基于YOLO v3的室内场景中人体检测方法的研究
2021-04-19马树波郑洪龙韩娟娟
石 强,葛 源,马树波,郑洪龙,韩娟娟
(中国核动力研究设计院,成都 610005)
0 引言
室内场景人体检测是指在24h 不间断对室内环境进行监控中实现对人体的识别。室内场景中,由于人体和物体或者人体和人体相互遮挡也为人体识别检测带来了困难。基于将候选框提取、特征提取、目标分类、目标定位统一于一个神经网络中的YOLO v3 网络,构建室内场景识别数据集,聚类anchor 的个数和规格,改进候选框分布,以及优化网络检测策略,提高人体识别在红外图片和遮挡情况下的精确度和实时性。
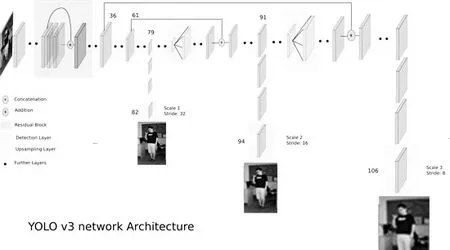
图1 YOLO v3结构图Fig.1 Structure of Yolo v3
1 YOLO v3
1.1 YOLO v3网络结构
图1 是YOLO v3 网络的整体网络架构,YOLO v3 网络总共有106 层,由残差模块、卷积层、上采样层,以及YOLO 层构成。
YOLO v3 是将网络中低高层的特征,通过卷积核多个矩阵的拼接工作,创建3 个尺度的预测输出。残差模块是为了解决由于网络加深导致的梯度爆炸和梯度消失的问题,通过跳跃连接,它可以直接将原始信息传送到后面的层中去,同时保证了参数的量不会太大;上采样的作用是将特征矩阵按倍数扩大,使用最临近插值算法将底层特征信息和上层特征信息进行融合;YOLO 层进行最终的预测检测。
1.2 特征提取
YOLO v3 采用了Darknet-53 的网络结构(含有5 组残差模块)来提取特征。其网络结构采用了横纵交叉结构,并采用了连串的3×3 和1×1 卷积。其中,3×3 的卷积增加通道数,而1×1 的卷积在于压缩3×3 卷积后的特征表示,同时Darknet-53 为了防止池化带来的低级特征的丢失,采用了全卷积层,并且引入了residual 结构。这意味着网络结构可以更好地利用GPU,从而使其评估效率更高、速度更快。Darknet-53 作为特征提取层,最终每个预测任务得到的特征大小为[3×(4+1+C)]。每个grid cell 预测3 个预测框,4 代表4 是边界框中心坐标bx,by,以及边界框bw,bh,1 代表预测值,C 代表预测类别。最终YOLO v3 可以获取(16×10+32×20+64×40)个特征向量。
1.3 坐标预测和类别预测
YOLO v3 网络在3 个特征图上进行目标预测,这些特征图上的grid cell 可以映射到原图上的一片区域。每一个grid cell 预测3 个bounding box,在训练的时候,如果ground truth 中某个object 的中心坐标落在哪个grid cell 中,那么就由该grid cell 来预测该object。在1.2 节可知,grid预测的初始3 个候选框的尺寸大小和宽高比是固定的,通过网络训练,平移和缩放初始候选框,最终得到逼近真实值的候选框。bounding box 的坐标预测方式由如下几个公式决定,其中W、H 为图片的宽度和高度,训练期间使用平方和距离误差作为损失误差总和。

其中,cx,cy——相对于图像左上角的坐标;pw,ph——初始候选框的宽度和长度;——需要网络学习的参数。类别预测方使用多标签分类,因此网络结构上采用多标签多分类的逻辑回归层。在一些复杂场景下,一个object 可能属于多个类,需要用逻辑回归层来对每个类别做二分类。逻辑回归层主要用到sigmoid 函数,该函数可以将输入约束在0 ~1 的范围内。因此,当一张图像经过特征提取后的某一类输出经过sigmoid 函数约束后,如果大于0.5,就表示属于该类。
2 YOLO_v3_H
2.1 构建室内场景人体识别数据集FHDRC
