基于关联分析的计算机软件数据挖掘技术
2021-04-21陈翠娟
陈翠娟
(福州理工学院,福建 福州 350506)
计算机硬件技术的发展为软件应用创造了良好条件,现代信息社会各领域工作离不开软件的应用,软件应用为各行业信息整理与快速获取创造便利[1]。计算机软件应用过程中随时产生大规模的应用数据、日志信息,反映了软件运行的一定规律。对于企业而言,计算机软件可能蕴藏海量有价值的财务信息、管理运营数据、人力资源管理信息,对其进行有效挖掘才能更好地利用这些软件大数据,提取有价值信息为企业运营创造利益[2]。本研究利用关联分析原理充分挖掘计算机软件内部蕴含的大数据,提出了基于改进Apriori算法挖掘计算机软件事务数据库的关联规则。
1 基于Apriori算法的计算机软件数据挖掘方法
1.1 Apriori算法基本原理
Apriori算法是以迭代的方式获取数据候选项集,利用剪枝操作选取候选项集中的频繁项集,在此基础上不断获得候选项集、生成频繁项集,当出现频繁项集量最大时可以终止迭代[3]。在Apriori算法中存在事务集合{G1,G2,…,Gm},也称为事务数据库,其中由差异项或者差异属性组成的集合可以表示为{I1,I2,…,In}。Apriori算法的项目集表示为E,包括E的事务集与事务总量的比值E⊆I称为支持度,频繁项集由此可以定义为“支持度不小于支持度阈值的项目集”,其余项目集则属于非频繁项集[4]。公式(1)为支持度计算公式,支持度表示数据库同时包含A和B事务的百分比:
supp(A⟹B)=P(AB)
(1)
公式(1)解释为在事务数据库中,数据库包含A与包含B的比值情况。
基于Apriori算法对计算机软件数据进行关联分析的过程基本分为两个步骤:一是找到软件事务数据库的全部频繁项集,定义为L;二是在L中获得软件数据之间的潜在关联规则。
Apriori算法的频繁挖掘特征使其对内存有较高的要求,经典的Apriori算法挖掘关联规则过程中效率不高、消耗内存较大,成为普遍存在的问题[5]。上述两个步骤描述中,前者是Apriori算法性能的关键保障,频繁项集挖掘复杂、计算量大将导致算法迭代用时增加,最终挖掘结果的效率与精准度难以保障;而后者相对前者的实现方法更为简单,并且比较依赖上一步骤获得的结果,所以,该研究在经典Apriori算法基础上着重优化“计算机软件数据频繁项集选取”这一步骤,提升整个算法挖掘关联规则的精准度,以获得计算机软件数据之间的强关联规则。
通过两种策略降低Apriori算法复杂度、减少扫描事务数据库的频次。首先构建双重支持度阈值规则,作为基于支持度筛选频繁项集的条件;其次重新组建原始事务数据库结构,减少连接与剪枝工作量[6]。这两种改进策略一方面可以提高频繁项集选取的冗余程度,精准获得计算机软件数据挖掘的强关联规则;另一方面节省Apriori 算法在频繁项集挖掘部分的计算量,减少算法的内存占用量,进而提升计算机软件数据挖掘的效率。
1.2 基于双重支持度阈值的频繁项集选取
事务数据库生成候选项集之后需要在其中挖掘出强关联的频繁项集,一般Apriori算法仅采用一种支持度阈值约束频繁项集的产生,导致有效频繁项集的效率较低、准确度不高。双重支持度阈值规则是针对非频繁项集与频繁项集选取步骤而制定的,可以在短时间内去除兴趣度不高的非频繁项集。
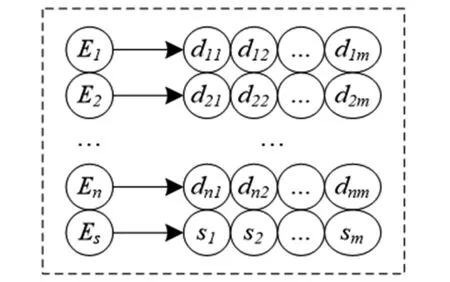
