基于卷积神经网络的业务识别
2021-04-22王佳妮王云峰夏振飞赵力强
王佳妮,王云峰,夏振飞,赵力强
(西安电子科技大学,陕西 西安 710071)
0 引言
网络业务识别问题由来已久。传统的业务识别在获取特征时较困难,影响业务识别的精准度,而现有的特征选择与提取方法需要研究者付出大量的时间和精力。因此简化业务识别特征的提取方法是本文的研究重点。
文献[1-4]使用支持向量机、朴素贝叶斯等方法对流量特征、有效载荷特征和混合特征进行分类。针对软件定义网络(Software Defiend Network,SDN)网络,大多数业务识别方案主要运用人工提取特征的方法或者直接使用公开的数据集[5-6],但是存在特征提取较为复杂,特征提取工程的设计严重影响识别的精度等问题。深度学习则可以避免这类问题,在业务识别中具有许多优势[7]。文献[8]提出在业务识别中引入卷积神经网络(Convolutional Neural Network,CNN)模型的方法,把分组序列转化成图像,获得了较高的分类准确率。但考虑到实际情况下网络采集到的样本数有限,不利于模型的训练,文献[9]充分利用生成对抗网络(Generative Adversarial Network,GAN)数据扩充的优势,为样本较少的类生成流量数据。因此,本文针对上述问题,研究了一种基于CNN的业务识别。
1 基于CNN的业务识别系统
1.1 系统模型
传统的封闭式网络架构无法同物联网业务和垂直行业的差异化需求相适配。SDN作为一种新的网络技术,在体系架构、运行方式上发生了很大变化。因此,本文利用SDN集中式控制的特点,在SDN的3层网络架构中引入了CNN和GAN,设计了如图1所示的基于CNN的业务识别系统模型。
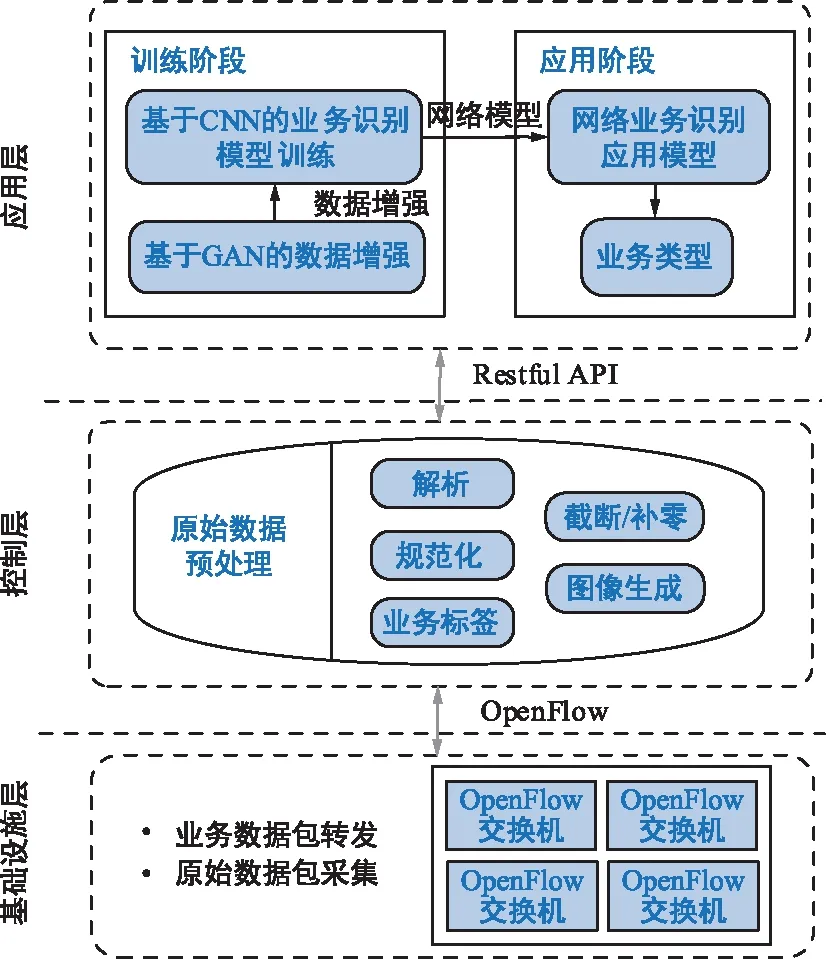
图1 系统模型Fig.1 System model
基础设施层主要由交换机等组成,它们具有转发功能。该层主要完成网络中业务数据的转发和原始数据包的采集,并将采集的数据包通过南向接口上传到控制层。
控制层主要由控制器组成,完成网络管理、网络状态获取以及原始数据预处理等功能。控制层采用解析、截断/填充、图像生成、规范化以及业务标签等功能模块将原始数据预处理,转换成二维的灰度图像,从而构建样本集,并通过北向接口上传到应用层。
应用层包括面向用户的许多业务和应用,业务识别与分类应用也部署在该层。其中一部分样本集输入到GAN模型中完成数据的增强产生生成样本,再将混合样本(即剩余的实测样本与生成样本的集合)共同输入到CNN模型中完成模型的训练。训练后的业务识别模型可以直接通过北向接口进行调用。
1.2 场景模型