为了适应室内场景中的人体检测以及解决人体检测中人体相互遮挡的问题,以旷世的CrowdHuman 数据集为基础数据集,同时使用摄像头在不同时段、不同角度、不同光照强度下对不同数量人体进行拍摄,共得到1200 张图片。其中,有855 张彩色图片和345 张红外夜视图片,总共包含6345 个人体目标。最终,使用其中的1000 张构成原始训练集TR_A,包含5076 个人体,剩余200 张图片构成测试集,包含1269 个人体,构成原始测试集TE_A。为了减小光照对图像的影响,增加样本图像光照的多样性,使用自适应直方图均衡化对原始训练集TR_A 进行处理,最终得到TR_B。为了更好地让网络学习到人体特征,对训练样本进行扩增,扩增方式包括对样本进行±100,±200的旋转和水平镜像等操作,并对处理后的图像进行居中剪切,若处理后的图像目标残缺不全则舍弃,得到样本数据集TR_C。为了后面的对比试验,添加了一个1000 张全部为彩色图片的数据集TR_D。
室内场景中,人体检测的一大难点是对密集人群的检测,人体相互遮挡或者人体与家具相互遮挡给检测带来的困难。针对此种情况,提出使用训练样本目标前景区域标注加强人体前景区域卷积特征学习的方法。
首先,通过手工标注方法,对目标背景区域的像素置零,获得目标前景区域样本,并使用目标前景区域样本对改进后的YOLO v3_H 网络进行训练,降低边界框内非前景特征的干扰,以增强网络对前景特征的学习,得到人体检测网络。样本标注时,将标注边界框内目标背景区域的像素置0,而前景区域像素保持不变。本文使用matlab 和labelimg 标注工具对训练集进行标注,首先对其中的3955个人体目标(遮挡面积<0.5)进行标注,然后对剩余的1121 个相互遮挡的目标进行前景区域标注,标注完成后生成VOC 格式的xml 文件,然后将xml 文件转换成一个yolo格式的txt 文件,最终的CrowdHuman 数据集添加部分见表1。最终的FHDRC 数据集为CrowdHuman 数据集+添加数据集。
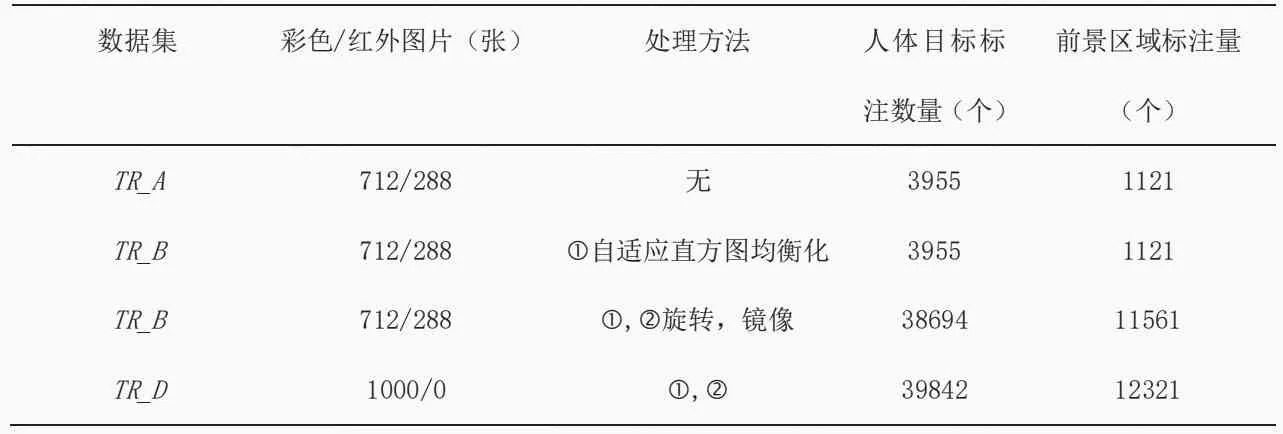
表1 CrowdHuman数据集训练集添加部分Table 1 Added part of CrowdHuman dataset training set
2.2 提取候选框
YOLO v3 为了解决小目标的检测问题,引入了三级预测的思想,YOLO v3 的图像分成N×N 的网络,比如predict1 的特征图为13×13,predict2 的特征图为26×26,predict3 的特征图为52×52,然后每一个grid cell 预测3bounding box。但是室内中的人体成像具有自己的特点,这一种侯选框在X 轴和Y 轴的等密度分布不适合人体检测。为了分析室内场景中人体成像的特点,随机在室内数据集中抽取了200 个人体目标,然后随机平均编入10 组,分别求出它们的宽高比的平均值。经分析可知,每一组的人体成像的高宽比平均值都大于1,因此可以发现人体成像具有高宽比大的特点,这就意味着候选框在X 轴和Y 轴的等密度分布并不有利于人体识别,在室内人群密集的时候,会导致漏检率升高。为了解决这个问题,增加候选框在X轴上的密度,降低候选框在Y 轴的密度。最终,在predict1的特征图修改为16×10,predict2 的特征图修改为32×20,predict3 的特征图修改为64×40。
YOLO v3 的候选框尺寸使用了anchor,anchor 是具有一组固定尺寸的初始候选框。YOLO v3 通过K-means 算法对数据集的标注框进行聚类,最终得到9 种候选框尺寸。但是对于室内场景中,这些尺寸未必是最好的结果,所以对1.1 节设计的室内人体数据集采用了k-means 算法,对手工标注的人体目标框进行聚类,对候选框宽高与单位网格长度之比进行聚类。预测框和真实框的IOU 是反映预测框与真实框差异的重要指标,IOU 值越大,表明两者差异越小,“距离”越近。

图2 室内场景人体识别数据集边界聚类Fig.2 Boundary clustering of human body recognition data set in indoor scene