在数据项集E={e1,e2,…,en}中,为随机k-项集A定义两个支持度阈值,即非频繁项集阈值和频繁项集阈值,也称为两种项集的最小支持度,分别用H1、H2表示,且H2大于H1,二者均在0之上。通过以上规则判断当前项集分类型[7]:(1)若项集A为频繁项集,此时supp(A)≥H2;(2)若项集A为非频繁项集,此时supp(A) 为了进一步减少事务数据库频繁项集选取工作量,对事务数据库结构进行重构,以省略不必要的连接与剪枝[9]。重构数据库的具体方法是基于映射结构存储计算机软件数据库的事务,达到压缩事务数据库的目的。基于映射的事务数据存储原理如下:定义项目集合为E={e1,e2,…,en},R表示其中的一个事务,图1为计算机软件数据事务库映射结构图。 图1 计算机软件数据事务库映射结构图 图1中一维数组是指Ek与Es的对应值构成的数组,其中dij计算方法如下: dij={0,Ei∉Rj 1,Ei∈Rj (2) 其中,事务的数量采用m表示,i的取值在1~∣E∣之间,j的取值在1~m之间。 图1中计算机软件事务数据库的项集数量采用sj的值来描述,计算方法如公式(3)所示: (3) 公式中n表示项集的数量。 基于上述映射原理重新组建计算机软件数据事务库,压缩数据库的规模,同时基于双重支持度阈值对候选项集进行连接与剪枝,当不生成频繁项集时终止迭代,以选取强关联的计算机软件数据频繁项集[10]。 以某企业的人力资源管理软件作为数据挖掘对象,利用JAVA语言编写实验程序,在Windows7系统中展开数据挖掘测试。研究引入经典Apriori算法、GA-Apriori算法作为关联规则挖掘的对比算法,通过对比实验分析该算法的挖掘性能。测试的事务数据库包括2056条事务,测试前对事务库进行简单的词汇删除等预处理操作,避免增加关联规则提取的工作量。 基于本文算法得到某企业人力资源部分关联规则如表1所示。表1中具体给出了与高素质人才、高职称人才、高技术人才相关的关联属性,其支持度均低于频繁项集支持度0.35,符合频繁项集的支持度挖掘阈值标准。另外,与人力资源管理部分人员访谈得知,表1中数据挖掘结果全部符合实际情况,证明了本文算法挖掘人力资源类计算机软件数据的有效性。 表1 关联规则提取结果 为了解本文算法挖掘计算机软件数据的性能,记录了经典Apriori算法、GA-Apriori算法、本文算法挖掘在各个时间节点挖掘关联规则的数量,如图2所示。 图2 3种算法的关联规则挖掘性能对比 由图2可知,当挖掘关联规则信息数量为50时,经典Apriori算法、GA-Apriori算法、本文算法对应的时间分别为10min、12.1min、3.5min,随着挖掘结果的增多,本文算法时间开销增长最为缓慢,并且其他两种算法的时间开销曲线为较陡的上升曲线,可见处理相同数量的计算机软件数据挖掘工作时,本文算法具有良好的效率优势。具体而言,是因为本文算法基于映射规则重新构建计算机软件事务数据库,减少了Apriori算法不必要的连接与剪枝操作;在此基础上设置双重支持度阈值,同时提取频繁项集与非频繁项集,保障算法在较短的时间内获得强关联度的频繁项集。 本文对经典Apriori算法进行改进,改进对象为频繁项集挖掘环节,一方面设置双重支持度阈值,高精度、高效率选取计算机软件数据的频繁项集;另一方面重构事务数据库结构,利用映射规则存储事务数据,避免重复数据存储,大大压缩了事务数据库的规模。两种策略的根本目的均是减少频繁项集挖掘中的剪枝操作,减少不必要的计算量,降低计算复杂度。最后在实验分析中证明了本文算法挖掘人力资源类计算机软件数据的有效性,相比经典Apriori算法以及GA-Apriori算法,本文算法效率性能有所提高。1.3 基于映射规则重组事务数据库结构
2 实验分析
2.1 关联规则挖掘结果分析

2.2 挖掘算法的性能分析

3 结论
