构如图4所示。整个网络的新颖之处在于,解码器对较低分辨率的输入特征图进行上采样。具体地说,解码器使用从相应的编码器接收的最大池化索引来进行对输入特征图的非线性上采样。这种方法减少了对上采样的学习,改善了边界划分,减少了端到端训练的参数量。由于上采样而变得稀疏的特征图随后经过可训练的卷积操作生成密集的特征图。最后由网络的最后一层softmax层来求出图像的每一个像素在所有类别中最大的概率,从而完成图像的像素级别分类。SegNet只存储最大池化索引,并将其应用于解码网络,以此来得到更好的表现。因此相比于其他分割网络,SegNet的突出优点是更加高效。
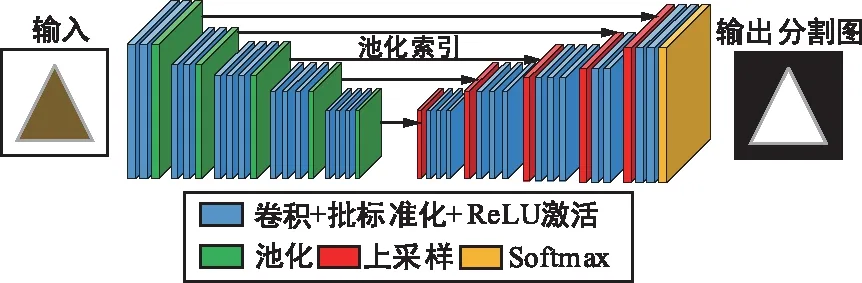
图4 SegNet结构Fig.4 Architecture of SegNet
2.1.5 DeepLab系列
DeepLab-v1[12]网络,将FCN与条件随机场(Conditional Random Field,CRF)模型相结合,解决了FCN分割不够精确的问题。其主要结构为在FCN之后串联完全连接的CRF模型。CRF将来自FCN的粗糙分割结果图进行处理,在图中的每个像素点均构建一个CRF模型,以此获得图像更为精细的分割结果。同时,DeepLab-v1中加入带孔算法来扩展感受野,感受野越大则可以获得图像更多的上下文信息,也避免了FCN在一步步卷积和池化过程中特征图分辨率逐渐下降的问题。DeepLab-v1的另一个改进点为添加了空洞卷积,大大提高了运行速度。DeepLab-v1模型分割流程如图5所示。

图5 DeepLab-v1模型分割流程Fig.5 DeepLab-v1 model for the split process
DeepLab-v2网络结构与DeepLab-v1结构类似,同样使用了CRF模型来提高分割精度,同时使用了带孔算法来扩展感受野。该网络使用了空洞空间卷积池化金字塔(Atrous Spatial Pyramid Pooling,ASPP)模块,采用不同采样率的空洞卷积对特征图进行并行采样,并将输出结果进行融合,以此可以获得更多的空间信息。另外,该网络将传统的VGG-16模块替换为ResNet模块,进一步提升了分割效果。
DeepLab-v3[13]对之前的DeepLab做了进一步的改进。该网络重点研究了网络中空洞卷积的使用,提出将级联模块采样率逐步翻倍,同时扩充了DeepLab-v2模型中的ASPP模块,增强了其性能。该网络在PASCAL VOC 2012数据集上获得了比之前的DeepLab更好的分割结果。
2.1.6 其他
自从U-Net网络提出后,其良好的分割效果激起了许多研究者的兴趣,各种基于传统U-Net网络的新方法开始被提了出来。在医学影像领域,部分医疗影像器械生成的影像是三维的,针对三维影像的分割任务,Çiçek等人[14]提出了3D U-net网络结构,更改下采样层数为3层,每个卷积层后添加了批归一化(Batch Normalization,BN)。Milletari等人[15]提出了V-net网络结构。V-Net结构是U-Net网络结构的一种3D变形,使用三维卷积核对图像进行卷积操作,利用1×1×1的卷积来减少通道维度。该结构在模型训练中引入了一个新的目标函数,能够解决图像中的类别不平衡的问题。Drozdzal等人[16]提出,U-Net网络结构中的长跳跃连接结构也可以用短跳跃连接结构代替。
对于FCN网络结构存在的缺陷,不少研究者对其进行了调整改进。对FCN解码器部分做出改进的有上面提到的SegNet网络和DeepLab系列网络,除此之外,FCN的编码器结构通常为经典分类网络,如VGG[17]、ResNet[18]及DenseNet[19]等。
由于FCN和SegNet等分割网络大多基于VGG架构,对于多分类任务其模型参数众多、推理时间过长。为了让分割模型更加轻便且精准,2016年Paszke等人[20]提出了高效神经网络(Efficient Neural Network,ENet),使其具备了进行实时逐像素语义分割的能力。具体来说,ENet的执行速度快了18倍,且需要的浮点运算次数少为1/75,同时参数减少为1/79,并且提供了与当时现有模型对比相似或更高的精度。在结构上,ENet通过保留编码网络中最大池化过程中最大值的索引,并借此在解码网络中生成稀疏的上采样特征图来降低下采样和上采样过程的分割精度丢失。
