基于Hadoop的高效率海量电子通信信息存储方法
2021-04-21刘苏英张晴晴
刘苏英,张晴晴
(安徽机电职业技术学院,安徽 芜湖 241002)
0 引言
互联网与智能技术盛行的时代,网络信息在消息传达中起到不可替代的作用,人们的电子通信意识与理念也随之日益更新[1]。社会各领域信息传递需求量千差万别,其中不乏大规模电子通信信息的传递与存储,为高效率、低能耗解决海量电子通信信息存储问题,本研究基于Hadoop集群构建大规模信息存储模型[2]。Hadoop集群框架属于开源云平台,创造了HDFS文件系统、MapReduce并行式计算模型的运行环境,打造了良好的海量电子通信文件信息存储条件[3]。本文提出的Hadoop海量电子通信信息存储方法不仅构建了Hadoop集群存储模型,并且使用动态优先级负载均衡调度算法协调海量信息存储任务,减少存储节点的能量消耗与负载情况,实现高效率、低能耗信息存储目标。
1 基于Hadoop的高效率海量电子通信信息存储技术
1.1 基于Hadoop集群的云存储模型设计
传统的Hadoop集群利用单节点主从结构存储文件,其缺点是对中心存储节点造成极大压力,甚至发生电子信息存储停滞问题。为此利用图1所示的单节点双层Hadoop结构代替传统的主从结构,分担节点压力。
主Hadoop结构的分析节点用于控制中心节点集群,基于用户信息向服务器分配存储任务。电子通信信息资源元数据全部保存在中心节点集群中,以Hadoop平台的元数据为基础构建完整的数据库。数据管理节点属于低层次的数据节点集群控制单元,集群的心跳数据检测、节点能量均衡负载、集群的其他事务管理均在此单元中进行,不具备元数据存储功能[4]。

图1 单节点双层Hadoop结构图
Hadoop集群环境中,存储客户端是电子通信信息上传、接收行为的发出者,即电子信息传输到HDFS文件系统的行为由客户端完成。Hadoop集群存储结构打造一个数据缓存单元作为发送端传输数据的存储模块,以降低存储系统同硬盘交互的频次,增强Hadoop集群存储电子信息的效率[5]。数据缓存单元存储规模自适应确定,一般