本文依托于SDN网络,设计了具有3种特征明显且特征相差较大的业务应用场景。业务1是高带宽的视频业务;业务2是对网络要求低,数据量较少的万维网业务;业务3是要求低时延的游戏业务。终端可以通过交换机接入到SDN网络中,随时享受3种业务的服务,交换机也可以获取到业务数据流的原始数据信息。将数据预处理的过程部署在SDN控制层,充分利用了控制器集中管控的功能,使不同业务数据流的分流过程更方便,便于样本集的建立。
2 基于CNN的业务识别方案
2.1 基于CNN的业务识别方案设计
2.1.1 CNN
CNN[10-11]是一种有深度学习能力的,可以深层次前向传播的神经网络,主要应用于计算机视觉等领域。二维CNN基本组成结构分为输入层、卷积层、池化层、全连接层和输出层,可以利用卷积核和池化层实现图像特征的自动提取。CNN在减少学习参数数量方面有明显的优势,从而优化了反向传播(Back Propagation,BP)算法,实现的方式主要有局部感知、参数共享及池化等[12]。
2.1.2 基于CNN的业务识别与分类模型
针对传统的基于流统计特征的分类方法,特征选择与获取过程较为困难,且特征提取工程的设计过于复杂等问题,本文采用CNN模型自动完成特征的提取,业务识别与分类模型如图2所示。
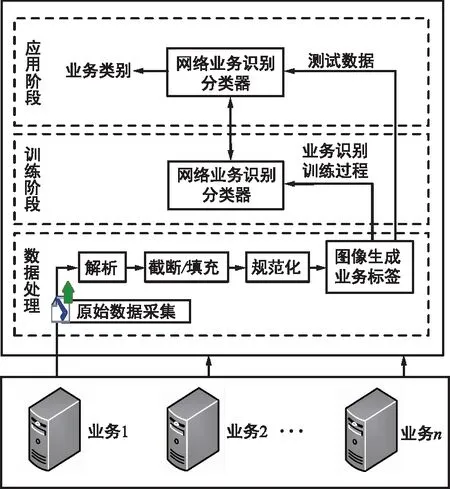
图2 基于CNN的业务识别与分类模型Fig.2 Traffic identification and classification model based on CNN
在数据处理阶段,为了使采集到的数据可以直接被CNN模型读取,需要对其进行预处理,该过程主要包括原数据的解析、截断/填充、规范化、图像生成和业务标签的标注。其中,解析是将采集到的数据按照会话标准进行划分,再删除数据包中多余的信息,如数据链路层数据、IP地址等;截断/填充是将数据包中的字节数进行统一,多余的部分进行截断,否则进行补零操作;图像生成采用进制转换的方式将数据包中的内容转换成二维灰度图像像素点的取值,从而得到带有业务特征信息的灰度图像;规范化是对图像中像素点的数值进行归一化,使CNN模型的处理更加方便;业务标签通过提取包含业务类型名称的字段对样本进行标注。经过此过程,将原始数据转换成带有业务特征信息的二维灰度图像,之后采用十折交叉验证法[13],将生成的图像数据集划分成训练集和测试集。
在训练阶段,将划分后的训练集输入到业务识别模型中自动完成特征的提取,并根据提取的特征进行模型的训练,不断调整模型参数,生成业务识别模型。在此阶段,CNN的层数设定、卷积层和池化层的连接顺序、卷积核的大小与数量以及激活函数等的选择等都会影响模型的训练效果。
在应用阶段,利用测试集对训练阶段得到的业务识别模型进行测试,验证模型的可靠性,并将此模型实际部署到应用场景中。
2.1.3方案测试与结果分析
表1为3种业务的平均准确率,视频业务的准确率相对Web和在线游戏来说较高,由于3种业务的样本集不平衡,导致识别的准确率有一定的差距。在采集原数据时,视频业务传输的数据包相对较多,可以用来构建的样本数较多,模型训练相对其他两种较好。