为了缓解语义分割模型为获得丰富的特征而过度依赖预训练网络导致定位精度降低的问题,Pohlen等人[21]创新性地提出了一个类似于ResNet的网络架构FRRN,使用两条支路将多尺度上下文信息和像素级识别的精度结合。一条支路携带全分辨率信息,用于实现边界的精准分割;而另一条支路经过一系列池化层获取用于识别的丰富特征,最后两条支路使用FRRNs单元做耦合。
要想在复杂场景中实现高精度的分割,往往需要使用空间金字塔池化来获得全局图像级特征。为了结合适当的全局特征,Zhao等人[22]提出了金字塔场景解析网络(Pyramid Scene Parsing Network,PSPNet)。通过金字塔池模块和PSPNet,聚合基于不同区域的上下文信息,从而提高网络在全局挖掘上下文信息的能力。为了解决全分辨率残差网络计算密集导致其在全尺度图像上推理速度缓慢的问题,PSPNet采用了4种不同的最大池化操作,这些操作分别对应4种不同的窗口大小和步长。
2.2 图像分割算法优劣和性能比较
基于深度学习的图像分割方法的技术特点和优缺点如表1所示。

表1 图像语义分割方法优劣比较Tab.2 Comparison of image semantic segmentation methods
针对算法的性能方面,在PASCAL VOC 2012数据集上,FCN、DeepLab-v1、DeepLab-v2、DeepLab-v3和PSPNet评估的mIoU值分别为62.2%、72.6%、79.7%、86.9%和85.4%。在CityScapes数据集上,FCN、DeepLab-v1、DeepLab-v2、ENet、FRRN和PSPNet评估的mIoU值分别为65.3%、63.1%、70.4%、58.3%、71.8%和81.2%。在PASCAL-CONTEXT数据集上,FCN和DeepLab-v2评估的mIoU值可达到35.1%和45.7%。在CamVid数据集上,SegNet和ENet评估的mIoU值为55.6%和51.3%。目前对静态图像进行语义分割时,大部分算法选用PASCAL VOC 2012作为测试数据集,当对动态场景进行解析或实时图像语义分割时,很多算法选用CityScapes作为测试数据集。基于PAS CAL VOC 2012测试数据集,DeepLab V3和PSPNet算法的mIoU值都超过了80%,对图像数据中不同尺度物体有较好的识别率,目标分割结果的边界比较接近真实分割边。
2.3 医学图像分割技术难点
医学图像具有的一些独特的特点,使得医学图像的分割比自然影像的分割更为复杂。具体表现为:
① 数据量少。精细标注的自然图像数据规模很大,相对而言,医学影像数据由于标注复杂、涉及隐私问题等限制,获取比较困难。数据量多时,模型不需要有很好的可解释性,训练一个好的模型相对容易。而数据量很少时,需要给模型提供足够多的先验知识来保证模型能够学到关键特征,同时要控制参数量来防止过拟合。
② 目标较小。大部分医学图像中的目标非常小,且形状不规则、边界模糊、梯度复杂,而医学图像的分割要求高精度,因此需要给模型输入较多的高分辨率信息来保证精准分割。
③ 图像语义简单。医学图像的上下文信息对于人体疾病的诊断非常重要,而由于器官的结构都较为固定,图像中的语义信息不够丰富,因此要求模型在训练过程中充分利用低分辨率信息来保证对目标的精确识别。
④ 多维图像。自然图像均为二维数据,而医学图像大多为三维数据,需要三维卷积来提取数据中的三维信息,增加了参数量,易过拟合。
⑤ 多模态。相比于自然图像,医学图像具有多种模态的数据,如OASIS-3数据集中,既有MRI图像,也有PET图像。不同模态的数据具有其独特的特点,在某一类数据上训练得到的模型,不一定适用于其他数据,这就要求模型能够提取不同模态的特征,从而提高模型的泛化能力。