在聚类的时候,分别取了anchor 的个数为1,2,3,4,5。根据图2 可知,当anchor 个数为3 的时候,算法的精度和速度综合效果较好,最终仍然取anchor 为3,得到了9 种 聚 类 结 果:(15×13),(19×33),(20×43),(31×61),(62×45),(59×119),(116×90),(152×198),(375×327)。
3 人体检测
3.1 图片去噪
在采集图片和ROI 提取的过程中,难免会受到外界和设备的噪声,为了提升人体识别效果,首先对图像进行去噪处理显得十分必要。在室内场景中,可见光下的图片受噪声的影响较小,因此主要讨论在光照条件不足的情况下,对红外图片噪声的处理。红外噪声的产生主要是在由红外波的相互干涉,引起散斑噪声。事实上,乘性噪声的影响远远大于加性噪声。因此,可以认为红外图片的主要噪声是乘性噪声。由于一次均值去噪效果较差,为了加强去噪效果,采用两次均值去噪处理。
3.2 ROI提取及检测
在室内场景中,对人体的检测更关心运动场景下的人体识别。为了节省检测时间和资源,先使用三帧差分法进行运动物体识别,进行运动区域ROI 提取。如果三帧差分法没有检测到运动物体区域,则间隔一段时间采集一张图片送入训练好的人体检测器进行检测,反之如果三帧差分法检测到运动目标,则找出物体所在边界后,对边界进行适当的扩充,剪出运动物体区域,然后将非运动区域的像素置零,将剪辑的区域利用YOLO v3_H 进行人体检测。
4 实验及结果分析

图3 红外图片人体检测效果对比Fig.3 Comparison of human body detection effect in infrared images
经过构建人体识别数据集FHDRC,以及进行YOLO v3_H 的网络改进训练,然后进行图片预处理后,得到室内场景人体识别方法YOLO_v3_H。在检测输出处理过程中,采用目标置信度阈值过滤边界框,然后使用非极大值抑制获取最终的目标框,最后使用准确率和召回率以及运行时间来验证改进后方法的有效性。准确率用P 表示,召回率用R 表示,漏检率用L 表示。如果是目标窗口的判断正确(IOU >0.6)的计数为Ty,如果不是目标窗口的判断正确的计数为Tn。采集200 张红外夜视图片,然后分别使用YOLO v3_H,YOLO,YOLO v3 和HOG+SVM 进行测试,最终结果如图3 所示。
实验证明,YOLO_v3_H 在室内场景中,对红外图片的人体检测比经典的人体检测算法HOG+SVM 的P 提升46.4%,同时比haar+adaboost 的P提升了56.4%,比YOLO v2P 值提高了8.2%,比YOLO v3 提高了4.1%。为了验证YOLO v3_H 对密集人群的人体识别效果,分别利用YOLO v3_H,YOLO v3,YOLO v2 和faster_CNN 和HOG+SVM 对FHDRC 的测试进行检测,然后使用漏检率进行性能测试。实验证明,YOLO_v3_H 漏检率基本和YOLO_v3 持平,但是比YOLO_v2 的漏检率低17.9%,比faster_cnn 低21.3%,比传统算法HOG+SVM 低42.3%。图4 为漏检率曲线。
将目标检测的最新研究成果YOLO v3 应用到室内场景中,为室内人体识别制作了人体识别数据集,聚类得出新的anchor。根据人体成像的特点,改进了候选框在X 轴和Y 轴的分布密度,针对常用算法在红外图片识别精度不佳的情况下,采取了红外图片和彩色图片混合训练的策略,同时改进了监控过程中将每一张图片放入网络检测造成的资源浪费,改进检测策略。在场景静止的情况下,使用隔一段时间采集图片进行检测,如果场景中有运动物体,则采取使用运动算法提取ROI 进行检测。实验证明,提出的方法对场景中的人体检测有着极高的识别准确率和较低的漏检率,也提高了资源利用效率。
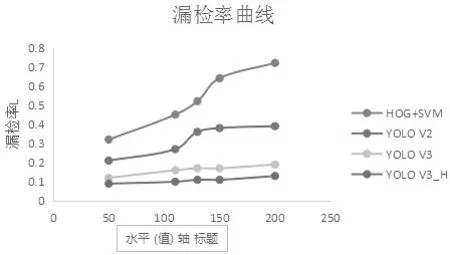
图4 漏检率效果对比Fig.4 Effect Comparison of missing detection rate