表1 3种业务类型准确率
CNN模型训练集与测试集平均准确率如图3所示。由图3可以看出,在数据集样本数小于10 000时,利用训练样本集测试的结果在90%以上,但是利用测试样本集测试的结果在80%以下。原因主要是模型训练过程出现过拟合的现象,使模型可以很好地契合训练集,但在测试集上效果不佳,而随着数据集样本数量的不断增大,模型在测试集上准确率明显有所提高。由此可以看出在业务识别的研究中,亟待解决的问题是缺少足够的数据集。下一节将针对这一问题给出解决方案并进行展开叙述。

图3 CNN 模型训练集与测试集平均准确率Fig.3 Average accuracy of training set and testing set of CNN model
2.2 基于CNN-GAN 的业务识别方案设计
2.2.1 GAN
GAN是一种生成式深度模型,主要采用反向传播的思想,不需要马尔科夫计算过程,在无监督学习或者半监督学习中应用广泛[14]。它由生成网络和判别网络组成[15]。
将随机噪声输入生成网络中,经过计算输出一组数据;判别网络接收输出的数据,并根据之前学习的真实数据分布状况,判断接收数据是否是真实的数据,同时输出一个概率,生成网络学习真实样本的分布状况,生成尽可能逼近真实的数据;判别网络也在提升自己与生成网络的博弈能力,尽可能地识别出真假。
2.2.2 基于CNN-GAN的业务识别与分类模型
针对过拟合和数据不均衡的问题,在上一节的基础上设计了如图4所示的业务识别与分类模型。基于GAN的数据增强可以学习实测样本数据的分布,生成一定数量的无限逼近实测样本集的生成样本集,再将混合样本集输入到CNN中进行模型的训练与调整,即可构建出业务分类模型。
数据增强的具体过程如下:在GAN网络中,随机噪声经过生成网络生成输出样本,并输入到判别网络中进行判别,而判别网络尽可能将生成样本集与实测样本集区分开,最后生成网络与判别网络之间不断进行对抗博弈得到一个最优解,即生成网络获得实测样本集的分布规律并生成了无限逼近于实测样本集的数据,而判别网络最终也无法对数据的真假做出判断。

图4 基于CNN-GAN的业务识别与分类模型Fig.4 Traffic identification and classification model based on CNN-GAN
2.2.3基于GAN的数据增强
本节中增强的样本集是经过预处理得到的包含业务特征的二维灰度图像组成的样本集。GAN在本质上是由2个神经网络组成,因此在使用GAN模型时,采用CNN搭建生成网络与判别网络。生成网络由全连接层和反卷积层组成,先将噪声输入到模型中,经过全连接层的计算,使噪声在维度上发生了变化,然后经过反卷积层得到输出的结果,也就是生成图像的样本。判别网络由卷积层和全连接层组成,卷积层提取图像样本特征,经过全连接层之后得到判别结果。
2.2.4 方案测试与结果分析
GAN模型根据实测的样本,产生一定数量的生成样本,样本数量如表2所示。由表2可以看出,增加了生成样本数量之后,样本间的不平衡现象有所改善,业务识别的准确率有所提升。

表2 样本集数目及准确率
如图5所示,采用混合样本之后,数据集样本数达到了26 000多,每种业务的识别准确率提高到了96%左右。由此可见,在采用CNN-GAN模型使样本数据增强的同时,也很好地解决了过拟合的问题,提高了业务识别的准确率。

图5 数据集样本数与准确率折线图Fig.5 Line chart of data scale and accuracy
3 结束语
本文主要研究了一种基于CNN的业务识别方案。首先,对基于CNN的业务识别系统模型和实现场景进行了描述,提出一种基于CNN模型的业务识别方案,简化了业务流特征的提取过程。为了更好地提高业务识别的准确率,在之前建立的系统模型基础上,综合考虑CNN与GAN各自的特性,将二者相互结合,探究了基于CNN-GAN的业务识别方案,有效解决了业务识别过程中出现的过拟合以及样本数据不平衡等问题,为业务识别准确率的提升提供了一种可选方案。