医学图像的这些特点,决定了医学图像分割必须使用编码器-解码器结构的网络模型。医学图像分割技术的高难度、高复杂度,是使医学图像分割在图像分割领域中受到特别关注的主要原因。
3 分割算法在医疗影像领域的应用
3.1 基于FCN
Zaho等人[23]在2018年在脑肿瘤分割任务中提出一种新的分割框架,该框架将FCN和CRF组合,可以实现具有外观和空间一致性的分割。首先将图像补丁输入到FCN中进行训练,再将图像切片输入到CRF中用递归神经网络(CRF-RNN)对其进行训练,最后将图像切片送入FCN和CRF集合框架中,对FCN和CRF-RNN的参数进行联合微调。
Lessmann等人[24]提出了一种基于FCN的迭代实例分割方法,用于CT图像中的自动椎骨分割。提出的分段网络体系结构受U-Net体系结构的启发,即网络由压缩、扩展路径和中间跳跃连接组成。
多器官分割任务中,Tong等人[25]提出了一种新的分割模型,将形状表示模型集成到FCN中。在另一项多器官分割任务中,Roth等人[26]针对3D图像的语义分割提出一种3D FCN模型,在腹部CT图像中的器官分割任务中取得了不错的成绩。
3.2 基于U-Net
Brosch等人[27]提出一种深3D卷积编码网络,该网络具有捷径连接,将U-Net网络的第一层卷积和最后一层反卷积连接,并将该网络应用于脑部MRI中的脑白质病灶分割,实验证明该网络在小规模训练数据集上仍能训练出较好的模型。
Bai等人[28]在MR图像中主动脉序列的像素分割任务提出一种将U-Net和CRF-RNN相结合的图像序列分割算法,将空间和时间信息结合到分割任务中,通过在注释上执行非刚性标签传播和引入指数加权损失函数来实现对模型的端对端训练,其结构如图6所示。
对于图像配准任务,Lv等人[29]在U-Net网络基础上提出一种完全自动化的框架,用以解决肾脏器官由于呼吸运动效应产生伪影造成误差大的问题。首先采用U-Net网络对肾脏图像进行分割,获取肾脏轮廓,再将分割后的图像标记为注册方法的感兴趣区域。

图6 U-Net与RNN结合结构Fig.6 Combined architecture of U-Net and RNN
3.3 其他
Oktay等人[30]提出一种专门用于医疗图像的注意门(Attention Gate,AG)模型,该模型主要对形状和大小不同的目标结构进行自动学习。AG模型在训练过程中隐式地学习到了图像的显著特征,因此可以不使用基于卷积神经网络的显式外部组织/器官定位模块。Kamnitsas等人[31]采用一种双通道结构来合并局部信息和全局信息,该结构可以同时在多个尺度上处理输入图像,该方法提高了图像分割的精度。Wang等人[32]提出一个对伤口图像进行处理的系统,可以实现对图像中的伤口区域自动分割并分析伤口状况。伤口图像输入深卷积神经网络(ConvNet),自动分割出输入图像中的伤口区域,得到的分割图像送入SVM分类器中进行判断伤口是否感染,并通过高斯过程回归算法对伤口的愈合进程进行预测。ConvNet架构如图7所示。

图7 ConvNet结构Fig.7 Architecture of ConvNet
4 数据集与损失函数
4.1 数据集
常见的深度学习分割网络属于有监督学习算法,在训练时需要使用大量带标签的数据。由于医学图像的注释一般需要医学专家或有专业知识的人士参与,这加剧了图像标注的难度。而且,与一般计算机视觉任务的数据集(通常是几十万到数百万个带注释的图像)相比,当前可用于医学图像分割任务的公共数据集规模都很小。
想要充分了解图像分割,首先需要了解图像分割任务中那些质量最好的各种数据集。以公共数据集作为基准,可比较各种医学图像分割模型的性能与精度,从而公平地评价模型的好坏。本节整理了目前医学图像分割任务中常用的数据集,如表2所示。

表2 医学图像分割数据集Tab.2 Datasets of medical image segmentation
4.2 损失函数
医学图像分割常用的损失函数:
① 交叉熵损失函数
(2)
式中,M表示类别数;yc只有0和1两种取值,如果该类别和样本的类别相同,yc取1,否则取0;pc表示预测样本属于c的概率。