图2 基于数据缓存单元的海量电子通信信息存储步骤图
为128MB大小,如果缓存单元已满此时数据自动传输至HDFS文件系统内,此过程实现步骤见图2所示。
1.2 基于MapReduce的电子通信信息并行计算存储模型
MapReduce并行计算是Hadoop集群处理海量分布式数据存储问题的优质编程模型,具有优秀的并行计算性能[6]。MapReduce并行计算的原理是分担海量数据计算任务,同时开展大规模电子通信信息的计算行为,以合并的方式统计最终的处理结果[7]。图3描述了MapReduce计算模型处理数据的基本原则。
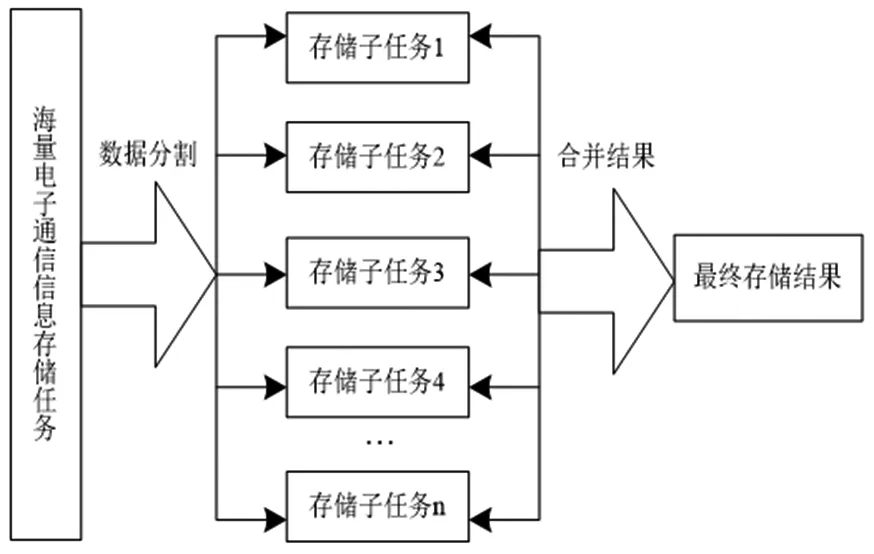
图3 MapReduce计算模型处理数据的基本原则
MapReduce计算模型处理海量电子通信信息存储任务时,基于分割法将数据划分成若干个子任务,每个计算节点担负均衡的计算任务,这样在相同的时间内可以完成更多数据计算任务,节约了Hadoop存储数据的时间开销。
1.3 基于动态优先级负载均衡调度算法的节点均衡负载算法
本文方法的创新之处在于使用Hadoop存储海量信息的同时,基于动态优先级负载均衡调度算法均衡存储节点的负载情况,避免个别或者少数节点负担过重,既能节约数据存储的时间又能延长Hadoop存储系统节点的使用寿命[8]。动态优先级负载均衡调度算法实时动态监测存储系统子节点的负载情况,精准计算节点的存储数据的负载量,根据负载量协调分配电子通信信息的存储任务。
Hadoop集群的MapReduce模型任务调度依赖于JobTracker和TaskTrasker实现,其中JobTracker与节点任务调度息息相关,用于实时监测与控制节点运行状态,对存储资源进行有效管理。心跳数据是动态优先级负载均衡调度算法实践的核心依据,此变量由TaskTrasker定期采集反馈,算法基于心跳数据求取节点负载量以及队列任务承担水平[9],据此生成能够减少电子通信信息文件存储时间的动态优先级G。算法实现的步骤如下:
1)定义k表示当前并行任务数量,队列承载能力为D,求取这两个参量值,当k达到并行任务数量上限值时执行步骤7,否则按顺序操作。
2)D值最大的队列负责接收JobTracker发送的数据存储任务,全部队列遍历后基于优先级排序信息存储任务;进而求取正常运行节点的负载量获取最大值的健康节点,如果此节点符合队列任务执行资源标准则按顺序步骤操作,反之执行步骤6。
3)判断当前节点是否属于健康节点范畴,若属于执行步骤4,若不属于执行步骤5。
4)当前节点资源协调到当前任务上,执行步骤1。
5)标记此节点的状态为“非健康”,继续选出最大值负载量的健康节点。
6)由其他队列接收当前存储任务,继续遍历队列,根据优先级排序任务列表。
7)终止节点任务调度与分配,动态优先级负载均衡调度算法结束。
算法中队列承载能力计算方法如公式(1)所示:
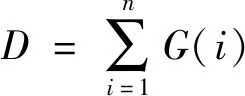
(1)
其中,G为普通健康节点的负载能力。
算法采用公式(2)描述的方法优化优先级计算方法,以减少小型任务排队等待的时间过长而降低信息存储效率:
(2)
公式中,ta、tb分别表示任务等待队列的时间开销、任务资源量需求。此表达式中队列等待时间越长、任务优先级则越大;任务资源量需求越小、任务优先级越大,满足了海量电子通信信息存储时间降低、效率提升的需求。
2 实验与分析
使用Hadoop1.2版本集群利用虚拟机搭建Hadoop集群存储环境,展开海量电子通信信息存储测试,以验证本文方法在大规模信息存储中的有效性及优势。实验集群包括4个节点,其中1个节点命名为Master,其余3个节点命名为Slave。实验系统版本为Linux Redhat9.0,实验数据为采集自某企业的海量电子通信信息数据集,为了突出本文方法的性能优势,采用传统Hadoop海量信息存储方法、基于云计算的海量信息存储方法进行对比测试。
本次研究主要测试了本文方法存储的时间消耗情况,测试期间选取2000个同等规模的电子通信数据作为测试集,记录了文件数据增加情况下3种方法存储文件的时间开销情况,如表1所示。
由表1数据可知,随着文件数量的增加,本文方法存储时间稳步增长,但增加幅度不大,存储1000个文件仅花费0.69s,存储2000个文件时间开销为1.27s,基本处于小幅度增加状态。相比之下,传统Hadoop海量信息存储方法在处理200个文件的初始阶段时间消耗便持续高走,当文件数量增加至1000个,存储时间达到1.38s,最终处理2000个文件的时间开销为2.68s。基于云计算的海量信息存储方法由于使用了云计算技术,在数据存储初期取得了较好的存储效率,但是文件数量由1400个增加至1600个的过程中,时间骤然增加0.31s,文件增加至1800个时,时间开销增加了0.47s,增幅较大,文件增加到2000个时,仅花费了0.12s,恢复了正常的数据存储效率;此情况是由于该方法没有进行均衡负载计算导致的,令部分节点过多承载存储任务,呈现了存储时间的阶段性波动。

表1 3种方法存储文件的时间开销(s)
3 结论
本文详细研究了海量电子通信信息的高效率存储问题,搭建Hadoop集群模型,最关键的是使用动态优先级负载均衡调度算法对集群存储节点任务进行均衡调节,降低部分节点任务负载量,避免节点过多承载数据存储任务而增加存储信息的时间开销,降低节点硬件使用寿命。最后在测试中验证了本文方法存储海量电子通信信息的高效性,具有一定的推广应用价值。未来关于电子通信大数据存储问题研究的重点将放在如何降低存储系统整体时间开销方面,从宏观角度提高海量文件信息存储效率。