交叉熵损失函数可以用在大多数语义分割场景中,其明显缺点为:对于二分类问题,当前景像素的数量远远小于背景像素的数量时,即此时yc=0的数量远大于yc=1的数量,损失函数中yc=0的成分就会占据主导,使得模型严重偏向背景,导致效果不好,不适用于医学图像中小目标分割任务。
② 带权重交叉熵损失函数
(3)
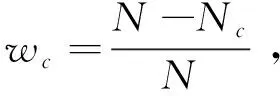
③ Focal损失函数
Focal损失函数是为了解决目标检测中正负样本比例严重失衡的问题而提出,如今广泛应用于医疗图像分割领域。二分类Focal损失函数为:
(4)
式中,γ>0,减少易分样本的损失,使网络更关注困难、错分的样本。平衡因子α用来平衡正负样本比例不均衡的问题。该损失函数降低了大量简单负样本在训练中所占的权重,实现了困难样本挖掘。
④ Dice损失函数
Dice系数是一种衡量集合相似度的指标,通常用于计算两个样本的相似度,值范围为[0,1],计算公式为:
(5)
式中,|X∩Y|为X和Y之间的交集,|X|和|Y|分别表示X和Y的元素个数。对于图像分割任务,X和Y分别表示真实分割图和预测分割图。
Dice损失函数定义为:
(6)
Dice损失函数适用于正负样本极度不均衡的情况,一般情况下使用Dice损失函数会对反向传播产生不利的影响,使得训练变得不稳定。
⑤ Jaccard损失函数
Jaccard系数用于比较样本之间的相似性与差异性,值范围为[0,1]。类似Dice,其计算公式为:
(7)
式中,|X∩Y|与|X∪Y|分别表示X和Y之间的交集与并集。Jaccard损失函数定义为:
(8)
与Dice函数一样,存在不稳定的问题。
⑥ Tversky损失函数
Tversky系数是Dice系数和Jaccard系数的广义系数,计算公式为:
(9)
对于图像分割任务,X表示真实分割图,Y表示预测分割图。Dice系数是Tversky系数中α与β都等于0.5的特殊情况,而Jaccard系数是Tversky系数中α与β都等于1的特殊情况。其中|Y-X|代表假阳性,|X-Y|代表假阴性,通过调整α与β超参数来控制二者间的平衡,进而影响召回率等指标。
5 总结与展望
相对于传统的医学图像分割方法,基于深度学习的分割方法消除了人为参与,在医学图像处理领域扮演着越来越重要的角色。但通过对比各深度学习分割相关的文献可以发现,现阶段的深度学习分割网络的发展演进存在一定的困难和挑战。
① 如今医学图像的分辨率越来越高,而目前的计算机硬件设备很难支持对高分辨率图像的处理,通常需要对图像进行裁剪,分块送入网络进行训练,这就限制了网络提取更多的空间信息。
② 医疗影像数据集较难获得。医学图像分析中的不同任务对数据的标注要求不同,适用于深度学习模型的数据集很少,且医学图像数据集通常规模较小,而训练数据的规模直接影响了深度学习模型的训练效果,过少的训练数据容易造成过度拟合,使得模型在其他数据集上表现很差。
③ 医学图像数据集通常都有样本不平衡问题。如臂丛神经分割数据集,神经元目标较小,整张图像中含有大部分的背景,用不平衡的数据训练深层网络可能会导致模型产生偏差。
深度学习下的医学图像分割对于疾病的诊断治疗具有重大意义,为了应对上述挑战,越来越多的研究者投入到医学图像处理领域,开始着力于探索新的创新。
① 半监督或无监督条件下的图像分割。有监督训练下的模型对于某些需要大量训练数据的模型很难发挥其效能。在缺乏标注数据的问题下,半监督或无监督条件下的图像分割将是未来的主要研究方向之一。
② 生成式对抗网络生成数据集。将GAN框架生成的图像数据与原始数据进行结合共同参与模型训练可以提高模型性能,这一特性对于医学图像分析尤为重要。如何对原始数据和生成数据进行合理分工以使训练模型达到最优性能是当下及未来需要解决的一个重要问题。
图像语义分割应用广泛,深度学习在医学成像方面的进展吸引了计算机视觉领域的专家参与解决医学图像分割任务。面对医学图像分割领域的重重困难,医学影像界正在付出更多努力,不断开发新理论和新技术来开拓应用前景。深度学习在医学图像分割方面的突破,将对医疗领域的发展做出巨大的贡献。
